nim anywhere
1.0.0

Wenn Sie ein interner Benutzer sind, treten Sie bitte dem Slack-Kanal #cdd-nim-anywhere bei. Wenn Sie ein externer Benutzer sind, öffnen Sie ein Problem für Fragen und Feedback.
Einer der Hauptvorteile des Einsatzes von KI für Unternehmen ist ihre Fähigkeit, mit ihren internen Daten zu arbeiten und daraus zu lernen. Retrieval-Augmented Generation (RAG) ist eine der besten Möglichkeiten hierfür. NVIDIA hat eine Reihe von Mikrodiensten namens NIM-Mikrodienst entwickelt, um unseren Partnern und Kunden beim einfachen Aufbau einer effektiven RAG-Pipeline zu helfen.
NIM Anywhere enthält alle erforderlichen Tools, um mit der Integration von NIMs für RAG zu beginnen. Es lässt sich nativ auf große Labore und bis hin zu Produktionsumgebungen skalieren. Das sind großartige Neuigkeiten für den Aufbau einer RAG-Architektur und das einfache Hinzufügen von NIMs nach Bedarf. Wenn Sie mit RAG nicht vertraut sind: Es ruft während der Inferenz dynamisch relevante externe Informationen ab, ohne das Modell selbst zu ändern. Stellen Sie sich vor, Sie sind der technische Leiter eines Unternehmens mit einer lokalen Datenbank, die vertrauliche, aktuelle Informationen enthält. Sie möchten nicht, dass OpenAI auf Ihre Daten zugreift, aber Sie benötigen das Modell, um sie zu verstehen, um Fragen genau beantworten zu können. Die Lösung besteht darin, Ihr Sprachmodell mit der Datenbank zu verbinden und diese mit den Informationen zu versorgen.
Um mehr darüber zu erfahren, warum RAG eine hervorragende Lösung zur Steigerung der Genauigkeit und Zuverlässigkeit Ihrer generativen KI-Modelle ist, lesen Sie diesen Blog.
Beginnen Sie jetzt mit NIM Anywhere mit der Schnellstartanleitung und erstellen Sie Ihre erste RAG-Anwendung mit NIMs!
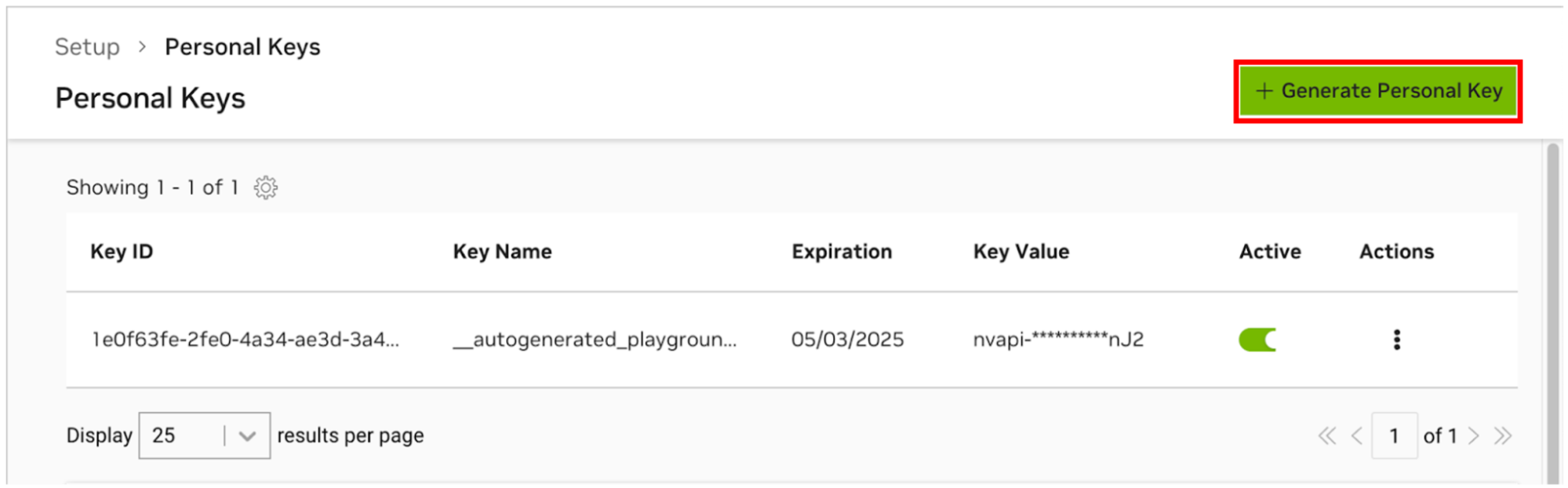
Damit AI Workbench auf die Cloud-Ressourcen von NVIDIA zugreifen kann, müssen Sie ihm einen persönlichen Schlüssel bereitstellen. Diese Schlüssel beginnen mit nvapi- .
Gehen Sie zum NGC Personal Key Manager. Wenn Sie dazu aufgefordert werden, registrieren Sie sich für ein neues Konto und melden Sie sich an.
TIPP Sie finden dieses Tool, indem Sie sich bei ngc.nvidia.com anmelden, Ihr Profilmenü oben rechts erweitern, „Setup“ und dann „Persönlichen Schlüssel generieren“ auswählen.
Wählen Sie Persönlichen Schlüssel generieren .
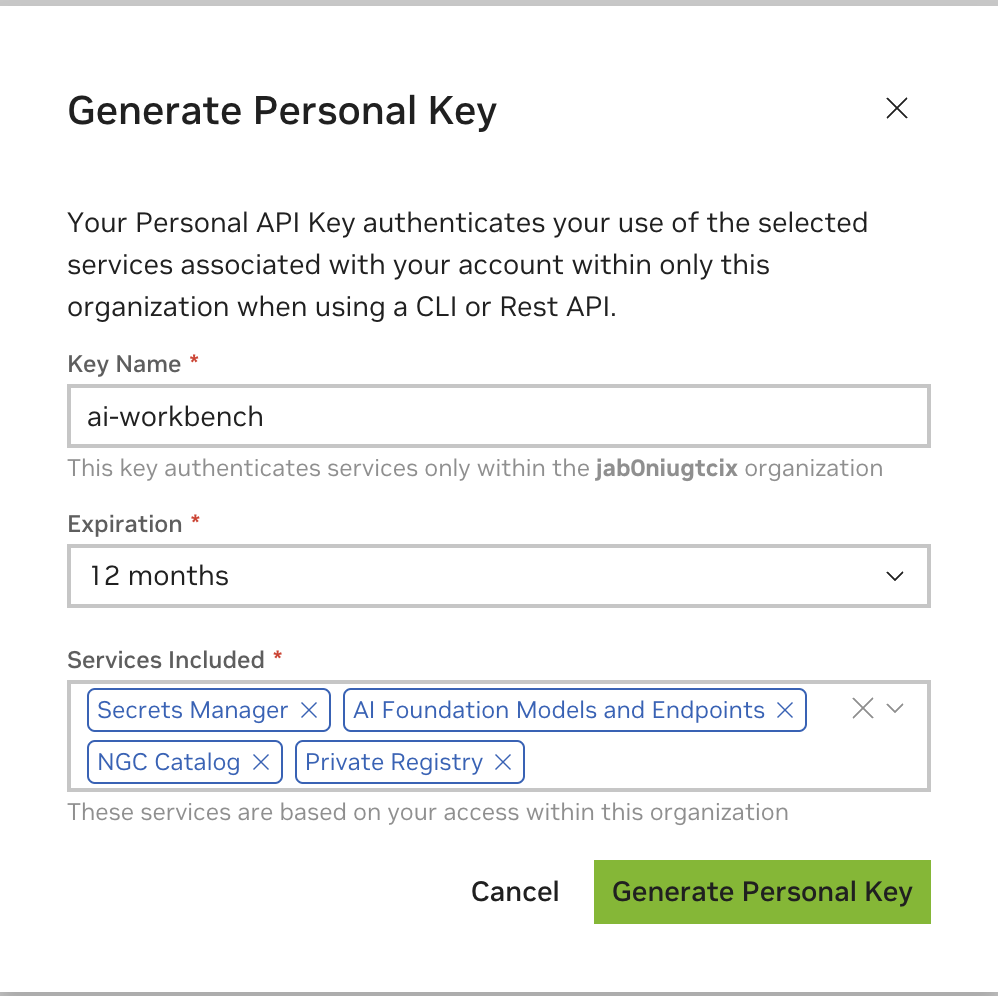
Geben Sie als Schlüsselnamen einen beliebigen Wert ein, ein Ablauf von 12 Monaten ist in Ordnung, und wählen Sie alle Dienste aus. Klicken Sie auf „Persönlichen Schlüssel generieren“, wenn Sie fertig sind.
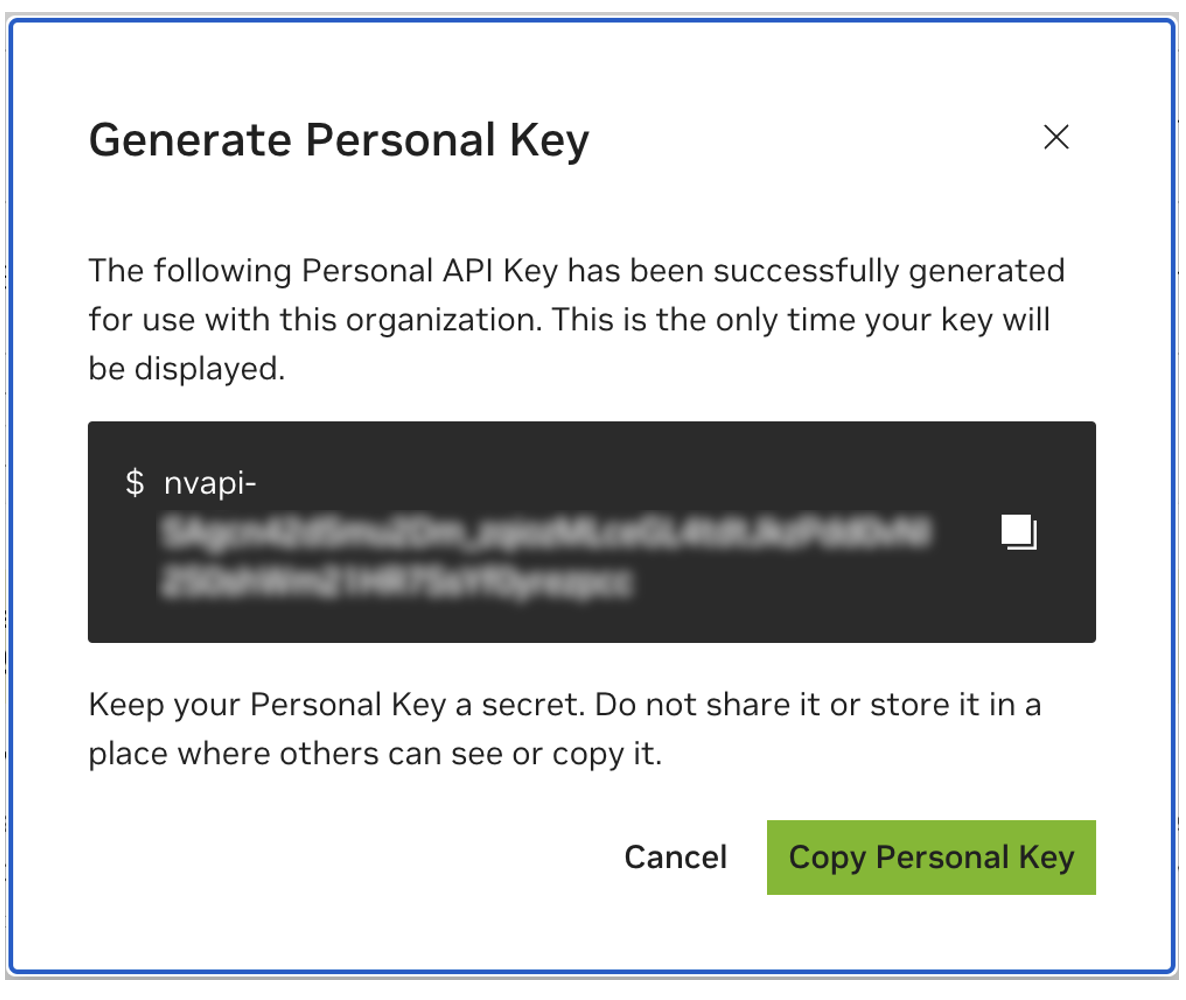
Speichern Sie Ihren persönlichen Schlüssel für später. Workbench wird es benötigen und es gibt keine Möglichkeit, es später abzurufen. Bei Verlust des Schlüssels muss ein neuer erstellt werden. Schützen Sie diesen Schlüssel wie ein Passwort.
Dieses Projekt ist für die Verwendung mit NVIDIA AI Workbench konzipiert. Dies ist zwar keine Voraussetzung, die Ausführung dieser Demo ohne AI Workbench erfordert jedoch manuelle Arbeit, da die vorkonfigurierte Automatisierung und Integrationen möglicherweise nicht verfügbar sind.
In dieser Kurzanleitung wird davon ausgegangen, dass ein Remote-Laborcomputer für die Entwicklung verwendet wird und der lokale Computer ein Thin-Client für den Remotezugriff auf den Entwicklungscomputer ist. Dies ermöglicht, dass Rechenressourcen an einem zentralen Ort bleiben und Entwickler mobiler arbeiten können. Beachten Sie, dass auf dem Remote-Laborcomputer Ubuntu ausgeführt werden muss, der lokale Client jedoch Windows, MacOS oder Ubuntu ausführen kann. Um dieses Projekt nur lokal zu installieren, überspringen Sie einfach die Remote-Installation.
Flussdiagramm LR
lokal
Subgraph-Laborumgebung
Remote-Labormaschine
Ende
lokale <-.ssh.-> remote-lab-machine
Ubuntu ist erforderlich, wenn der lokale Client auch für die Entwicklung verwendet wird. Bei Verwendung eines Remote-Laborcomputers kann dies Windows, MacOS oder Ubuntu sein.
Vollständige Anweisungen finden Sie im NVIDIA AI Workbench-Benutzerhandbuch.
Installieren Sie die erforderliche Software
Laden Sie das NVIDIA AI Workbench-Installationsprogramm herunter und führen Sie es aus. Autorisieren Sie Windows, damit das Installationsprogramm Änderungen vornehmen kann.
Folgen Sie den Anweisungen des Installationsassistenten. Wenn Sie WSL2 installieren müssen, autorisieren Sie Windows, die Änderungen vorzunehmen und den lokalen Computer bei Aufforderung neu zu starten. Beim Neustart des Systems sollte das NVIDIA AI Workbench-Installationsprogramm automatisch fortgesetzt werden.
Wählen Sie Docker als Container-Laufzeitumgebung aus.
Melden Sie sich bei Ihrem GitHub-Konto an, indem Sie die Option „Über GitHub.com anmelden“ verwenden.
Geben Sie bei Bedarf Ihre Git-Autorinformationen ein.
Vollständige Anweisungen finden Sie im NVIDIA AI Workbench-Benutzerhandbuch.
Installieren Sie die erforderliche Software
Laden Sie das NVIDIA AI Workbench-Disk-Image ( .dmg- Datei) herunter und öffnen Sie es.
Ziehen Sie AI Workbench in den Anwendungsordner und führen Sie NVIDIA AI Workbench über den Anwendungsstarter aus. 
Wählen Sie Docker als Container-Laufzeitumgebung aus.
Melden Sie sich bei Ihrem GitHub-Konto an, indem Sie die Option „Über GitHub.com anmelden“ verwenden.
Geben Sie bei Bedarf Ihre Git-Autorinformationen ein.
Vollständige Anweisungen finden Sie im NVIDIA AI Workbench-Benutzerhandbuch. Führen Sie diese Installation als Benutzer aus, der als Workbench-Benutzer fungiert. Führen Sie diese Schritte nicht als root aus.
Installieren Sie die erforderliche Software
Laden Sie das NVIDIA AI Workbench-Installationsprogramm herunter, machen Sie es ausführbar und führen Sie es dann aus. Sie können die Datei mit dem folgenden Befehl ausführbar machen:
chmod +x NVIDIA-AI-Workbench- * .AppImageAI Workbench installiert die NVIDIA-Treiber für Sie (falls erforderlich). Sie müssen Ihren lokalen Computer neu starten, nachdem die Treiber installiert wurden, und dann die AI Workbench-Installation neu starten, indem Sie auf dem Desktop auf das NVIDIA AI Workbench-Symbol doppelklicken.
Wählen Sie Docker als Container-Laufzeitumgebung aus.
Melden Sie sich bei Ihrem GitHub-Konto an, indem Sie die Option „Über GitHub.com anmelden“ verwenden.
Geben Sie bei Bedarf Ihre Git-Autorinformationen ein.
Für Remote-Rechner wird nur Ubuntu unterstützt.
Vollständige Anweisungen finden Sie im NVIDIA AI Workbench-Benutzerhandbuch. Führen Sie diese Installation als der Benutzer aus, der Workbench verwenden wird. Führen Sie diese Schritte nicht als root aus.
Stellen Sie sicher, dass die SSH-Schlüsselbasierte Authentifizierung vom lokalen Computer zum Remote-Computer aktiviert ist. Wenn dies derzeit nicht aktiviert ist, können Sie dies in den meisten Fällen mit den folgenden Befehlen aktivieren. Ändern Sie REMOTE_USER und REMOTE-MACHINE so, dass sie Ihre Remote-Adresse widerspiegeln.
ssh - keygen -f " C:Userslocal-user.sshid_rsa " - t rsa - N ' "" '
type $ env: USERPROFILE .sshid_rsa.pub | ssh REMOTE_USER @REMOTE - MACHINE " cat >> .ssh/authorized_keys " if [ ! -e ~ /.ssh/id_rsa ] ; then ssh-keygen -f ~ /.ssh/id_rsa -t rsa -N " " ; fi
ssh-copy-id REMOTE_USER@REMOTE-MACHINESSH in den Remote-Host. Verwenden Sie dann die folgenden Befehle, um das NVIDIA AI Workbench-Installationsprogramm herunterzuladen und auszuführen.
mkdir -p $HOME /.nvwb/bin &&
curl -L https://workbench.download.nvidia.com/stable/workbench-cli/ $( curl -L -s https://workbench.download.nvidia.com/stable/workbench-cli/LATEST ) /nvwb-cli- $( uname ) - $( uname -m ) --output $HOME /.nvwb/bin/nvwb-cli &&
chmod +x $HOME /.nvwb/bin/nvwb-cli &&
sudo -E $HOME /.nvwb/bin/nvwb-cli installAI Workbench installiert die NVIDIA-Treiber für Sie (falls erforderlich). Sie müssen Ihren Remote-Computer neu starten, nachdem die Treiber installiert wurden, und dann die AI Workbench-Installation neu starten, indem Sie die Befehle im vorherigen Schritt erneut ausführen.
Wählen Sie Docker als Container-Laufzeitumgebung aus.
Melden Sie sich bei Ihrem GitHub-Konto an, indem Sie die Option „Über GitHub.com anmelden“ verwenden.
Geben Sie bei Bedarf Ihre Git-Autorinformationen ein.
Sobald die Remote-Installation abgeschlossen ist, kann der Remote-Standort zur lokalen AI Workbench-Instanz hinzugefügt werden. Öffnen Sie die AI Workbench-Anwendung, klicken Sie auf Remote-Standort hinzufügen und geben Sie dann die erforderlichen Informationen ein. Wenn Sie fertig sind, klicken Sie auf Standort hinzufügen .
REMOTE-MACHINE identisch sein.REMOTE_USER identisch sein./home/USER/.ssh/id_rsa .Es gibt zwei Möglichkeiten, dieses Projekt für die lokale Verwendung herunterzuladen: Klonen und Forken.
Das Klonen dieses Repositorys ist der empfohlene Einstieg. Dadurch sind zwar keine lokalen Änderungen möglich, aber der Einstieg ist am schnellsten. Dies ermöglicht auch die einfachste Möglichkeit, Updates abzurufen.
Für die Entwicklung wird empfohlen, dieses Repository zu forken, da Änderungen gespeichert werden können. Um jedoch Updates zu erhalten, muss der Fork-Betreuer regelmäßig Daten aus dem Upstream-Repo abrufen. Um von einem Fork aus zu arbeiten, befolgen Sie die Anweisungen von GitHub und verweisen Sie dann im Rest dieses Abschnitts auf die URL zu Ihrem persönlichen Fork.
Öffnen Sie das lokale NVIDIA AI Workbench-Fenster. Wählen Sie aus der Liste der angezeigten Standorte entweder den Remote-Standort aus, den Sie gerade eingerichtet haben, oder „Lokal“, wenn Sie lokal arbeiten möchten.
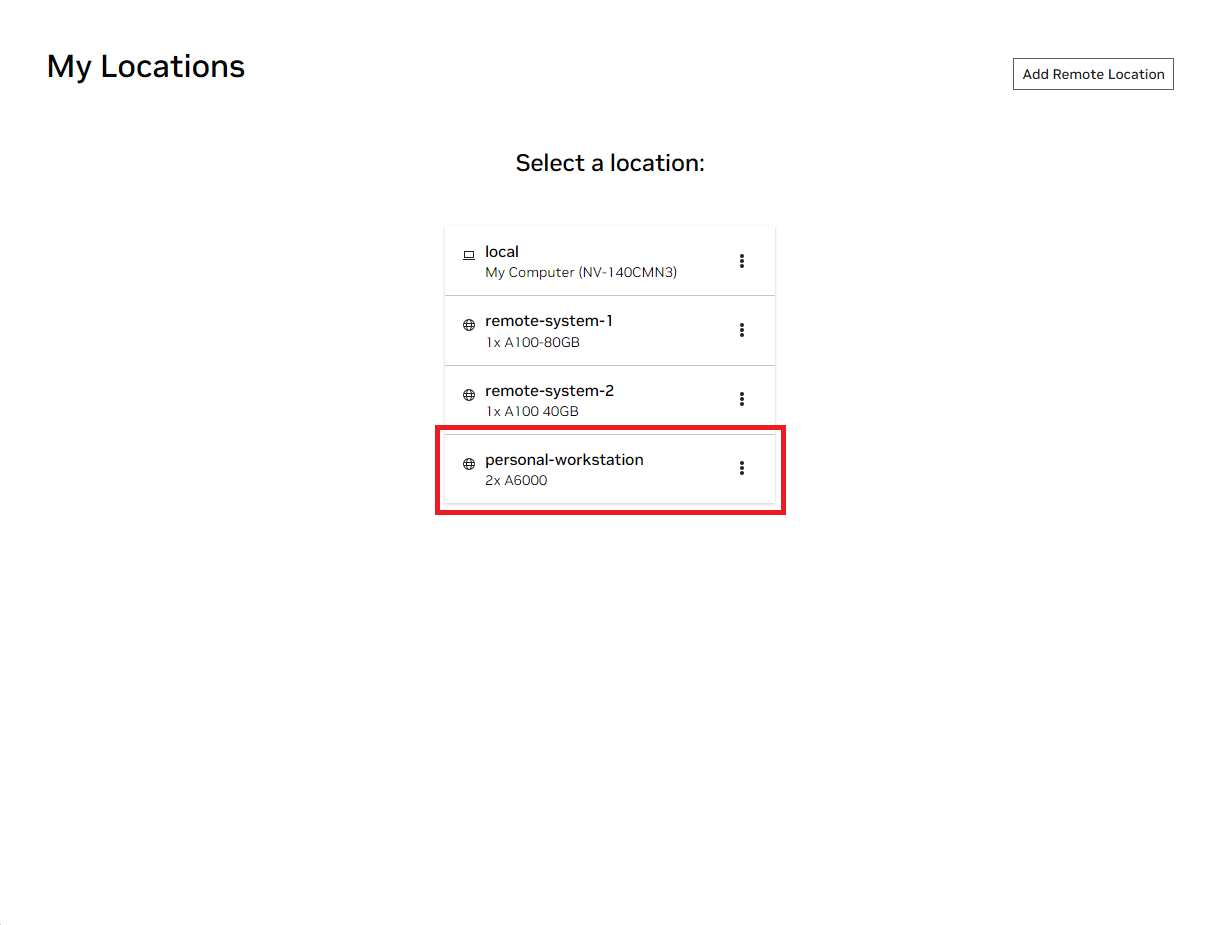
Sobald Sie sich am Standort befinden, wählen Sie „Projekt klonen“ aus.
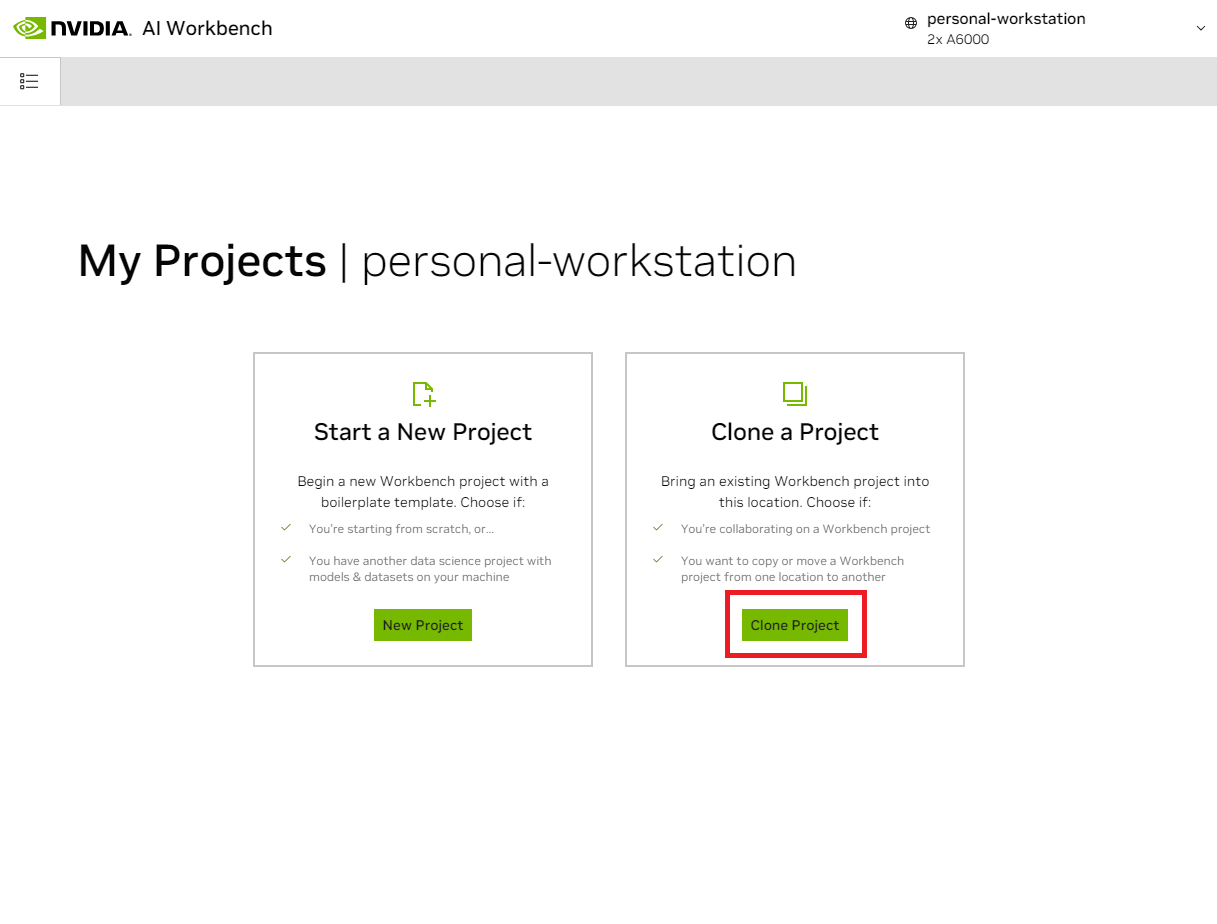
Legen Sie im Popup-Fenster „Projekt klonen“ die Repository-URL auf https://github.com/NVIDIA/nim-anywhere.git fest. Sie können den Pfad als Standardwert /home/REMOTE_USER/nvidia-workbench/nim-anywhere.git belassen. Klicken Sie auf „Klonen “.
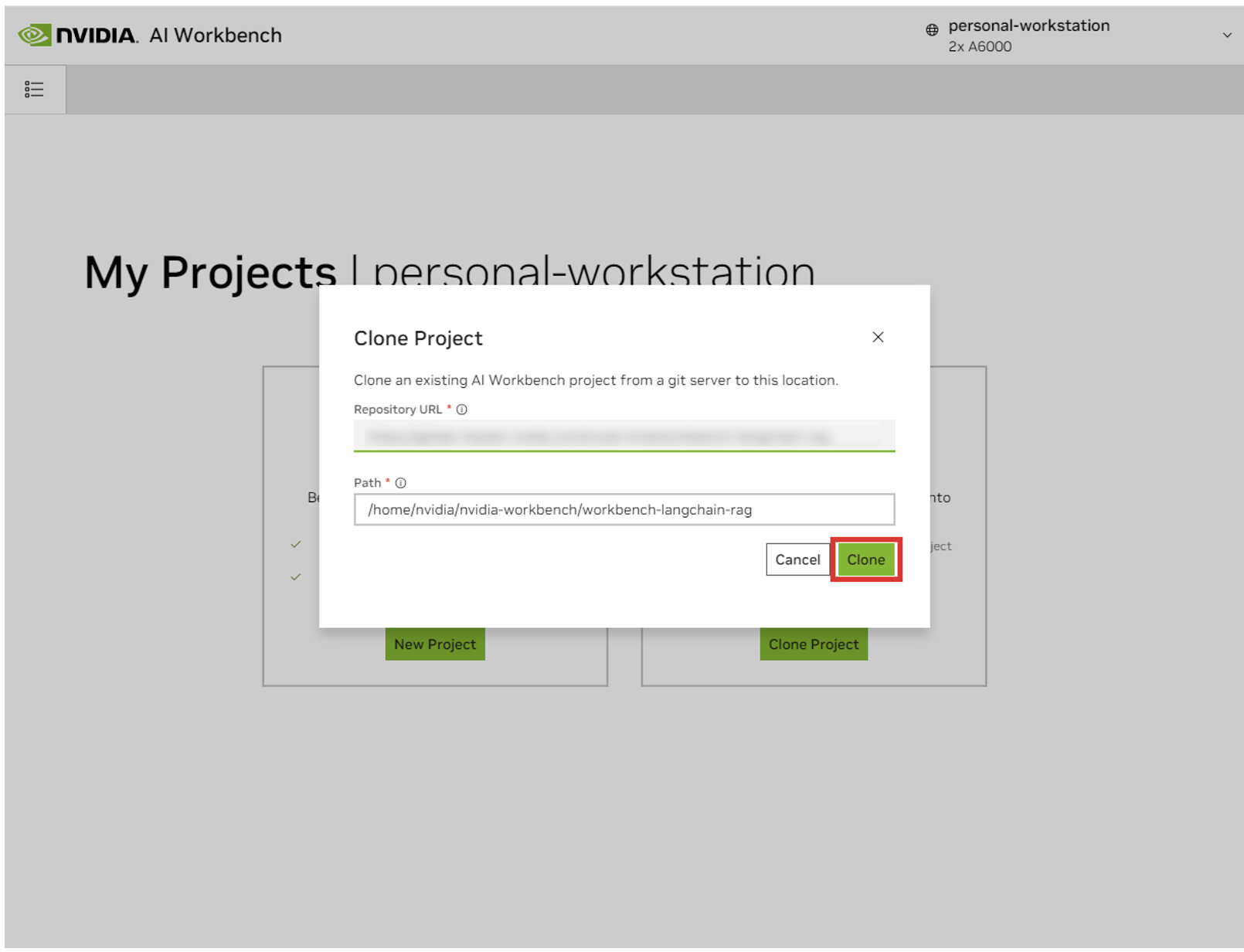
Sie werden zur Seite des neuen Projekts weitergeleitet. Workbench führt automatisch einen Bootstrap der Entwicklungsumgebung durch. Sie können den Fortschritt in Echtzeit anzeigen, indem Sie die Ausgabe am unteren Rand des Fensters erweitern.
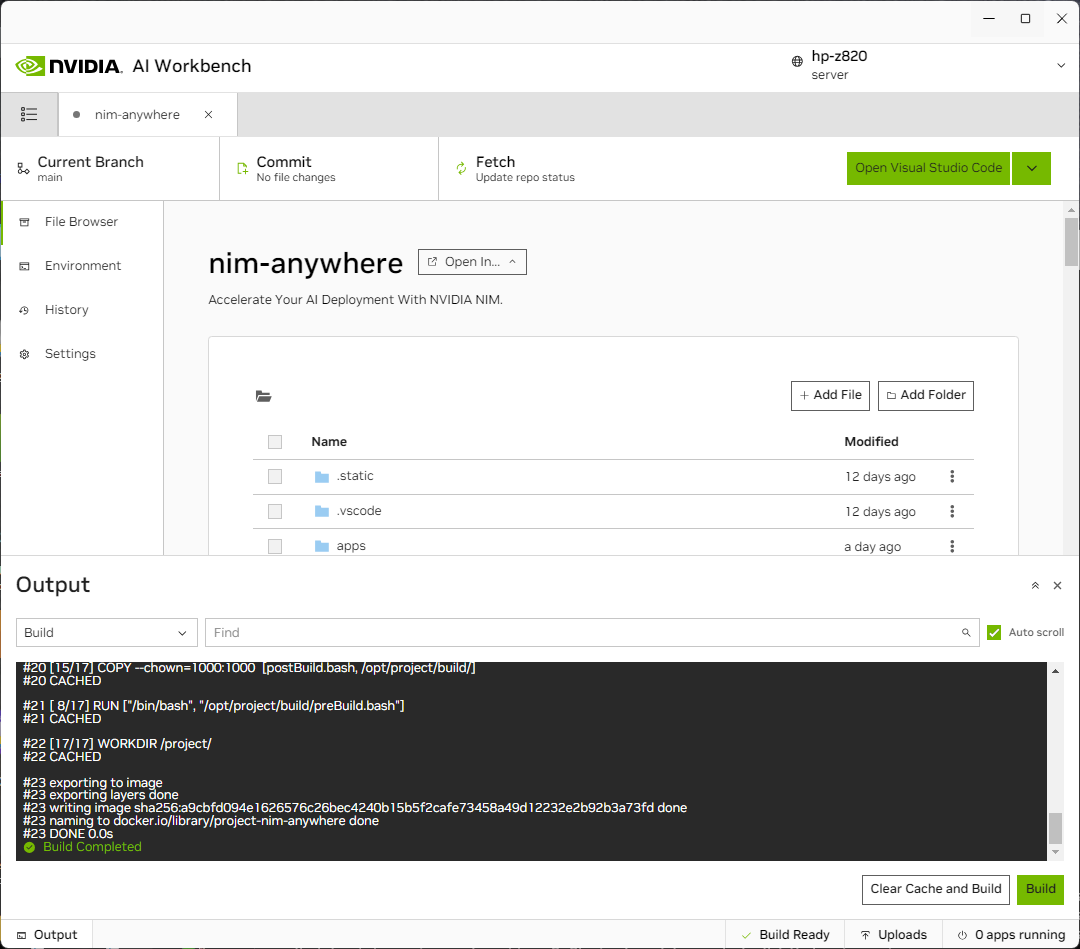
Das Projekt muss für die Arbeit mit lokalen Maschinenressourcen konfiguriert sein.
Vor dem ersten Start muss eine projektspezifische Konfiguration vorgenommen werden. Die Projektkonfiguration erfolgt über die Registerkarte „Umgebung“ im linken Bereich.
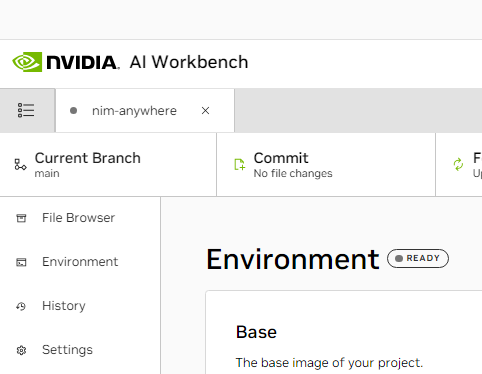
Scrollen Sie nach unten zum Abschnitt „Variablen“ und suchen Sie den Eintrag „NGC_HOME“ . Es sollte auf etwas wie ~/.cache/nvidia-nims eingestellt sein. Der Wert hier wird von der Workbench verwendet. Derselbe Speicherort erscheint auch im Abschnitt „ Mounts“ , der dieses Verzeichnis in den Container einbindet.
Scrollen Sie nach unten zum Abschnitt „Geheimnisse“ und suchen Sie den Eintrag „NGC_API_KEY“ . Klicken Sie auf „Konfigurieren“ und geben Sie den zuvor generierten persönlichen Schlüssel für NGC ein.
Scrollen Sie nach unten zum Abschnitt „Reittiere“ . Hier müssen zwei Halterungen konfiguriert werden.
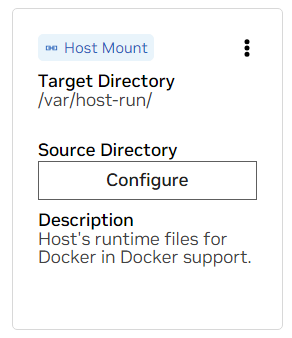
A. Suchen Sie den Mount für /var/host-run. Dies wird verwendet, um der Entwicklungsumgebung den Zugriff auf den Docker-Daemon des Hosts in einem Muster namens Docker out of Docker zu ermöglichen. Klicken Sie auf „Konfigurieren“ und geben Sie das Verzeichnis /var/run an.
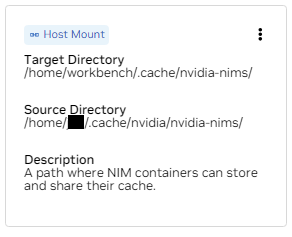
B. Suchen Sie den Mount für /home/workbench/.cache/nvidia-nims. Dieser Mount wird als Laufzeitcache für NIMs verwendet, wo sie Modelldateien zwischenspeichern können. Durch die gemeinsame Nutzung dieses Caches mit dem Host werden die Festplattennutzung und die Netzwerkbandbreite reduziert.
Wenn Sie noch keinen Nim-Cache haben oder sich nicht sicher sind, verwenden Sie die folgenden Befehle, um einen unter /home/USER/.cache/nvidia-nims zu erstellen.
mkdir -p ~ /.cache/nvidia-nims
chmod 2777 ~ /.cache/nvidia-nimsNachdem diese Einstellungen geändert wurden, erfolgt ein Neuaufbau.
Sobald der Build mit der Meldung „Build Ready“ abgeschlossen ist, stehen Ihnen alle Anwendungen zur Verfügung.
Selbst die grundlegendsten LLM-Ketten sind auf einige zusätzliche Microservices angewiesen. Diese können während der Entwicklung für In-Memory-Alternativen ignoriert werden, dann sind jedoch Codeänderungen erforderlich, um in die Produktion zu gelangen. Glücklicherweise verwaltet Workbench diese zusätzlichen Microservices für Entwicklungsumgebungen.
TIPP: Für jede Anwendung kann die Debug-Ausgabe in der Benutzeroberfläche überwacht werden, indem Sie auf den Link „Ausgabe“ in der unteren linken Ecke klicken, das Dropdown-Menü auswählen und die gewünschte Anwendung auswählen.
Alle in diesem Arbeitsbereich gebündelten Anwendungen können durch Navigieren zu Umgebung > Anwendungen gesteuert werden.
Schalten Sie zunächst Milvus Vector DB und Redis ein. Milvus wird als unstrukturierte Wissensdatenbank und Redis zum Speichern von Gesprächsverläufen verwendet.
Sobald diese Dienste gestartet sind, kann der Chain Server sicher gestartet werden. Dies enthält den benutzerdefinierten LangChain-Code zur Durchführung unserer Argumentationskette. Standardmäßig werden die lokalen Milvus und Redis verwendet, aber ai.nvidia.com wird für die LLM- und Einbettungsmodell-Inferenzierung verwendet.
[OPTIONAL]: Als nächstes starten Sie das LLM NIM . Beim ersten Start des LLM NIM dauert es einige Zeit, das Bild und die optimierten Modelle herunterzuladen.
A. Um zu bestätigen, dass das LLM-NIM während eines langen Starts startet, kann der Fortschritt beobachtet werden, indem die Protokolle im Ausgabebereich unten links auf der Benutzeroberfläche angezeigt werden.
B. Wenn die Protokolle einen Authentifizierungsfehler anzeigen, bedeutet dies, dass der bereitgestellte NGC_API_KEY keinen Zugriff auf die NIMs hat. Bitte stellen Sie sicher, dass es korrekt und in einer NGC-Organisation generiert wurde, die NVIDIA AI Enterprise-Support oder -Testversion bietet.
C. Wenn die Protokolle festzustecken scheinen ..........: Pull complete . ..........: Verifying complete , oder ..........: Download complete ; Dies ist alles eine normale Ausgabe von Docker, dass die verschiedenen Ebenen des Container-Images heruntergeladen wurden.
D. Alle anderen hier auftretenden Fehler müssen behoben werden.
Sobald der Chain Server hochgefahren ist, kann die Chat-Schnittstelle gestartet werden. Beim Starten der Schnittstelle wird diese automatisch in einem Browserfenster geöffnet.
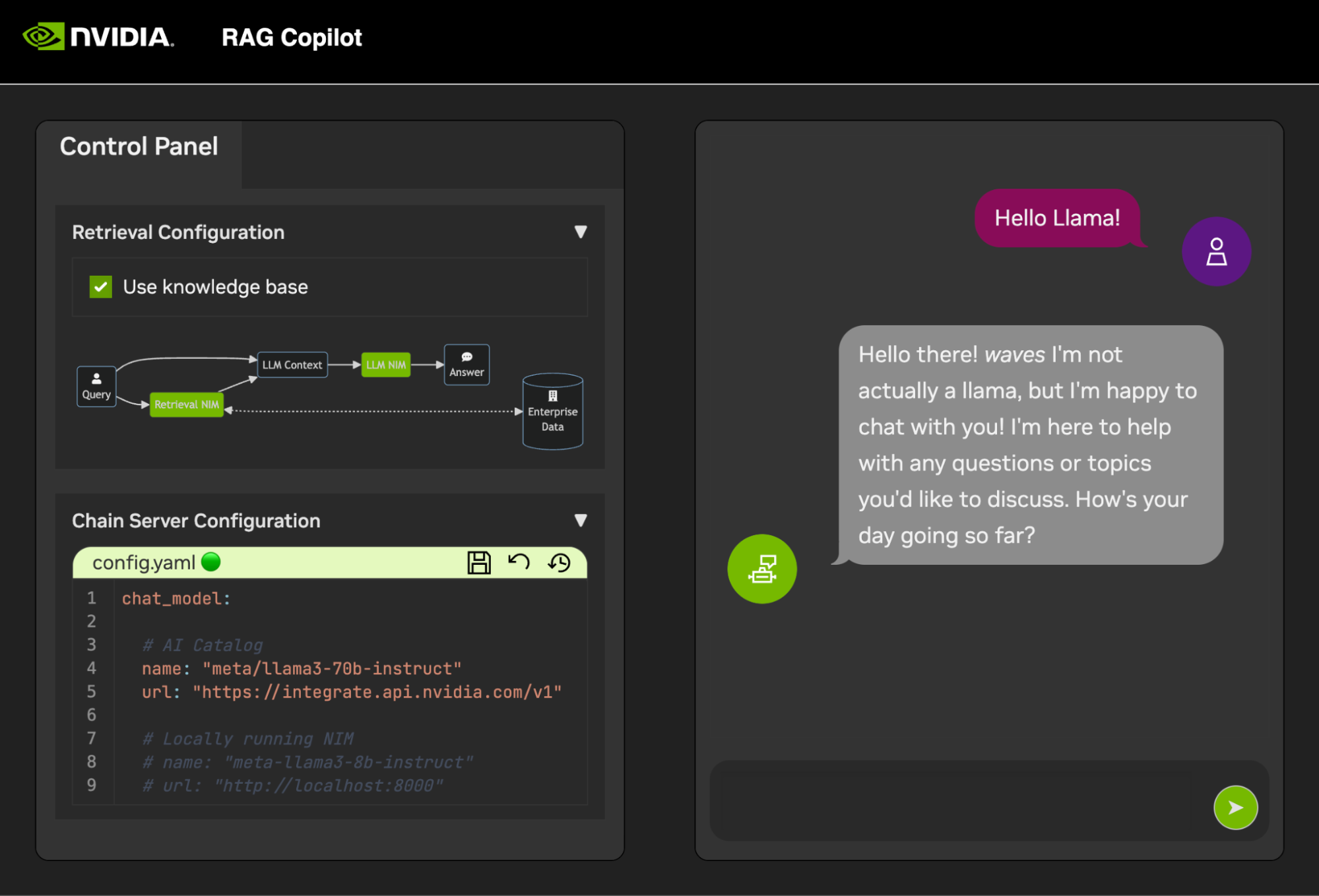
Um mit der Entwicklung von Demos zu beginnen, wird ein Beispieldatensatz zusammen mit einem Jupyter-Notebook bereitgestellt, das zeigt, wie Daten in eine Vector-Datenbank aufgenommen werden.
Um PDF-Dokumentation in die Vektordatenbank zu importieren, öffnen Sie Jupyter mit dem App Launcher in AI Workbench.
Verwenden Sie das Jupyter Notebook unter code/upload-pdfs.ipynb um den Standarddatensatz aufzunehmen. Bei Verwendung des Standarddatensatzes sind keine Änderungen erforderlich.
Wenn Sie einen benutzerdefinierten Datensatz verwenden, laden Sie ihn in das Verzeichnis data/ in Jupyter hoch und ändern Sie das bereitgestellte Notebook nach Bedarf.
Dieses Projekt enthält Anwendungen für einige Demodienste sowie Integrationen mit externen Diensten. Diese werden alle von NVIDIA AI Workbench orchestriert.
Die Demo-Dienste befinden sich alle im code Ordner. Auf der Stammebene des Codeordners befinden sich einige interaktive Notizbücher, die für tiefe technische Einblicke gedacht sind. Der Chain Server ist eine Beispielanwendung, die NIMs mit LangChain nutzt. (Beachten Sie, dass der Kettenserver Ihnen hier die Möglichkeit bietet, mit und ohne RAG zu experimentieren.) Der Chat-Frontend-Ordner enthält einen interaktiven UI-Server zum Ausführen des Kettenservers. Schließlich werden im Evaluierungsverzeichnis Beispielnotizbücher bereitgestellt, um die Bewertung und Validierung des Abrufs zu demonstrieren.
Mindmap
root((AI Workbench))
Demo-Dienste
Kettenserver<br />LangChain + NIMs
Frontend<br />Interaktive Demo-Benutzeroberfläche
Auswertung<br />Validieren Sie die Ergebnisse
Notizbücher<br />Erweiterte Nutzung
Integrationen
Redis</br>Konversationsverlauf
Milvus</br>Vektordatenbank
LLM NIM</br>Optimierte LLMs
Der Chain Server kann entweder mit einer Konfigurationsdatei oder Umgebungsvariablen konfiguriert werden.
Standardmäßig sucht die Anwendung an allen folgenden Speicherorten nach einer Konfigurationsdatei. Wenn mehrere Konfigurationsdateien gefunden werden, haben Werte aus niedrigeren Dateien in der Liste Vorrang.
Ein zusätzlicher Konfigurationsdateipfad kann über eine Umgebungsvariable namens APP_CONFIG angegeben werden. Der Wert in dieser Datei hat Vorrang vor allen Standarddateispeicherorten.
export APP_CONFIG=/etc/my_config.yaml Die Konfiguration kann auch mithilfe von Umgebungsvariablen festgelegt werden. Die Variablennamen haben das folgende Format: APP_FIELD__SUB_FIELD Als Umgebungsvariablen angegebene Werte haben Vorrang vor allen Werten aus Dateien.
# Your API key for authentication to AI Foundation.
# ENV Variables: NGC_API_KEY, NVIDIA_API_KEY, APP_NVIDIA_API_KEY
# Type: string, null
nvidia_api_key : ~
# The Data Source Name for your Redis DB.
# ENV Variables: APP_REDIS_DSN
# Type: string
redis_dsn : redis://localhost:6379/0
llm_model :
# The name of the model to request.
# ENV Variables: APP_LLM_MODEL__NAME
# Type: string
name : meta/llama3-8b-instruct
# The URL to the model API.
# ENV Variables: APP_LLM_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
embedding_model :
# The name of the model to request.
# ENV Variables: APP_EMBEDDING_MODEL__NAME
# Type: string
name : nvidia/nv-embedqa-e5-v5
# The URL to the model API.
# ENV Variables: APP_EMBEDDING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
reranking_model :
# The name of the model to request.
# ENV Variables: APP_RERANKING_MODEL__NAME
# Type: string
name : nv-rerank-qa-mistral-4b:1
# The URL to the model API.
# ENV Variables: APP_RERANKING_MODEL__URL
# Type: string
url : https://integrate.api.nvidia.com/v1
milvus :
# The host machine running Milvus vector DB.
# ENV Variables: APP_MILVUS__URL
# Type: string
url : http://localhost:19530
# The name of the Milvus collection.
# ENV Variables: APP_MILVUS__COLLECTION_NAME
# Type: string
collection_name : collection_1
log_level :
Auch das Chat-Frontend verfügt über einige Konfigurationsmöglichkeiten. Sie können auf die gleiche Weise wie der Kettenserver eingestellt werden.
# The URL to the chain on the chain server.
# ENV Variables: APP_CHAIN_URL
# Type: string
chain_url : http://localhost:3030/
# The url prefix when this is running behind a proxy.
# ENV Variables: PROXY_PREFIX, APP_PROXY_PREFIX
# Type: string
proxy_prefix : /
# Path to the chain server's config.
# ENV Variables: APP_CHAIN_CONFIG_FILE
# Type: string
chain_config_file : ./config.yaml
log_level :
Alle Rückmeldungen und Beiträge zu diesem Projekt sind willkommen. Wenn Sie Änderungen an diesem Projekt vornehmen, entweder für den persönlichen Gebrauch oder um Beiträge zu leisten, wird empfohlen, an einem Fork dieses Projekts zu arbeiten. Sobald die Änderungen am Fork abgeschlossen sind, sollte ein Merge Request geöffnet werden.
Dieses Projekt wurde mit Linters konfiguriert, die so optimiert wurden, dass der Code konsistent bleibt, ohne übermäßig aufwändig zu sein. Wir verwenden folgende Linters:
Die eingebettete VSCode-Umgebung ist so konfiguriert, dass Linting und Überprüfung in Echtzeit ausgeführt werden.
Um das von den CI-Pipelines durchgeführte Linting manuell auszuführen, führen Sie /project/code/tools/lint.sh aus. Einzelne Tests können ausgeführt werden, indem sie anhand ihres Namens angegeben werden: /project code/tools/lint.sh [deps|pylint|mypy|black|docs|fix] . Wenn Sie das Lint-Tool im Korrekturmodus ausführen, wird automatisch alles korrigiert, was möglich ist, indem Black ausgeführt, die README-Datei aktualisiert und die Zellenausgabe auf allen Jupyter-Notebooks gelöscht wird.
Das Frontend wurde so konzipiert, dass die erforderliche HTML- und Javascript-Entwicklung minimiert wird. Es wird eine gebrandete und gestaltete Anwendungs-Shell bereitgestellt, die mit Vanilla-HTML, Javascript und CSS erstellt wurde. Es ist so konzipiert, dass es leicht angepasst werden kann, sollte aber niemals erforderlich sein. Die interaktiven Komponenten des Frontends werden alle in Gradio erstellt und mithilfe von Iframes in der App-Shell eingebunden.
Oben in der App-Shell befindet sich ein Menü, das die verfügbaren Ansichten auflistet. Jede Ansicht kann ein eigenes Layout haben, das aus einer oder mehreren Seiten besteht.
Seiten enthalten die interaktiven Komponenten für eine Demo. Der Code für die Seiten befindet sich im Verzeichnis code/frontend/pages . So erstellen Sie eine neue Seite:
__init__.py , die Gradio zum Definieren der Benutzeroberfläche verwendet. Das Layout der Gradio-Blöcke sollte in einer Variablen namens page definiert werden.chat -Seite.code/frontend/pages/__init__.py , importieren Sie die neue Seite und fügen Sie die neue Seite zur Liste __all__ hinzu.HINWEIS: Durch das Erstellen einer neuen Seite wird diese nicht zum Frontend hinzugefügt. Es muss einer Ansicht hinzugefügt werden, damit es im Frontend angezeigt wird.
Die Ansichten bestehen aus einer oder mehreren Seiten und sollten unabhängig voneinander funktionieren. Ansichten werden alle im Modul code/frontend/server.py definiert. Alle deklarierten Ansichten werden automatisch zur Menüleiste des Frontends hinzugefügt und in der Benutzeroberfläche verfügbar gemacht.
Um eine neue Ansicht zu definieren, ändern Sie die Liste mit dem Namen views . Dies ist eine Liste von View -Objekten. Die Reihenfolge der Objekte bestimmt deren Reihenfolge im Frontend-Menü. Die erste definierte Ansicht ist die Standardansicht.
Ansichtsobjekte beschreiben den Namen und das Layout der Ansicht. Sie können wie folgt deklariert werden:
my_view = frontend . view . View (
name = "My New View" , # the name in the menu
left = frontend . pages . sample_page , # the page to show on the left
right = frontend . pages . another_page , # the page to show on the right
) Alle Seitendeklarationen View.left oder View.right sind optional. Wenn sie nicht deklariert sind, werden die zugehörigen Iframes im Weblayout ausgeblendet. Die anderen Iframes werden erweitert, um die Lücken zu schließen. Die folgenden Diagramme zeigen die verschiedenen Layouts.
Block-Beta
Spalten 1
Menü["Menüleiste"]
Block
Spalten 2
links rechts
Ende
Block-Beta
Spalten 1
Menü["Menüleiste"]
Block
Spalten 1
links:1
Ende
Das Frontend enthält einige Marken-Assets, die für verschiedene Anwendungsfälle angepasst werden können.
Das Frontend enthält oben links auf der Seite ein Logo. Um das Logo zu ändern, ist eine SVG-Datei des gewünschten Logos erforderlich. Die App-Shell kann dann einfach geändert werden, um das neue SVG zu verwenden, indem die Datei code/frontend/_assets/index.html geändert wird. Es gibt ein einzelnes div mit der ID logo . Diese Box enthält eine einzelne SVG-Datei. Aktualisieren Sie dies auf die gewünschte SVG-Definition.
< div id =" logo " class =" logo " >
< svg viewBox =" 0 0 164 30 " > ... </ svg >
</ div > Der Stil der App Shell ist in code/frontend/_static/css/style.css definiert. Die Farben in dieser Datei können bedenkenlos geändert werden.
Der Stil der verschiedenen Seiten wird in code/frontend/pages/*/*.css definiert. Diese Dateien müssen möglicherweise auch für benutzerdefinierte Farbschemata geändert werden.
Das Gradio-Theme ist in der Datei code/frontend/_assets/theme.json definiert. Die Farben in dieser Datei können problemlos an das gewünschte Branding angepasst werden. Andere Stile in dieser Datei können ebenfalls geändert werden, können jedoch zu bahnbrechenden Änderungen am Frontend führen. Die Gradio-Dokumentation enthält weitere Informationen zur Gradio-Themengestaltung.
HINWEIS: Dies ist ein fortgeschrittenes Thema, das die meisten Entwickler niemals benötigen werden.
Gelegentlich kann es erforderlich sein, mehrere Seiten in einer Ansicht zu haben, die miteinander kommunizieren. Zu diesem Zweck wird das postMessage Messaging-Framework von Javascript verwendet. Jede vertrauenswürdige Nachricht, die an die Anwendungs-Shell gesendet wird, wird an jeden Iframe weitergeleitet, wo die Seiten die Nachricht wie gewünscht verarbeiten können. Die control verwendet diese Funktion, um die Konfiguration der chat -Seite zu ändern.
Im Folgenden wird eine Nachricht an die App-Shell ( window.top ) gesendet. Die Nachricht enthält ein Wörterbuch mit dem Schlüssel use_kb und dem Wert true. Mit Gradio kann dieses Javascript von jedem Gradio-Ereignis ausgeführt werden.
window . top . postMessage ( { "use_kb" : true } , '*' ) ; Diese Nachricht wird von der App-Shell automatisch an alle Seiten gesendet. Der folgende Beispielcode konsumiert die Nachricht auf einer anderen Seite. Dieser Code wird asynchron ausgeführt, wenn ein message empfangen wird. Wenn die Nachricht vertrauenswürdig ist, wird eine Gradio-Komponente mit der elem_id von use_kb auf den in der Nachricht angegebenen Wert aktualisiert. Auf diese Weise kann der Wert einer Gradio-Komponente seitenübergreifend dupliziert werden.
window . addEventListener (
"message" ,
( event ) => {
if ( event . isTrusted ) {
use_kb = gradio_config . components . find ( ( element ) => element . props . elem_id == "use_kb" ) ;
use_kb . props . value = event . data [ "use_kb" ] ;
} ;
} ,
false ) ; Die README-Datei wird automatisch gerendert; Direkte Änderungen werden überschrieben. Um die README-Datei zu ändern, müssen Sie die Dateien für jeden Abschnitt separat bearbeiten. Alle diese Dateien werden kombiniert und die README-Datei wird automatisch generiert. Sie finden alle zugehörigen Dateien im Ordner docs .
Die Dokumentation wird in Github Flavored Markdown geschrieben und dann von Pandoc in eine endgültige Markdown-Datei gerendert. Die Details für diesen Prozess sind im Makefile definiert. Die Reihenfolge der generierten Dateien wird in docs/_TOC.md definiert. Die Dokumentation kann im Workbench-Dateibrowserfenster in der Vorschau angezeigt werden.
Die Header-Datei ist die erste Datei, die zum Kompilieren der Dokumentation verwendet wird. Diese Datei finden Sie unter docs/_HEADER.md . Der Inhalt dieser Datei wird vor allem wörtlich und ohne Manipulation in die README-Datei geschrieben.
Die Zusammenfassungsdatei enthält eine Kurzbeschreibung und eine Grafik, die dieses Projekt beschreiben. Der Inhalt dieser Datei wird der README-Datei unmittelbar nach der Kopfzeile und unmittelbar vor dem Inhaltsverzeichnis hinzugefügt. Diese Datei wird von Pandoc verarbeitet, um Bilder einzubetten, bevor sie in die README-Datei geschrieben wird.
Die wichtigste Datei für die Dokumentation ist die Inhaltsverzeichnisdatei unter docs/_TOC.md . Diese Datei definiert eine Liste von Dateien, die verkettet werden sollten, um das endgültige README-Handbuch zu generieren. Dateien müssen in dieser Liste enthalten sein, um aufgenommen zu werden.
Speichern Sie alle statischen Inhalte, einschließlich Bilder, im Ordner _static . Dies hilft bei der Organisation.
Es kann hilfreich sein, Dokumente zu haben, die sich selbst aktualisieren und schreiben. Um ein dynamisches Dokument zu erstellen, erstellen Sie einfach eine ausführbare Datei, die das Markdown-formatierte Dokument nach stdout schreibt. Wenn während der Erstellungszeit ein Eintrag in der Inhaltsverzeichnisdatei ausführbar ist, wird er ausgeführt und stattdessen seine Standardausgabe verwendet.
Wenn ein dokumentationsbezogener Commit gepusht wird, rendert eine GitHub-Aktion die Dokumentation. Alle Änderungen an der README-Datei werden automatisch übernommen.
Der Großteil der Konfiguration für die Entwicklungsumgebung erfolgt mit Umgebungsvariablen. Um dauerhafte Änderungen an Umgebungsvariablen vorzunehmen, ändern Sie variables.env oder verwenden Sie die Workbench-Benutzeroberfläche.
Dieses Projekt verwendet eine Python-Umgebung unter /usr/bin/python3 und Abhängigkeiten werden mit pip verwaltet. Da die gesamte Entwicklung innerhalb eines Containers erfolgt, sind alle Änderungen an der Python-Umgebung nur kurzlebig. Um ein Python-Paket dauerhaft zu installieren, fügen Sie es der Datei requirements.txt hinzu oder verwenden Sie die Workbench-Benutzeroberfläche.
Die Entwicklungsumgebung basiert auf Ubuntu 22.04. Der Hauptbenutzer hat sudo-Zugriff ohne Passwort, aber alle Änderungen am System sind vorübergehend. Um dauerhafte Änderungen an installierten Paketen vorzunehmen, fügen Sie diese zur Datei [ apt.txt ] hinzu. Um andere Änderungen am Betriebssystem vorzunehmen, z. B. Dateien zu bearbeiten, Umgebungsvariablen hinzuzufügen usw.; Verwenden Sie die Dateien postBuild.bash und preBuild.bash .
Normalerweise empfiehlt es sich, Abhängigkeiten monatlich zu aktualisieren, um sicherzustellen, dass keine CVEs durch missbrauchte Abhängigkeiten offengelegt werden. Der folgende Prozess kann zum Patchen dieses Projekts verwendet werden. Es wird empfohlen, den Regressionstest nach dem Patch durchzuführen, um sicherzustellen, dass im Update keine Fehler aufgetreten sind.
/project/code/tools/bump.sh ausführen./project/code/tools/audit.sh aus. Dieses Skript druckt einen Bericht aller Python-Pakete im Warnstatus und aller Pakete im Fehlerstatus aus. Alles, was einen Fehlerstatus aufweist, muss behoben werden, da es aktive CVEs und bekannte Schwachstellen aufweist.

