Facebook Messenger Bot
1.0.0
Der FB Messenger-Chatbot, den ich darauf trainiert habe, wie ich zu sprechen. Der dazugehörige Blogbeitrag.
Für dieses Projekt wollte ich ein Sequence-To-Sequence-Modell anhand meiner früheren Konversationsprotokolle von verschiedenen Social-Media-Sites trainieren. Mehr über die Motivation hinter diesem Ansatz, die Details des ML-Modells und den Zweck jedes Python-Skripts können Sie im Blogbeitrag lesen, aber ich möchte diese README-Datei verwenden, um zu erklären, wie Sie Ihren eigenen Chatbot trainieren können, so zu sprechen wie Sie .
Um diese Skripte auszuführen, benötigen Sie die folgenden Bibliotheken.
Laden Sie das gesamte Repository von GitHub herunter und entpacken Sie es entweder interaktiv oder indem Sie Folgendes in Ihr Terminal eingeben.
git clone https://github.com/adeshpande3/Facebook-Messenger-Bot.gitNavigieren Sie in das oberste Verzeichnis des Repos auf Ihrem Computer
cd Facebook-Messenger-BotUnsere erste Aufgabe besteht darin, alle Ihre Konversationsdaten von verschiedenen Social-Media-Sites herunterzuladen. Ich habe Facebook, Google Hangouts und LinkedIn verwendet. Wenn Sie andere Websites haben, von denen Sie Daten erhalten, ist das kein Problem. Sie müssen lediglich eine neue Methode in createDataset.py erstellen.
Facebook-Daten : Laden Sie Ihre Daten hier herunter. Nach dem Herunterladen sollten Sie eine ziemlich große Datei mit dem Namen „messages.htm“ haben. Es wird eine ziemlich große Datei sein (über 190 MB für mich). Wir müssen diese große Datei analysieren und alle Konversationen extrahieren. Dazu verwenden wir dieses Tool, das Dillon Dixon freundlicherweise als Open Source zur Verfügung gestellt hat. Sie werden das Tool nun installieren, indem Sie es ausführen
pip install fbchat-archive-parserund dann läuft:
fbcap ./messages.htm > fbMessages.txtDadurch erhalten Sie alle Ihre Facebook-Konversationen in einer ziemlich einheitlichen Textdatei. Danke Dillon! Fahren Sie fort und speichern Sie diese Datei dann in Ihrem Facebook-Messenger-Bot-Ordner.
LinkedIn-Daten : Laden Sie Ihre Daten hier herunter. Nach dem Herunterladen sollte eine Datei „inbox.csv“ angezeigt werden. Wir müssen hier keine weiteren Schritte unternehmen, wir möchten es nur in unseren Ordner kopieren.
Google Hangouts-Daten : Laden Sie Ihr Datenformular hier herunter. Nach dem Herunterladen erhalten Sie eine JSON-Datei, die wir analysieren müssen. Dazu verwenden wir diesen Parser, den wir in diesem phänomenalen Blogbeitrag gefunden haben. Wir möchten die Daten in Textdateien speichern und dann den Ordner in unseren kopieren.
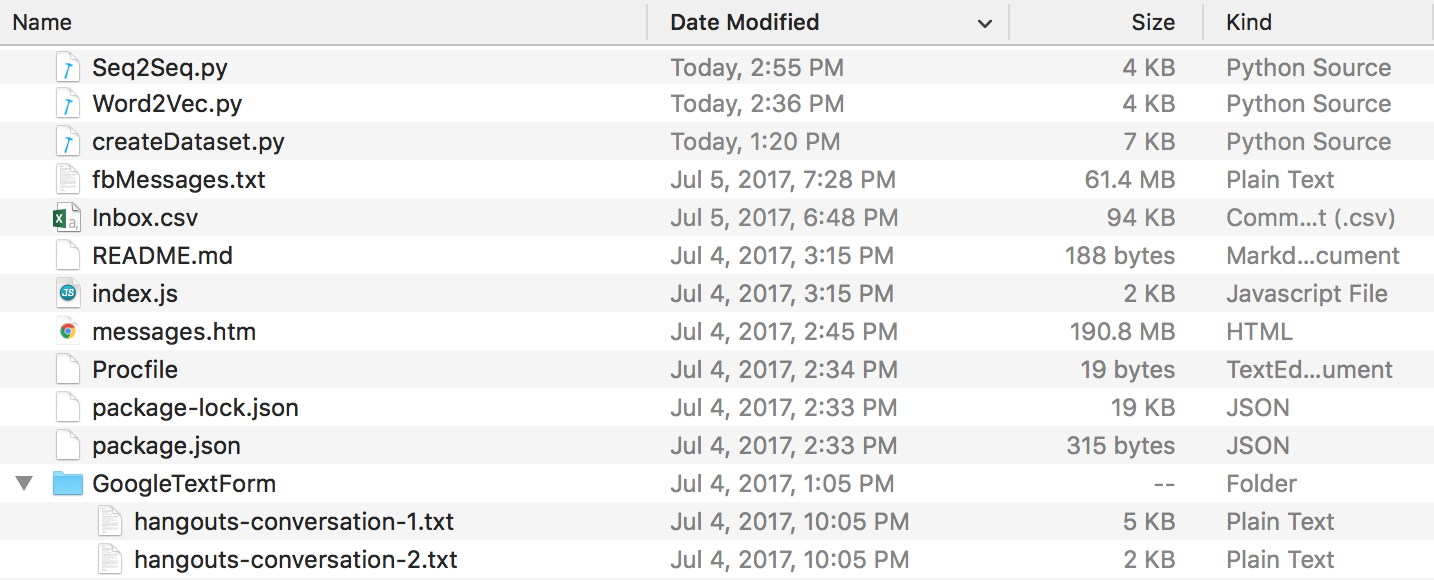
Am Ende sollten Sie eine Verzeichnisstruktur haben, die so aussieht. Stellen Sie sicher, dass Sie die Ordner- und Dateinamen umbenennen, falls Ihre Namen abweichen.
Discord-Daten : Sie können Ihre Discord-Chatlogs mit diesem fantastischen DiscordChatExporter von Tyrrrz extrahieren. Befolgen Sie die Dokumentation, um Ihre gewünschten einzelnen Chatprotokolle im .txt Format zu extrahieren (dies ist wichtig). Sie können sie dann alle in einem Ordner namens DiscordChatLogs im Repo-Verzeichnis ablegen.
WhatsApp-Daten : Stellen Sie sicher, dass Sie ein Mobiltelefon haben, und geben Sie es im US-Datumsformat ein, falls dies noch nicht geschehen ist (dies wird später wichtig sein, wenn Sie die Protokolldatei in .csv analysieren). Sie können WhatsApp Web für diesen Zweck nicht verwenden. Öffnen Sie den Chat, den Sie senden möchten, tippen Sie auf die Menüschaltfläche, tippen Sie auf „Mehr“ und dann auf „E-Mail-Chat“. Senden Sie die E-Mail an sich selbst und laden Sie sie auf Ihren Computer herunter. Dadurch erhalten Sie eine .txt-Datei. Zum Parsen konvertieren wir sie in .csv. Gehen Sie dazu auf diesen Link und geben Sie den gesamten Text in Ihre Protokolldatei ein. Klicken Sie auf „Exportieren“, laden Sie die CSV-Datei herunter und speichern Sie sie einfach in Ihrem Facebook-Messenger-Bot-Ordner unter dem Namen „whatsapp_chats.csv“.
HINWEIS : Der im obigen Link bereitgestellte Parser wurde offenbar entfernt. Wenn Sie noch eine .csv Datei im richtigen Format haben, können Sie diese weiterhin verwenden. Andernfalls laden Sie Ihre WhatsApp-Chat-Protokolle als .txt Dateien herunter und legen Sie sie alle in einem Ordner namens WhatsAppChatLogs im Repo-Verzeichnis ab. createDataset.py funktioniert stattdessen nur dann mit diesen Dateien, wenn es KEINE .csv Datei mit dem Namen whatsapp_chats.csv findet.
Falls Sie .txt Chatprotokolle verwenden, beachten Sie, dass das erwartete Format ist:
[20.06.19, 15:58:57] Loris: Welcome to the chat example
[20.06.19, 15:59:07] John: Thanks
(ODER)
12/28/19, 21:43 - Loris: Welcome to the chat example
12/28/19, 21:43 - John: Thanks
Da wir nun alle unsere Konversationsprotokolle in einem sauberen Format haben, können wir mit der Erstellung unseres Datensatzes fortfahren. Lassen Sie uns in unserem Verzeichnis Folgendes ausführen:
python createDataset.pyAnschließend werden Sie aufgefordert, Ihren Namen einzugeben (damit das Skript weiß, nach wem es suchen muss) und welche Social-Media-Sites Sie über Daten verfügen. Dieses Skript erstellt eine Datei mit dem Namen „conversationDictionary.npy“ , bei der es sich um ein Numpy-Objekt handelt, das Paare in der Form (FRIENDS_MESSAGE, YOUR RESPONSE) enthält. Außerdem wird eine Datei mit dem Namen „conversationData.txt“ erstellt. Dabei handelt es sich lediglich um eine große Textdatei mit Wörterbuchdaten in einheitlicher Form.
Da wir nun diese beiden Dateien haben, können wir mit der Erstellung unserer Wortvektoren über ein Word2Vec-Modell beginnen. Dieser Schritt unterscheidet sich ein wenig von den anderen. Die Tensorflow-Funktion, die wir später (in seq2seq.py) sehen, übernimmt tatsächlich auch den Einbettungsteil. Sie können sich also entweder dafür entscheiden, Ihre eigenen Vektoren zu trainieren, oder die seq2seq-Funktion dies gemeinsam tun lassen, was ich letztendlich auch getan habe. Wenn Sie über Word2Vec Ihre eigenen Wortvektoren erstellen möchten, sagen Sie an der Eingabeaufforderung „y“ (nachdem Sie Folgendes ausgeführt haben). Wenn Sie dies nicht tun, ist das in Ordnung. Antworten Sie mit „n“ und diese Funktion erstellt nur die Datei „wordList.txt“.
python Word2Vec.pyWenn Sie word2vec.py vollständig ausführen, werden 4 verschiedene Dateien erstellt. Word2VecXTrain.npy und Word2VecYTrain.npy sind die Trainingsmatrizen, die Word2Vec verwenden wird. Wir speichern diese in unserem Ordner, für den Fall, dass wir unser Word2Vec-Modell erneut mit anderen Hyperparametern trainieren müssen. Wir speichern auch wordList.txt , das einfach alle eindeutigen Wörter in unserem Korpus enthält. Die letzte gespeicherte Datei ist „embeddingMatrix.npy “, eine Numpy-Matrix, die alle generierten Wortvektoren enthält.
Jetzt können wir unser Seq2Seq-Modell erstellen und trainieren.
python Seq2Seq.pyDadurch werden 3 oder mehr verschiedene Dateien erstellt. Seq2SeqXTrain.npy und Seq2SeqYTrain.npy sind die Trainingsmatrizen, die Seq2Seq verwenden wird. Auch hier speichern wir diese nur für den Fall, dass wir Änderungen an unserer Modellarchitektur vornehmen und unseren Trainingssatz nicht neu berechnen möchten. Die letzten Dateien sind .ckpt-Dateien, die unser gespeichertes Seq2Seq-Modell enthalten. Modelle werden zu unterschiedlichen Zeitpunkten in der Trainingsschleife gespeichert. Diese werden verwendet und bereitgestellt, sobald wir unseren Chatbot erstellt haben.
Nachdem wir nun ein gespeichertes Modell haben, erstellen wir nun unseren Facebook-Chatbot. Dazu würde ich empfehlen, diesem Tutorial zu folgen. Sie müssen nichts unter dem Abschnitt „Anpassen, was der Bot sagt“ lesen. Unser Seq2Seq-Modell übernimmt diesen Teil. WICHTIG – Im Tutorial werden Sie aufgefordert, einen neuen Ordner zu erstellen, in dem sich das Node-Projekt befindet. Beachten Sie, dass sich dieser Ordner von unserem Ordner unterscheidet. Sie können sich diesen Ordner als den Ort vorstellen, an dem sich unsere Datenvorverarbeitung und unser Modelltraining befinden, während der andere Ordner ausschließlich für die Express-App reserviert ist (BEARBEITEN: Ich glaube, Sie können den Schritten des Tutorials in unserem Ordner folgen und einfach das Node-Projekt erstellen. Procfile und index.js-Dateien hier, wenn Sie möchten). Das Tutorial selbst sollte ausreichen, aber hier ist eine Zusammenfassung der Schritte.
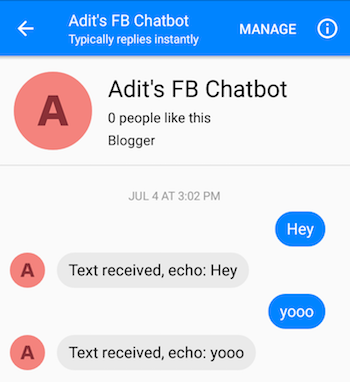
Nachdem Sie die Schritte korrekt ausgeführt haben, sollten Sie in der Lage sein, dem Chatbot eine Nachricht zu senden und Antworten zu erhalten.
Ah, du bist fast fertig! Jetzt müssen wir einen Flask-Server erstellen, auf dem wir unser gespeichertes Seq2Seq-Modell bereitstellen können. Ich habe den Code für diesen Server hier. Lassen Sie uns über die allgemeine Struktur sprechen. Flask-Server verfügen normalerweise über eine Haupt-PY-Datei, in der Sie alle Endpunkte definieren. In unserem Fall ist dies app.py. Hier laden wir unser Modell. Sie sollten einen Ordner namens „models“ erstellen und ihn mit 4 Dateien füllen (einer Prüfpunktdatei, einer Datendatei, einer Indexdatei und einer Metadatei). Dies sind die Dateien, die erstellt werden, wenn Sie ein Tensorflow-Modell speichern.

In dieser app.py-Datei möchten wir eine Route erstellen (in meinem Fall „/prediction“), bei der die Eingabe der Route in unser gespeichertes Modell eingespeist wird und die Decoder-Ausgabe die zurückgegebene Zeichenfolge ist. Schauen Sie sich app.py genauer an, falls das immer noch etwas verwirrend ist. Nachdem Sie nun Ihre app.py und Ihre Modelle (und ggf. weitere Hilfsdateien) haben, können Sie Ihren Server bereitstellen. Wir werden Heroku wieder verwenden. Es gibt viele verschiedene Tutorials zum Bereitstellen von Flask-Servern auf Heroku, aber dieses gefällt mir besonders gut (die Abschnitte „Foreman“ und „Logging“ sind nicht erforderlich).
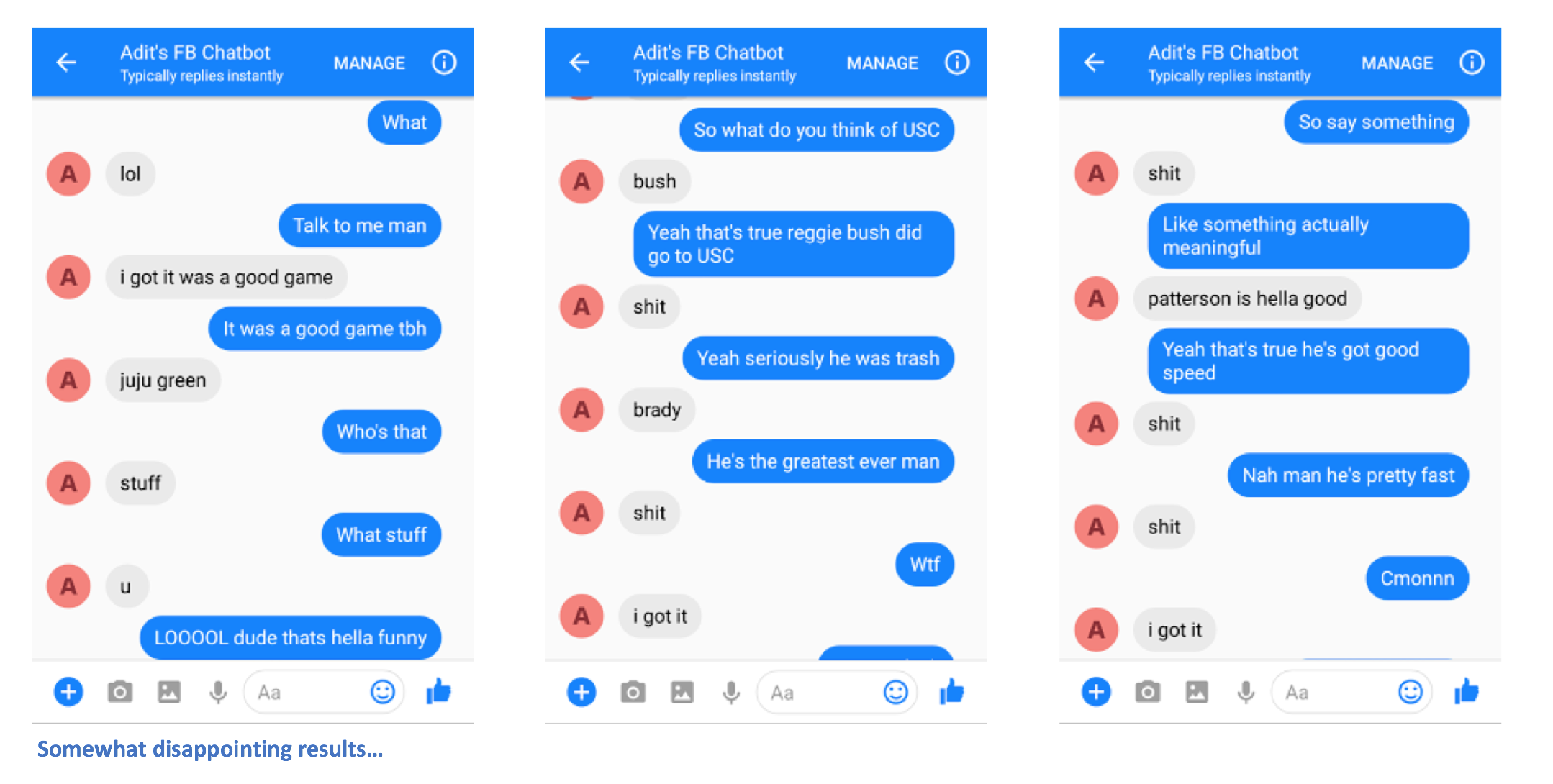
Los geht's. Sie sollten in der Lage sein, Nachrichten an den Chatbot zu senden und einige interessante Antworten zu sehen, die (hoffentlich) in irgendeiner Weise Ihnen ähneln.
Bitte teilen Sie mir mit, wenn Sie Probleme haben oder Vorschläge zur Verbesserung dieser README-Datei haben. Wenn Sie der Meinung sind, dass ein bestimmter Schritt unklar ist, lassen Sie es mich wissen und ich werde mein Bestes geben, die README-Datei zu bearbeiten und etwaige Klarstellungen vorzunehmen.


