dialog eval
1.0.0
Ein leichtgewichtiges Repo zur automatischen Bewertung von Dialogmodellen anhand von 17 Metriken .
? Wählen Sie aus, welche Metriken berechnet werden sollen
Die Auswertung kann automatisch entweder für eine Antwortdatei oder ein Verzeichnis mit mehreren Dateien ausgeführt werden
? Metriken werden in einem vordefinierten, einfach zu verarbeitenden Format gespeichert
Führen Sie diesen Befehl aus, um die erforderlichen Pakete zu installieren:
pip install -r requirements.txt
Die Hauptdatei kann von überall aufgerufen werden, aber wenn Sie Pfade zu Verzeichnissen angeben, sollten Sie diese vom Stammverzeichnis des Repositorys aus angeben.
python code/main.py -h
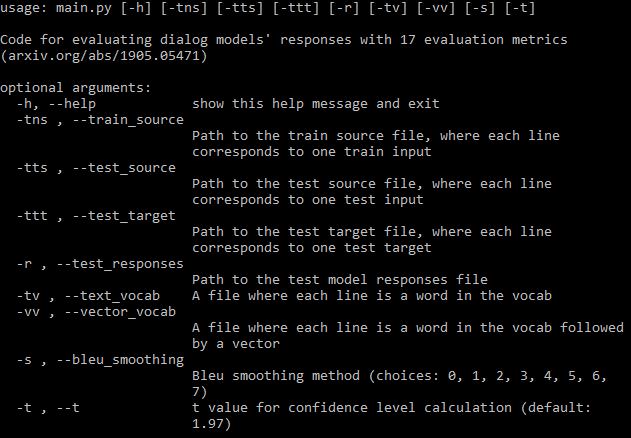
Die vollständige Dokumentation finden Sie im Wiki.
Sie sollten so viele der erforderlichen Argumentpfade (Bild oben) wie möglich angeben. Wenn Sie einige übersehen, wird das Programm weiterhin ausgeführt, berechnet jedoch einige Metriken, die diese Dateien erfordern, nicht (diese Metriken werden gedruckt). Wenn Sie über eine Trainingsdatendatei verfügen, kann das Programm automatisch ein Vokabular generieren und FastText-Einbettungen herunterladen.
Wenn Sie nicht alle Metriken berechnen möchten, können Sie ganz einfach in der Konfigurationsdatei festlegen, welche Metriken berechnet werden sollen.
Eine Datei wird in dem Verzeichnis gespeichert, in dem sich die Antwortdatei(en) befinden. Die erste Zeile enthält die Namen der Metriken, dann enthält jede Zeile die Metriken für eine Datei. Auf den Namen der Datei folgen die einzelnen Metrikwerte, getrennt durch Leerzeichen. Jede Metrik besteht aus drei durch Kommas getrennten Zahlen: dem Mittelwert, der Standardabweichung und dem Konfidenzintervall. Sie können den t-Wert des Konfidenzintervalls in den Argumenten festlegen, der Standardwert ist 95 % Konfidenz.
Interessanterweise verbessern sich alle 17 Metriken bis zu einem bestimmten Punkt und stagnieren dann, ohne dass es während des Trainings eines Transformer-Modells auf DailyDialog zu einer Überanpassung kommt. Die Abbildungen finden Sie im Anhang der Arbeit. 
TRF ist das Transformer-Modell, das beim Validierungsverlustminimum bewertet wird, und TRF-O ist das Transformer-Modell, das nach 150 Trainingsepochen ausgewertet wird, in denen die Metriken zu stagnieren beginnen. RT bedeutet zufällig ausgewählte Antworten aus dem Trainingssatz und GT bedeutet Ground-Truth-Antworten.

TRF ist das Transformer-Modell, während RT zufällig ausgewählte Antworten aus dem Trainingssatz und GT Ground-Truth-Antworten bedeutet. Diese Ergebnisse werden am Testsatz an einem Kontrollpunkt gemessen, an dem der Validierungsverlust minimal war.

TRF ist das Transformer-Modell, während RT zufällig ausgewählte Antworten aus dem Trainingssatz und GT Ground-Truth-Antworten bedeutet. Diese Ergebnisse werden am Testsatz an einem Kontrollpunkt gemessen, an dem der Validierungsverlust minimal war.
Neue Metriken können hinzugefügt werden, indem eine Klasse für die Metrik erstellt wird, die die Berechnung der gegebenen Metrikdaten übernimmt. Ein Beispiel finden Sie in den BLEU-Metriken. Normalerweise übernimmt die Init-Funktion alle Dateneinstellungen, die später benötigt werden, und update_metrics aktualisiert das Metrik-Dikt anhand des aktuellen Beispiels aus den Argumenten. Innerhalb der Klasse sollten Sie das Diktat self.metrics definieren, das Listen mit Metrikwerten für eine bestimmte Testdatei speichert. Die Namen dieser Metriken (Schlüssel des Wörterbuchs) sollten auch in der Konfigurationsdatei zu self.metrics hinzugefügt werden. Schließlich müssen Sie self.objects eine Instanz Ihrer Metrikklasse hinzufügen. Hier können Sie bei der Initialisierung Pfade zu Datendateien verwenden, wenn Ihre Metrik eine Einrichtung erfordert. Danach sollte Ihre Metrik automatisch berechnet und gespeichert werden.
Sie sollten Ihrer Metrik jedoch auch einige Einschränkungen hinzufügen, z. B. wenn eine für die Berechnung der Metrik erforderliche Datei fehlt, sollte der Benutzer benachrichtigt werden, wie hier.
Dieses Projekt ist unter der MIT-Lizenz lizenziert – Einzelheiten finden Sie in der LIZENZ-Datei.
Bitte fügen Sie einen Link zu diesem Repo hinzu, wenn Sie es in Ihrer Arbeit verwenden und erwägen Sie, das folgende Dokument zu zitieren:
@inproceedings{Csaky:2019,
title = "Improving Neural Conversational Models with Entropy-Based Data Filtering",
author = "Cs{'a}ky, Rich{'a}rd and Purgai, Patrik and Recski, G{'a}bor",
booktitle = "Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2019",
address = "Florence, Italy",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P19-1567",
pages = "5650--5669",
}


