This template can be used for both Azure AI Studio and Azure Machine Learning.It can be used for both AZURE and LOCAL execution.It supports all types of flow - python Class flows, Function flows and YAML flows.It supports Github, Azure DevOps and Jenkins CI/CD orchestration.It supports pure python based Evaluation as well using promptflow-evals package.It should be used for INNER-LOOP Experimentation and Evaluation.It should be used for OUTER-LOOP Deployment and Inferencing. NOTE: A new FAQ section is added to help Engineers, Data Scientist and developers find answers to general questions on configuring and using this template.
FAQs HIER
Large Language Model Operations (LLMOps) ist zum Grundstein für effizientes Prompt Engineering und LLM-induzierte Anwendungsentwicklung und -bereitstellung geworden. Da die Nachfrage nach LLM-basierten Anwendungen weiter steigt, benötigen Unternehmen einen zusammenhängenden und optimierten Prozess zur Verwaltung ihres End-to-End-Lebenszyklus.
Der Aufstieg von KI und großen Sprachmodellen (LLMs) hat verschiedene Branchen verändert und die Entwicklung innovativer Anwendungen mit menschenähnlichen Textverständnis- und Generierungsfunktionen ermöglicht. Diese Revolution hat neue Möglichkeiten in Bereichen wie Kundenservice, Inhaltserstellung und Datenanalyse eröffnet.
Da sich LLMs rasant weiterentwickeln, wird die Bedeutung von Prompt Engineering immer offensichtlicher. Prompt Engineering spielt eine entscheidende Rolle bei der Nutzung des vollen Potenzials von LLMs, indem es effektive Eingabeaufforderungen erstellt, die auf bestimmte Geschäftsszenarien zugeschnitten sind. Dieser Prozess ermöglicht es Entwicklern, maßgeschneiderte KI-Lösungen zu erstellen, wodurch KI für ein breiteres Publikum zugänglicher und nützlicher wird.
Es handelt sich um ein Experimentier- und Evaluierungsframework für Prompt Flow. Es handelt sich einfach nicht um CI/CD-Pipelines für Prompt Flow, obwohl es diese unterstützt. Es verfügt über umfangreiche Funktionen zum Experimentieren, Evaluieren, Bereitstellen und Überwachen von Prompt Flow. Es handelt sich um eine vollständige End-to-End-Lösung für die Operationalisierung von Prompt Flow.
Die Vorlage unterstützt sowohl Azure AI Studio als auch Azure Machine Learning. Je nach Konfiguration kann die Vorlage sowohl für Azure AI Studio als auch für Azure Machine Learning verwendet werden. Es bietet eine nahtlose Migrationserfahrung zum Experimentieren, Evaluieren und Bereitstellen von Prompt Flow über verschiedene Dienste hinweg.
Diese Vorlage unterstützt verschiedene Arten von Abläufen, sodass Sie Arbeitsabläufe basierend auf Ihren spezifischen Anforderungen definieren und ausführen können. Die beiden wichtigsten unterstützten Flow-Typen sind:
Flexible Abläufe
Gerichtete azyklische Graphen (DAG)-Flüsse
Eine der leistungsstarken Funktionen dieses Projekts ist seine Fähigkeit, den Flow-Typ automatisch zu erkennen und den Flow entsprechend auszuführen. Dadurch können Sie mit verschiedenen Durchflussarten experimentieren und diejenige auswählen, die Ihren Anforderungen am besten entspricht.
Diese Vorlage unterstützt:
Die Verwaltung großer sprachbasierter Abläufe, vom lokalen Experimentieren bis zur Produktionsbereitstellung, war alles andere als einfach und ist keine einheitliche Aufgabe.
Jeder Flow hat seinen eigenen Lebenszyklus, vom ersten Experiment bis zur Bereitstellung, und jede Phase bringt ihre eigenen Herausforderungen mit sich.
Organisationen haben häufig mit mehreren Abläufen gleichzeitig zu kämpfen, von denen jeder seine Ziele, Anforderungen und Komplexitäten hat. Ohne geeignete Verwaltungstools kann dies schnell überwältigend werden.
Dazu gehört die Handhabung mehrerer Abläufe und ihrer einzigartigen Lebenszyklen, das Experimentieren mit verschiedenen Konfigurationen und die Gewährleistung reibungsloser Bereitstellungen.
Hier kommt LLMOps mit Prompt Flow ins Spiel. LLMOps mit Prompt Flow ist eine „LLMOps-Vorlage und Anleitung“, die Sie beim Erstellen von LLM-infundierten Apps mit Prompt Flow unterstützt. Es bietet die folgenden Funktionen:
Zentralisiertes Code-Hosting: Dieses Repo unterstützt das Hosten von Code für mehrere Flows basierend auf dem Prompt-Flow und stellt ein einziges Repository für alle Ihre Flows bereit. Stellen Sie sich diese Plattform als ein einziges Repository vor, in dem sich Ihr gesamter Prompt-Flow-Code befindet. Es ist wie eine Bibliothek für Ihre Flows, die es einfach macht, verschiedene Projekte zu finden, darauf zuzugreifen und daran zusammenzuarbeiten.
Lebenszyklusmanagement: Jeder Flow verfügt über einen eigenen Lebenszyklus, der reibungslose Übergänge vom lokalen Experimentieren zur Produktionsbereitstellung ermöglicht.
Experimentieren mit Varianten und Hyperparametern: Experimentieren Sie mit mehreren Varianten und Hyperparametern und bewerten Sie Flussvarianten ganz einfach. Varianten und Hyperparameter sind wie Zutaten in einem Rezept. Mit dieser Plattform können Sie mit verschiedenen Kombinationen von Varianten über mehrere Knoten in einem Fluss hinweg experimentieren.
A/B-Bereitstellung: Implementieren Sie A/B-Bereitstellungen nahtlos, sodass Sie verschiedene Flow-Versionen mühelos vergleichen können. Genau wie bei herkömmlichen A/B-Tests für Websites erleichtert diese Plattform die A/B-Bereitstellung für schnelle Flow-Flows. Dies bedeutet, dass Sie verschiedene Versionen eines Flows mühelos in einer realen Umgebung vergleichen können, um festzustellen, welche die beste Leistung erbringt.
Viele-zu-viele-Datensatz-/Flow-Beziehungen: Platz für mehrere Datensätze für jeden Standard- und Bewertungsfluss, um Vielseitigkeit bei Flusstests und -bewertungen zu gewährleisten. Die Plattform ist so konzipiert, dass sie mehrere Datensätze für jeden Fluss aufnehmen kann.
Mehrere Bereitstellungsziele: Das Repo unterstützt die Bereitstellung von Flows für Kubernetes und Azure Managed Computing, gesteuert durch die Konfiguration, um sicherzustellen, dass Ihre Flows nach Bedarf skaliert werden können.
Umfassende Berichterstattung: Erstellen Sie detaillierte Berichte für jede Variantenkonfiguration, sodass Sie fundierte Entscheidungen treffen können. Bietet eine detaillierte Metrikerfassung für alle Varianten-Massenläufe und -Experimente und ermöglicht datengesteuerte Entscheidungen sowohl in CSV- als auch in HTML-Dateien.
Bietet BYOF (Bring-Your-Own-Flows). Eine vollständige Plattform für die Entwicklung mehrerer Anwendungsfälle im Zusammenhang mit LLM-basierten Anwendungen.
Bietet konfigurationsbasierte Entwicklung. Es ist nicht erforderlich, umfangreichen Boiler-Plate-Code zu schreiben.
Ermöglicht die Durchführung umgehender Experimente und Auswertungen sowohl lokal als auch in der Cloud.
Stellt Notebooks für die lokale Auswertung der Eingabeaufforderungen bereit. Bietet eine Funktionsbibliothek für lokale Experimente.
Endpunkttests innerhalb der Pipeline nach der Bereitstellung, um deren Verfügbarkeit und Bereitschaft zu überprüfen.
Bietet optionale Human-in-Loop zur Validierung von Eingabeaufforderungsmetriken vor der Bereitstellung.
LLMOps mit Prompt Flow bietet Funktionen sowohl für einfache als auch für komplexe LLM-infundierte Apps. Es ist vollständig an die Anforderungen der Anwendung anpassbar.
Jeder Anwendungsfall (Satz von Prompt-Flow-Standards und Bewertungsflows) sollte der hier gezeigten Ordnerstruktur folgen:
Darüber hinaus gibt es eine experiment.yaml -Datei, die den Anwendungsfall konfiguriert (weitere Details finden Sie in der Dateibeschreibung und den Spezifikationen). Es gibt auch eine Datei „sample-request.json“, die Testdaten zum Testen von Endpunkten nach der Bereitstellung enthält.
Der Ordner „.azure-pipelines“ enthält die allgemeinen Azure DevOps-Pipelines für die Plattform und alle Änderungen daran wirken sich auf die Ausführung aller Flows aus.
Der Ordner „.github“ enthält die Github-Workflows für die Plattform sowie die Anwendungsfälle. Dies unterscheidet sich ein wenig von Azure DevOps, da sich alle Github-Workflows zur Ausführung in diesem einzigen Ordner befinden sollten.
Der Ordner „.jenkins“ enthält die deklarativen Jenkins-Pipelines für die Plattform sowie die Anwendungsfälle und einzelnen Jobs.
Der Ordner „docs“ enthält Dokumentation für Schritt-für-Schritt-Anleitungen für Azure DevOps, Github Workflow und Jenkins-bezogene Konfiguration.
Der Ordner „llmops“ enthält den gesamten Code zur Flow-Ausführung, -Bewertung und -Bereitstellung.
Der Ordner „dataops“ enthält den gesamten Code für die Bereitstellung der Datenpipeline.
Der Ordner „local_execution“ enthält Python-Skripte zum lokalen Ausführen des Standard- und Evaluierungsablaufs.
Das Projekt umfasst 6 Beispiele, die verschiedene Szenarien demonstrieren:
Speicherort: ./web_classification Bedeutung: Demonstriert die Zusammenfassung von Website-Inhalten mit mehreren Varianten und demonstriert die Flexibilität und Anpassungsoptionen, die in der Vorlage verfügbar sind.
Speicherort: ./named_entity_recognition Bedeutung: Zeigt die Extraktion benannter Entitäten aus Text, die für verschiedene Aufgaben der Verarbeitung natürlicher Sprache und Informationsextraktion wertvoll ist.
Speicherort: ./math_coding Bedeutung: Zeigt die Fähigkeit, mathematische Berechnungen durchzuführen und Codeausschnitte zu generieren, und unterstreicht die Vielseitigkeit der Vorlage bei der Bearbeitung von Rechenaufgaben.
Speicherort: ./chat_with_pdf Bedeutung: Demonstriert eine Konversationsschnittstelle für die Interaktion mit PDF-Dokumenten und nutzt die Leistungsfähigkeit der Retrieval-Augmented Generation (RAG), um genaue und relevante Antworten bereitzustellen.
Speicherort: ./function_flows Bedeutung: Demonstriert die Generierung von Codeausschnitten basierend auf Benutzereingaben und zeigt das Potenzial für die Automatisierung von Codegenerierungsaufgaben auf.
Speicherort: ./class_flows Bedeutung: Präsentiert eine Chat-Anwendung, die mit klassenbasierten Flows erstellt wurde und die Strukturierung und Organisation komplexerer Konversationsschnittstellen veranschaulicht.
Das Repo hilft bei der Bereitstellung für Kubernetes, Kubernetes ARC, Azure Web Apps und AzureML Managed Computing sowie bei der A/B-Bereitstellung für AzureML Managed Computing.
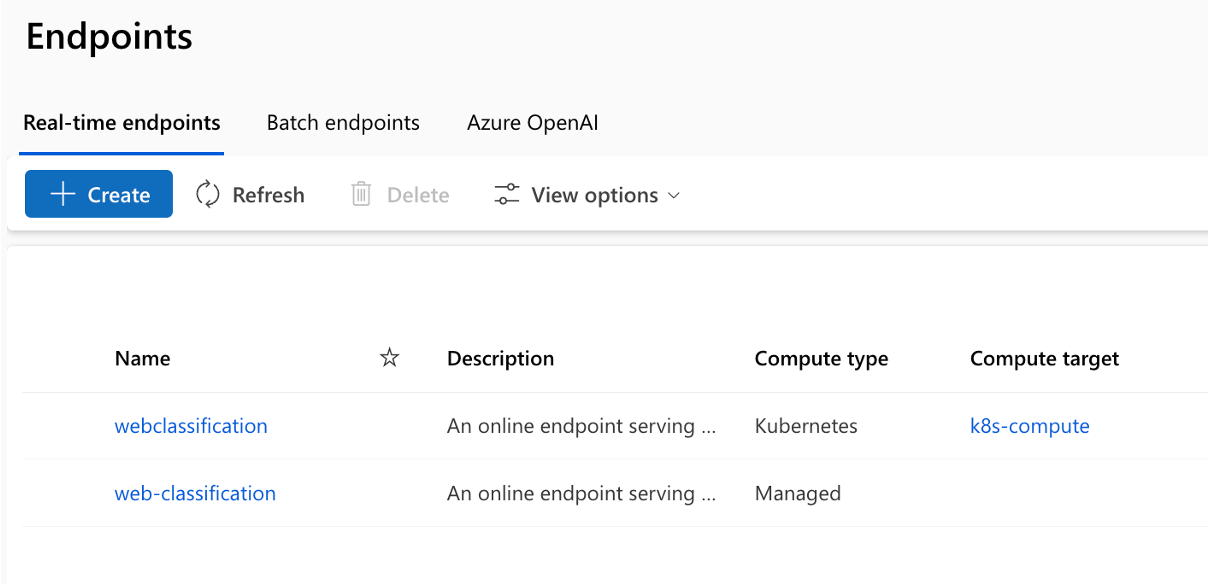
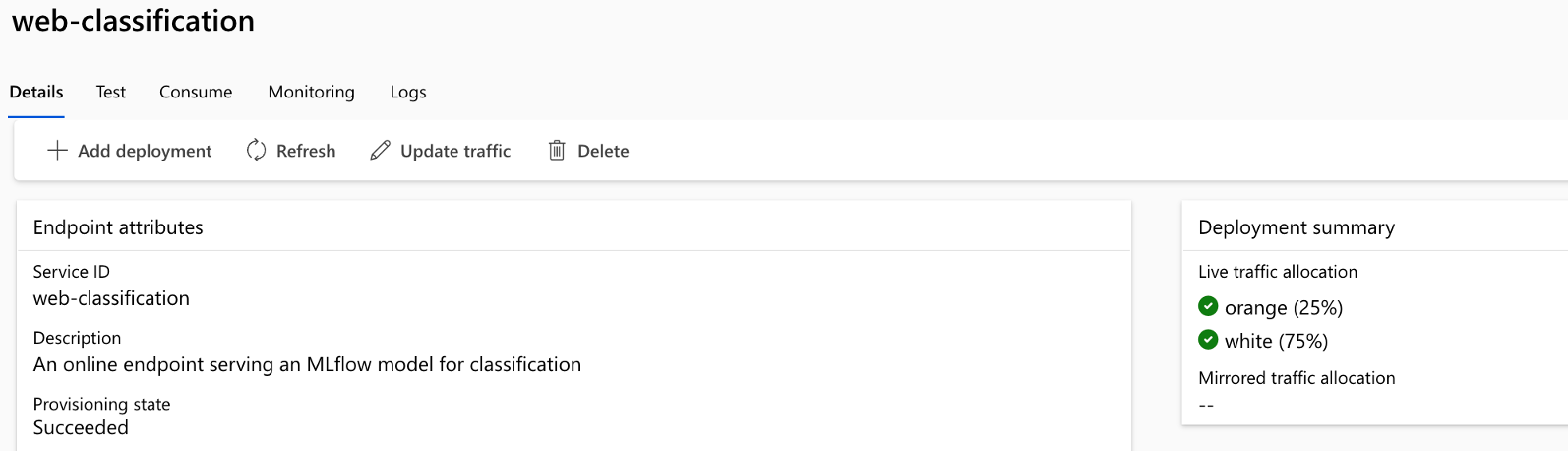
Die Pipeline-Ausführung besteht aus mehreren Phasen und Jobs in jeder Phase:
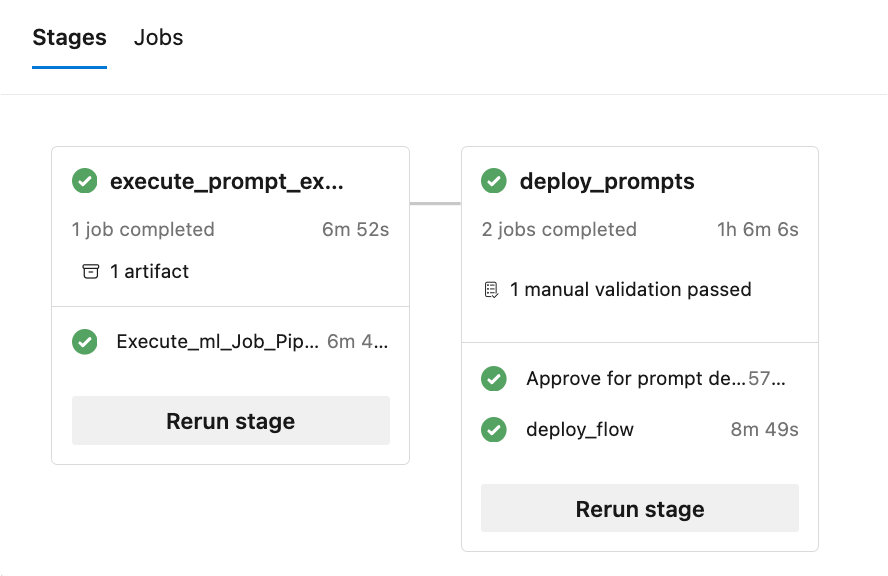
Das Repo generiert mehrere Berichte (es werden Experimente, Läufe und Metrikbeispiele angezeigt):


Um die Funktionen der lokalen Ausführung zu nutzen, führen Sie die folgenden Installationsschritte aus:
git clone https://github.com/microsoft/llmops-promptflow-template.gitaoai . Fügen Sie eine Zeile aoai={"api_key": "","api_base": "","api_type": "azure","api_version": "2023-03-15-preview"} mit aktualisierten Werten für api_key und api_base hinzu. Wenn in Ihren Flows zusätzliche Verbindungen mit unterschiedlichen Namen verwendet werden, sollten diese entsprechend hinzugefügt werden. Derzeit wird der Fluss mit AzureOpenAI als unterstütztem Anbieter unterstützt. experiment_name=
connection_name_1={ " api_key " : " " , " api_base " : " " , " api_type " : " azure " , " api_version " : " 2023-03-15-preview " }
connection_name_2={ " api_key " : " " , " api_base " : " " , " api_type " : " azure " , " api_version " : " 2023-03-15-preview " }python -m pip install promptflow promptflow-tools promptflow-sdk jinja2 promptflow[azure] openai promptflow-sdk[builtins] python-dotenv
Bringen Sie Ihre Flows in die Vorlage ein oder schreiben Sie sie basierend auf der Dokumentation hier in die Vorlage.
Schreiben Sie Python-Skripte ähnlich den bereitgestellten Beispielen im Ordner „local_execution“.
DataOps kombiniert Aspekte von DevOps, agilen Methoden und Datenverwaltungspraktiken, um den Prozess der Datenerfassung, -verarbeitung und -analyse zu optimieren. DataOps kann dazu beitragen, Disziplin beim Aufbau der für die LLM-App-Entwicklung erforderlichen Datensätze (Schulung, Experimente, Bewertung usw.) zu schaffen.
Die Datenpipelines werden von den prompten Engineering-Abläufen getrennt gehalten. Datenpipelines erstellen die Datensätze und die Datensätze werden als Datenbestände in Azure ML registriert, damit die Flüsse sie nutzen können. Dieser Ansatz hilft dabei, verschiedene Teile des Systems unabhängig voneinander zu skalieren und Fehler zu beheben.
Einzelheiten zu den ersten Schritten mit DataOps finden Sie in diesem Dokument – So konfigurieren Sie DataOps.
Dieses Projekt freut sich über Beiträge und Vorschläge. Für die meisten Beiträge müssen Sie einem Contributor License Agreement (CLA) zustimmen, in dem Sie erklären, dass Sie das Recht haben, uns die Rechte zur Nutzung Ihres Beitrags zu gewähren, und dies auch tatsächlich tun. Weitere Informationen finden Sie unter https://cla.opensource.microsoft.com.
Wenn Sie eine Pull-Anfrage einreichen, ermittelt ein CLA-Bot automatisch, ob Sie eine CLA bereitstellen müssen, und schmückt die PR entsprechend (z. B. Statusprüfung, Kommentar). Folgen Sie einfach den Anweisungen des Bots. Sie müssen dies nur einmal für alle Repos tun, die unsere CLA verwenden.
Dieses Projekt hat den Microsoft Open Source Verhaltenskodex übernommen. Weitere Informationen finden Sie in den FAQ zum Verhaltenskodex oder wenden Sie sich bei weiteren Fragen oder Kommentaren an [email protected].
Dieses Projekt kann Marken oder Logos für Projekte, Produkte oder Dienstleistungen enthalten. Die autorisierte Nutzung von Microsoft-Marken oder -Logos unterliegt den Marken- und Markenrichtlinien von Microsoft und muss diesen entsprechen. Die Verwendung von Microsoft-Marken oder -Logos in geänderten Versionen dieses Projekts darf keine Verwirrung stiften oder eine Sponsorschaft durch Microsoft implizieren. Jegliche Verwendung von Marken oder Logos Dritter unterliegt den Richtlinien dieser Drittanbieter.
Dieses Projekt hat den Microsoft Open Source Verhaltenskodex übernommen. Weitere Informationen finden Sie in den FAQ zum Verhaltenskodex oder wenden Sie sich bei weiteren Fragen oder Kommentaren an [email protected].
Urheberrecht (c) Microsoft Corporation. Alle Rechte vorbehalten.
Lizenziert unter der MIT-Lizenz.


