Transformer in generating dialogue
1.0.0
Der Code ist eine Implementierung von Paper. Aufmerksamkeit ist alles, was Sie für Dialoggenerierungsaufgaben wie Chatbot , Textgenerierung usw. benötigen.
Vielen Dank an alle Freunde, die Probleme angesprochen und bei der Lösung geholfen haben. Ihr Beitrag ist für die Verbesserung dieses Projekts sehr wichtig. Aufgrund der begrenzten Unterstützung des „statischen Diagrammmodus“ in der Codierung haben wir uns entschieden, die Funktionen auf die Version 2.0.0-beta1 zu verschieben. Wenn Sie sich jedoch Sorgen über die Probleme bei der Docker-Erstellung und der Diensterstellung mit Versionsproblemen machen, behalten wir als Referenz immer noch eine alte Version des Codes bei, der im Eager-Modus unter Verwendung der Tensorflow-Version 1.12.x geschrieben wurde.
|-- root/
|-- data/
|-- src-train.csv
|-- src-val.csv
|-- tgt-train.csv
`-- tgt-val.csv
|-- old_version/
|-- data_loader.py
|-- eval.py
|-- make_dic.py
|-- modules.py
|-- params.py
|-- requirements.txt
`-- train.py
|-- tf1.12.0-eager/
|-- bleu.py
|-- main.ipynb
|-- modules.py
|-- params.py
|-- requirements.txt
`-- utils.py
|-- images/
|-- bleu.py
|-- main-v2.ipynb
|-- modules-v2.py
|-- params.py
|-- requirements.txt
`-- utils-v2.py
Wie wir alle wissen, kann das Übersetzungssystem zur Implementierung eines Konversationsmodells verwendet werden, indem einfach das Paris von zwei verschiedenen Sätzen durch Fragen und Antworten ersetzt wird. Schließlich wurde das grundlegende Konversationsmodell mit dem Namen „Sequence-to-Sequence“ aus einem Übersetzungssystem entwickelt. Warum sollten wir daher nicht die Effizienz des Konversationsmodells bei der Generierung von Dialogen verbessern?
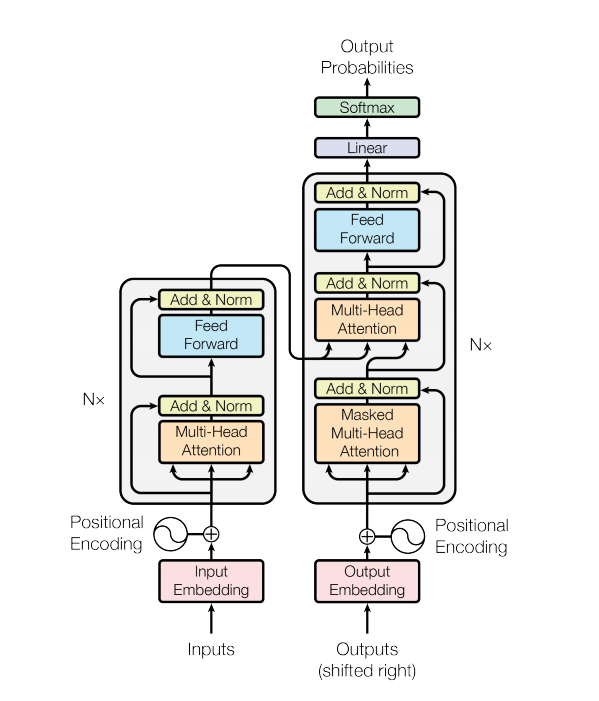
Mit der Entwicklung BERT-basierter Modelle werden immer mehr NLP-Aufgaben ständig aktualisiert. Das Sprachmodell ist jedoch nicht in den Open-Source-Aufgaben von BERT enthalten. Es besteht kein Zweifel, dass wir auf diesem Weg noch einen langen Weg vor uns haben.
Ein Transformatormodell verarbeitet Eingaben variabler Größe mithilfe von Stapeln von Selbstaufmerksamkeitsschichten anstelle von RNNs oder CNNs. Diese allgemeine Architektur hat eine Reihe von Vorteilen und besonderen Merkmalen. Jetzt nehmen wir sie raus:
In der neuesten Version unseres Codes vervollständigen wir die in Papierform beschriebenen Details.
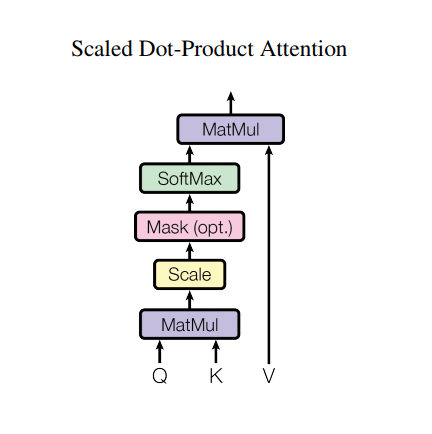
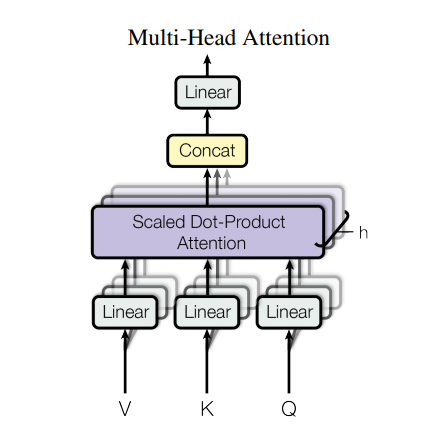
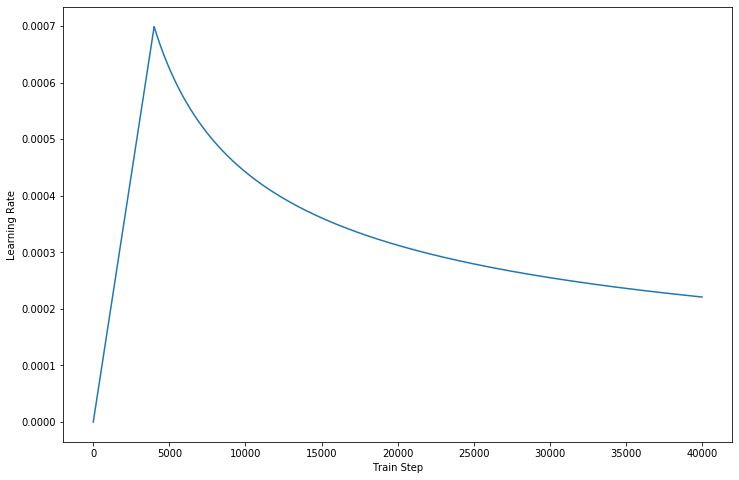
Allerdings hat eine so starke Architektur immer noch einige Nachteile:
data/ .params.py an, wenn Sie möchten.make_dic.py aus, um Vokabeldateien in einem neuen Ordner mit dem Namen dictionary zu generieren.train.py aus, um das Modell zu erstellen. Checkpoint wird im checkpoint Ordner gespeichert, während die Tensorflow-Ereignisdateien im logdir zu finden sind.eval.py aus, um das Ergebnis mit Testdaten auszuwerten. Das Ergebnis wird im Results gespeichert.GPU verwenden, um die Trainingsverarbeitung zu beschleunigen, richten Sie Ihr Gerät bitte im Code ein. (Es unterstützt die Schulung mehrerer Mitarbeiter.) - Source: 肥 宅 初 夜 可 以 賣 多 少 `
- Ground Truth: 肥 宅 還 是 去 打 手 槍 吧
- Predict: 肥 宅 還 是 去 打 手 槍 吧
- Source: 兇 的 女 生 484 都 很 胸
- Ground Truth: 我 看 都 是 醜 的 比 較 凶
- Predict: 我 看 都 是 醜 的 比 較 <UNK>
- Source: 留 髮 不 留 頭
- Ground Truth: 還 好 我 早 就 禿 頭 了
- Predict: 還 好 我 早 就 禿 頭 了
- Source: 當 人 好 痛 苦 R 的 八 卦
- Ground Truth: 去 中 國 就 不 用 當 人 了
- Predict: 去 中 國 就 不 會 有 了 -
- Source: 有 沒 有 今 天 捷 運 的 八 卦
- Ground Truth: 有 - 真 的 有 多
- Predict: 有 - 真 的 有 多
- Source: 2016 帶 走 了 什 麼 `
- Ground Truth: HellKitty 麥 當 勞 歡 樂 送 開 門 -
- Predict: <UNK> 麥 當 勞 歡 樂 送 開 門 -
- Source: 有 沒 有 多 益 很 賺 的 八 卦
- Ground Truth: 比 大 型 包 裹 貴
- Predict: 比 大 型 包 <UNK> 貴
- Source: 邊 緣 人 收 到 地 震 警 報 了
- Ground Truth: 都 跑 到 窗 邊 了 才 來
- Predict: 都 跑 到 <UNK> 邊 了 才 來
- Source: 車 震
- Ground Truth: 沒 被 刪 版 主 是 有 眼 睛 der
- Predict: 沒 被 刪 版 主 是 有 眼 睛 der
- Source: 在 家 跌 倒 的 八 卦 `
- Ground Truth: 傷 到 腦 袋 - 可 憐
- Predict: 傷 到 腦 袋 - 可 憐
- Source: 大 家 很 討 厭 核 核 嗎 `
- Ground Truth: 核 核 欠 幹 阿
- Predict: 核 核 欠 幹 阿
- Source: 館 長 跟 黎 明 打 誰 贏 -
- Ground Truth: 我 愛 黎 明 - 我 愛 黎 明 -
- Predict: 我 愛 <UNK> 明 - 我 愛 <UNK> 明 -
- Source: 嘻 嘻 打 打
- Ground Truth: 媽 的 智 障 姆 咪 滾 喇 幹
- Predict: 媽 的 智 障 姆 咪 滾 喇 幹
- Source: 經 典 電 影 台 詞
- Ground Truth: 超 時 空 要 愛 裡 滿 滿 的 梗
- Predict: 超 時 空 要 愛 裡 滿 滿 滿 的
- Source: 2B 守 得 住 街 亭 嗎 `
- Ground Truth: 被 病 毒 滅 亡 真 的 會 -
- Predict: <UNK> 守 得 住
Wenn Sie AutoGraph verwenden, um Ihren Trainingsprozess zu beschleunigen, stellen Sie bitte sicher, dass die Datensätze auf eine feste Länge aufgefüllt werden. Aufgrund des Diagrammwiederherstellungsvorgangs wird während des Trainings aktiviert, was sich auf die Leistung auswirken kann. Unser Code stellt nur die Leistung von Version 2.0 sicher, und die niedrigeren Versionen können versuchen, darauf zu verweisen.
Danke für Transformer und Tensorflow


