wink nlp
Operational update
WinkNLP ist eine JavaScript-Bibliothek für Natural Language Processing (NLP). winkNLP wurde speziell dafür entwickelt, die Entwicklung von NLP-Anwendungen einfacher und schneller zu machen und ist für die richtige Balance zwischen Leistung und Genauigkeit optimiert.
Die Unterstützung für die Worteinbettung ermöglicht eine tiefergehende Textanalyse. Stellen Sie Wörter und Text problemlos als numerische Vektoren dar und sorgen Sie so für eine höhere Genauigkeit bei Aufgaben wie semantischer Ähnlichkeit, Textklassifizierung und mehr – sogar innerhalb eines Browsers .
Es ist von Grund auf ohne externe Abhängigkeit aufgebaut und verfügt über eine schlanke Codebasis von ca. 10 KB, minimiert und komprimiert. Eine Testabdeckung von ~100 % und die Einhaltung der Best Practices der Open Source Security Foundation machen winkNLP zum idealen Werkzeug für den sicheren Aufbau produktionstauglicher Systeme.
WinkNLP mit vollständiger Typescript-Unterstützung, läuft auf Node.js, Webbrowsern und Deno.
| Zeitleiste des Wikipedia-Artikels | Kontextbewusste Wortwolke | Erkennung von Schlüsselsätzen |
|---|---|---|
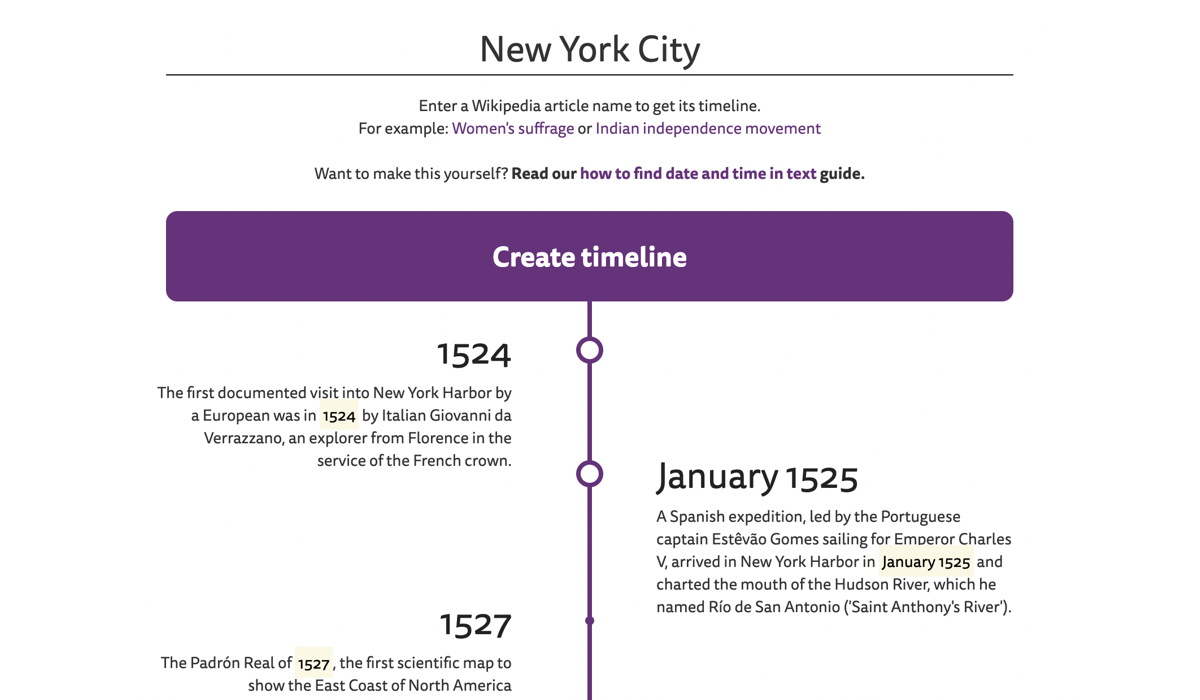 |  |  |
Gehen Sie zu den Live-Beispielen, um mehr darüber zu erfahren.
WinkNLP kann problemlos große Mengen Rohtext mit Geschwindigkeiten von über 650.000 Tokens/Sekunde auf einem M1 Macbook Pro sowohl in Browser- als auch in Node.js-Umgebungen verarbeiten. Es läuft sogar problemlos im Browser eines Low-End-Smartphones.
| Umfeld | Benchmarking-Befehl |
|---|---|
| Node.js | Knoten-Benchmark/Lauf |
| Browser | Wie misst man die Geschwindigkeit von winkNLP in Browsern? |
WinkNLP verfügt über eine umfassende NLP-Pipeline (Natural Language Processing), die Tokenisierung, Satzgrenzenerkennung (sbd), Negationsbehandlung, Stimmungsanalyse, Wortart-Tagging (pos), benannte Entitätserkennung (ner) und benutzerdefinierte Entitätserkennung (cer) umfasst. . Es bietet einen umfangreichen Funktionsumfang:
| ? Schneller, verlustfreier und mehrsprachiger Tokenizer | Beispielsweise wird die mehrsprachige Textzeichenfolge "¡Hola! नमस्कार! Hi! Bonjour chéri" als ["¡", "Hola", "!", "नमस्कार", "!", "Hi", "!", "Bonjour", "chéri"] . Der Tokenizer verarbeitet Text mit einer Geschwindigkeit von nahezu 4 Millionen Token/Sekunde im Browser eines M1 MBP. |
| Entwicklerfreundliche und intuitive API | Verarbeiten Sie mit winkNLP jeden Text mit einer einfachen, deklarativen Syntax; Die meisten Live-Beispiele bestehen aus 30–40 Zeilen Code. |
| ? Erstklassige Textvisualisierung | Markieren Sie Token, Sätze, Entitäten usw. programmgesteuert mit einer HTML-Markierung oder einem anderen Tag Ihrer Wahl. |
| ♻️ Umfangreiche Textverarbeitungsfunktionen | Entfernen und/oder behalten Sie Token mit bestimmten Attributen wie Wortart, benanntem Entitätstyp, Tokentyp, Stoppwort, Form und vielem mehr; Berechnen Sie den Flesch-Lesbarkeitswert; n-Gramm generieren; normalisieren, lemmatisieren oder stammeln. Erfahren Sie, wie mit der richtigen Art der Textvorverarbeitung sogar der Naive-Bayes-Klassifikator eine beeindruckende Genauigkeit (≥90 %) bei Stimmungsanalysen und Chatbot-Absichtsklassifizierungsaufgaben erreicht. |
| ? Vorab trainierte Sprachmodelle | Kompakte Größen ab ca. 1 MB (minimiert und gzippt) – reduzieren die Ladezeit des Modells drastisch auf ca. 1 Sekunde in einem 4G-Netzwerk. |
| 100-dimensionale englische Worteinbettungen für über 350.000 englische Wörter, die für winkNLP optimiert sind. Ermöglicht die einfache Berechnung von Satz- oder Dokumenteinbettungen. |
Verwenden Sie npm install:
npm install wink-nlp --saveUm winkNLP nach der Installation verwenden zu können, müssen Sie außerdem ein Sprachmodell entsprechend der verwendeten Knotenversion installieren. Die folgende Tabelle beschreibt den versionspezifischen Installationsbefehl:
| Node.js-Version | Installation |
|---|---|
| 16 oder 18 | npm install wink-eng-lite-web-model --save |
| 14 oder 12 | node -e "require('wink-nlp/models/install')" |
Das wink-eng-lite-web-model ist für die Verwendung mit Node.js Version 16 oder 18 konzipiert. Es kann auch auf Browsern funktionieren, wie im nächsten Abschnitt beschrieben. Dies ist das empfohlene Modell.
Der zweite Befehl installiert das wink-eng-lite-model, das mit Node.js Version 14 oder 12 funktioniert.
Aktivieren Sie esModuleInterop allowSyntheticDefaultImports in der Datei tsconfig.json :
"compilerOptions": {
"esModuleInterop": true,
"allowSyntheticDefaultImports": true,
...
}
Wenn Sie winkNLP im Browser verwenden, verwenden Sie das wink-eng-lite-web-model. Erfahren Sie mehr über die Installation und Verwendung in unserem Leitfaden zur Verwendung von winkNLP im Browser. Entdecken Sie winkNLP-Rezepte auf Observable für browserbasierte Live-Beispiele.
Folgen Sie dem Beispiel auf replit.
Hier ist das „Hallo Welt!“ von winkNLP:
// Load wink-nlp package.
const winkNLP = require ( 'wink-nlp' ) ;
// Load english language model.
const model = require ( 'wink-eng-lite-web-model' ) ;
// Instantiate winkNLP.
const nlp = winkNLP ( model ) ;
// Obtain "its" helper to extract item properties.
const its = nlp . its ;
// Obtain "as" reducer helper to reduce a collection.
const as = nlp . as ;
// NLP Code.
const text = 'Hello World?! How are you?' ;
const doc = nlp . readDoc ( text ) ;
console . log ( doc . out ( ) ) ;
// -> Hello World?! How are you?
console . log ( doc . sentences ( ) . out ( ) ) ;
// -> [ 'Hello World?!', 'How are you?' ]
console . log ( doc . entities ( ) . out ( its . detail ) ) ;
// -> [ { value: '?', type: 'EMOJI' } ]
console . log ( doc . tokens ( ) . out ( ) ) ;
// -> [ 'Hello', 'World', '?', '!', 'How', 'are', 'you', '?' ]
console . log ( doc . tokens ( ) . out ( its . type , as . freqTable ) ) ;
// -> [ [ 'word', 5 ], [ 'punctuation', 2 ], [ 'emoji', 1 ] ]Experimentieren Sie mit winkNLP auf RunKit.
Das winkNLP verarbeitet Rohtext mit seinem wink-eng-lite-web-Modell mit ~650.000 Token pro Sekunde , wenn es mit „Ch 13 of Ulysses by James Joyce“ auf einem M1 Macbook Pro-Rechner mit 16 GB RAM verglichen wird. Die Verarbeitung umfasste die gesamte NLP-Pipeline – Tokenisierung, Satzgrenzenerkennung, Negationsbehandlung, Sentimentanalyse, Wortart-Tagging und Extraktion benannter Entitäten. Diese Geschwindigkeit liegt weit über den vorherrschenden Geschwindigkeits-Benchmarks.
Der Benchmark wurde mit den Node.js-Versionen 16 und 18 durchgeführt.
Es markiert eine Teilmenge des WSJ-Korpus mit einer Genauigkeit von ~95 % – dies beinhaltet die Tokenisierung von Rohtext vor dem Pos-Tagging . Der aktuelle Stand der Technik liegt bei etwa 97 % Genauigkeit, jedoch bei geringeren Geschwindigkeiten, und wird im Allgemeinen mit einem vortokenisierten Goldstandard-Korpus berechnet.
Die allgemeine Sentiment-Analyse liefert einen f-Score von ~84,5 % , wenn sie mithilfe des Amazon Product Review Sentiment Labeled Sentences Data Set im UCI Machine Learning Repository validiert wird. Die aktuelle Benchmark-Genauigkeit für speziell trainierte Modelle kann etwa 95 % betragen.
Wink NLP liefert diese Leistung bei minimaler RAM-Belastung. Beispielsweise verarbeitet es die gesamte History of India Volume I mit einem Gesamtspitzenspeicherbedarf von unter 80 MB . Das Buch hat rund 350 Seiten, was über 125.000 Token entspricht.
Bitte fragen Sie bei Stack Overflow nach, diskutieren Sie bei Wink JS GitHub Discussions oder chatten Sie mit uns bei Wink JS Gitter Lobby.
Wenn Sie einen Fehler entdecken und dieser noch nicht gemeldet wurde, melden Sie ein neues Problem oder ziehen Sie in Betracht, ihn zu beheben und eine PR zu senden.
Suchen Sie nach einer neuen Funktion, fordern Sie diese über das Diskussionsforum für neue Funktionen und Ideen an oder erwägen Sie, Mitwirkender zu werden.
WinkJS ist eine Familie von Open-Source-Paketen für die Verarbeitung natürlicher Sprache , maschinelles Lernen und statistische Analyse in NodeJS. Der Code ist gründlich dokumentiert, damit er für den Menschen leicht verständlich ist, und verfügt über eine Testabdeckung von ~100 %, um die Zuverlässigkeit bei der Erstellung produktionstauglicher Lösungen zu gewährleisten.
Wink NLP unterliegt dem Urheberrecht 2017-24 GRAYPE Systems Private Limited.
Es ist unter den Bedingungen der MIT-Lizenz lizenziert.


