test arranger
v1.6.3
Bei TDD gibt es drei Phasen: Anordnen, Handeln und Behaupten (gegeben, wann, dann in BDD). Die Assert-Phase verfügt über eine hervorragende Toolunterstützung. Möglicherweise kennen Sie AssertJ, FEST-Assert oder Hamcrest. Es steht im Gegensatz zur Arrangierphase. Obwohl das Ordnen von Testdaten oft eine Herausforderung darstellt und normalerweise ein Großteil des Tests darauf verwendet wird, ist es schwierig, ein Tool zu nennen, das dies unterstützt.
Test Arranger versucht, diese Lücke zu schließen, indem er Instanzen von Klassen anordnet, die für Tests erforderlich sind. Die Instanzen sind mit Pseudozufallswerten gefüllt, die den Prozess der Testdatenerstellung vereinfachen. Der Tester deklariert nur Typen der erforderlichen Objekte und erhält brandneue Instanzen. Wenn ein Pseudozufallswert für ein bestimmtes Feld nicht gut genug ist, muss nur dieses Feld manuell festgelegt werden:
Product product = Arranger . some ( Product . class );
product . setBrand ( "Ocado" );< dependency >
< groupId >com.ocadotechnology.gembus</ groupId >
< artifactId >test-arranger</ artifactId >
< version >1.6.3</ version >
</ dependency >testImplementation ' com.ocadotechnology.gembus:test-arranger:1.6.3 ' Die Arranger-Klasse verfügt über mehrere statische Methoden zum Generieren pseudozufälliger Werte einfacher Typen. Jeder von ihnen verfügt über eine Wrapping-Funktion, um die Aufrufe für Kotlin zu vereinfachen. Nachfolgend sind einige der möglichen Anrufe aufgeführt:
| Java | Kotlin | Ergebnis |
|---|---|---|
Arranger.some(Product.class) | some<Product>() | eine Instanz von Product, bei der alle Felder mit Werten gefüllt sind |
Arranger.some(Product.class, "brand") | some<Product>("brand") | eine Instanz von Product ohne Wert für das Markenfeld |
Arranger.someSimplified(Category.class) | someSimplified<Category>() | Als Instanz einer Kategorie ist die Größe von Feldern vom Typ „Sammlung“ auf 1 reduziert und die Tiefe für den Objektbaum ist auf 3 begrenzt |
Arranger.someObjects(Product.class, 7) | someObjects<Product>(7) | ein Stream der Größe 7 von Produktinstanzen |
Arranger.someEmail() | someEmail() | eine Zeichenfolge, die eine E-Mail-Adresse enthält |
Arranger.someLong() | someLong() | eine Pseudozufallszahl vom Typ long |
Arranger.someFrom(listOfCategories) | someFrom(listOfCategories) | ein Eintrag aus der listOfCategories |
Arranger.someText() | someText() | eine aus einer Markov-Kette generierte Zeichenfolge; Standardmäßig handelt es sich um eine sehr einfache Kette, die jedoch neu konfiguriert werden kann, indem eine andere „enMarkovChain“-Datei mit alternativer Definition in den Testklassenpfad eingefügt wird. Eine auf einem englischen Korpus trainierte Datei finden Sie hier. Informationen zum Dateiformat finden Sie in der im Projekt enthaltenen Datei „enMarkovChain“. |
| - | some<Product> {name = "not so random"} | eine Instanz von Produkt, bei der alle Felder mit Zufallswerten gefüllt sind, mit Ausnahme des name , der auf „nicht so zufällig“ gesetzt ist; diese Syntax kann verwendet werden, um so viele Felder des Objekts wie nötig festzulegen, aber jedes der Objekte muss veränderbar sein |
Völlig zufällige Daten sind möglicherweise nicht für jeden Testfall geeignet. Oft gibt es mindestens ein Feld, das für das Testziel entscheidend ist und einen bestimmten Wert benötigt. Wenn die angeordnete Klasse veränderbar ist, es sich um eine Kotlin-Datenklasse handelt oder es eine Möglichkeit gibt, eine geänderte Kopie zu erstellen (z. B. Lomboks @Builder(toBuilder = true)), dann verwenden Sie einfach das, was verfügbar ist. Glücklicherweise können Sie den Test Arranger verwenden, auch wenn er nicht einstellbar ist. Es gibt dedizierte Versionen der Methoden some() und someObjects() die einen Parameter vom Typ Map<String,Supplier> akzeptieren. Die Schlüssel in dieser Karte stellen Feldnamen dar, während die entsprechenden Lieferanten Werte liefern, die Test Arranger für diese Felder für Sie festlegt, z. B.:
Product product = Arranger . some ( Product . class , Map . of ( "name" , () -> value ));Standardmäßig werden die Zufallswerte entsprechend dem Feldtyp generiert. Zufällige Werte korrespondieren nicht immer gut mit Klasseninvarianten. Wenn eine Entität immer nach bestimmten Regeln bezüglich der Werte von Feldern angeordnet werden muss, können Sie einen benutzerdefinierten Arranger bereitstellen:
class ProductArranger extends CustomArranger < Product > {
@ Override
protected Product instance () {
Product product = enhancedRandom . nextObject ( Parent . class );
product . setPrice ( BigDecimal . valueOf ( Arranger . somePositiveLong ( 9_999L )));
return product ;
}
} Um die Kontrolle über den Prozess der Product zu haben, müssen wir die Methode instance() überschreiben. Innerhalb der Methode können wir die Instanz von Product nach unseren Wünschen erstellen. Insbesondere können wir einige Zufallswerte generieren. Der Einfachheit halber gibt es in der CustomArranger -Klasse ein enhancedRandom -Feld. Im gegebenen Beispiel generieren wir eine Instanz von Product , wobei alle Felder pseudozufällige Werte haben, aber dann ändern wir den Preis auf einen für unsere Domäne akzeptablen Preis. Das ist nicht negativ und kleiner als die 10.000-Zahl.
Der ProductArranger wird automatisch (mittels Reflektion) vom Arranger übernommen und immer dann verwendet, wenn eine neue Instanz des Product angefordert wird. Es betrifft nicht nur direkte Aufrufe wie Arranger.some(Product.class) , sondern auch indirekte. Angenommen, es gibt eine Klasse Shop mit dem Feld products vom Typ List<Product> . Beim Aufruf von Arranger.some(Shop.class) verwendet der Arranger ProductArranger um alle in Shop.products gespeicherten Produkte zu erstellen.
Das Verhalten des Test-Arrangers kann über Eigenschaften konfiguriert werden. Wenn Sie die Datei arranger.properties erstellen und im Stammverzeichnis des Klassenpfads speichern (normalerweise ist dies das Verzeichnis src/test/resources/ ), wird sie übernommen und die folgenden Eigenschaften werden angewendet:
arranger.root Die benutzerdefinierten Arranger werden mithilfe von Reflection erfasst. Alle Klassen, CustomArranger erweitern, gelten als benutzerdefinierte Arranger. Die Reflexion konzentriert sich auf ein bestimmtes Paket, das standardmäßig com.ocado ist. Das ist nicht unbedingt bequem für Sie. Mit arranger.root=your_package kann es jedoch in your_package geändert werden. Versuchen Sie, das Paket so spezifisch wie möglich zu gestalten, da etwas Generisches (z. B. nur com , das in vielen Bibliotheken das Root-Paket ist) dazu führt, dass Hunderte von Klassen gescannt werden, was beträchtliche Zeit in Anspruch nimmt.arranger.randomseed Standardmäßig wird immer derselbe Startwert verwendet, um den zugrunde liegenden Generator für Pseudozufallswerte zu initialisieren. Infolgedessen generieren die nachfolgenden Ausführungen dieselben Werte. Um Zufälligkeit über die Läufe hinweg zu erreichen, also immer mit anderen Zufallswerten zu beginnen, ist die Einstellung arranger.randomseed=true erforderlich.arranger.cache.enable Das Anordnen zufälliger Instanzen erfordert einige Zeit. Wenn Sie eine große Anzahl von Instanzen erstellen und diese nicht völlig zufällig sein sollen, ist die Aktivierung des Caches möglicherweise die richtige Lösung. Wenn diese Option aktiviert ist, speichert der Cache Verweise auf jede zufällige Instanz, und irgendwann hört der Test-Arranger auf, neue Instanzen zu erstellen, und verwendet stattdessen die zwischengespeicherten Instanzen wieder. Standardmäßig ist der Cache deaktiviert.arranger.overridedefaults Test-Arranger respektiert die Standardfeldinitialisierung, dh wenn ein Feld mit einer leeren Zeichenfolge initialisiert wird, enthält die von test-arranger zurückgegebene Instanz die leere Zeichenfolge in diesem Feld. Nicht immer ist es das, was Sie in den Tests benötigen, insbesondere wenn es im Projekt eine Konvention gibt, Felder mit leeren Werten zu initialisieren. Glücklicherweise können Sie test-arranger zwingen, die Standardwerte mit Zufallswerten zu überschreiben. Setzen Sie arranger.overridedefaults auf „true“, um die Standardinitialisierung zu überschreiben.arranger.maxRandomizationDepth Einige Testdatenstrukturen können beliebig lange Ketten von Objekten generieren, die aufeinander verweisen. Um sie jedoch effektiv in einem Testfall nutzen zu können, ist es entscheidend, die Länge dieser Ketten zu kontrollieren. Standardmäßig stoppt Test-Arranger die Erstellung neuer Objekte auf der 4. Ebene der Verschachtelungstiefe. Sollte diese Standardeinstellung nicht zu Ihren Projekttestfällen passen, kann sie über diesen Parameter angepasst werden. Wenn Sie einen Java-Datensatz haben, der als Testdaten verwendet werden könnte, Sie aber ein oder zwei seiner Felder ändern müssen, bietet die Data Klasse mit ihrer Kopiermethode eine Lösung. Dies ist besonders nützlich, wenn es um unveränderliche Datensätze geht, bei denen es keine offensichtliche Möglichkeit gibt, ihre Felder direkt zu ändern.
Mit der Data.copy -Methode können Sie eine flache Kopie eines Datensatzes erstellen und gleichzeitig die gewünschten Felder selektiv ändern. Durch die Bereitstellung einer Karte von Feldüberschreibungen können Sie die zu ändernden Felder und ihre neuen Werte angeben. Die Kopiermethode sorgt dafür, dass eine neue Instanz des Datensatzes mit den aktualisierten Feldwerten erstellt wird.
Dieser Ansatz erspart Ihnen das manuelle Erstellen eines neuen Datensatzobjekts und das individuelle Festlegen der Felder und bietet eine bequeme Möglichkeit, Testdaten mit geringfügigen Abweichungen von vorhandenen Datensätzen zu generieren.
Insgesamt retten die Data-Klasse und ihre Kopiermethode die Situation, indem sie die Erstellung flacher Kopien von Datensätzen mit geänderten ausgewählten Feldern ermöglichen, was Flexibilität und Komfort bei der Arbeit mit unveränderlichen Datensatztypen bietet:
Data . copy ( myRecord , Map . of ( "recordFieldName" , () -> "altered value" ));Beim Durchlaufen von Tests eines Softwareprojekts hat man selten den Eindruck, dass es nicht besser gemacht werden kann. Im Bereich der Anordnung von Testdaten gibt es zwei Bereiche, die wir mit Test Arranger verbessern möchten.
Tests sind viel einfacher zu verstehen, wenn man die Absicht des Erstellers kennt, also warum der Test geschrieben wurde und welche Art von Problemen er erkennen soll. Leider kommt es nicht selten vor, dass Tests im Abschnitt „arrangieren“ Anweisungen wie die folgende enthalten:
Product product = Product . builder ()
. withName ( "Some name" )
. withBrand ( "Some brand" )
. withPrice ( new BigDecimal ( "12.99" ))
. withCategory ( "Water, Juice & Drinks / Juice / Fresh" )
...
. build ();Wenn man sich solchen Code ansieht, ist es schwer zu sagen, welche Werte für den Test relevant sind und welche nur bereitgestellt werden, um einige Nicht-Null-Anforderungen zu erfüllen. Wenn es bei dem Test um die Marke geht, warum nicht so schreiben:
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );Jetzt ist klar, dass die Marke wichtig ist. Versuchen wir, noch einen Schritt weiter zu gehen. Der gesamte Test könnte wie folgt aussehen:
//arrange
Product product = Arranger . some ( Product . class );
product . setBrand ( "Some brand" );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( "Some brand" ) Wir testen derzeit, ob der Bericht für die Marke „Some brand“ erstellt wurde. Aber ist das das Ziel? Es ist sinnvoller zu erwarten, dass der Bericht für dieselbe Marke erstellt wird, der das jeweilige Produkt zugeordnet ist. Was wir also testen wollen, ist:
//arrange
Product product = Arranger . some ( Product . class );
//act
Report actualReport = sut . createBrandReport ( Collections . singletonList ( product ))
//assert
assertThat ( actualReport . getBrand ). isEqualTo ( product . getBrand ()) Falls das Markenfeld veränderbar ist und wir befürchten, dass das sut es ändern könnte, können wir seinen Wert in einer Variablen speichern, bevor wir in die Aktionsphase gehen, und ihn später für die Behauptung verwenden. Der Test wird länger dauern, aber die Absicht bleibt klar.
Es ist bemerkenswert, dass es sich bei dem, was wir gerade gemacht haben, um eine Anwendung von generierten Werten und in gewissem Umfang von Mustern der Erstellungsmethode handelt, die in xUnit Test Patterns: Refactoring Test Code von Gerard Meszaros beschrieben werden.
Haben Sie schon einmal eine Kleinigkeit im Produktionscode geändert und dabei bei Dutzenden von Tests Fehler festgestellt? Einige von ihnen melden eine fehlgeschlagene Behauptung, andere weigern sich möglicherweise sogar, die Kompilierung durchzuführen. Dies ist ein Schrotflinten-Chirurgie-Code-Geruch, der gerade auf Ihre unschuldigen Tests geschossen hat. Nun ja, vielleicht nicht so unschuldig, da sie anders gestaltet werden könnten, um den Kollateralschaden zu begrenzen, der durch kleine Veränderungen verursacht wird. Lassen Sie es uns anhand eines Beispiels analysieren. Angenommen, wir haben in unserer Domäne die folgende Klasse:
class TimeRange {
private LocalDateTime start ;
private long durationinMs ;
public TimeRange ( LocalDateTime start , long durationInMs ) {
... und dass es an vielen Orten verwendet wird. Besonders in den Tests, ohne Test Arranger, mit Anweisungen wie dieser: new TimeRange(LocalDateTime.now(), 3600_000L); Was passiert, wenn wir aus wichtigen Gründen gezwungen sind, die Klasse zu ändern in:
class TimeRange {
private LocalDateTime start ;
private LocalDateTime end ;
public TimeRange ( LocalDateTime start , LocalDateTime end ) {
... Es ist eine ziemliche Herausforderung, eine Reihe von Refactorings zu entwickeln, die die alte Version in die neue umwandeln, ohne alle abhängigen Tests zu zerstören. Wahrscheinlicher ist ein Szenario, bei dem die Tests nach und nach an die neue API der Klasse angepasst werden. Das bedeutet eine Menge nicht gerade spannender Arbeit mit vielen Fragen zum gewünschten Wert der Dauer (sollte ich ihn sorgfältig in das end des Typs „LocalDateTime“ umwandeln oder handelte es sich nur um einen praktischen Zufallswert)? Mit Test Arranger wäre das Leben viel einfacher. Wenn wir an allen Stellen, an denen TimeRange nicht null ist, Arranger.some(TimeRange.class) haben, ist es für die neue Version von TimeRange genauso gut wie für die alte. Damit bleiben uns die wenigen Fälle, in denen kein zufälliger TimeRange erforderlich ist. Da wir jedoch bereits Test Arranger verwenden, um die Testabsicht aufzudecken, wissen wir in jedem Fall genau, welcher Wert für TimeRange verwendet werden sollte.
Aber das ist nicht alles, was wir tun können, um die Tests zu verbessern. Vermutlich können wir einige Kategorien der TimeRange Instanz identifizieren, z. B. Bereiche aus der Vergangenheit, Bereiche aus der Zukunft und Bereiche, die aktuell aktiv sind. Der TimeRangeArranger ist ein großartiger Ort, um Folgendes zu arrangieren:
class TimeRangeArranger extends CustomArranger < TimeRange > {
private final long MAX_DISTANCE = 999_999L ;
@ Override
protected TimeRange instance () {
LocalDateTime start = enhancedRandom . nextObject ( LocalDateTime . class );
LocalDateTime end = start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
public TimeRange fromPast () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime end = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( end . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )), end );
}
public TimeRange fromFuture () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , start . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE )));
}
public TimeRange currentlyActive () {
LocalDateTime now = LocalDateTime . now ();
LocalDateTime start = now . minusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
LocalDateTime end = now . plusHours ( Arranger . somePositiveLong ( MAX_DISTANCE ));
return new TimeRange ( start , end );
}
} Eine solche Erstellungsmethode sollte nicht im Voraus erstellt werden, sondern mit vorhandenen Testfällen korrespondieren. Dennoch besteht die Möglichkeit, dass der TimeRangeArranger alle Fälle abdeckt, in denen Instanzen von TimeRange für Tests erstellt werden. Als Konsequenz haben wir anstelle von Konstruktoraufrufen mit mehreren mysteriösen Parametern einen Arranger mit einer gut benannten Methode, die die Domänenbedeutung des erstellten Objekts erklärt und beim Verständnis der Testabsicht hilft.
Bei der Erörterung der von Test Arranger gelösten Herausforderungen haben wir zwei Ebenen von Testdatenerstellern identifiziert. Um das Bild zu vervollständigen, müssen wir noch mindestens eines erwähnen, nämlich die Ausstattung. Für diese Diskussion können wir davon ausgehen, dass Fixture eine Klasse ist, die zum Erstellen komplexer Strukturen von Testdaten entwickelt wurde. Der benutzerdefinierte Arranger konzentriert sich immer auf eine Klasse, aber manchmal können Sie in Ihren Testfällen wiederkehrende Konstellationen von zwei oder mehr Klassen beobachten. Dies können der Benutzer und sein Bankkonto sein. Möglicherweise gibt es für jeden von ihnen einen CustomArranger, aber warum sollte man die Tatsache ignorieren, dass sie häufig zusammenkommen? Dann sollten wir anfangen, über ein Fixture nachzudenken. Es ist dafür verantwortlich, sowohl das Benutzer- als auch das Bankkonto zu erstellen (vermutlich unter Verwendung spezieller benutzerdefinierter Arranger) und diese miteinander zu verknüpfen. Die Fixtures werden ausführlich beschrieben, einschließlich mehrerer Implementierungsvarianten in xUnit Test Patterns: Refactoring Test Code von Gerard Meszaros.
Wir haben also drei Arten von Bausteinen in den Testklassen. Jeder von ihnen kann als Gegenstück zu einem Konzept (Domain Driven Design-Baustein) aus dem Produktionscode betrachtet werden: 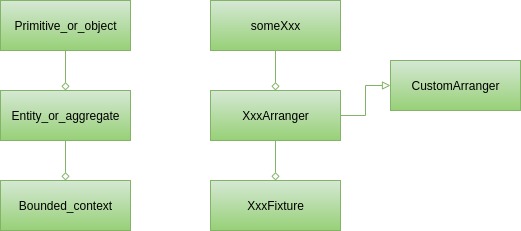
An der Oberfläche gibt es Grundelemente und einfache Objekte. Das kommt selbst in den einfachsten Unit-Tests zum Vorschein. Sie können das Anordnen solcher Testdaten mit den someXxx -Methoden der Arranger -Klasse abdecken.
Daher verfügen Sie möglicherweise über Dienste, die Tests erfordern, die ausschließlich auf User oder sowohl auf User als auch auf anderen in der User enthaltenen Klassen, wie z. B. einer Liste von Adressen, funktionieren. Um solche Fälle abzudecken, ist normalerweise ein benutzerdefinierter Arranger erforderlich, nämlich der UserArranger . Es werden Instanzen von User erstellt, die alle Einschränkungen und Klasseninvarianten berücksichtigen. Darüber hinaus wird AddressArranger (falls vorhanden) abgerufen, um die Liste der Adressen mit gültigen Daten zu füllen. Wenn mehrere Testfälle einen bestimmten Benutzertyp erfordern, z. B. obdachlose Benutzer mit einer leeren Adressliste, kann im UserArranger eine zusätzliche Methode erstellt werden. Wenn es daher erforderlich ist, eine User für die Tests zu erstellen, reicht es aus, in UserArranger nachzusehen und eine geeignete Factory-Methode auszuwählen oder einfach Arranger.some(User.class) aufzurufen.
Der schwierigste Fall betrifft Tests, die auf großen Datenstrukturen basieren. Im E-Commerce kann das ein Shop sein, der viele Produkte enthält, aber auch Benutzerkonten mit Einkaufshistorie. Das Ordnen von Daten für solche Testfälle ist normalerweise nicht trivial und es wäre nicht sinnvoll, so etwas zu wiederholen. Es ist viel besser, es in einer dedizierten Klasse unter einer gut benannten Methode wie shopWithNineProductsAndFourCustomers zu speichern und in jedem der Tests wiederzuverwenden. Wir empfehlen dringend, für solche Klassen eine Namenskonvention zu verwenden. Um sie leichter auffindbar zu machen, empfehlen wir die Verwendung Fixture Postfixes. Irgendwann könnten wir so etwas bekommen:
class ShopFixture {
Repository repo ;
public void shopWithNineProductsAndFourCustomers () {
Arranger . someObjects ( Product . class , 9 )
. forEach ( p -> repo . save ( p ));
Arranger . someObjects ( Customer . class , 4 )
. forEach ( p -> repo . save ( p ));
}
}Die neueste Test-Arranger-Version wird mit Java 17 kompiliert und sollte in der Java 17+-Laufzeit verwendet werden. Aus Gründen der Abwärtskompatibilität gibt es jedoch auch einen Java 8-Zweig, der mit den 1.4.x-Versionen abgedeckt ist.


