clearml agent
v1.9.2

ClearML Agent – MLOps/LLMOps leicht gemacht
MLOps/LLMOps-Planer- und Orchestrierungslösung, die Linux, macOS und Windows unterstützt
? ClearML is open-source - Leave a star to support the project! ?
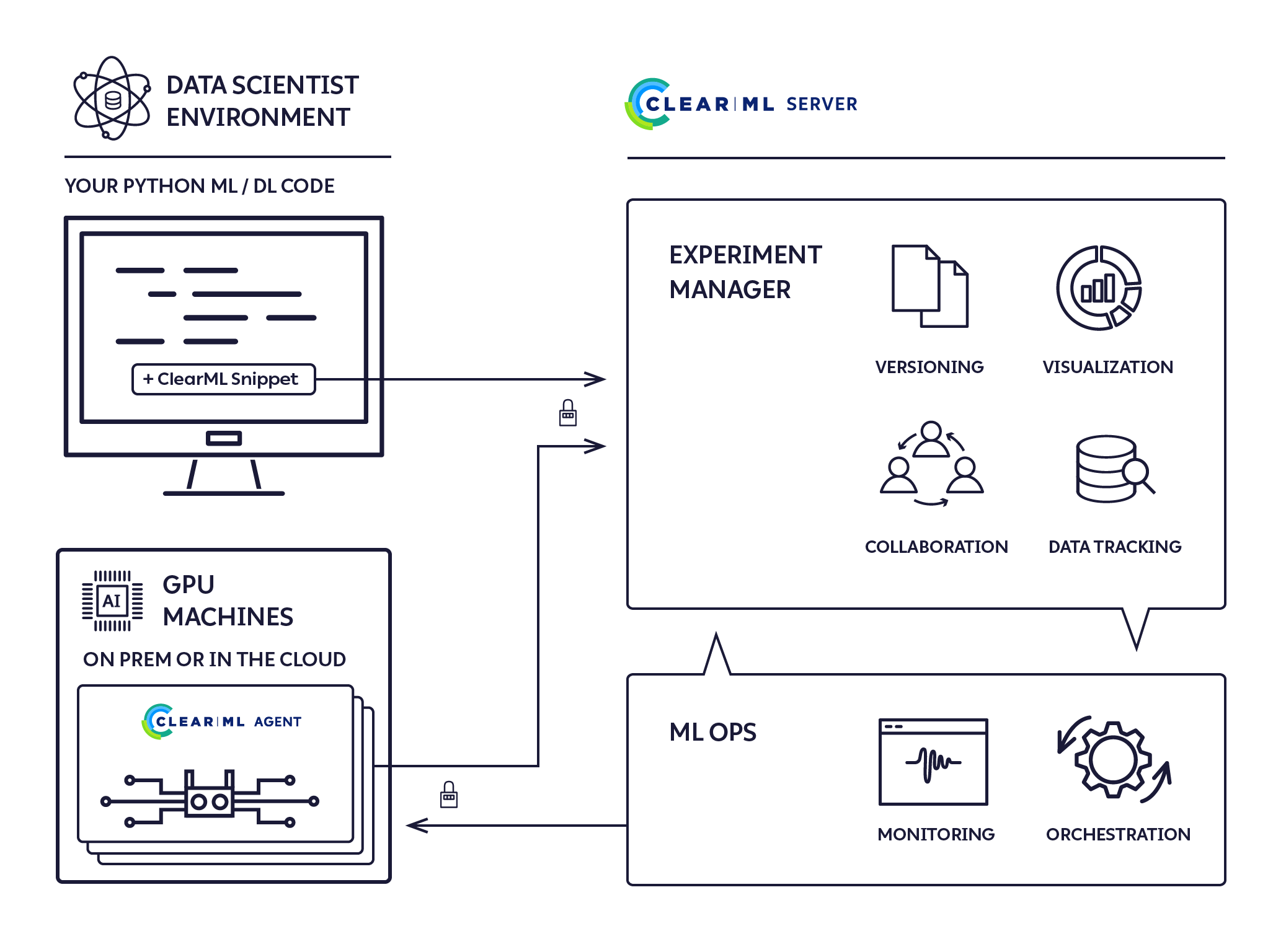
Es handelt sich um einen Fire-and-Forget-Ausführungsagenten ohne Konfiguration, der eine vollständige ML/DL-Clusterlösung bietet.
Vollständige Automatisierung in 5 Schritten
pip install clearml-agent (Installieren Sie den ClearML-Agenten auf einer beliebigen GPU-Maschine: lokal / in der Cloud / ...)„Alle Deep/Machine-Learning-DevOps, die Ihre Forschung braucht, und noch mehr … Denn dafür hat niemand Zeit.“
Testen Sie ClearML jetzt selbst gehostet oder als kostenloses Hosting 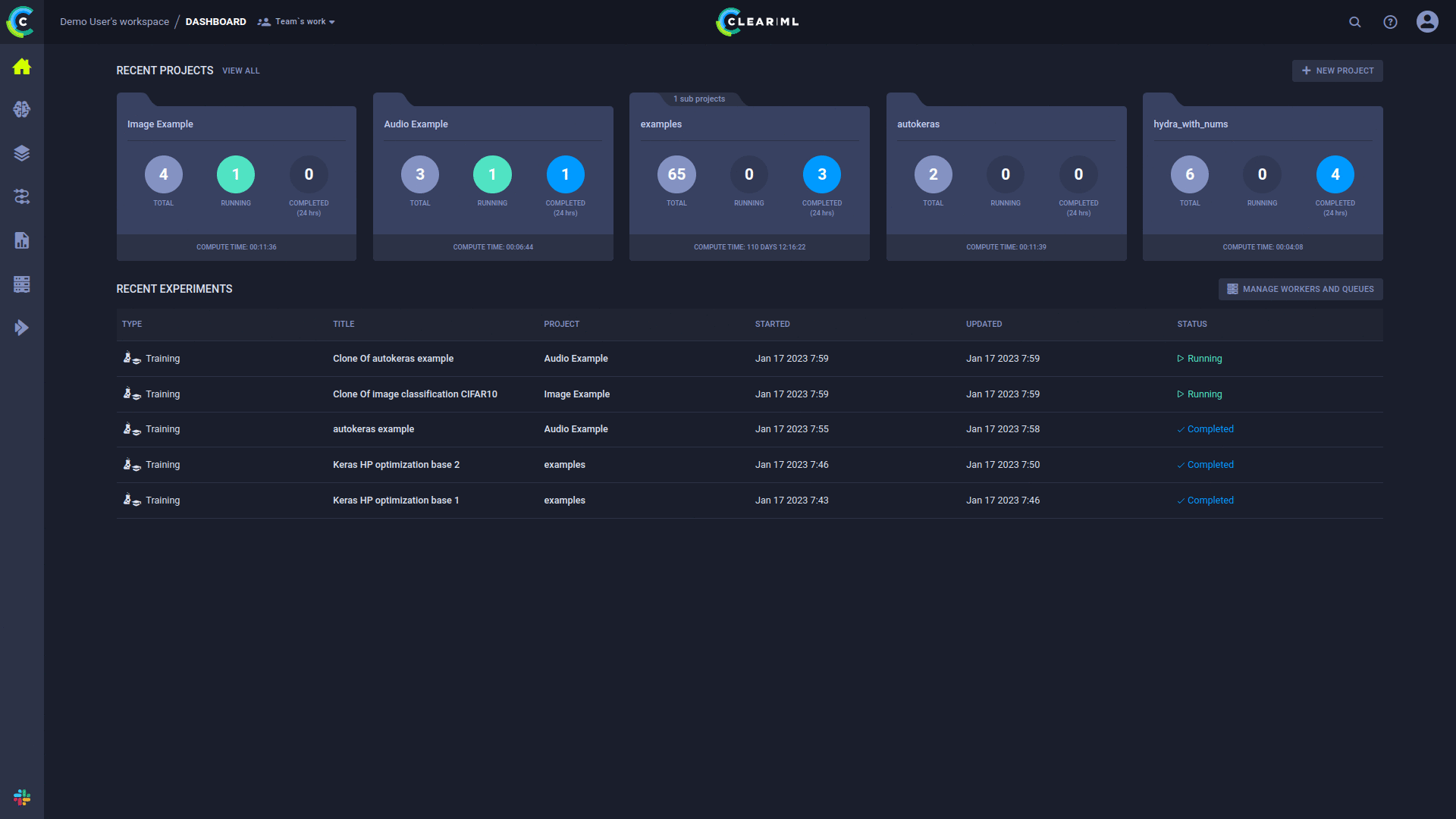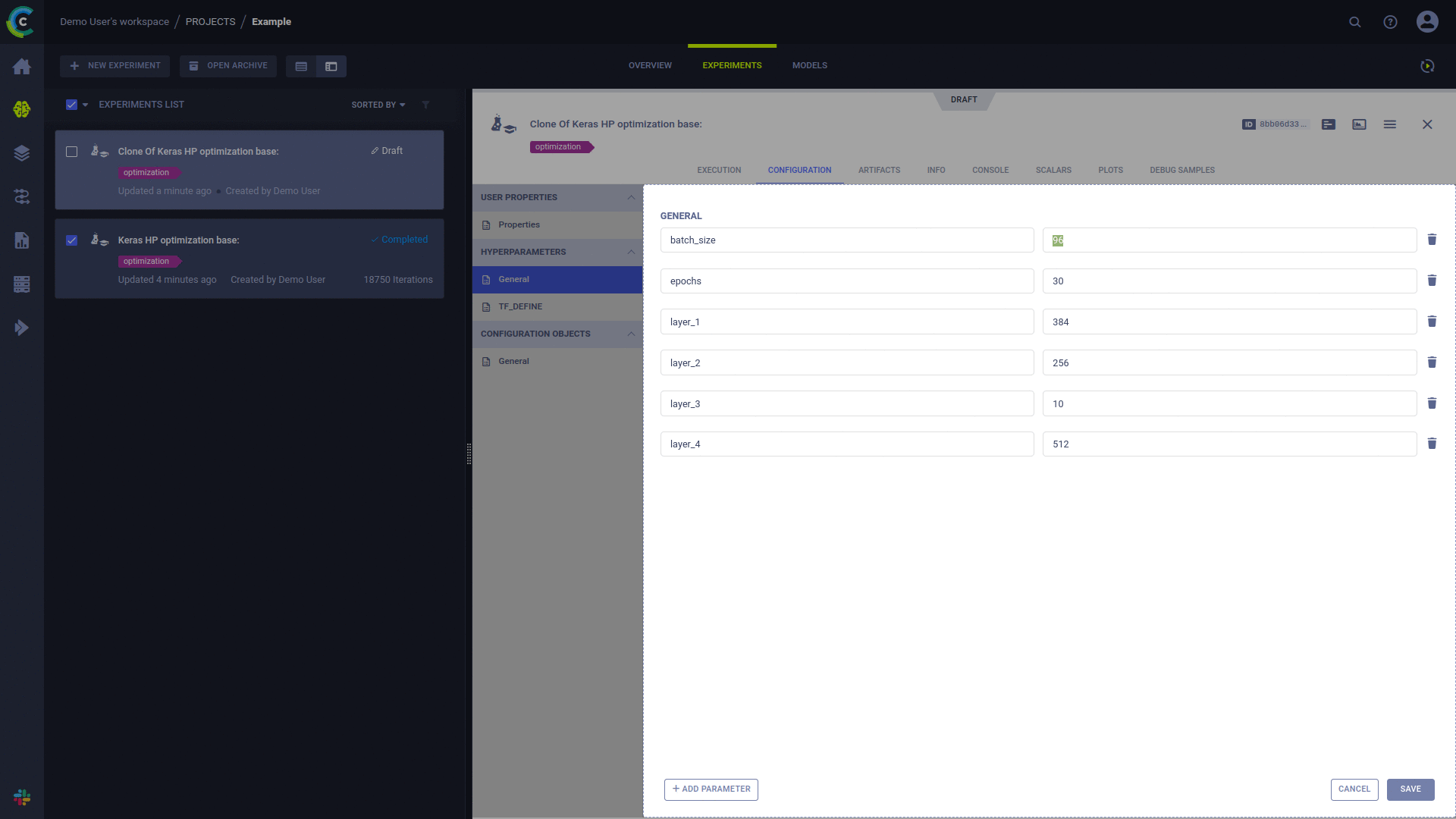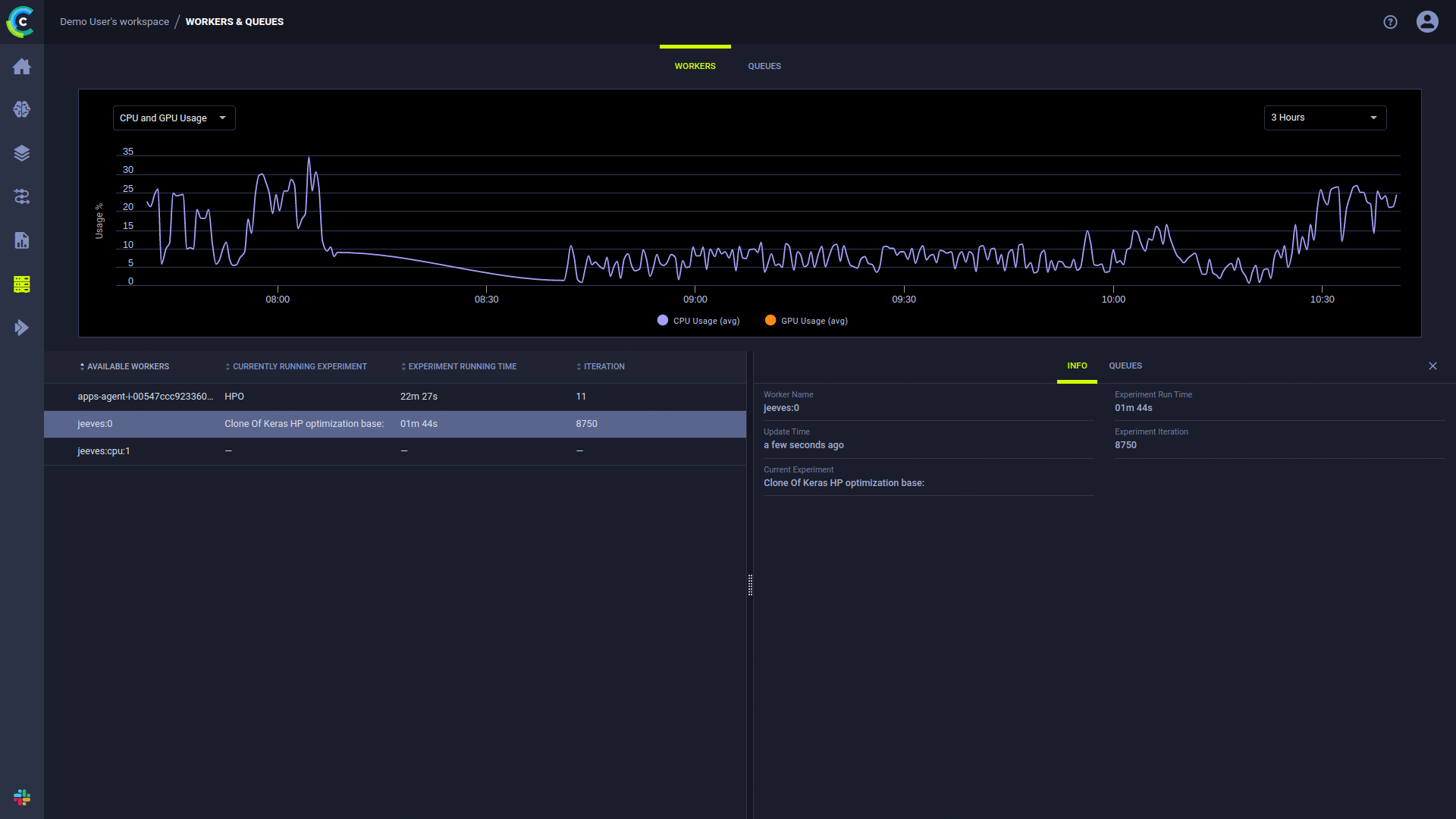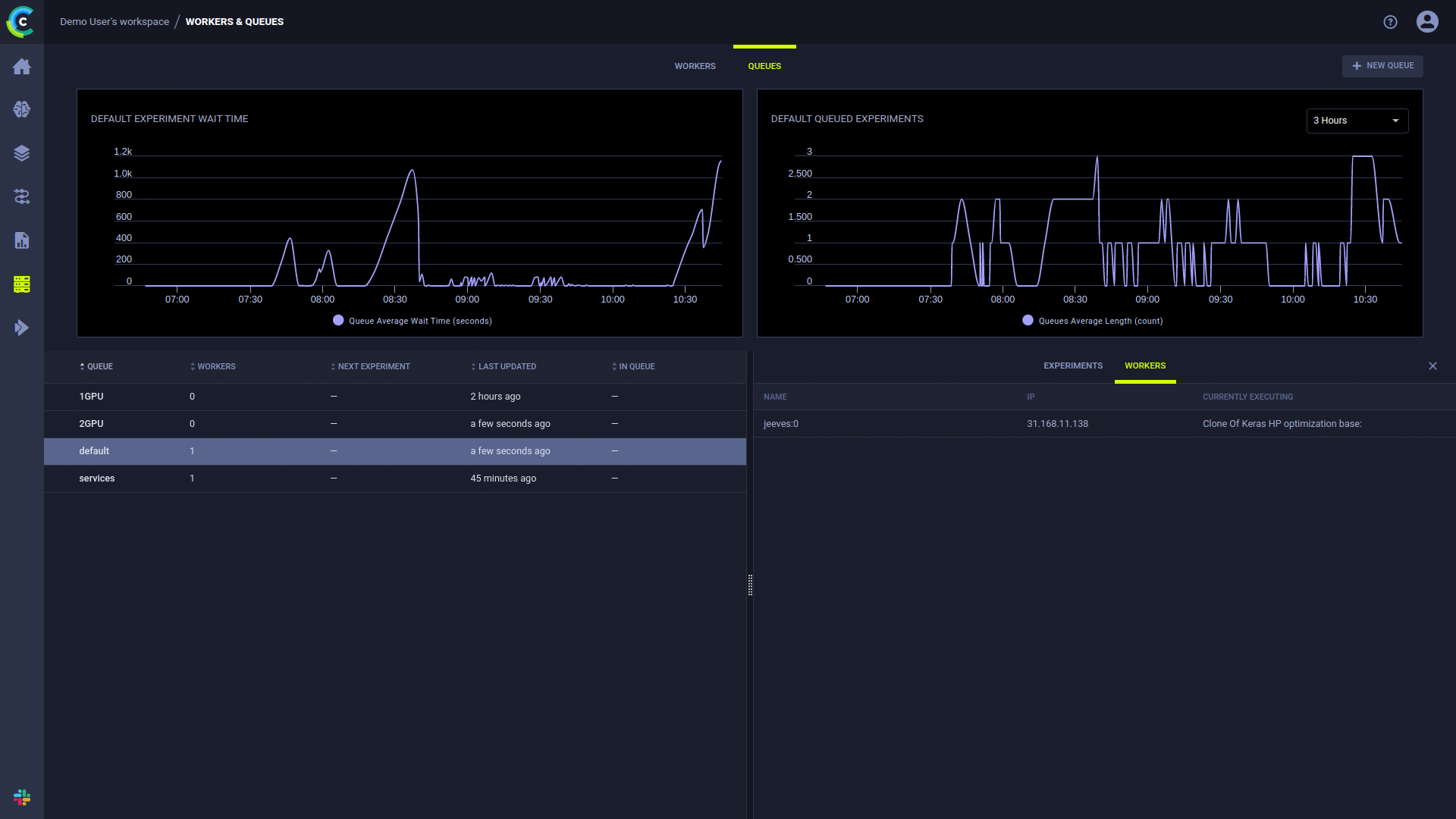
Der ClearML-Agent wurde entwickelt, um die Anforderungen von DL/ML R&D DevOps zu erfüllen:
Mit dem ClearML Agent können Sie jetzt einen dynamischen Cluster mit *epsilon DevOps einrichten
*epsilon – Weil wir es sind? und nichts ist wirklich null Arbeit
Wir finden Kubernetes großartig, aber es ist kein Muss, um mit Remote-Ausführungsagenten und Cluster-Management zu beginnen. Wir haben clearml-agent so entwickelt, dass Sie sowohl Bare-Metal als auch auf Kubernetes ausführen können, in jeder Kombination, die zu Ihrer Umgebung passt.
Sie finden die Docker-Dateien im Docker-Ordner und das Helm-Chart unter https://github.com/allegroai/clearml-helm-charts
Führen Sie den Agenten im Kubernetes-Glue-Modus aus und ordnen Sie ClearML-Jobs direkt K8s-Jobs zu:
Ja! Slurm-Integration ist verfügbar. Weitere Informationen finden Sie in der Dokumentation
Vollwertiges HPC per Knopfdruck
Der ClearML-Agent ist ein Jobplaner, der Jobwarteschlangen abhört, Jobs abruft, die Jobumgebungen festlegt, den Job ausführt und seinen Fortschritt überwacht.
Jedes „Entwurfsexperiment“ kann zur Ausführung durch einen ClearML-Agenten geplant werden.
Ein zuvor ausgeführtes Experiment kann auf zwei Arten in den Entwurfsstatus versetzt werden:
Die Ausführung eines Experiments wird geplant, indem Sie die Aktion „In die Warteschlange stellen“ im Kontextmenü des Experiments mit der rechten Maustaste in der ClearML-Benutzeroberfläche auswählen und die Ausführungswarteschlange auswählen.
Weitere Informationen finden Sie unter Erstellen eines Experiments und Einreihen in die Warteschlange zur Ausführung.
Sobald ein Experiment in die Warteschlange gestellt wird, wird es von einem ClearML-Agenten, der diese Warteschlange überwacht, aufgenommen und ausgeführt.
Die Seite „Arbeiter und Warteschlangen“ der ClearML-Benutzeroberfläche bietet Informationen zur laufenden Ausführung:
Der ClearML-Agent führt Experimente mit dem folgenden Prozess aus:
pip install clearml-agentVollständige Schnittstelle und Funktionen sind verfügbar mit
clearml-agent --help
clearml-agent daemon --helpclearml-agent init Hinweis: Der ClearML-Agent verwendet einen Cache-Ordner zum Zwischenspeichern von Pip-Paketen, Apt-Paketen und geklonten Repositorys. Der Standard-Cache-Ordner des ClearML-Agenten ist ~/.clearml .
Ausführliche Informationen finden Sie in Ihrer Konfigurationsdatei unter ~/clearml.conf .
Hinweis: Der ClearML-Agent erweitert die ClearML- Konfigurationsdatei ~/clearml.conf . Sie sind so konzipiert, dass sie dieselbe Konfigurationsdatei verwenden, siehe Beispiel hier
Starten Sie zum Debuggen und Experimentieren den ClearML-Agenten im foreground , in dem die gesamte Ausgabe auf dem Bildschirm ausgegeben wird:
clearml-agent daemon --queue default --foreground Für den eigentlichen Servicemodus werden alle Standardausgaben automatisch in einer temporären Datei gespeichert (kein Pipe-Vorgang erforderlich). Hinweis: Mit dem Flag --detached wird der ClearML-Agent im Hintergrund ausgeführt
clearml-agent daemon --detached --queue default Die GPU-Zuteilung wird über die Standard-Betriebssystemumgebung NVIDIA_VISIBLE_DEVICES oder das Flag --gpus gesteuert (oder mit --cpu-only deaktiviert).
Wenn kein Flag gesetzt ist und die Variable NVIDIA_VISIBLE_DEVICES nicht vorhanden ist, werden alle GPUs für den clearml-agent zugewiesen.
Wenn das Flag --cpu-only oder NVIDIA_VISIBLE_DEVICES="none" gesetzt ist, wird dem clearml-agent keine GPU zugewiesen.
Beispiel: Drehen Sie zwei Agenten, einen pro GPU, auf derselben Maschine:
Hinweis: Mit dem Flag --detached wird der ClearML-Agent im Hintergrund ausgeführt
clearml-agent daemon --detached --gpus 0 --queue default
clearml-agent daemon --detached --gpus 1 --queue default Beispiel: Drehen Sie zwei Agenten und ziehen Sie zwei GPUs pro Agent aus der dedizierten dual_gpu Warteschlange
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu Starten Sie zum Debuggen und Experimentieren den ClearML-Agenten im foreground , in dem die gesamte Ausgabe auf dem Bildschirm ausgegeben wird
clearml-agent daemon --queue default --docker --foreground Für den eigentlichen Servicemodus werden alle Standardausgaben automatisch in einer Datei gespeichert (keine Pipe-Anleitung erforderlich). Hinweis: Mit dem Flag --detached wird der ClearML-Agent im Hintergrund ausgeführt
clearml-agent daemon --detached --queue default --docker Beispiel: Führen Sie zwei Agenten aus, einen pro GPU auf demselben Computer, mit dem standardmäßigen Docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 :
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 1 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 Beispiel: Zwei Agenten drehen, aus der dedizierten dual_gpu Warteschlange abrufen, zwei GPUs pro Agent, mit standardmäßigem nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 Docker:
clearml-agent daemon --detached --gpus 0,1 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04
clearml-agent daemon --detached --gpus 2,3 --queue dual_gpu --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04Priority Queues werden ebenfalls unterstützt, Beispielanwendungsfall:
Warteschlange mit hoher Priorität: important_jobs , Warteschlange mit niedriger Priorität: default
clearml-agent daemon --queue important_jobs default Der ClearML-Agent versucht zunächst, Jobs aus der Warteschlange important_jobs abzurufen. Nur wenn diese leer ist, versucht der Agent, Jobs aus der default abzurufen.
Das Hinzufügen von Warteschlangen, das Verwalten der Auftragsreihenfolge innerhalb einer Warteschlange und das Verschieben von Aufträgen zwischen Warteschlangen ist über die Web-Benutzeroberfläche möglich, siehe Beispiel auf unserem kostenlosen Server
Um die Ausführung eines ClearML-Agenten im Hintergrund zu stoppen, führen Sie dieselbe Befehlszeile aus, die zum Starten des Agenten verwendet wurde, mit angehängtem --stop . Um beispielsweise den ersten der oben gezeigten gleichen Computer und einzelnen GPU-Agenten zu stoppen:
clearml-agent daemon --detached --gpus 0 --queue default --docker nvidia/cuda:11.0.3-cudnn8-runtime-ubuntu20.04 --stopIntegrieren Sie ClearML in Ihren Code
Führen Sie den Code auf Ihrem Computer aus (manuell / PyCharm / Jupyter Notebook)
Während Ihr Code ausgeführt wird, erstellt ClearML ein Experiment, das alle erforderlichen Ausführungsinformationen protokolliert:
Sie haben jetzt eine „Vorlage“ Ihres Experiments mit allem, was für die automatisierte Durchführung erforderlich ist
Klicken Sie in der ClearML-Benutzeroberfläche mit der rechten Maustaste auf das Experiment und wählen Sie „Klonen“. Es wird eine Kopie Ihres Experiments erstellt.
Sie haben jetzt einen neuen Experimententwurf, der von Ihrem ursprünglichen Experiment geklont wurde. Sie können ihn gerne bearbeiten
Planen Sie die Ausführung des neu erstellten Experiments: Klicken Sie mit der rechten Maustaste auf das Experiment und wählen Sie „In die Warteschlange stellen“.
ClearML-Agent Services ist ein spezieller Modus von ClearML-Agent, der die Möglichkeit bietet, langlebige Jobs zu starten, die zuvor auf lokalen/dedizierten Maschinen ausgeführt werden mussten. Es ermöglicht einem einzelnen Agenten, mehrere Docker (Aufgaben) für verschiedene Anwendungsfälle zu starten:
Der ClearML-Agent Services-Modus dreht jede Aufgabe, die in die angegebene Warteschlange eingereiht ist. Jede von ClearML-Agent Services gestartete Aufgabe wird als neuer Knoten im System registriert und bietet Tracking- und Transparenzfunktionen. Derzeit unterstützt der Clearml-Agent im Dienstemodus nur die CPU-Konfiguration. Der ClearML-Agent-Dienstmodus kann zusammen mit GPU-Agenten gestartet werden.
clearml-agent daemon --services-mode --detached --queue services --create-queue --docker ubuntu:18.04 --cpu-onlyHinweis : Es liegt in der Verantwortung des Benutzers, sicherzustellen, dass die richtigen Aufgaben in die angegebene Warteschlange verschoben werden.
Der ClearML-Agent kann auch zur Implementierung von AutoML-Orchestrierung und Experiment-Pipelines in Verbindung mit dem ClearML-Paket verwendet werden.
Beispielbeispiele für AutoML und Orchestration finden Sie im Ordner „ClearML example/automation“.
AutoML-Beispiele:
Beispiele für Experiment-Pipelines:
Apache-Lizenz, Version 2.0 (weitere Informationen finden Sie in der LIZENZ)


