RLAIF V
1.0.0

Ausrichtung von MLLMs durch Open-Source-KI-Feedback für Super-GPT-4V-Vertrauenswürdigkeit
中文 | Englisch
[26.11.2024] Wir unterstützen jetzt das LoRA-Training!
[28.05.2024] Unser Artikel ist jetzt bei arXiv verfügbar!
[20.05.2024] Unser RLAIF-V-Datensatz wird für das Training von MiniCPM-Llama3-V 2.5 verwendet, das das erste endseitige GPT-4V-Level-MLLM darstellt!
[20.05.2024] Wir veröffentlichen den Code, die Gewichte (7B, 12B) und die Daten von RLAIF-V als Open Source!
Wir stellen RLAIF-V vor, ein neuartiges Framework, das MLLMs in einem vollständig Open-Source-Paradigma für Super-GPT-4V-Vertrauenswürdigkeit ausrichtet. RLAIF-V nutzt das Open-Source-Feedback aus zwei Schlüsselperspektiven maximal aus, einschließlich hochwertiger Feedback-Daten und eines Online-Feedback-Lernalgorithmus. Zu den bemerkenswerten Merkmalen von RLAIF-V gehören:
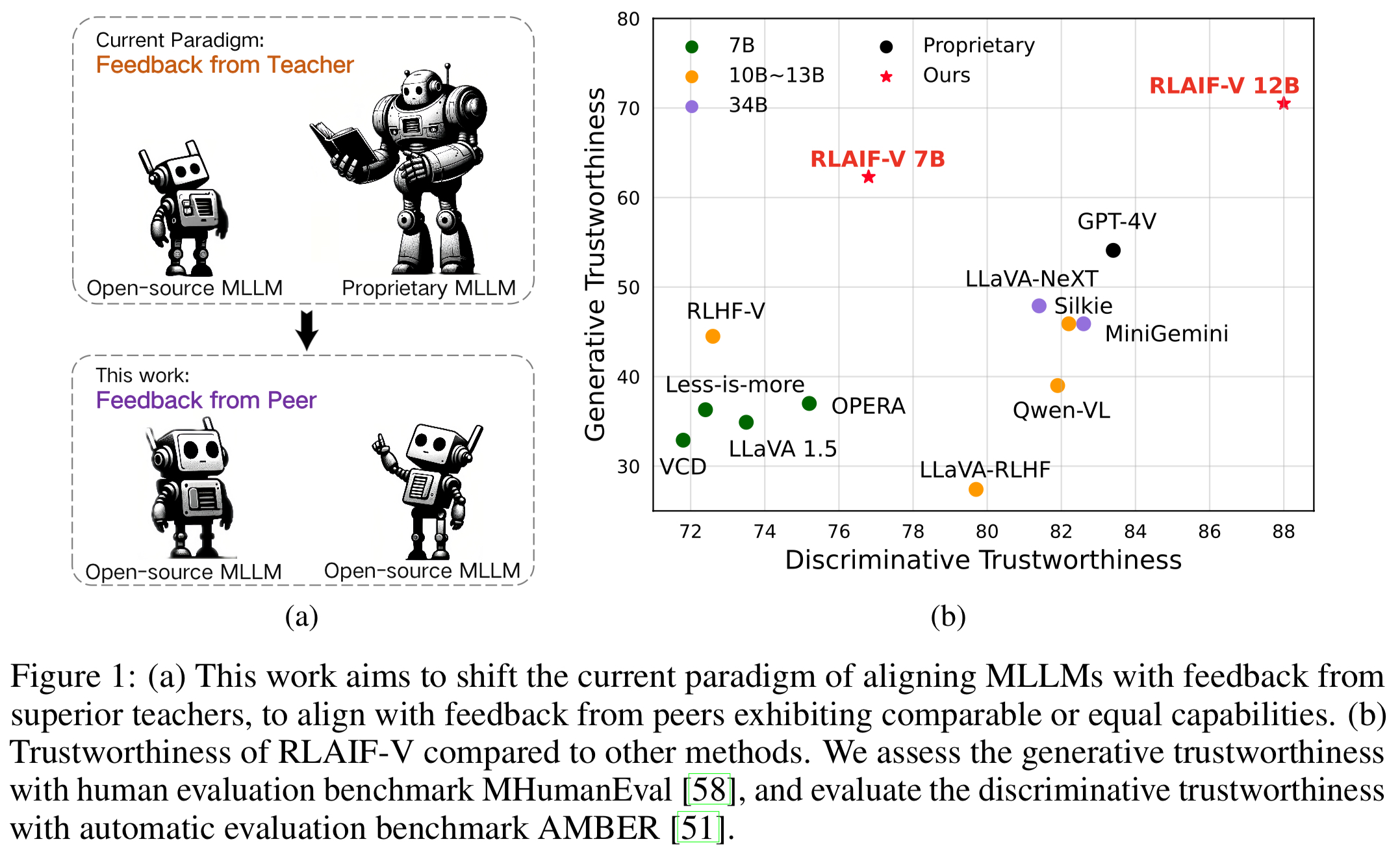
Super GPT-4V-Vertrauenswürdigkeit durch Open-Source-Feedback . Durch das Lernen aus Open-Source-KI-Feedback erreicht RLAIF-V 12B eine hervorragende GPT-4V-Vertrauenswürdigkeit sowohl bei generativen als auch bei diskriminierenden Aufgaben.
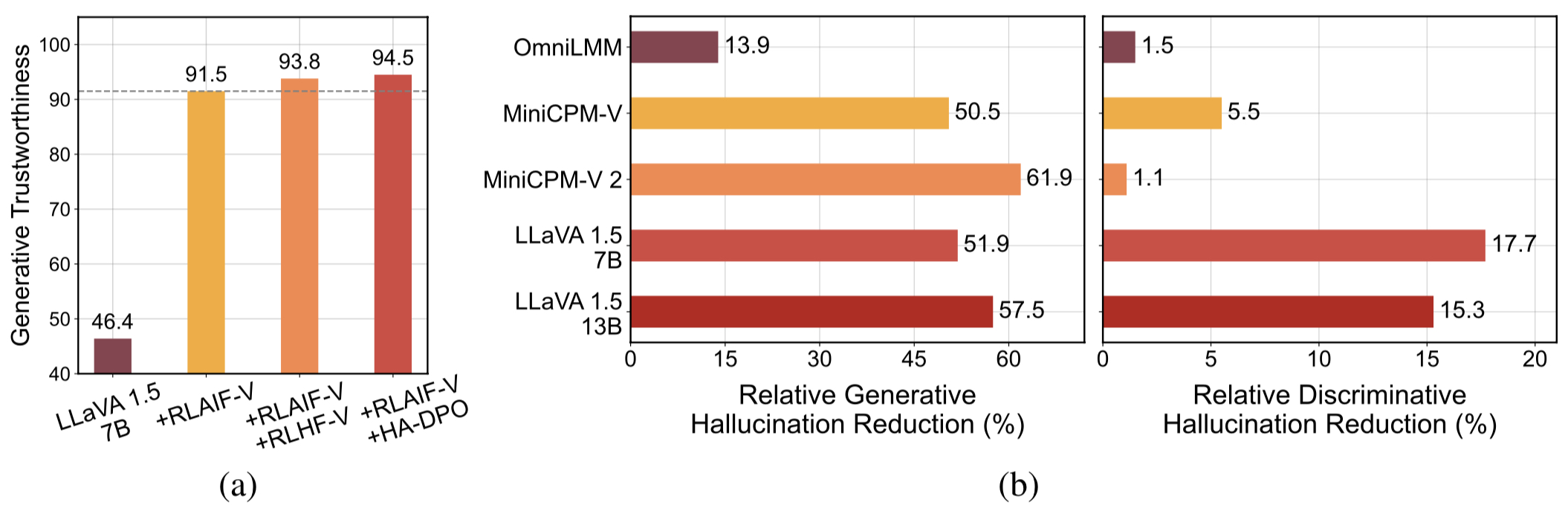
Hochwertige verallgemeinerbare Feedback-Daten . Die von RLAIF-V verwendeten Feedback-Daten reduzieren wirksam die Halluzination verschiedener MLLMs .
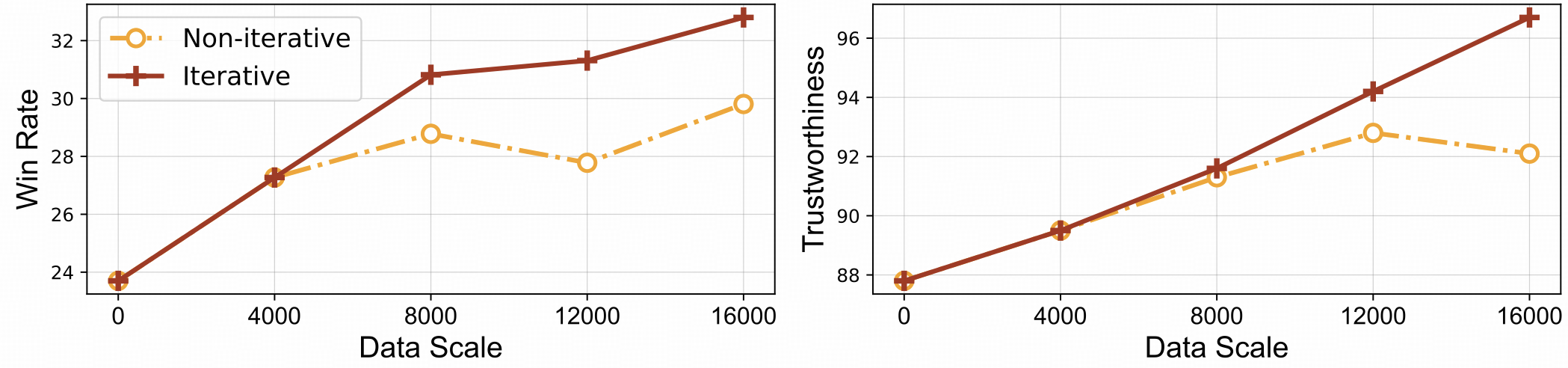
⚡️ Effizientes Feedback-Lernen mit iterativer Ausrichtung. RLAIF-V weist im Vergleich zum nicht-iterativen Ansatz sowohl eine bessere Lerneffizienz als auch eine höhere Leistung auf.
Datensatz
Installieren
Modellgewichte
Schlussfolgerung
Datengenerierung
Zug
Auswertung
Objekt HalBench
MMHal-Bank
RefoMB
Zitat
Wir präsentieren den RLAIF-V-Datensatz, einen KI-generierten Präferenzdatensatz, der verschiedene Aufgaben und Bereiche abdeckt. Dieser Open-Source-Datensatz mit multimodalen Präferenzen enthält 83.132 hochwertige Vergleichspaare . Der Datensatz enthält die generierten Präferenzpaare in jeder Trainingsiteration verschiedener Modelle, einschließlich LLaVA 1.5 7B, OmniLMM 12B und MiniCPM-V.
Klonen Sie dieses Repository und navigieren Sie zum Ordner RLAIF-V
Git-Klon https://github.com/RLHF-V/RLAIF-V.gitcd RLAIF-V
Paket installieren
conda create -n rlaifv python=3.10 -y Conda aktiviert rlaifv pip install -e .
Installieren Sie das erforderliche spaCy-Modell
wget https://github.com/explosion/spacy-models/releases/download/en_core_web_trf-3.7.3/en_core_web_trf-3.7.3.tar.gz pip install en_core_web_trf-3.7.3.tar.gz
| Modell | Beschreibung | Herunterladen |
|---|---|---|
| RLAIF-V 7B | Die vertrauenswürdigste Variante von LLaVA 1.5 | ? |
| RLAIF-V 12B | Basiert auf OmniLMM-12B und erreicht eine hervorragende GPT-4V-Vertrauenswürdigkeit. | ? |
Wir zeigen anhand eines einfachen Beispiels, wie RLAIF-V verwendet wird.
from chat import RLAIFVChat, img2base64chat_model = RLAIFVChat('openBMB/RLAIF-V-7B') # or 'openBMB/RLAIF-V-12B'image_path="./examples/test.jpeg"msgs = "Beschreiben Sie detailliert die Personen in das Bild."inputs = {"image": image_path, "question": msgs}answer = chat_model.chat(Eingaben)print(Antwort)Sie können dieses Beispiel auch ausführen, indem Sie das folgende Skript ausführen:
Python chat.py

Frage:
Warum blieb das Auto auf dem Bild stehen?
Erwartete Ergebnisse:
Auf dem Bild hielt ein Auto auf der Straße an, weil sich ein Schaf auf der Fahrbahn befand. Das Auto hielt wahrscheinlich an, um den Schafen zu ermöglichen, sicher aus dem Weg zu gehen oder mögliche Unfälle mit dem Tier zu vermeiden. Diese Situation verdeutlicht, wie wichtig es ist, beim Fahren vorsichtig und aufmerksam zu sein, insbesondere in Gebieten, in denen Tiere in der Nähe von Straßen herumlaufen können.
Umgebungseinrichtung
Zur Feedbackgenerierung stellen wir das Modell OmniLMM 12B und das Modell MiniCPM-Llama3-V 2.5 zur Verfügung. Wenn Sie MiniCPM-Llama3-V 2.5 zum Geben von Feedback verwenden möchten, konfigurieren Sie bitte seine Inferenzumgebung gemäß den Anweisungen im MiniCPM-V-GitHub-Repository.
Bitte laden Sie unsere fein abgestimmten Llama3 8B-Modelle herunter: Split-Modell und Fragetransformationsmodell, und speichern Sie sie im Ordner ./models/llama3_split bzw. ./models/llama3_changeq .
Feedback zum OmniLMM 12B-Modell
Das folgende Skript demonstriert die Verwendung des LLaVA-v1.5-7b-Modells zur Generierung von Kandidatenantworten und des OmniLMM 12B-Modells zur Bereitstellung von Feedback.
mkdir ./results bash ./script/data_gen/run_data_pipeline_llava15_omni.sh
MiniCPM-Llama3-V 2.5 Modell-Feedback
Das folgende Skript demonstriert die Verwendung des LLaVA-v1.5-7b-Modells zum Generieren von Kandidatenantworten und des MiniCPM-Llama3-V 2.5-Modells zur Bereitstellung von Feedback. Ersetzen Sie zunächst minicpmv_python in ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh durch den Python-Pfad der von Ihnen erstellten MiniCPM-V-Umgebung.
mkdir ./results bash ./script/data_gen/run_data_pipeline_llava15_minicpmv.sh
Daten vorbereiten (optional)
Wenn Sie auf den Huggingface-Datensatz zugreifen können, können Sie diesen Schritt überspringen. Wir laden dann automatisch den RLAIF-V-Datensatz herunter.
Wenn Sie den Datensatz bereits heruntergeladen haben, können Sie hier in Zeile 38 „openbmb/RLAIF-V-Dataset“ durch Ihren Datensatzpfad ersetzen.
Ausbildung
Hier stellen wir ein Trainingsskript zum Trainieren des Modells in einer Iteration bereit. Der Parameter max_step sollte entsprechend der Menge Ihrer Daten angepasst werden.
Vollständige Feinabstimmung
Führen Sie den folgenden Befehl aus, um mit der vollständigen Feinabstimmung zu beginnen.
bash ./script/train/llava15_train.sh
LoRA
Führen Sie den folgenden Befehl aus, um das Lora-Training zu starten.
pip install peft bash ./script/train/llava15_train_lora.sh
Iterative Ausrichtung
Um den iterativen Trainingsprozess in der Arbeit zu reproduzieren, müssen Sie die folgenden Schritte viermal ausführen:
S1. Datengenerierung.
Befolgen Sie die Anweisungen zur Datengenerierung, um Präferenzpaare für das Basismodell zu generieren. Konvertieren Sie die generierte JSONL-Datei in Huggingface-Parkett.
S2. Trainingskonfiguration ändern.
Ersetzen Sie im Datensatzcode hier 'openbmb/RLAIF-V-Dataset' durch Ihren Datenpfad.
Ersetzen Sie im Trainingsskript --data_dir durch ein neues Verzeichnis, ersetzen Sie --model_name_or_path durch den Basismodellpfad, setzen Sie --max_step auf die Anzahl der Schritte für 4 Epoche, setzen Sie --save_steps auf die Anzahl der Schritte für 1/4 Epoche .
S3. Machen Sie eine DPO-Schulung.
Führen Sie das Trainingsskript aus, um das Basismodell zu trainieren.
S4. Wählen Sie das Basismodell für die nächste Iteration.
Bewerten Sie jeden Prüfpunkt auf Object HalBench und MMHal Bench und wählen Sie den Prüfpunkt mit der besten Leistung als Basismodell in der nächsten Iteration aus.
Bereiten Sie COCO2014-Anmerkungen vor
Die Auswertung von Object HalBench basiert auf den Beschriftungs- und Segmentierungsanmerkungen aus dem COCO2014-Datensatz. Bitte laden Sie zunächst den COCO2014-Datensatz von der offiziellen Website des COCO-Datensatzes herunter.
mkdir coco2014cd coco2014 wget http://images.cocodataset.org/annotations/annotations_trainval2014.zip Entpacken Sie annotations_trainval2014.zip
Schlussfolgerung, Bewertung und Zusammenfassung
Bitte ersetzen Sie {YOUR_OPENAI_API_KEY} durch einen gültigen OpenAI-API-Schlüssel.
Hinweis: Die Auswertung basiert auf gpt-3.5-turbo-0613 .
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_objhal.sh ./RLAIF-V_weight ./results/RLAIF-V ./coco2014/annotations {YOUR_OPENAI_API_KEY}Bereiten Sie MMHal-Daten vor
Bitte laden Sie die MMHal-Bewertungsdaten hier herunter und speichern Sie die Datei unter eval/data .
Führen Sie das folgende Skript aus, um es für MMHal Bench zu generieren:
Hinweis: Die Auswertung basiert auf gpt-4-1106-preview .
# cd RLAIF-Vbash ./script/eval/eval_rlaifv_mmhal.sh ./RLAIF-V_weight ./results/RLAIF-V {YOUR_OPENAI_API_KEY}Vorbereitung
Um die GPT-4-Evaluierung zu verwenden, führen Sie bitte zuerst pip install openai==0.28 aus, um das Openai-Paket zu installieren. Als nächstes ändern Sie openai.base und openai.api_key in eval/gpt4.py in Ihre eigene Einstellung.
Evaluierungsdaten für den Entwicklungssatz finden Sie unter eval/data/RefoMB_dev.jsonl . Sie müssen jedes Bild über den Schlüssel image_url in jeder Zeile herunterladen.
Auswertung zur Gesamtnote
Speichern Sie Ihre Modellantwort im answer der Eingabedatendatei eval/data/RefoMB_dev.jsonl , zum Beispiel:
{
"image_url": "https://thunlp.oss-cn-qingdao.aliyuncs.com/multimodal_openmme_test_20240319__20.jpg",
"question": "What is the background of the image?",
"type": "Coarse Perception",
"split": "dev",
"answer": "The background of the image features trees, suggesting that the scene takes place outdoors.",
"gt_description": "......"
}Führen Sie das folgende Skript aus, um Ihr Modellergebnis auszuwerten:
save_dir="YOUR SAVING DIR" model_ans_path="YOUR MODEL ANSWER PATH" model_name="YOUR MODEL NAME" bash ./script/eval/run_refobm_overall.sh $save_dir $model_ans_path $model_name
Auswertung des Halluzinations-Scores
Nach Auswertung der Gesamtpunktzahl wird eine Bewertungsergebnisdatei mit dem Namen A-GPT-4V_B-${model_name}.json erstellt. Verwenden Sie diese Auswertungsergebnisdatei, um den Halluzinations-Score wie folgt zu berechnen:
eval_result="EVAL RESULT FILE PATH, e.g. 'A-GPT-4V_B-${model_name}'"
# Do not include ".json" in your file path!
bash ./script/eval/run_refomb_hall.sh $eval_resultHinweis: Für eine bessere Stabilität empfehlen wir Ihnen, mehr als dreimal zu bewerten und die Durchschnittsbewertung als endgültige Modellbewertung zu verwenden.
Nutzungs- und Lizenzhinweise : Die Daten, der Code und der Prüfpunkt sind nur für Forschungszwecke bestimmt und lizenziert. Sie sind außerdem auf Nutzungen beschränkt, die der Lizenzvereinbarung von LLaMA, Vicuna und Chat GPT folgen. Der Datensatz ist CC BY NC 4.0 (und erlaubt nur die nichtkommerzielle Nutzung) und Modelle, die mit dem Datensatz trainiert wurden, sollten nicht außerhalb von Forschungszwecken verwendet werden.
RLHF-V: Die Codebasis, auf der wir aufgebaut haben.
LLaVA: Das Anweisungsmodell und Etikettiermodell von RLAIF-V-7B.
MiniCPM-V: Das Anweisungsmodell und Etikettiermodell von RLAIF-V-12B.
Wenn Sie unser Modell/Code/Daten/Papier hilfreich finden, ziehen Sie bitte in Betracht, unsere Papiere zu zitieren und uns zu markieren ️!
@article{yu2023rlhf, title={Rlhf-v: Auf dem Weg zu vertrauenswürdigen mllms durch Verhaltensausrichtung durch feinkörniges korrigierendes menschliches Feedback}, Autor={Yu, Tianyu und Yao, Yuan und Zhang, Haoye und He, Taiwen und Han, Yifeng und Cui, Ganqu und Hu, Jinyi und Liu, Zhiyuan und Zheng, Hai-Tao und Sun, Maosong und andere}, journal={arXiv preprint arXiv:2312.00849}, Jahr={2023}}@article{yu2024rlaifv, title={RLAIF-V: Aligning MLLMs through Open-Source AI Feedback for Super GPT-4V Trustworthiness}, Autor={Yu, Tianyu und Zhang, Haoye und Yao, Yuan und Dang, Yunkai und Chen, Da und Lu, Xiaoman und Cui, Ganqu und He, Taiwen und Liu, Zhiyuan und Chua, Tat-Seng und Sun, Maosong}, Zeitschrift={arXiv preprint arXiv:2405.17220}, Jahr={2024},
}