[Papier] [Projektseite] [miniFLUX-Modell] [SD3-Modell ⚡️] [Demo?]
Dies ist das offizielle Repository für Pyramid Flow, eine trainingseffiziente autoregressive Videogenerierungsmethode basierend auf Flow Matching . Durch das ausschließliche Training mit Open-Source-Datensätzen können hochwertige 10-Sekunden-Videos mit einer Auflösung von 768p und 24 FPS generiert werden, und die Bild-zu-Video-Generierung wird natürlich unterstützt.
| 10s, 768p, 24fps | 5s, 768p, 24fps | Bild-zu-Video |
|---|---|---|
Feuerwerk.mp4 | Trailer.mp4 | sonntag.mp4 |
2024.11.13 Wir veröffentlichen den 768p miniFLUX-Checkpoint (bis zu 10 Sekunden).
Wir haben die Modellstruktur von SD3 auf einen Mini-FLUX umgestellt, um Probleme mit der menschlichen Struktur zu beheben. Probieren Sie bitte unseren 1024p-Bild-Checkpoint, 384p-Video-Checkpoint (bis zu 5 Sekunden) und 768p-Video-Checkpoint (bis zu 10 Sekunden) aus. Das neue Miniflux-Modell zeigt eine große Verbesserung der menschlichen Struktur und Bewegungsstabilität
2024.10.29 ⚡️⚡️⚡️ Wir veröffentlichen Trainingscode für VAE, Feinabstimmungscode für DiT und neue Modellprüfpunkte mit von Grund auf trainierter FLUX-Struktur.
2024.10.13 Multi-GPU-Inferenz und CPU-Offloading werden unterstützt. Verwenden Sie es mit weniger als 8 GB GPU-Speicher, mit großer Geschwindigkeitssteigerung auf mehreren GPUs.
2024.10.11 ??? Hugging Face-Demo ist verfügbar. Danke @multimodalart für das Commit!
2024.10.10 Wir veröffentlichen den technischen Bericht, die Projektseite und den Modellkontrollpunkt von Pyramid Flow.
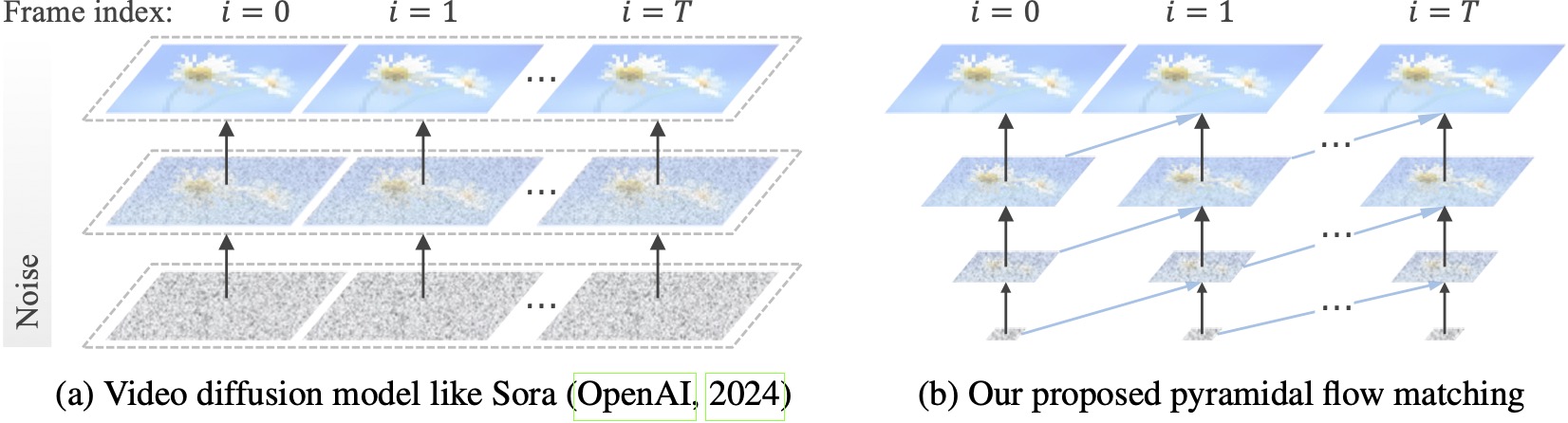
Bestehende Videodiffusionsmodelle arbeiten mit voller Auflösung und erfordern einen hohen Rechenaufwand für sehr verrauschte Latentdaten. Im Gegensatz dazu nutzt unsere Methode die Flexibilität des Flussabgleichs (Lipman et al., 2023; Liu et al., 2023; Albergo & Vanden-Eijnden, 2023), um zwischen Latentdaten unterschiedlicher Auflösung und Rauschpegel zu interpolieren und so eine gleichzeitige Erzeugung und Dekomprimierung visueller Inhalte mit besserer Recheneffizienz. Das gesamte Framework ist mit einem einzigen DiT durchgängig optimiert (Peebles & Xie, 2023) und generiert innerhalb von 20,7.000 A100-GPU-Trainingsstunden hochwertige 10-Sekunden-Videos mit einer Auflösung von 768p und 24 FPS.
Wir empfehlen, die Umgebung mit Conda einzurichten. Die Codebasis verwendet derzeit Python 3.8.10 und PyTorch 2.1.2 (Anleitung), und wir arbeiten aktiv daran, eine breitere Palette von Versionen zu unterstützen.
git clone https://github.com/jy0205/Pyramid-Flow
cd Pyramid-Flow
# create env using conda
conda create -n pyramid python==3.8.10
conda activate pyramid
pip install -r requirements.txtLaden Sie dann das Modell von Huggingface herunter (es gibt zwei Varianten: miniFLUX oder SD3). Die miniFLUX-Modelle unterstützen die Erzeugung von 1024p-Bildern, 384p- und 768p-Videos und die SD3-basierten Modelle unterstützen die Erzeugung von 768p- und 384p-Videos. Der 384p-Checkpoint generiert 5-Sekunden-Videos mit 24 Bildern pro Sekunde, während der 768p-Checkpoint bis zu 10 Sekunden lange Videos mit 24 Bildern pro Sekunde generiert.
from huggingface_hub import snapshot_download
model_path = 'PATH' # The local directory to save downloaded checkpoint
snapshot_download ( "rain1011/pyramid-flow-miniflux" , local_dir = model_path , local_dir_use_symlinks = False , repo_type = 'model' )Um zu beginnen, installieren Sie zunächst Gradio, legen Sie Ihren Modellpfad auf #L36 fest und führen Sie es dann auf Ihrem lokalen Computer aus:
python app.pyDie Gradio-Demo wird in einem Browser geöffnet. Vielen Dank an @tpc2233 für den Commit, siehe #48 für Details.
Oder probieren Sie es mühelos bei Hugging Face Space aus? erstellt von @multimodalart. Aufgrund von GPU-Einschränkungen kann diese Online-Demo nur 25 Bilder generieren (Export mit 8 FPS oder 24 FPS). Duplizieren Sie den Platz, um längere Videos zu erstellen.
Um Pyramid Flow schnell auf Google Colab auszuprobieren, führen Sie den folgenden Code aus:
# Setup
!git clone https://github.com/jy0205/Pyramid-Flow
%cd Pyramid-Flow
!pip install -r requirements.txt
!pip install gradio
# This code downloads miniFLUX
from huggingface_hub import snapshot_download
model_path = '/content/Pyramid-Flow'
snapshot_download("rain1011/pyramid-flow-miniflux", local_dir=model_path, local_dir_use_symlinks=False, repo_type='model')
# Start
!python app.py
Um unser Modell zu verwenden, folgen Sie bitte dem Inferenzcode in video_generation_demo.ipynb unter diesem Link. Wir empfehlen Ihnen dringend, den neuesten veröffentlichten Pyramiden-Miniflux auszuprobieren, der eine große Verbesserung der menschlichen Struktur und Bewegungsstabilität zeigt. Setzen Sie den zu verwendenden Parameter model_name auf pyramid_flux . Wir vereinfachen es weiter in das folgende zweistufige Verfahren. Laden Sie zunächst das heruntergeladene Modell:
import torch
from PIL import Image
from pyramid_dit import PyramidDiTForVideoGeneration
from diffusers . utils import load_image , export_to_video
torch . cuda . set_device ( 0 )
model_dtype , torch_dtype = 'bf16' , torch . bfloat16 # Use bf16 (not support fp16 yet)
model = PyramidDiTForVideoGeneration (
'PATH' , # The downloaded checkpoint dir
model_name = "pyramid_flux" ,
model_dtype ,
model_variant = 'diffusion_transformer_768p' ,
)
model . vae . enable_tiling ()
# model.vae.to("cuda")
# model.dit.to("cuda")
# model.text_encoder.to("cuda")
# if you're not using sequential offloading bellow uncomment the lines above ^
model . enable_sequential_cpu_offload ()Anschließend können Sie die Text-zu-Video-Generierung anhand Ihrer eigenen Eingabeaufforderungen ausprobieren. Beachten Sie, dass die 384p-Version derzeit nur 5 Sekunden unterstützt (Temp. auf 16 einstellen)!
prompt = "A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors"
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate (
prompt = prompt ,
num_inference_steps = [ 20 , 20 , 20 ],
video_num_inference_steps = [ 10 , 10 , 10 ],
height = height ,
width = width ,
temp = 16 , # temp=16: 5s, temp=31: 10s
guidance_scale = 7.0 , # The guidance for the first frame, set it to 7 for 384p variant
video_guidance_scale = 5.0 , # The guidance for the other video latent
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./text_to_video_sample.mp4" , fps = 24 )Als autoregressives Modell unterstützt unser Modell auch die (textbedingte) Bild-zu-Video-Generierung:
# used for 384p model variant
# width = 640
# height = 384
# used for 768p model variant
width = 1280
height = 768
image = Image . open ( 'assets/the_great_wall.jpg' ). convert ( "RGB" ). resize (( width , height ))
prompt = "FPV flying over the Great Wall"
with torch . no_grad (), torch . cuda . amp . autocast ( enabled = True , dtype = torch_dtype ):
frames = model . generate_i2v (
prompt = prompt ,
input_image = image ,
num_inference_steps = [ 10 , 10 , 10 ],
temp = 16 ,
video_guidance_scale = 4.0 ,
output_type = "pil" ,
save_memory = True , # If you have enough GPU memory, set it to `False` to improve vae decoding speed
)
export_to_video ( frames , "./image_to_video_sample.mp4" , fps = 24 )Wir unterstützen außerdem zwei Arten von CPU-Offloading, um den GPU-Speicherbedarf zu reduzieren. Beachten Sie, dass sie möglicherweise die Effizienz beeinträchtigen.
cpu_offloading=True -Parameters zur Generierungsfunktion ermöglicht Rückschlüsse mit weniger als 12 GB GPU-Speicher. Diese Funktion wurde von @Ednaordinary beigesteuert, siehe #23 für Details.model.enable_sequential_cpu_offload() vor dem obigen Verfahren ermöglicht eine Schlussfolgerung mit weniger als 8 GB GPU-Speicher. Diese Funktion wurde von @rodjjo beigesteuert, siehe #75 für Details. Dank @niw können auch Apple Silicon-Nutzer (z. B. MacBook Pro mit M2 24GB) unser Modell mit dem MPS-Backend ausprobieren! Weitere Informationen finden Sie unter Nr. 113.
Für Benutzer mit mehreren GPUs stellen wir ein Inferenzskript bereit, das Sequenzparallelität verwendet, um Speicher auf jeder GPU zu sparen. Dies führt auch zu einer erheblichen Geschwindigkeitssteigerung, da die Erstellung eines 5-Sekunden-, 768p- und 24-fps-Videos auf 4 A100-GPUs nur 2,5 Minuten dauert (im Vergleich zu 5,5 Minuten auf einer einzelnen A100-GPU). Führen Sie es mit dem folgenden Befehl auf 2 GPUs aus:
CUDA_VISIBLE_DEVICES=0,1 sh scripts/inference_multigpu.shEs unterstützt derzeit 2 oder 4 GPUs (für die SD3-Version), wobei im Originalskript weitere Konfigurationen verfügbar sind. Sie können auch eine Multi-GPU-Gradio-Demo starten, die von @tpc2233 erstellt wurde. Weitere Informationen finden Sie unter #59.
Spoiler: Dank unserer effizienten Pyramidenströmungsdesigns haben wir im Training nicht einmal Sequenzparallelität verwendet.
guidance_scale steuert die visuelle Qualität. Wir empfehlen die Verwendung einer Anleitung in [7, 9] für den 768p-Kontrollpunkt während der Text-zu-Video-Generierung und 7 für den 384p-Kontrollpunkt.video_guidance_scale steuert die Bewegung. Ein größerer Wert erhöht den Dynamikgrad und mildert die Verschlechterung der autoregressiven Generierung, während ein kleinerer Wert das Video stabilisiert.Die Hardwareanforderungen für das Training von VAE sind mindestens 8 A100-GPUs. Bitte beachten Sie dieses Dokument. Hierbei handelt es sich um eine MAGVIT-v2-ähnliche kontinuierliche 3D-VAE, die recht flexibel sein sollte. Fühlen Sie sich frei, auf diesem Teil des VAE-Trainingscodes Ihr eigenes generatives Videomodell zu erstellen.
Die Hardwareanforderungen für die Feinabstimmung von DiT betragen mindestens 8 A100-GPUs. Bitte beachten Sie dieses Dokument. Wir bieten Anweisungen sowohl für autoregressive als auch für nicht-autoregressive Versionen von Pyramid Flow. Ersteres ist stärker forschungsorientiert und letzteres ist stabiler (aber ohne zeitliche Pyramide weniger effizient).
Die folgenden Videobeispiele werden mit 5 Sekunden, 768p und 24 Bildern pro Sekunde generiert. Weitere Ergebnisse finden Sie auf unserer Projektseite.
Tokio.mp4 | eiffel.mp4 |
Wellen.mp4 | schiene.mp4 |
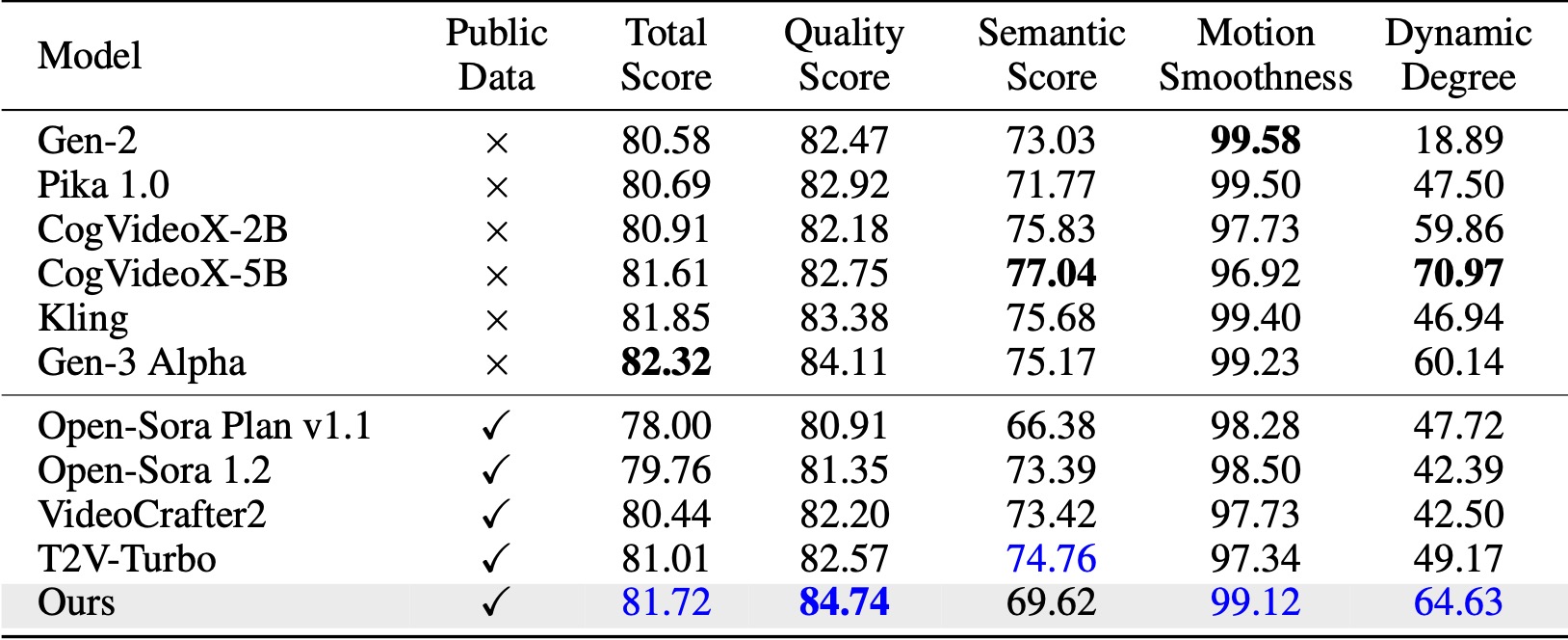
Auf VBench (Huang et al., 2024) übertrifft unsere Methode alle verglichenen Open-Source-Baselines. Selbst mit nur öffentlichen Videodaten erreicht es eine vergleichbare Leistung wie kommerzielle Modelle wie Kling (Kuaishou, 2024) und Gen-3 Alpha (Runway, 2024), insbesondere in Bezug auf den Qualitätsfaktor (84,74 vs. 84,11 von Gen-3) und die Bewegungsglätte .
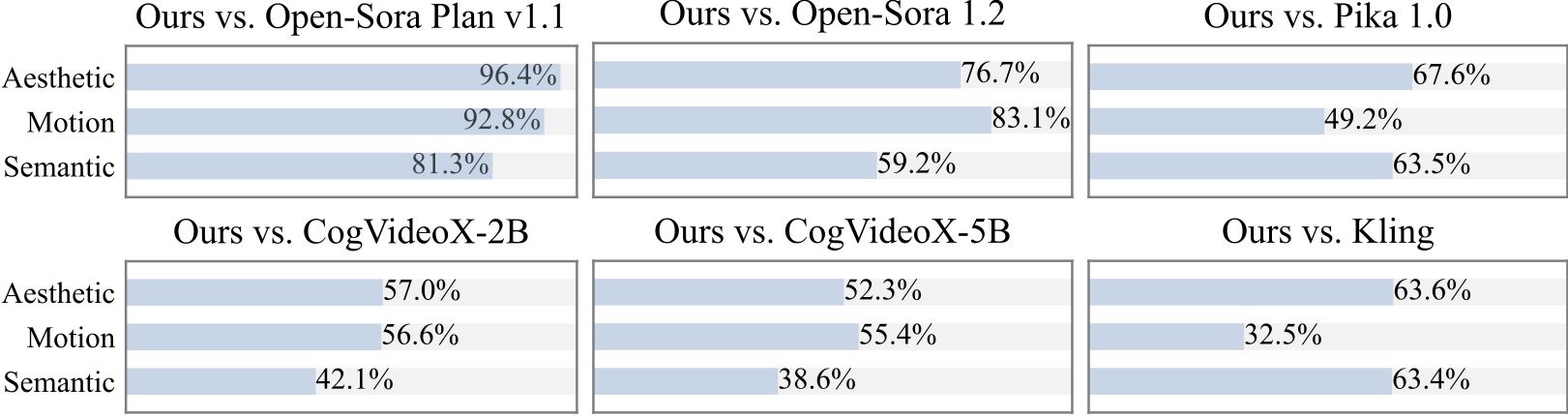
Wir führen eine zusätzliche Benutzerstudie mit mehr als 20 Teilnehmern durch. Wie man sieht, ist unsere Methode vor allem im Hinblick auf die Bewegungsglätte Open-Source-Modellen wie Open-Sora und CogVideoX-2B vorzuziehen.
Wir sind dankbar für die folgenden tollen Projekte bei der Implementierung von Pyramid Flow:
Erwägen Sie, diesem Repository einen Stern zu geben und Pyramid Flow in Ihren Veröffentlichungen zu zitieren, wenn es Ihrer Forschung hilft.
@article{jin2024pyramidal,
title={Pyramidal Flow Matching for Efficient Video Generative Modeling},
author={Jin, Yang and Sun, Zhicheng and Li, Ningyuan and Xu, Kun and Xu, Kun and Jiang, Hao and Zhuang, Nan and Huang, Quzhe and Song, Yang and Mu, Yadong and Lin, Zhouchen},
jounal={arXiv preprint arXiv:2410.05954},
year={2024}
}


