hercules
v10.7.2
Schnelle, aufschlussreiche und hochgradig anpassbare Git-Verlaufsanalyse.
Übersicht • Verwendung • Installation • Beiträge • Lizenz
Hercules ist eine erstaunlich schnelle und hochgradig anpassbare Git-Repository-Analyse-Engine, die in Go geschrieben wurde. Batterien sind im Lieferumfang enthalten. Unterstützt von go-git.
Hinweis (November 2020): Der Hauptautor ist aus der Schwebe zurück und nimmt die Entwicklung schrittweise wieder auf. Sehen Sie sich die Roadmap an.
Es gibt zwei Befehlszeilentools: hercules und labours . Das erste ist ein in Go geschriebenes Programm, das ein Git-Repository verwendet und einen gerichteten azyklischen Graphen (DAG) von Analyseaufgaben über den gesamten Commit-Verlauf ausführt. Das zweite ist ein Python-Skript, das einige vordefinierte Diagramme über den gesammelten Daten anzeigt. Diese beiden Werkzeuge werden normalerweise zusammen durch ein Rohr verwendet. Mit dem Plugin-System ist es möglich, benutzerdefinierte Analysen zu schreiben. Es ist auch möglich, mehrere Analyseergebnisse zusammenzuführen – relevant für Organisationen. Der analysierte Commit-Verlauf umfasst Verzweigungen, Zusammenführungen usw.
Hercules wurde erfolgreich für mehrere interne Projekte bei source{d} eingesetzt. Es gibt Blogbeiträge: 1, 2 und eine Präsentation. Bitte tragen Sie dazu bei, indem Sie testen, Fehler beheben, neue Analysen hinzufügen oder prahlerisch programmieren!
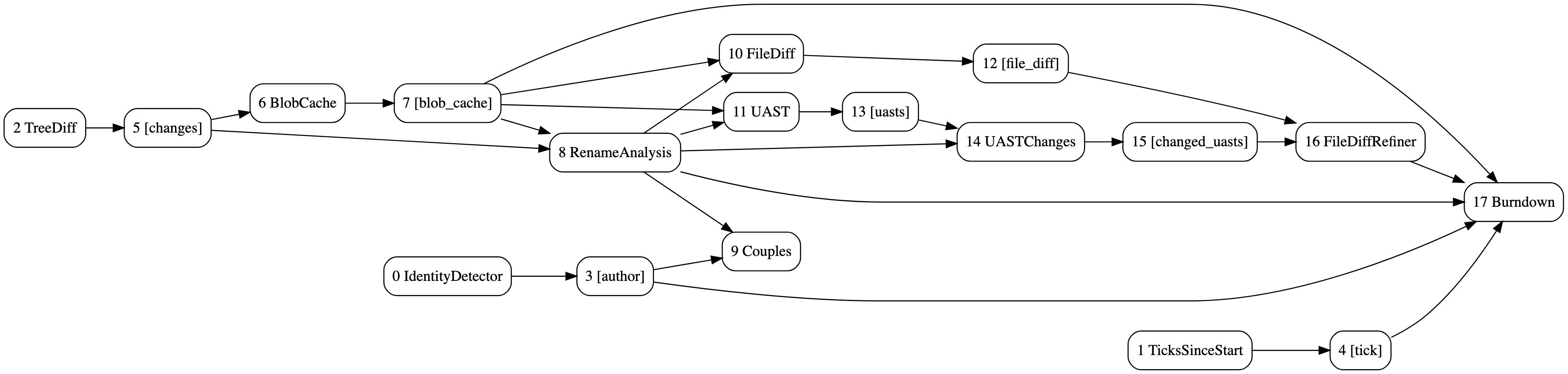
Die DAG von Burndown- und Paaranalysen mit UAST-Diff-Verfeinerung. Erstellt mit hercules --burndown --burndown-people --couples --feature=uast --dry-run --dump-dag doc/dag.dot https://github.com/src-d/hercules
Torvalds/Linux-Line-Burndown (Granularität 30, Sampling 30, erneutes Sampling nach Jahr). Generiert mit hercules --burndown --first-parent --pb https://github.com/torvalds/linux | labours -f pb -m burndown-project in 1h 40min.
Holen Sie sich hercules Binärdatei von der Seite „Releases“. labours ist von PyPi aus installierbar:
pip3 install labours
pip3 ist der Python-Paketmanager.
Numpy und Scipy können unter Windows über http://www.lfd.uci.edu/~gohlke/pythonlibs/ installiert werden.
Sie benötigen Go (>= v1.11) und protoc .
git clone https://github.com/src-d/hercules && cd hercules
make
pip3 install -e ./python
Es ist möglich, Hercules als GitHub-Aktion auszuführen: Hercules auf dem GitHub Marketplace. Bitte beachten Sie den Beispiel-Workflow, der die Einrichtung veranschaulicht.
...sind herzlich willkommen! Siehe MITTEILUNG und Verhaltenskodex.
Apache 2.0
Die nützlichste und zuverlässig aktuellste Befehlszeilenreferenz:
hercules --help
Einige Beispiele:
# Use "memory" go-git backend and display the burndown plot. "memory" is the fastest but the repository's git data must fit into RAM.
hercules --burndown https://github.com/go-git/go-git | labours -m burndown-project --resample month
# Use "file system" go-git backend and print some basic information about the repository.
hercules /path/to/cloned/go-git
# Use "file system" go-git backend, cache the cloned repository to /tmp/repo-cache, use Protocol Buffers and display the burndown plot without resampling.
hercules --burndown --pb https://github.com/git/git /tmp/repo-cache | labours -m burndown-project -f pb --resample raw
# Now something fun
# Get the linear history from git rev-list, reverse it
# Pipe to hercules, produce burndown snapshots for every 30 days grouped by 30 days
# Save the raw data to cache.yaml, so that later is possible to labours -i cache.yaml
# Pipe the raw data to labours, set text font size to 16pt, use Agg matplotlib backend and save the plot to output.png
git rev-list HEAD | tac | hercules --commits - --burndown https://github.com/git/git | tee cache.yaml | labours -m burndown-project --font-size 16 --backend Agg --output git.png
labours -i /path/to/yaml ermöglicht das Lesen der Ausgabe von hercules , die auf der Festplatte gespeichert wurde.
Es ist möglich, das geklonte Repository auf der Festplatte zu speichern. Die anschließende Analyse kann im entsprechenden Verzeichnis ausgeführt werden, anstatt von Grund auf zu klonen:
# First time - cache
hercules https://github.com/git/git /tmp/repo-cache
# Second time - use the cache
hercules --some-analysis /tmp/repo-cache
Die Aktion erzeugt das Artefakt mit dem Namen hercules_charts . Da es derzeit nicht möglich ist, mehrere Dateien in ein Artefakt zu packen, werden alle Diagramme und Tensorflow-Projektordateien im inneren TAR-Archiv gepackt. Um die Einbettungen anzuzeigen, gehen Sie zu Projektor.tensorflow.org, klicken Sie auf „Laden“ und wählen Sie die beiden TSVs aus. Dann nutzen Sie UMAP oder T-SNE.
docker run --rm srcd/hercules hercules --burndown --pb https://github.com/git/git | docker run --rm -i -v $(pwd):/io srcd/hercules labours -f pb -m burndown-project -o /io/git_git.png
hercules --burndown
labours -m burndown-project
Zeilen-Burndown-Statistiken für das gesamte Repository. Genau das Gleiche, was git-of-theseus macht, aber viel schneller. Die Schuldzuweisung wird mithilfe eines benutzerdefinierten RB-Baum-Tracking-Algorithmus effizient und inkrementell durchgeführt, und während der Analyse wird nur das letzte Änderungsdatum aufgezeichnet.
Alle Abbrandanalysen hängen von den Werten für Granularität und Probenahme ab. Die Granularität ist die Anzahl der Tage, aus denen jedes Band im Stapel besteht. Unter Sampling versteht man die Häufigkeit, mit der der Burnout-Zustand erfasst wird. Je kleiner der Wert, desto glatter ist die Darstellung, aber desto mehr Arbeit wird geleistet.
Es besteht die Möglichkeit, die Bänder innerhalb labours erneut abzutasten, sodass Sie eine sehr genaue Verteilung definieren und diese auf unterschiedliche Weise visualisieren können. Außerdem werden durch Resampling die Bänder über periodische Grenzen hinweg, z. B. Monate oder Jahre, ausgerichtet. Nicht erneut abgetastete Bänder sind offenbar nicht ausgerichtet und beginnen mit dem Geburtsdatum des Projekts.
hercules --burndown --burndown-files
labours -m burndown-file
Burndown-Statistiken für jede Datei im Repository, die in der neuesten Revision aktiv ist.
Hinweis: Für jede Datei wird ein separates Diagramm erstellt. Sie möchten es nicht in einem Repository mit vielen Dateien ausführen.
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m burndown-person
Burndown-Statistiken für die Mitwirkenden des Repositorys. Wenn --people-dict nicht angegeben ist, werden die Identitäten durch den folgenden Algorithmus ermittelt:
Wenn --people-dict angegeben ist, sollte es auf eine Textdatei mit den benutzerdefinierten Identitäten verweisen. Das Format ist: Jede Zeile ist ein einzelner Entwickler, sie enthält alle passenden E-Mails und Namen, getrennt durch | . Der Fall wird ignoriert.
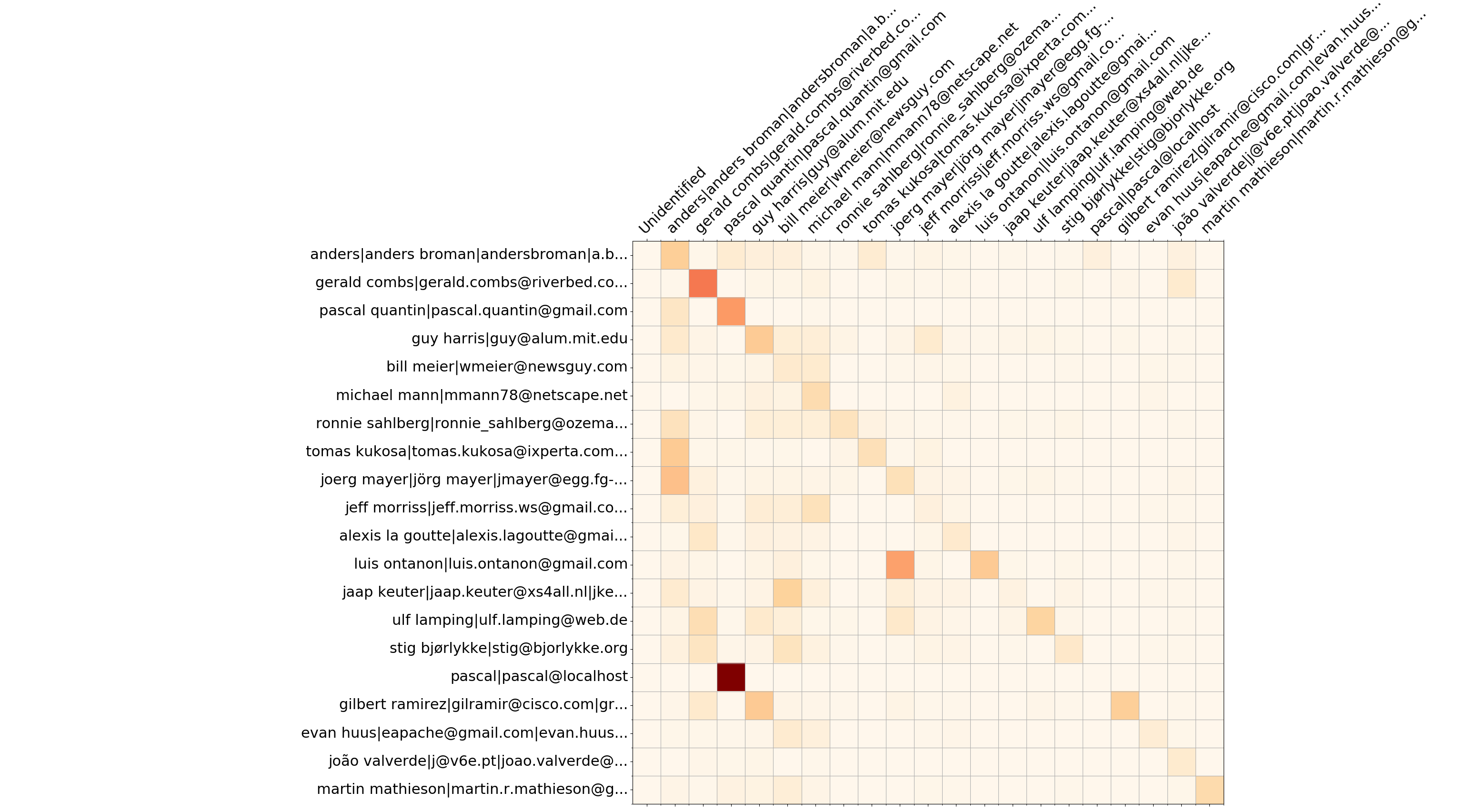
Wireshark Top 20 Entwickler – überschreibt Matrix
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m overwrites-matrix
Neben den Burndown-Informationen sammelt --burndown-people die hinzugefügten und gelöschten Zeilenstatistiken pro Entwickler. Dadurch kann visualisiert werden, wie viele von Entwickler A geschriebene Zeilen von Entwickler B entfernt werden. Dies zeigt die Zusammenarbeit zwischen Personen an und definiert Expertenteams.
Das Format ist die Matrix mit N Zeilen und (N+2) Spalten, wobei N die Anzahl der Entwickler ist.
--people-dict nicht angegeben ist, ist es immer 0). Die Reihenfolge der Entwickler wird im YAML-Knoten people_sequence gespeichert.
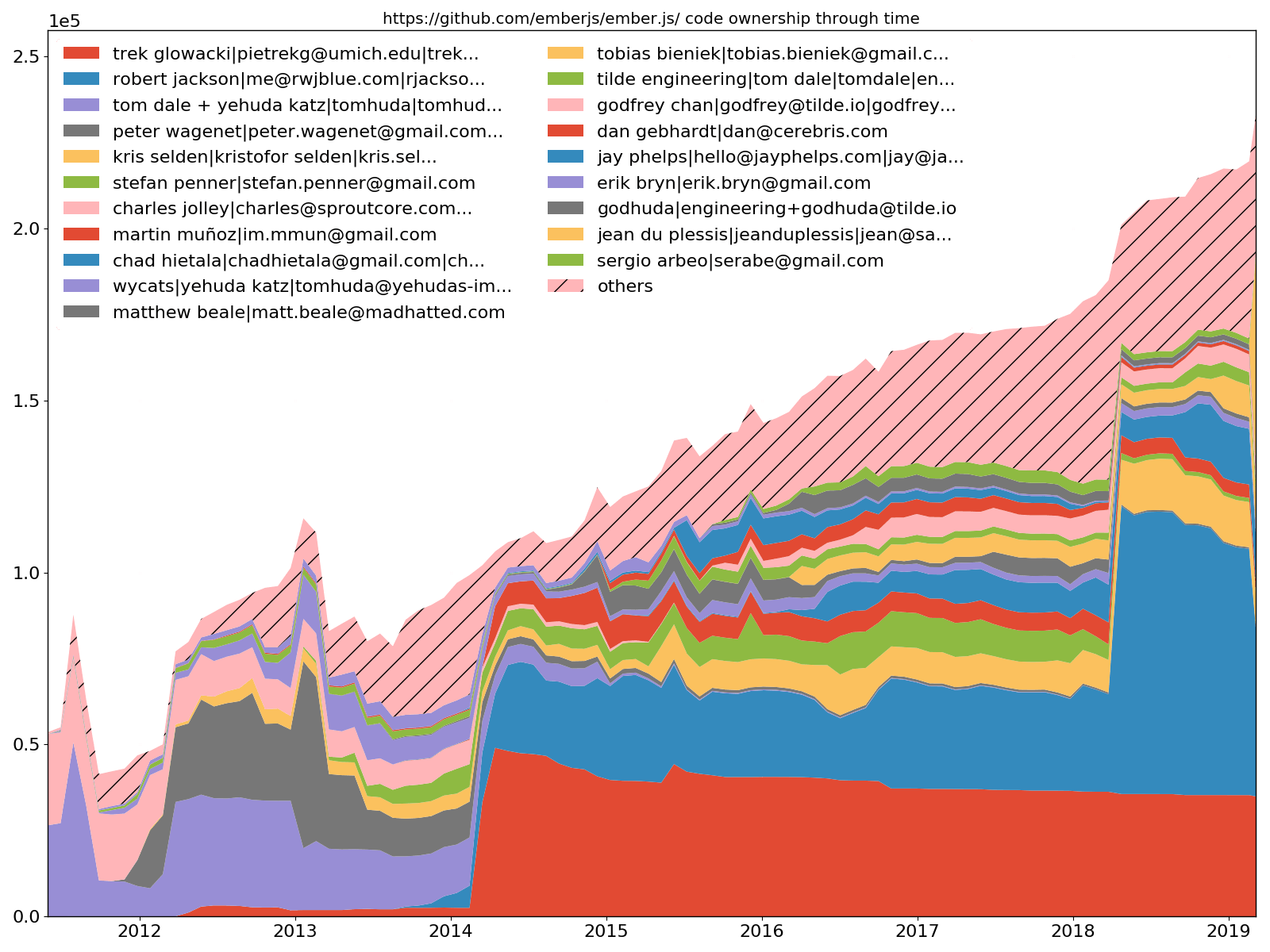
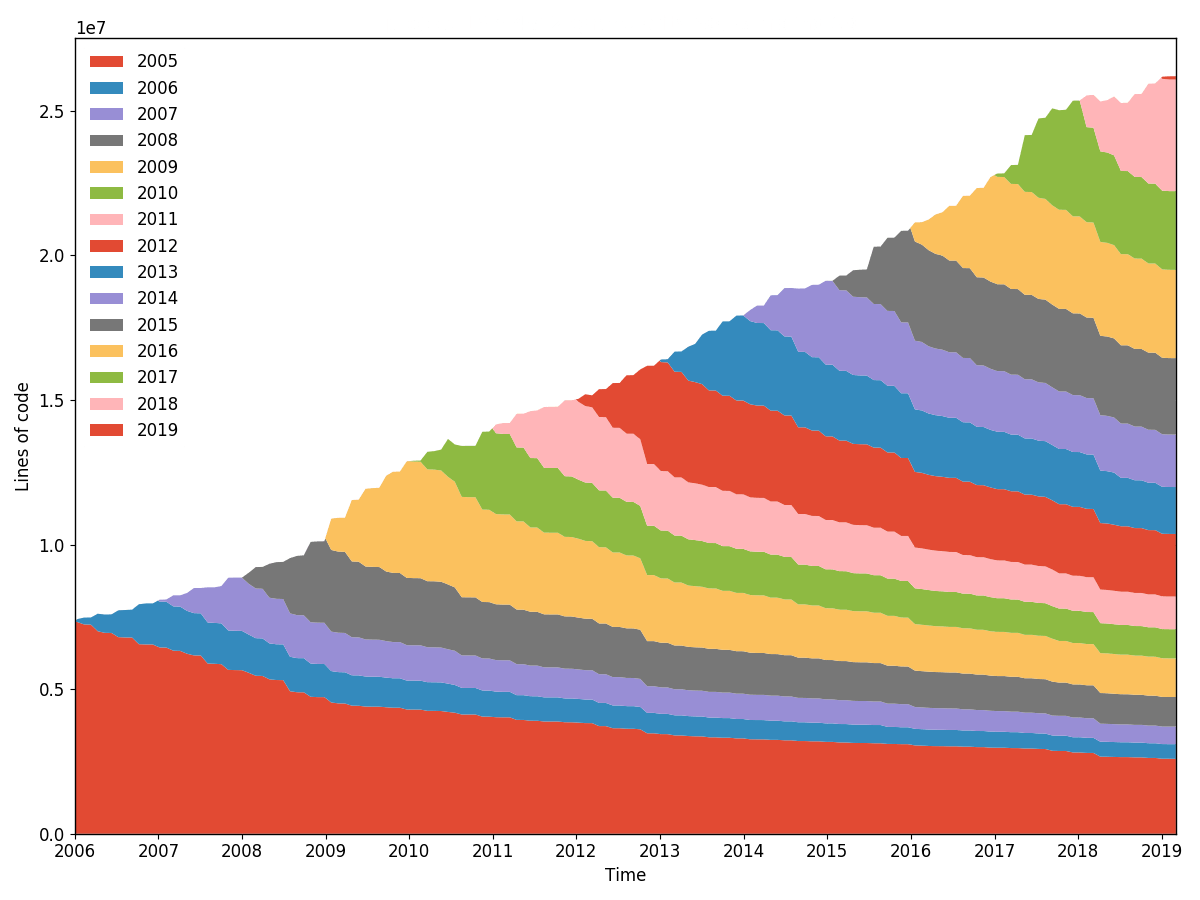
Ember.js Top-20-Entwickler – Code-Besitz
hercules --burndown --burndown-people [--people-dict=/path/to/identities]
labours -m ownership
--burndown-people ermöglicht auch das Zeichnen des Codeanteils durch ein zeitgestapeltes Flächendiagramm. Das heißt, wie viele Zeilen zu den erfassten Zeitpunkten für jeden identifizierten Entwickler aktiv sind.
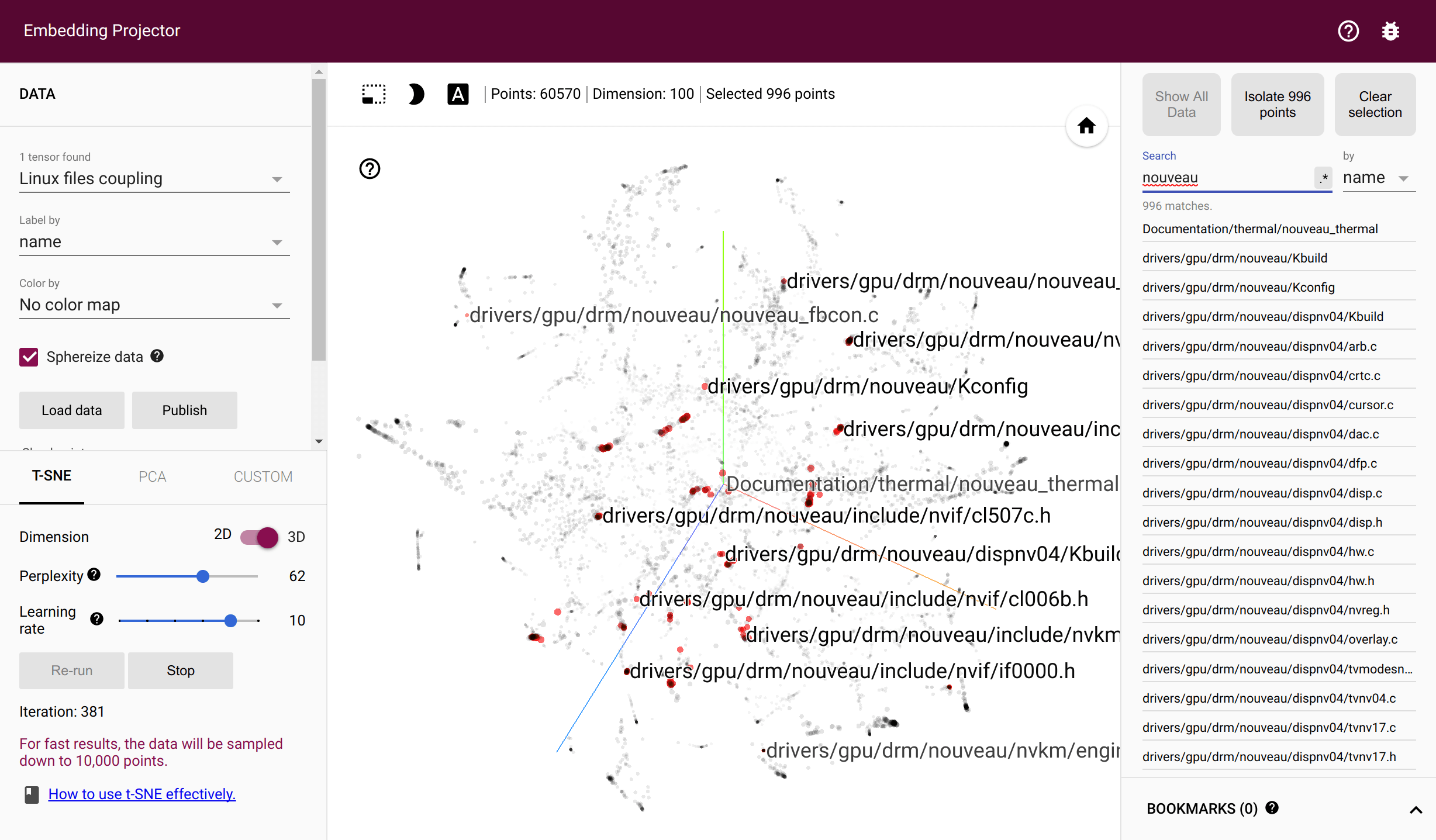
Kopplung von Torvalds/Linux-Dateien im Tensorflow-Projektor
hercules --couples [--people-dict=/path/to/identities]
labours -m couples -o <name> [--couples-tmp-dir=/tmp]
Wichtig : Tensorflow muss installiert sein. Bitte befolgen Sie die offiziellen Anweisungen.
Die Dateien werden gekoppelt, wenn sie im selben Commit geändert werden. Die Entwickler sind gekoppelt, wenn sie dieselbe Datei ändern. hercules zeichnet die Anzahl der Paare im gesamten Commit-Verlauf auf und gibt die beiden entsprechenden Kookkurrenzmatrizen aus. labours trainiert dann Schwenkeinbettungen – dichte Vektoren, die die Wahrscheinlichkeit des gleichzeitigen Auftretens über die euklidische Distanz widerspiegeln. Für das Training ist eine funktionierende Tensorflow-Installation erforderlich. Die Zwischendateien werden im temporären Systemverzeichnis oder --couples-tmp-dir gespeichert, sofern angegeben. Die trainierten Einbettungen werden in das aktuelle Arbeitsverzeichnis geschrieben, wobei der Name von -o abhängt. Das Ausgabeformat ist TSV und entspricht dem Tensorflow-Projektor, sodass die Dateien und Personen mit t-SNE, das in TF-Projektor implementiert ist, visualisiert werden können.
46 jinja2/compiler.py:visit_Template [FunctionDef]
42 jinja2/compiler.py:visit_For [FunctionDef]
34 jinja2/compiler.py:visit_Output [FunctionDef]
29 jinja2/environment.py:compile [FunctionDef]
27 jinja2/compiler.py:visit_Include [FunctionDef]
22 jinja2/compiler.py:visit_Macro [FunctionDef]
22 jinja2/compiler.py:visit_FromImport [FunctionDef]
21 jinja2/compiler.py:visit_Filter [FunctionDef]
21 jinja2/runtime.py:__call__ [FunctionDef]
20 jinja2/compiler.py:visit_Block [FunctionDef]
Dank Babelfish kann Hercules messen, wie oft jede Struktureinheit geändert wurde. Standardmäßig werden Funktionen betrachtet. Informationen zum Wechsel zu etwas anderem finden Sie im Semantic UAST XPath-Handbuch.
hercules --shotness [--shotness-xpath-*]
labours -m shotness
Die Paaranalyse lädt automatisch „Shotness“-Daten, sofern verfügbar.
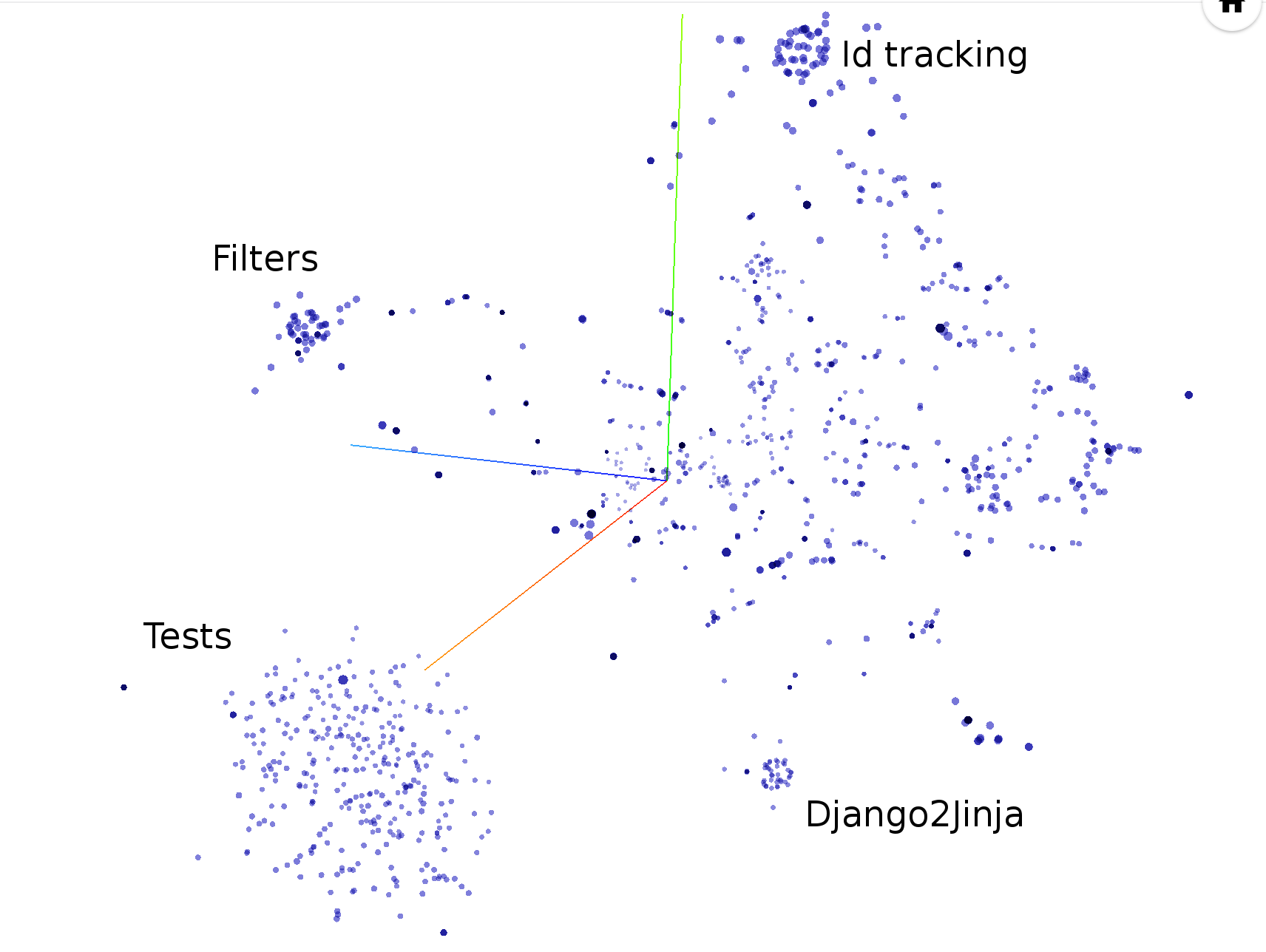
hercules --shotness --pb https://github.com/pallets/jinja | labours -m couples -f pb
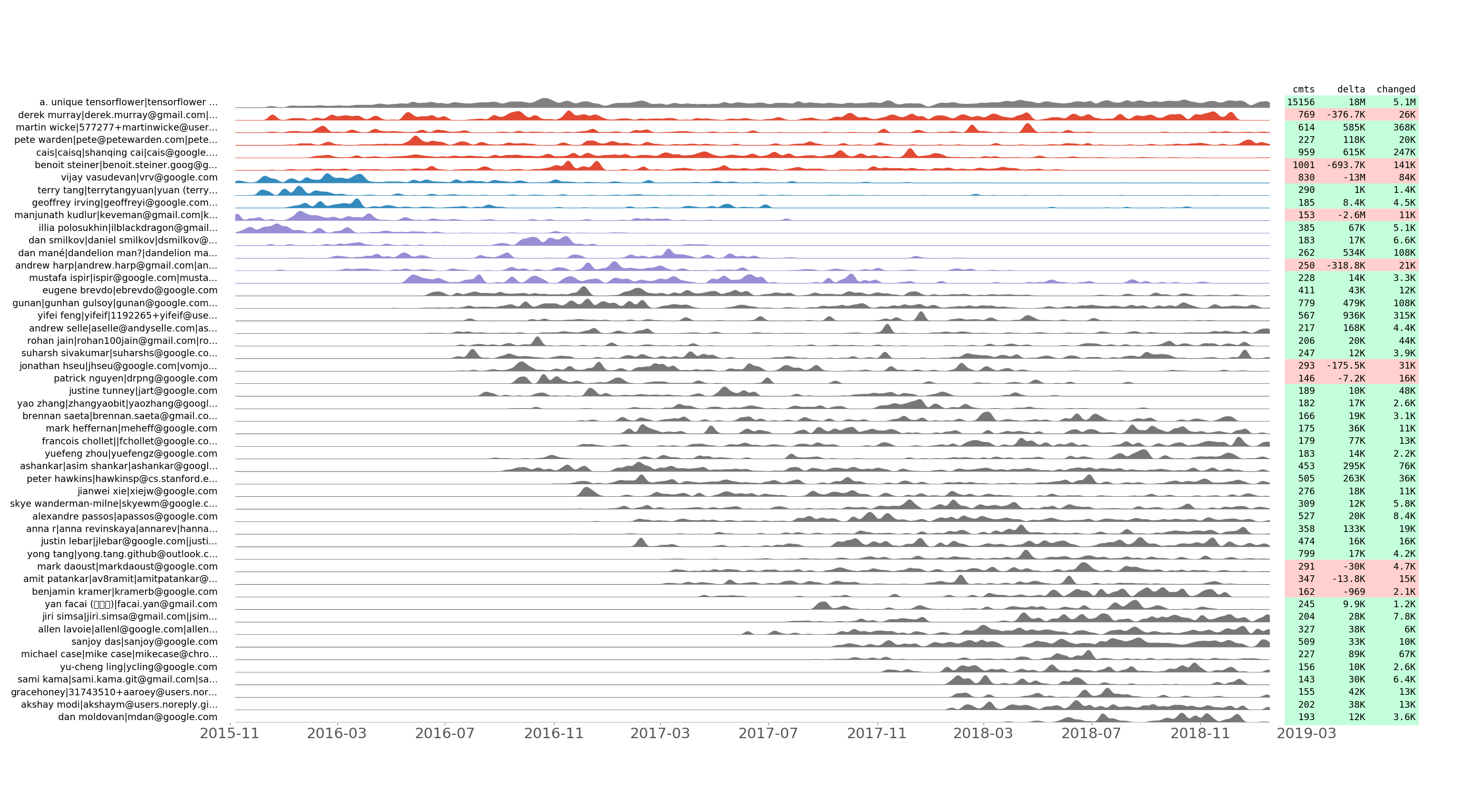
Tensorflow/Tensorflow-ausgerichtete Commit-Reihe der 50 besten Entwickler nach Commit-Nummer.
hercules --devs [--people-dict=/path/to/identities]
labours -m devs -o <name>
Wir zeichnen auf, wie viele Commits pro Tag für jeden Entwickler vorgenommen wurden sowie wie viele Zeilen hinzugefügt, entfernt und geändert wurden. Wir zeichnen die resultierende Commit-Zeitreihe auf und verwenden dabei ein paar Tricks, um die zeitliche Gruppierung darzustellen. Mit anderen Worten: Zwei benachbarte Commit-Serien sollten nach der Normalisierung ähnlich aussehen.
Diese Handlung ermöglicht es zu entdecken, wie sich das Entwicklungsteam im Laufe der Zeit entwickelt hat. Es werden auch „Commit-Flashmobs“ wie das Hacktoberfest gezeigt. Hier sind zum Beispiel die Erkenntnisse aus dem tensorflow/tensorflow -Diagramm oben:
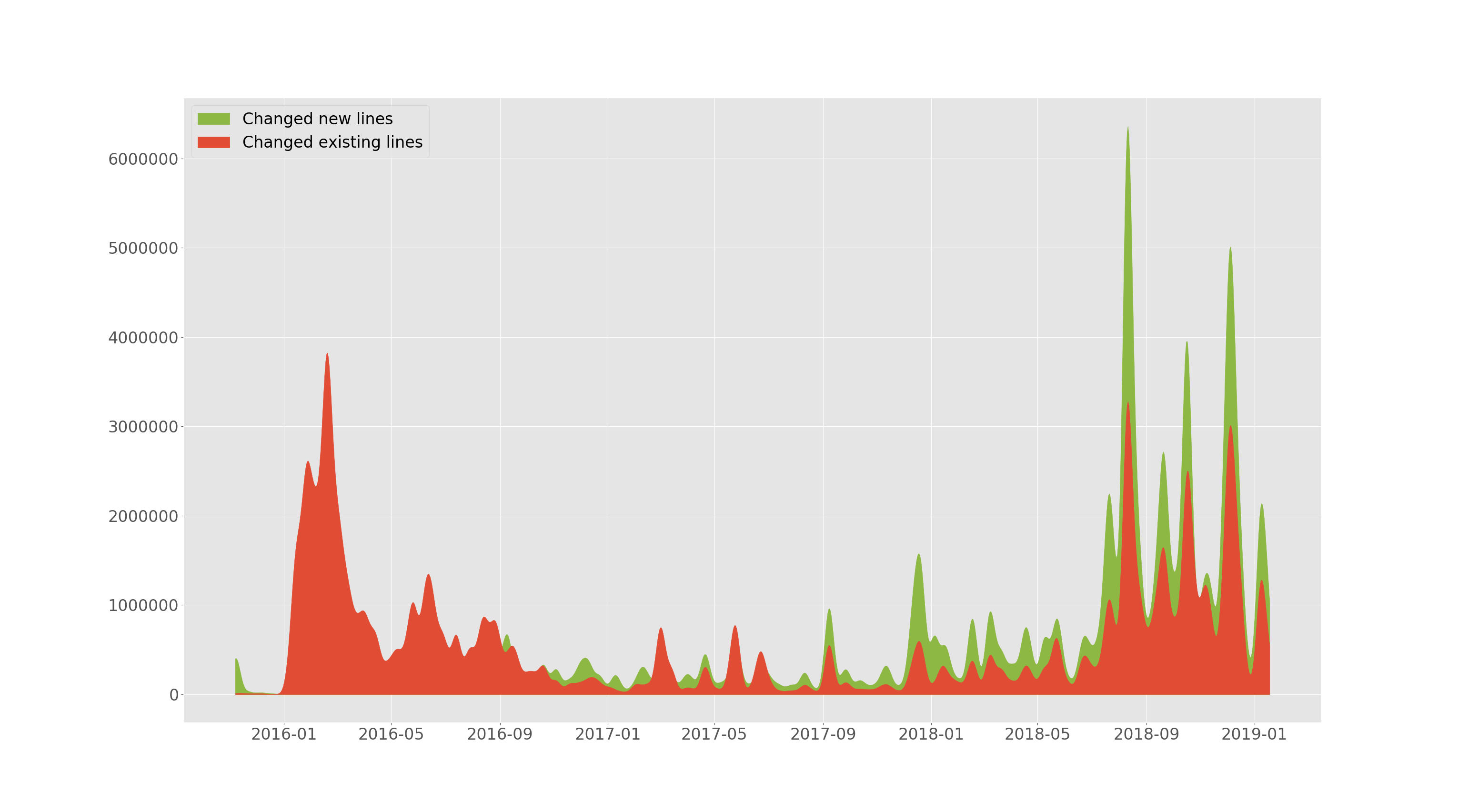
tensorflow/tensorflow hat im Laufe der Zeit Zeilen hinzugefügt und geändert.
hercules --devs [--people-dict=/path/to/identities]
labours -m old-vs-new -o <name>
--devs aus dem vorherigen Abschnitt ermöglicht es, darzustellen, wie viele Zeilen hinzugefügt wurden und wie viele bestehende im Laufe der Zeit geändert (gelöscht oder ersetzt) wurden. Dieses Diagramm ist geglättet.
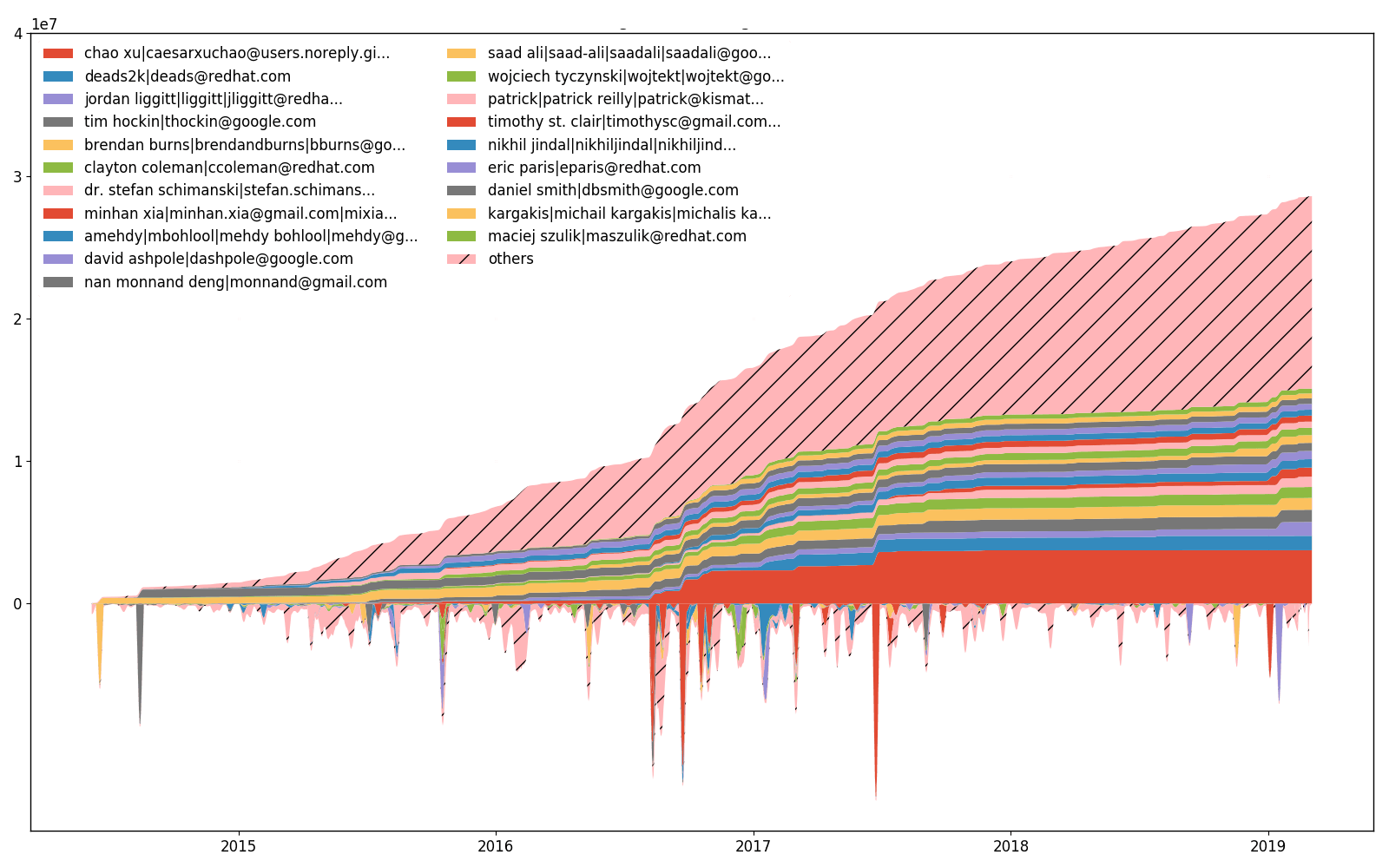
Kubernetes/Kubernetes-Bemühungen im Laufe der Zeit.
hercules --devs [--people-dict=/path/to/identities]
labours -m devs-efforts -o <name>
Außerdem ermöglicht --devs die Darstellung, wie viele Zeilen von jedem Entwickler geändert (hinzugefügt oder entfernt) wurden. Der obere Teil des Diagramms ist ein akkumulierter (integrierter) unterer Teil. Es ist unmöglich, für beide Teile den gleichen Maßstab zu haben, daher werden die niedrigeren Werte skaliert und daher gibt es keine unteren Y-Achsen-Teilstriche. Es gibt einen Unterschied zwischen dem Aufwandsdiagramm und dem Eigentumsdiagramm, obwohl sich ändernde Linien mit den Besitzlinien korrelieren.
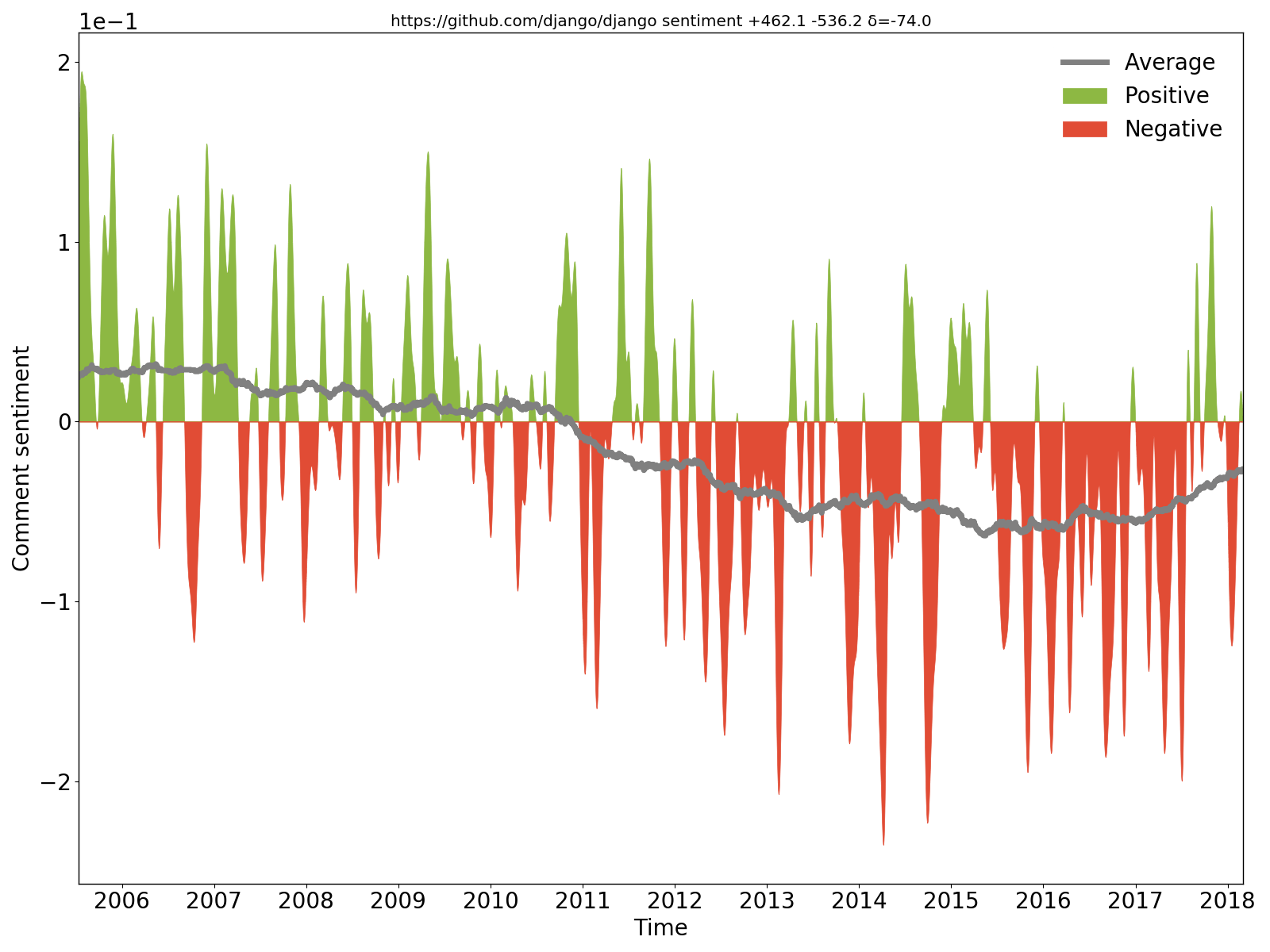
Es ist deutlich zu erkennen, dass die Kommentare von Django am Anfang positiv/optimistisch waren, später jedoch negativ/pessimistisch wurden.
hercules --sentiment --pb https://github.com/django/django | labours -m sentiment -f pb
Wir extrahieren bei jedem Commit neue und geänderte Kommentare aus dem Quellcode, wenden das wiederkehrende neuronale Allzweck-Sentiment-Netzwerk BiDiSentiment an und zeichnen die Ergebnisse auf. Erfordert libtensorflow. sadly, we need to hide the rect from the documentation finder for now Es ist negativ und Theano has a built-in optimization for logsumexp (...) so we can just write the expression directly . Erwarten Sie jedoch nicht zu viel – wie bereits geschrieben wurde, ist das Sentiment-Modell ein Allzweckmodell und die Codekommentare sind unterschiedlicher Natur, sodass es (vorerst) keine Magie gibt.
Hercules muss mit dem Tag „tensorflow“ erstellt werden – dies ist nicht standardmäßig der Fall:
make TAGS=tensorflow
Ein solcher Build erfordert libtensorflow .
hercules --burndown --burndown-files --burndown-people --couples --shotness --devs [--people-dict=/path/to/identities]
labours -m all
Hercules verfügt über ein Plugin-System und ermöglicht die Durchführung benutzerdefinierter Analysen. Siehe PLUGINS.md.
hercules combine ist der Befehl, der mehrere Analyseergebnisse im Protocol Buffers-Format zusammenfügt.
hercules --burndown --pb https://github.com/go-git/go-git > go-git.pb
hercules --burndown --pb https://github.com/src-d/hercules > hercules.pb
hercules combine go-git.pb hercules.pb | labours -f pb -m burndown-project --resample M
YAML unterstützt nicht den gesamten Bereich der Unicode-Zeichen und der Parser auf labours kann Ausnahmen auslösen. Filtern Sie die Ausgabe von hercules über fix_yaml_unicode.py um solche beleidigenden Zeichen zu verwerfen.
hercules --burndown --burndown-people https://github.com/... | python3 fix_yaml_unicode.py | labours -m people
Diese Optionen wirken sich auf alle Plots aus:
labours [--style=white|black] [--backend=] [--size=Y,X]
--style legt den allgemeinen Stil der Handlung fest (siehe labours --help ). --background ändert den Plothintergrund so, dass er entweder weiß oder schwarz ist. --backend wählt das Matplotlib-Backend. --size legt die Größe der Figur in Zoll fest. Der Standardwert ist 12,9 .
(erforderlich in macOS) Sie können das Standard-Matplotlib-Backend mit anheften
echo "backend: TkAgg" > ~/.matplotlib/matplotlibrc
Diese Optionen sind nur in Burndown-Diagrammen wirksam:
labours [--text-size] [--relative]
--text-size ändert die Schriftgröße, --relative aktiviert das gestreckte Burndown-Layout.
Es besteht die Möglichkeit, alle zum Zeichnen der Diagramme erforderlichen Informationen im JSON-Format auszugeben. Hängen Sie einfach .json an die Ausgabe an ( -o ) und schon sind Sie fertig. Das Datenformat ist nicht vollständig spezifiziert und hängt vom Python-Code ab, der es generiert. Jede JSON-Datei sollte "type" enthalten, der die Art der Handlung widerspiegelt.
--first-parent als Problemumgehung an.hercules für den Linux-Kernel im „Paare“-Modus beträgt 1,5 GB und das Parsen dauert mehr als eine Stunde bzw. 180 GB RAM. Die meisten Repositorys werden jedoch innerhalb einer Minute analysiert. Versuchen Sie stattdessen, Protokollpuffer zu verwenden ( hercules --pb und labours -f pb ). # Debian, Ubuntu
apt install libyaml-dev
# macOS
brew install yaml-cpp libyaml
# you might need to re-install pyyaml for changes to make effect
pip uninstall pyyaml
pip --no-cache-dir install pyyaml
Wenn das analysierte Repository groß ist und häufig Verzweigungen verwendet, schlägt die Sammlung der Burndown-Statistiken möglicherweise mit einem OOM fehl. Sie sollten Folgendes versuchen:
--skip-blacklist um die Analyse unerwünschter Dateien zu vermeiden. Es ist auch möglich, die --language einzuschränken.--hibernation-distance 10 --burndown-hibernation-threshold=1000 . Spielen Sie mit diesen beiden Zahlen, um direkt vor dem OOM in den Winterschlaf zu gehen.--burndown-hibernation-disk --burndown-hibernation-dir /path .--first-parent , du gewinnst. src-d/go-git zu go-git/go-git . Aktualisieren Sie die Codebasis, um sie mit der neuesten Go-Version kompatibel zu machen. 

