ChatLM mini Chinese
1.0.0
Chinesisch |. Englisch
Heutige große Sprachmodelle neigen dazu, große Parameter zu haben, und Computer für Verbraucher sind langsam, wenn es darum geht, einfache Schlussfolgerungen zu ziehen, geschweige denn, ein Modell von Grund auf zu trainieren. Das Ziel dieses Projekts besteht darin, ein generatives Sprachmodell von Grund auf zu trainieren, einschließlich Datenbereinigung, Tokenizer-Training, Modell-Vortraining, Feinabstimmung von SFT-Anweisungen, RLHF-Optimierung usw.
ChatLM-mini-Chinese ist ein kleines chinesisches Dialogmodell mit nur 0,2 Milliarden Modellparametern (ca. 210 Millionen einschließlich gemeinsamer Gewichte). Es kann auf einem Computer mit mindestens 4 GB Videospeicher ( batch_size=1 , fp16 oder bf16 ) vorab trainiert werden ), und das Laden und Inferenzieren float16 erfordert mindestens 512 MB Videospeicher.
Huggingface NLP-Framework, einschließlich transformers , accelerate , trl , peft usw.trainer unterstützt das Vortraining und die SFT-Feinabstimmung auf einem einzelnen Computer mit einer einzelnen Karte oder mit mehreren Karten auf einem einzelnen Computer. Es unterstützt das Anhalten an jeder Position während des Trainings und das Fortsetzen des Trainings an jeder Position.Text-to-Text -Vortraining und das Vortraining für Nicht- mask -Vorhersage.sentencepiece und huggingface tokenizers .batch_size=1, max_len=320 wird das Vortraining auf einem Computer mit mindestens 16 GB Arbeitsspeicher + 4 GB Videospeicher unterstützt;trainer unterstützt die sofortige Feinabstimmung von Befehlen und unterstützt jeden Haltepunkt, um das Training fortzusetzen.Huggingface trainer sequence to sequence ;peft lora zur Präferenzoptimierung;Lora adapter kann mit dem Originalmodell zusammengeführt werden.Wenn Sie eine Retrieval Enhanced Generation (RAG) basierend auf kleinen Modellen durchführen müssen, können Sie auf mein anderes Projekt Phi2-mini-Chinese verweisen. Den Code finden Sie unter rag_with_langchain.ipynb
? Neueste Updates
Alle Datensätze stammen aus im Internet veröffentlichten Einzelrunden-Konversationsdatensätzen . Nach der Datenbereinigung und -formatierung werden sie als Parkettdateien gespeichert. Informationen zum Datenverarbeitungsprozess finden Sie utils/raw_data_process.py . Zu den wichtigsten Datensätzen gehören:
Belle_open_source_1M , train_2M_CN und train_3.5M_CN aus, die kurze Antworten haben, keine komplexen Tabellenstrukturen und Übersetzungsaufgaben enthalten (keine englische Vokabelliste), Insgesamt sind es 3,7 Millionen Reihen und nach der Reinigung verbleiben 3,38 Millionen Reihen.N Wörter der Enzyklopädie sind die Antworten. Unter Verwendung von 202309 Enzyklopädiedaten bleiben nach der Bereinigung 1,19 Millionen Eingabeaufforderungen und Antworten übrig. Wiki-Download: zhwiki, konvertieren Sie die heruntergeladene bz2-Datei in wiki.txt, Referenz: WikiExtractor. Die Gesamtzahl der Datensätze beträgt 10,23 Millionen: Text-zu-Text-Vortrainingssatz: 9,3 Millionen, Bewertungssatz: 25.000 (da die Dekodierung langsam ist, ist der Bewertungssatz nicht zu groß eingestellt). Testsatz: 900.000. Die SFT-Feinabstimmungs- und DPO-Optimierungsdatensätze werden unten angezeigt.
T5-Modell (Text-to-Text Transfer Transformer), Einzelheiten finden Sie im Artikel: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.
Der Quellcode des Modells stammt von Huggingface, siehe: T5ForConditionalGeneration.
Siehe model_config.json für die Modellkonfiguration. Die offizielle T5-base : encoder layer und decoder layer sind beide 12 Schichten. In diesem Projekt werden diese beiden Parameter auf 10 Schichten geändert.
Modellparameter: 0,2B. Größe der Wortliste: 29298, darunter nur Chinesisch und eine kleine Menge Englisch.
Hardware:
# 预训练阶段:
CPU: 28 vCPU Intel(R) Xeon(R) Gold 6330 CPU @ 2.00GHz
内存:60 GB
显卡:RTX A5000(24GB) * 2
# sft及dpo阶段:
CPU: Intel(R) i5-13600k @ 5.1GHz
内存:32 GB
显卡:NVIDIA GeForce RTX 4060 Ti 16GB * 1 Tokenizer-Training : Die vorhandene tokenizer Trainingsbibliothek weist OOM-Probleme auf, wenn ein großer Korpus auftritt. Daher wird der vollständige Korpus basierend auf der Worthäufigkeit gemäß einer BPE ähnlichen Methode zusammengeführt und erstellt, deren Ausführung einen halben Tag dauert.
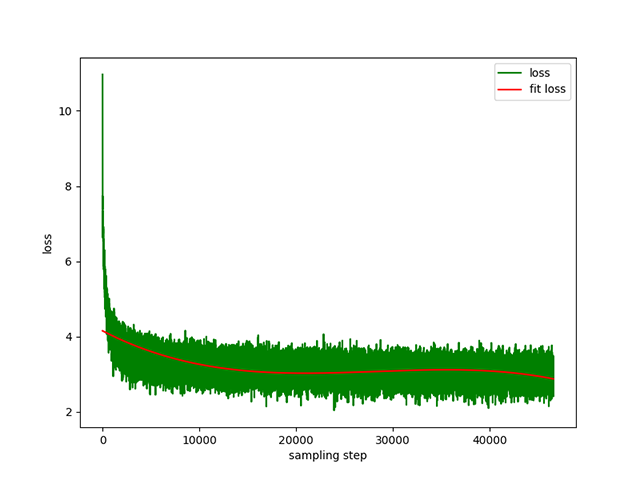
Text-zu-Text-Vortraining : Eine dynamische Lernrate von 1e-4 bis 5e-3 und eine Vortrainingszeit von 8 Tagen. Trainingsausfall:
belle -Instruction-Trainingsdatensatz (sowohl die Anweisungs- als auch die Antwortlänge liegen unter 512), die Lernrate ist eine dynamische Lernrate von 1e-7 bis 5e-5 und die Feinabstimmungszeit beträgt 2 Tage. Feinabstimmungsverlust: 
chosen Text verwendet. In Schritt 2 generate der SFT-Modellstapel die Eingabeaufforderungen im Datensatz und ruft den rejected Text ab Um die volle DPO-Präferenz zu optimieren und zu lernen, beträgt die Rate le-5 , halbe Genauigkeit fp16 , insgesamt 2 epoch , und es dauert 3 Stunden. DPO-Verlust: 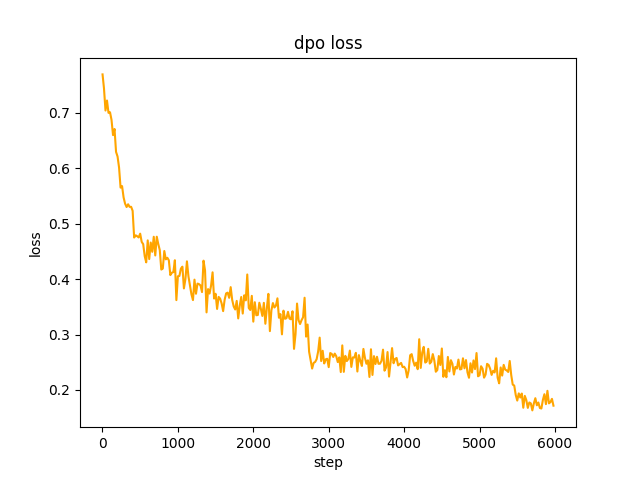
Standardmäßig wird TextIteratorStreamer von huggingface transformers zum Implementieren des Streaming-Dialogs verwendet, der nur greedy search unterstützt. Wenn Sie andere Generierungsmethoden wie beam sample benötigen, ändern Sie bitte den Parameter stream_chat von cli_demo.py in False . 

Es gibt Probleme: Der Datensatz vor dem Training umfasst nur mehr als 9 Millionen und die Modellparameter betragen nur 0,2 B. Er kann nicht alle Aspekte abdecken, und es wird Situationen geben, in denen die Antwort falsch ist und der Generator Unsinn ist.
Wenn Huggingface nicht verbunden werden kann, verwenden Sie modelscope.snapshot_download um die Modelldatei von Modelscope herunterzuladen.
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
import torch
model_id = 'charent/ChatLM-mini-Chinese'
# 如果无法连接huggingface,打开以下两行代码的注释,将从modelscope下载模型文件,模型文件保存到'./model_save'目录
# from modelscope import snapshot_download
# model_id = snapshot_download(model_id, cache_dir='./model_save')
device = torch . device ( 'cuda' if torch . cuda . is_available () else 'cpu' )
tokenizer = AutoTokenizer . from_pretrained ( model_id )
model = AutoModelForSeq2SeqLM . from_pretrained ( model_id , trust_remote_code = True ). to ( device )
txt = '如何评价Apple这家公司?'
encode_ids = tokenizer ([ txt ])
input_ids , attention_mask = torch . LongTensor ( encode_ids [ 'input_ids' ]), torch . LongTensor ( encode_ids [ 'attention_mask' ])
outs = model . my_generate (
input_ids = input_ids . to ( device ),
attention_mask = attention_mask . to ( device ),
max_seq_len = 256 ,
search_type = 'beam' ,
)
outs_txt = tokenizer . batch_decode ( outs . cpu (). numpy (), skip_special_tokens = True , clean_up_tokenization_spaces = True )
print ( outs_txt [ 0 ])Apple是一家专注于设计和用户体验的公司,其产品在设计上注重简约、流畅和功能性,而在用户体验方面则注重用户的反馈和使用体验。作为一家领先的科技公司,苹果公司一直致力于为用户提供最优质的产品和服务,不断推陈出新,不断创新和改进,以满足不断变化的市场需求。
在iPhone、iPad和Mac等产品上,苹果公司一直保持着创新的态度,不断推出新的功能和设计,为用户提供更好的使用体验。在iPad上推出的iPad Pro和iPod touch等产品,也一直保持着优秀的用户体验。
此外,苹果公司还致力于开发和销售软件和服务,例如iTunes、iCloud和App Store等,这些产品在市场上也获得了广泛的认可和好评。
总的来说,苹果公司在设计、用户体验和产品创新方面都做得非常出色,为用户带来了许多便利和惊喜。
Vorsicht
Das Modell dieses Projekts ist ein TextToText -Modell. Fügen Sie in den prompt , response und anderen Feldern in den Phasen Pre-Training, SFT und RLFH unbedingt die Sequenzendmarkierung [EOS] hinzu.
git clone --depth 1 https://github.com/charent/ChatLM-mini-Chinese.git
cd ChatLM-mini-Chinese Dieses Projekt empfiehlt die Verwendung von python 3.10 . Ältere Python-Versionen sind möglicherweise nicht mit den Bibliotheken von Drittanbietern kompatibel, von denen sie abhängig sind.
Pip-Installation:
pip install -r ./requirements.txtWenn pip die CPU-Version von Pytorch installiert hat, können Sie die CUDA-Version von Pytorch mit dem folgenden Befehl installieren:
# pip 安装torch + cu118
pip3 install torch --index-url https://download.pytorch.org/whl/cu118Conda-Installation:
conda install --yes --file ./requirements.txt Verwenden Sie den Befehl git , um die Modellgewichtungen und Konfigurationsdateien von Hugging Face Hub herunterzuladen. Sie müssen zuerst Git LFS installieren und dann Folgendes ausführen:
# 使用git命令下载huggingface模型,先安装[Git LFS],否则下载的模型文件不可用
git clone --depth 1 https://huggingface.co/charent/ChatLM-mini-Chinese
# 如果无法连接huggingface,请从modelscope下载
git clone --depth 1 https://www.modelscope.cn/charent/ChatLM-mini-Chinese.git
mv ChatLM-mini-Chinese model_save Sie können es auch manuell direkt aus dem Hugging Face Hub Warehouse ChatLM-Chinese-0.2B herunterladen und die heruntergeladene Datei in das Verzeichnis model_save verschieben.
Die Korpusanforderungen sollten so vollständig wie möglich sein. Es wird empfohlen, mehrere Korpusse wie Enzyklopädien, Codes, Aufsätze, Blogs, Konversationen usw. hinzuzufügen.
Dieses Projekt basiert hauptsächlich auf der chinesischen Wiki-Enzyklopädie. So erhalten Sie den chinesischen Wiki-Korpus: Chinesische Wiki-Download-Adresse: zhwiki, laden Sie zhwiki-[存档日期]-pages-articles-multistream.xml.bz2 herunter, ca. 2,7 GB, konvertieren Sie die heruntergeladene bz2-Datei in wiki.txt, Referenz: WikiExtractor Verwenden Sie dann OpenCC -Bibliothek von Python, um es in vereinfachtes Chinesisch zu konvertieren, und legen Sie schließlich die erhaltene wiki.simple.txt im data des Projektstammverzeichnisses ab. Bitte führen Sie mehrere Korpora selbst zu einer txt Datei zusammen.
Da der Trainings-Tokenizer viel Speicher verbraucht, wird empfohlen, den Korpus nach Kategorien und Proportionen abzutasten, wenn Ihr Korpus sehr groß ist (die zusammengeführte txt Datei überschreitet 2 GB), um die Trainingszeit und den Speicherverbrauch zu reduzieren. Das Trainieren einer 1,7-GB- txt Datei erfordert etwa 48 GB Arbeitsspeicher (geschätzt, ich habe nur 32 GB, löse häufig den Austausch aus, der Computer bleibt lange hängen T_T), eine 13600-k-CPU dauert etwa 1 Stunde.
Der Unterschied zwischen char level und byte level ist wie folgt (bitte suchen Sie selbst nach Informationen zu spezifischen Nutzungsunterschieden). Der Tokenizer trainiert standardmäßig char level . Wenn byte level erforderlich ist, legen Sie einfach token_type='byte' in train_tokenizer.py fest.
# 原始文本
txt = '这是一段中英混输的句子, (chinese and English, here are words.)'
tokens = charlevel_tokenizer . tokenize ( txt )
print ( tokens )
# char level tokens输出
# ['▁这是', '一段', '中英', '混', '输', '的', '句子', '▁,', '▁(', '▁ch', 'inese', '▁and', '▁Eng', 'lish', '▁,', '▁h', 'ere', '▁', 'are', '▁w', 'ord', 's', '▁.', '▁)']
tokens = bytelevel_tokenizer . tokenize ( txt )
print ( tokens )
# byte level tokens输出
# ['Ġè¿Ļæĺ¯', 'ä¸Ģ段', 'ä¸Ńèĭ±', 'æ··', 'è¾ĵ', 'çļĦ', 'åı¥åŃIJ', 'Ġ,', 'Ġ(', 'Ġch', 'inese', 'Ġand', 'ĠEng', 'lish', 'Ġ,', 'Ġh', 'ere', 'Ġare', 'Ġw', 'ord', 's', 'Ġ.', 'Ġ)']Mit dem Training beginnen:
# 确保你的训练语料`txt`文件已经data目录下
python train_tokenizer . py {
"prompt" : "对于花园街,你有什么了解或看法吗? " ,
"response" : "花园街(是香港油尖旺区的一条富有特色的街道,位于九龙旺角东部,北至界限街,南至登打士街,与通菜街及洗衣街等街道平行。现时这条街道是香港著名的购物区之一。位于亚皆老街以南的一段花园街,也就是"波鞋街"整条街约150米长,有50多间售卖运动鞋和运动用品的店舖。旺角道至太子道西一段则为排档区,售卖成衣、蔬菜和水果等。花园街一共分成三段。明清时代,花园街是芒角村栽种花卉的地方。此外,根据历史专家郑宝鸿的考证:花园街曾是1910年代东方殷琴拿烟厂的花园。纵火案。自2005年起,花园街一带最少发生5宗纵火案,当中4宗涉及排档起火。2010年。2010年12月6日,花园街222号一个卖鞋的排档于凌晨5时许首先起火,浓烟涌往旁边住宅大厦,消防接报4 "
}jupyter-lab oder jupyter-notebook:
Siehe die Datei train.ipynb . Es wird empfohlen, jupyter-lab zu verwenden, um zu vermeiden, dass der Terminalprozess nach der Trennung vom Server abgebrochen wird.
Konsole:
Beim Konsolentraining muss berücksichtigt werden, dass der Prozess nach dem Trennen der Verbindung abgebrochen wird. Es wird empfohlen, zum Aufbau einer Verbindungssitzung das Prozess-Daemon-Tool Supervisor oder screen zu verwenden.
Konfigurieren Sie zunächst accelerate , führen Sie den folgenden Befehl aus und wählen Sie ihn entsprechend den accelerate.yaml aus. Hinweis: Die Installation von DeepSpeed ist unter Windows schwieriger .
accelerate config Beginnen Sie mit dem Training. Wenn Sie die vom Projekt bereitgestellte Konfiguration verwenden möchten, fügen Sie bitte den Parameter --config_file ./accelerate.yaml nach dem folgenden Befehl hinzu accelerate launch . Die Konfiguration basiert auf der 2xGPU-Konfiguration für eine einzelne Maschine.
Es gibt zwei Skripte für das Vortraining. Der in diesem Projekt implementierte Trainer entspricht train.py und der von Huggingface implementierte Trainer entspricht pre_train.py . Sie können eines davon verwenden und haben den gleichen Effekt. Der in diesem Projekt implementierte Trainer zeigt schönere Trainingsinformationen an und erleichtert die Änderung von Trainingsdetails (z. B. Verlustfunktionen, Protokolldatensätze usw.). Alle unterstützen Haltepunkte, um das Training nach einem fortzusetzen Haltepunkt an einer beliebigen Position. Drücken Sie ctrl+c um Haltepunktinformationen beim Verlassen des Skripts zu speichern.
Einzelmaschine und Einzelkarte:
# 本项目实现的trainer
accelerate launch ./train.py train
# 或者使用 huggingface trainer
python pre_train.py Einzelne Maschine mit mehreren Karten: 2 ist die Anzahl der Grafikkarten, bitte ändern Sie sie entsprechend Ihrer tatsächlichen Situation.
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train
# 或者使用 huggingface trainer
accelerate launch --multi_gpu --num_processes 2 pre_train.pyVom Haltepunkt aus weiter trainieren:
# 本项目实现的trainer
accelerate launch --multi_gpu --num_processes 2 ./train.py train --is_keep_training=True
# 或者使用 huggingface trainer
# 需要在`pre_train.py`中的`train`函数添加`resume_from_checkpoint=True`
accelerate launch --multi_gpu --num_processes 2 pre_train.pyDer SFT-Datensatz stammt vollständig aus dem Beitrag von BELLE-Chef, vielen Dank. Die SFT-Datensätze sind: generic_chat_0.4M, train_0.5M_CN und train_2M_CN, wobei nach der Bereinigung etwa 1,37 Millionen Zeilen übrig bleiben. Beispiel für die Feinabstimmung eines Datensatzes mit dem Befehl sft:
{
"prompt" : "解释什么是欧洲启示录" ,
"response" : "欧洲启示录(The Book of Revelation)是新约圣经的最后一卷书,也被称为《启示录》、《默示录》或《约翰默示录》。这本书从宗教的角度描述了世界末日的来临,以及上帝对世界的审判和拯救。 书中的主题包括来临的基督的荣耀,上帝对人性的惩罚和拯救,以及魔鬼和邪恶力量的存在。欧洲启示录是一个充满象征和暗示的文本,对于解读和理解有许多不同的方法和观点。 "
} Erstellen Sie Ihren eigenen Datensatz, indem Sie auf die Beispiel- parquet im data verweisen. Das Datensatzformat ist: parquet ist in zwei Spalten unterteilt, eine Spalte mit prompt , der die Eingabeaufforderung darstellt, und eine Spalte mit response . Dies stellt die erwartete Modellausgabe dar. Einzelheiten zur Feinabstimmung finden Sie in der train unter model/trainer.py . Wenn is_finetune auf True gesetzt ist, werden bei der Feinabstimmung standardmäßig die Einbettungsebene und die Encoderebene eingefroren und nur der Decoder trainiert Schicht. Wenn Sie andere Parameter einfrieren müssen, passen Sie den Code bitte selbst an.
Führen Sie die SFT-Feinabstimmung durch:
# 本项目实现的trainer, 添加参数`--is_finetune=True`即可, 参数`--is_keep_training=True`可从任意断点处继续训练
accelerate launch --multi_gpu --num_processes 2 ./train.py --is_finetune=True
# 或者使用 huggingface trainer, 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 sft_train.py
python sft_train.pyHier sind zwei gängige bevorzugte Methoden: PPO und DPO. Bitte suchen Sie in Artikeln und Blogs nach bestimmten Implementierungen.
PPO-Methode (ungefähre Präferenzoptimierung, Proximal Policy Optimization)
Schritt 1: Verwenden Sie den Feinabstimmungsdatensatz, um eine überwachte Feinabstimmung durchzuführen (SFT, Supervised Finetuning).
Schritt 2: Verwenden Sie den Präferenzdatensatz (eine Eingabeaufforderung enthält mindestens zwei Antworten, eine gewünschte Antwort und eine unerwünschte Antwort. Mehrere Antworten können nach Punktzahl sortiert werden, wobei die meistgesuchte Antwort die höchste Punktzahl hat), um das Belohnungsmodell (RM) zu trainieren , Belohnungsmodell). Mit der peft -Bibliothek können Sie schnell das Lora-Belohnungsmodell erstellen.
Schritt 3: Führen Sie mit RM ein überwachtes PPO-Training für das SFT-Modell durch, damit das Modell den Präferenzen entspricht.
Verwenden Sie die DPO-Feinabstimmung (Direct Preference Optimization) ( dieses Projekt verwendet die DPO-Feinabstimmungsmethode, die Videospeicher spart ). Basierend auf dem Erhalt des SFT-Modells ist es nicht erforderlich, das Belohnungsmodell zu trainieren, um positive Antworten zu erhalten (). ausgewählt) und negative Antworten (abgelehnt), um mit der Feinabstimmung zu beginnen. Der fein abgestimmte chosen Text stammt aus dem Originaldatensatz alpaca-gpt4-data-zh, und der rejected Text stammt aus der Modellausgabe nach der SFT-Feinabstimmung für eine Epoche. Die anderen beiden Datensätze: huozi_rlhf_data_json und rlhf-reward- single-round-trans_chinese, nach dem Zusammenführen Insgesamt 80.000 DPO-Daten.
Informationen zum Verarbeitungsprozess des DPO-Datensatzes finden Sie utils/dpo_data_process.py .
Beispiel für einen DPO-Präferenzoptimierungsdatensatz:
{
"prompt" : "为给定的产品创建一个创意标语。,输入:可重复使用的水瓶。 " ,
"chosen" : " "保护地球,从拥有可重复使用的水瓶开始! " " ,
"rejected" : " "让你的水瓶成为你的生活伴侣,使用可重复使用的水瓶,让你的水瓶成为你的伙伴" "
}Führen Sie die Präferenzoptimierung aus:
# 多GPU请用accelerate launch --multi_gpu --num_processes gpu个数 dpo_train.py
python dpo_train.py Stellen Sie sicher, dass sich die folgenden Dateien im Verzeichnis model_save befinden. Diese Dateien befinden sich im Hugging Face Hub Warehouse ChatLM-Chinese-0.2B:
ChatLM-mini-Chinese
├─model_save
| ├─config.json
| ├─configuration_chat_model.py
| ├─generation_config.json
| ├─model.safetensors
| ├─modeling_chat_model.py
| ├─special_tokens_map.json
| ├─tokenizer.json
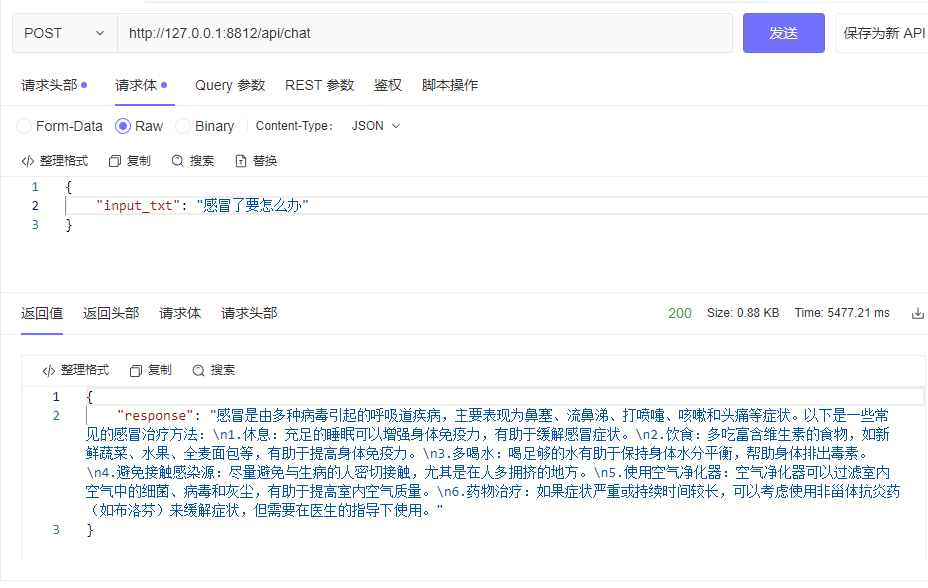
| └─tokenizer_config.jsonpython cli_demo.pypython api_demo.pyBeispiel für einen API-Aufruf:
curl --location ' 127.0.0.1:8812/api/chat '
--header ' Content-Type: application/json '
--header ' Authorization: Bearer Bearer '
--data ' {
"input_txt": "感冒了要怎么办"
} ' 
Hier nehmen wir die Triplett-Informationen im Text als Beispiel für eine nachgelagerte Feinabstimmung. Informationen zur herkömmlichen Deep-Learning-Extraktionsmethode für diese Aufgabe finden Sie im Warehouse pytorch_IE_model. Extrahieren Sie alle Tripel in einem Textstück, wie zum Beispiel den Satz 《写生随笔》是冶金工业2006年出版的图书,作者是张来亮. Extrahieren Sie die Tripel (写生随笔,作者,张来亮) und (写生随笔,出版社,冶金工业) .
Der Originaldatensatz ist: Baidu-Dreifachextraktionsdatensatz. Beispiel für das verarbeitete, fein abgestimmte Datensatzformat:
{
"prompt" : "请抽取出给定句子中的所有三元组。给定句子:《家乡的月亮》是宋雪莱演唱的一首歌曲,所属专辑是《久违的哥们》 " ,
"response" : " [(家乡的月亮,歌手,宋雪莱),(家乡的月亮,所属专辑,久违的哥们)] "
} Sie können das Skript sft_train.py zur Feinabstimmung direkt verwenden. Das Skript finetune_IE_task.ipynb enthält den detaillierten Dekodierungsprozess. Der Trainingsdatensatz umfasst etwa 17000 Elemente, die Lernrate 5e-5 und die Trainingsepoche 5 . Die Dialogfähigkeiten anderer Aufgaben sind nach der Feinabstimmung nicht verschwunden.

Feinabstimmungseffekt: Verwenden Sie den von Baidu veröffentlichten dev百度三元组抽取数据集als Testsatz für den Vergleich mit der herkömmlichen Methode pytorch_IE_model.
| Modell | F1-Ergebnis | Präzision P | Erinnern Sie sich an R |
|---|---|---|---|
| ChatLM-Chinese-0.2B Feinabstimmung | 0,74 | 0,75 | 0,73 |
| ChatLM-Chinese-0.2B ohne Vorschulung | 0,51 | 0,53 | 0,49 |
| Traditionelle Deep-Learning-Methoden | 0,80 | 0,79 | 80.1 |
Hinweis: ChatLM-Chinese-0.2B无预训练bedeutet, dass zufällige Parameter direkt initialisiert werden und das Training mit einer Lernrate von 1e-4 beginnt. Andere Parameter stehen im Einklang mit der Feinabstimmung.
Das Modell selbst wird nicht anhand eines größeren Datensatzes trainiert und ist auch nicht auf die Anweisungen zur Beantwortung von Multiple-Choice-Fragen abgestimmt. Der C-Eval-Score ist grundsätzlich ein Basisniveau und kann bei Bedarf als Referenz verwendet werden. C-Eval-Bewertungscode siehe: eval/c_eavl.ipynb
| Kategorie | richtig | Frage_Anzahl | Genauigkeit |
|---|---|---|---|
| Geisteswissenschaften | 63 | 257 | 24,51 % |
| Andere | 89 | 384 | 23,18 % |
| STÄNGEL | 89 | 430 | 20,70 % |
| Sozialwissenschaft | 72 | 275 | 26,18 % |
Wenn Sie glauben, dass dieses Projekt für Sie hilfreich ist, zitieren Sie es bitte.
@misc{Charent2023,
author={Charent Chen},
title={A small chinese chat language model with 0.2B parameters base on T5},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/ChatLM-mini-Chinese}},
}
Dieses Projekt trägt keine Risiken und Verantwortlichkeiten, die sich aus Datensicherheit und Risiken für die öffentliche Meinung ergeben, die durch Open-Source-Modelle und -Codes oder durch Irreführung, Missbrauch, Verbreitung oder missbräuchliche Nutzung von Modellen verursacht werden.


