Dieser Code basiert auf einem bereits vorhandenen Image-to-BEV-Deep-Learning-Modell, basierend auf dem Artikel „Translating Images Into Maps“. Dieser Code wurde mit Python 3.7 geschrieben. und wurde anhand des nuScenes-Datensatzes trainiert. Informationen zu den zu installierenden Abhängigkeiten und Datensätzen finden Sie in der ReadMe-Datei des Repositorys.
Der erste Schritt besteht darin, einen Ordner mit dem Namen „translating-images-into-maps-main“ zu erstellen und alle Dateien dorthin herunterzuladen. Aufgrund der großen Dateigröße können dann die neuesten Prüfpunkte unseres Trainings und der zur Validierung verwendete Mini-nuScenes-Datensatz von diesem Google Drive heruntergeladen werden. Diese Ordner sollten direkt im Verzeichnis „translating-images-into-maps-main“ hinzugefügt werden.
Nachfolgend finden Sie die Liste der erforderlichen Bibliotheken für dieses Repo:
opencv
numpy
pyquaternion
shapely
lmdb
nuscenes-devkit
pillow
matplotlib
torchvision
descartes
scipy
tensorboard
scikit-image
cv2
Um die Funktionen dieses Repositorys nutzen zu können, müssen möglicherweise die folgenden Befehlszeilenargumente geändert werden:
--name: name of the experiment
--video-name: name of the video file within the video root and without extension
--savedir: directory to save experiments to
--val-interval: number of epochs between validation runs
--root: directory of the repository
--video-root: absolute directory to the video input
--nusc-version: nuscenes version (either “v1.0-mini” or “v1.0-trainval” for the full US dataset)
--train-split: training split (either “train_mini" or “train_roddick” for the full US dataset)
--val-split: validation split (either “val_mini" or “val_roddick” for the full US dataset)
--data-size: percentage of dataset to train on
--epochs: number of epochs to train for
--batch-size: batch size
--cuda-available: environment used (0 for cpu, 1 for cuda)
--iou: iou metric used (0 for iou, 1 for diou)
Zum Trainieren des Modells können diese Befehlszeilenargumente geändert werden:
--optimizer: optimizer for gradient descent to run during training. Default: adam
--lr: learning rate. Default: 5e-5
--momentum: momentum for Stochastic gradient descent. Default: 0.9
--weight-decay: weight decay. Default: 1e-4
--lr-decay: learning rate decay. Default: 0.99
Die NuScenes Mini- und Full-Datensätze finden Sie an den folgenden Orten:
NuScene Mini:
NuScenes Vollständige USA:
Da die NuScene-Mini- und Volldatensätze nicht dasselbe Bildeingabeformat (lmdb oder png) haben, müssen einige Änderungen am Code vorgenommen werden, um das eine oder andere zu verwenden:
mini -Argument in „false“, um das Mini-Dataset sowie die Argumentpfade und Aufteilungen in den Dateien train.py , validation.py und inference.py zu verwenden. data = nuScenesMaps (
root = args . root ,
split = args . val_split ,
grid_size = args . grid_size ,
grid_res = args . grid_res ,
classes = args . load_classes_nusc ,
dataset_size = args . data_size ,
desired_image_size = args . desired_image_size ,
mini = True ,
gt_out_size = ( 200 , 200 ),
)
loader = DataLoader (
data ,
batch_size = args . batch_size ,
shuffle = False ,
num_workers = 0 ,
collate_fn = src . data . collate_funcs . collate_nusc_s ,
drop_last = True ,
pin_memory = True
)data_loader.py : # if mini:
image_input_key = pickle . dumps ( id , protocol = 3 )
with self . images_db . begin () as txn :
value = txn . get ( key = image_input_key )
image = Image . open ( io . BytesIO ( value )). convert ( mode = 'RGB' )
# else:
# original_nusenes_dir = "/work/scitas-share/datasets/Vita/civil-459/NuScenes_full/US/samples/CAM_FRONT"
# new_cam_path = os.path.join(original_nusenes_dir, Path(cam_path).name)
# image = Image.open(new_cam_path).convert(mode='RGB')Die vortrainierten Checkpoints finden Sie hier:
Die Prüfpunkte müssen innerhalb von /pretrained_models/27_04_23_11_08 im Stammverzeichnis dieses Repositorys aufbewahrt werden. Wenn Sie sie aus einem anderen Verzeichnis laden möchten, ändern Sie bitte die folgenden Argumente:
- - savedir = "pretrained_models" # Careful, this path is relative in validation.py but global in train.py
- - name = "27_04_23_11_08"Um Scitas zu trainieren, müssen Sie das folgende Skript aus dem Stammverzeichnis starten:
sbatch job.script.sh
So trainieren Sie lokal auf der CPU:
python3 train.py
Stellen Sie sicher, dass Sie das Skript an Ihre Befehlszeilenargumente anpassen.
So validieren Sie die Leistung eines Modells bei Scitas:
sbatch job.validate.sh
So trainieren Sie lokal auf der CPU:
python3 validate.py
Stellen Sie sicher, dass Sie das Skript an Ihre Befehlszeilenargumente anpassen.
Um auf ein Video über Scitas zu schließen:
sbatch job.evaluate.sh
So trainieren Sie lokal auf der CPU:
python3 inference.py
Stellen Sie sicher, dass Sie das Skript an Ihre Befehlszeilenargumente anpassen, insbesondere:
--batch-size // 1 for the test videos
--video-name
--video-root
Dieses Projekt wurde im Rahmen des Kurses „Deep Learning for Autonomous Vehicles“ CIVIL-459 durchgeführt, der von Professor Alexandre Alahi an der EPFL unterrichtet wird. Betreut wurden wir von der Doktorandin Yuejiang Liu. Das Hauptziel des Kursprojekts ist die Entwicklung eines Deep-Learning-Modells, das an Bord eines Tesla-Autopilotsystems verwendet werden kann. Was unsere Gruppe betrifft, haben wir uns mit der Transformation von monokularen Kamerabildern zur Vogelperspektive befasst. Dies kann durch semantische Segmentierung zur Klassifizierung von Elementen wie Autos, Gehwegen, Fußgängern und dem Horizont erreicht werden.
Bei unserer Forschung zu monokularen Bildern für BEV-Deep-Learning-Modelle haben wir festgestellt, dass Informationen über Fußgänger während der Segmentierung verloren gingen, was zu einer schlechten Klassifizierung führte. Wie im Bild unten zu sehen ist, erreicht das von uns ausgewählte Modell bei der Auswertung einen Mittelwert von 25,7 % IoU (Intersection over Union) über 14 Objektklassen im nuScenes-Datensatz. Die Vorhersagegenauigkeit für befahrbare Güter ist gut (74,5 %), für Fahrräder, Barrieren und Anhänger eher schlecht. Allerdings ist die Vorhersagegenauigkeit für Fußgänger (9,5 %) viel zu gering. Eine so geringe Genauigkeit könnte zu Unfällen führen, wenn jemand die Straße überquert, ohne sich auf der Kreuzung zu befinden.

Weitere Informationen zu unserer Forschung finden Sie auf der Drive.
Da die schlechte Erkennung von Fußgängern das unmittelbarste Problem des aktuell trainierten Modells zu sein schien, wollten wir die Genauigkeit verbessern, indem wir nach besser geeigneten Verlustfunktionen suchten und das neue Modell anhand des nuScenes-Datensatzes trainierten.
Das Modell, auf dem wir aufgebaut haben, wurde mit einem trainiert
Ein weiteres Problem mit
Der
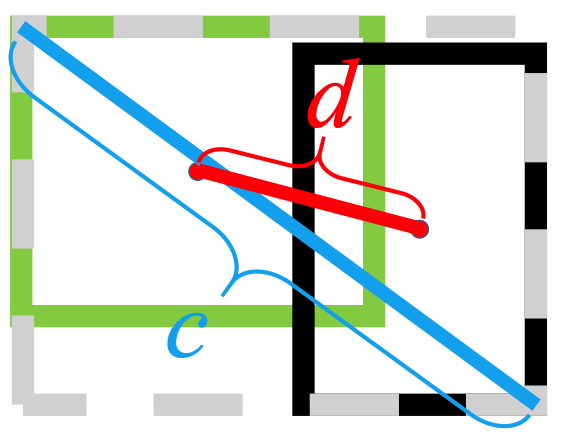
Es verwendet die L2-Norm, um den Abstand zwischen vorhergesagten und Zielfeldern zu minimieren, und konvergiert viel schneller als

Horizontale Dehnung

Vertikale Dehnung
Darüber hinaus führt der DIoU-Verlust einen Regularisierungsterm ein, der eine reibungslose Konvergenz fördert.
Wie im folgenden Bild zu sehen ist, ist die
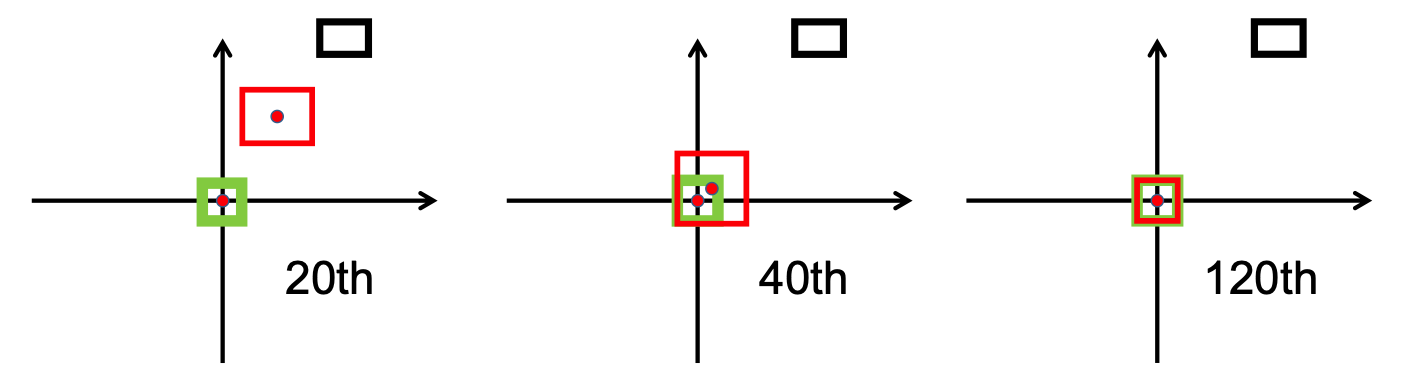
Nach der Forschungsphase haben wir das implementiert bbox_overlaps_diou in der Datei /src/utils.py durch Verwendung von
Diese Funktion wird dann zur Multiskalenberechnung verwendet compute_multiscale_iou derselben Datei. Für jede Klasse ist die iou Eingabearguments) wird über die Stapelgröße berechnet. Die Ausgabe der Funktion ist ein Wörterbuch iou_dict das die Multiskala enthält
Wir haben diese Werte dann in train.py verwendet, wo die val-interval -Epochen in den Bewertungsläufen verwendet. Diese Werte wurden auch in validation.py verwendet, wo sie zur Anzeige der Verluste und verwendet wurden
Wir haben das Modell auf dem NuScenes-Datensatz trainiert, beginnend mit dem bereitgestellten Checkpoint checkpoint-008.pth.gz , einmal mit dem
Ein weiterer Beitrag ist das neue Visualisierungsformat zur besseren Unterscheidung von Klassen mit allen entsprechenden Beschriftungen und IoU-Werten. Dies wurde in der Datei visualization.py implementiert.
Zuletzt haben wir daran gearbeitet, einen Modus zu implementieren, der .mp4 Videos als Eingabe nimmt und sie in einzelne Bildrahmen zerlegt. Diese würden dann vom Modell ausgewertet und wir könnten das Segmentierungsergebnis in der Datei inference.py visualisieren.
Um eine vorläufige Vorstellung von der Trainingsstrategie dieses Modells zu bekommen, haben wir uns zunächst entschieden, es auf den NuScenes-Minidatensätzen zu trainieren. Ausgehend von checkpoint-008.pth.gz konnten wir zwei Modelle trainieren, die sich in der verwendeten IoU-Metrik unterscheiden (IoU für das eine und DIoU für das andere). Die mit einem NuScenes-Minibatch nach 10 Trainingsepochen erzielten Ergebnisse sind in der folgenden Tabelle aufgeführt.

Nachdem wir uns diese Ergebnisse angesehen hatten, stellten wir fest, dass die Fußgängerklasse, auf der wir unsere Hypothese basierten, überhaupt keine schlüssigen Ergebnisse lieferte. Wir kamen daher zu dem Schluss, dass der Minidatensatz für unsere Anforderungen nicht ausreichte, und beschlossen, unser Training auf den vollständigen Datensatz von Scitas zu verlagern.
Nachdem wir unsere neuen Modelle (mit DIoU oder IoU) von checkpoint-008.pth.gz für 8 neue Epochen trainiert hatten, beobachteten wir vielversprechende Ergebnisse. Mit dem Ziel, die Leistung dieser neu trainierten Modelle zu vergleichen, führten wir einen Validierungsschritt für den Minidatensatz durch. Eine Visualisierung des Ergebnisses für ein Bild dieses Datensatzes finden Sie unten.
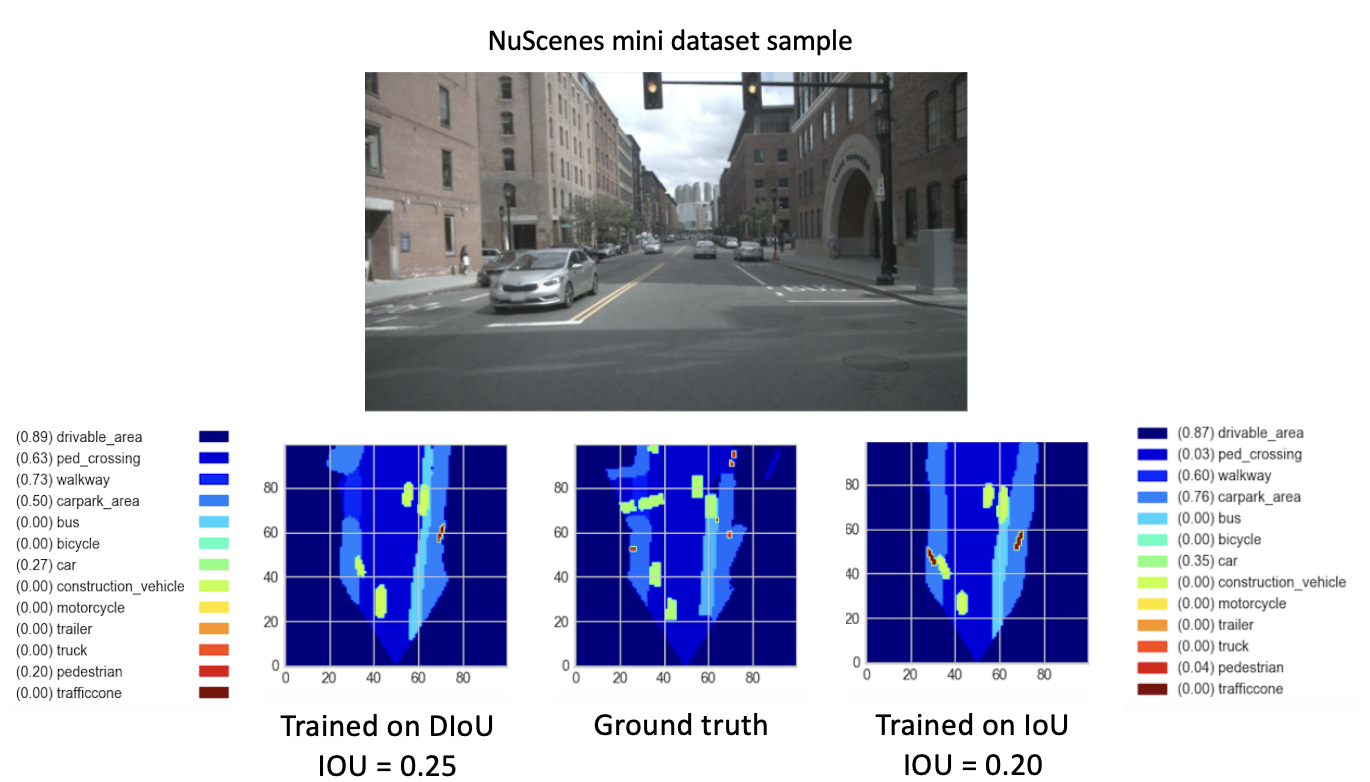
Hier, die

Diese Ergebnisse zeigen schließlich eine bessere Leistung des
Da wir nun über ein trainiertes Modell verfügen, können wir es verwenden, um das BEV anhand beliebiger Eingabebilder oder Videos vorherzusagen. Obwohl unser Ziel darin bestand, unsere Methode in der Abschlussdemo des Kurses zu implementieren, waren die abgeleiteten Karten aus der Vogelperspektive leider nicht ausreichend leistungsfähig. Die folgende Abbildung zeigt das Inferenzergebnis für eines der bereitgestellten Testvideos (siehe Testvideos).

Wir glauben, dass dieser Leistungsmangel bei der Inferenz auf die folgenden Parameter zurückzuführen ist:
Obwohl die Passage von
Eine Möglichkeit ist die Umsetzung
Der
Darüber hinaus nimmt der Regressionsfehler für CIoU laut den in diesem Artikel [2] durchgeführten Untersuchungen schneller ab als für die anderen und konvergiert
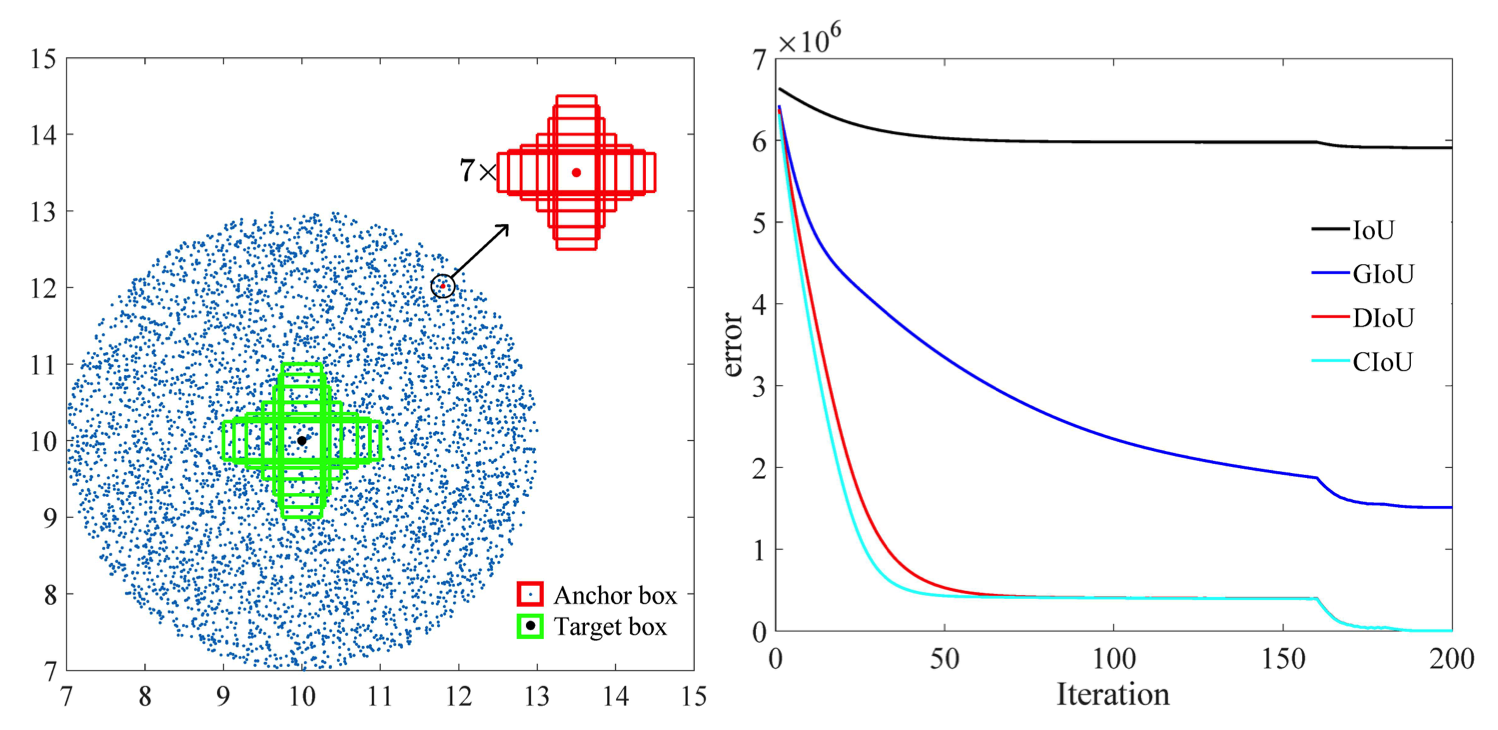
Eine weitere Möglichkeit besteht darin, anhand von Datensätzen zu trainieren, die viele Umgebungen enthalten, um eine bessere Darstellung von Fußgängern und Fahrrädern zu erhalten.
Um unsere Hypothese wirklich zu validieren, könnte schließlich ein Validierungslauf für den gesamten NuScenes-Datensatz durchgeführt und die Fußgänger-IoUs der beiden Modelle verglichen werden.
[1] Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, Dongwei Ren (2020). Distanz-IoU-Verlust: Schnelleres und besseres Lernen für die Bounding-Box-Regression https://arxiv.org/pdf/1911.08287.pdf
[2] Zhaohui Zheng, Ping Wang, Dongwei Ren, Wei Liu, Rongguang Ye, Qinghua Hu, Wangmeng Zuo (2021). Verbesserung geometrischer Faktoren beim Modelllernen und Inferenz zur Objekterkennung und Instanzsegmentierung https://arxiv.org/pdf/2005.03572.pdf


