customer support chatbot
1.0.0
Chatbot ist ein Computerprogramm, das ein Gespräch auf menschenähnliche Weise führt. Dieses Projekt implementiert einen Chatbot, der als Kundendienstmitarbeiter versucht, Benutzerfragen zu beantworten. Folgende Kundensupport-Chatbots wurden implementiert: AppleSupport, AmazonHelp, Uber_Support, Delta und SpotifyCares. Chatbots wurden anhand öffentlich zugänglicher Gespräche zwischen Kundensupport und Benutzern auf Twitter trainiert.
Chatbot wird als Sequenz-zu-Sequenz-Deep-Learning-Modell mit Aufmerksamkeit implementiert. Das Projekt basiert größtenteils auf Bahdanau et al. 2014, Luong et al. 2015. und Vinyals et al., 2015.
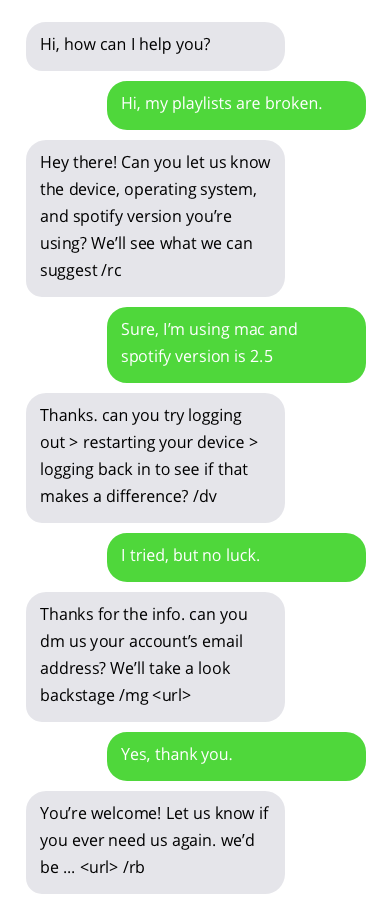
Beispielgespräche mit Kundensupport-Chatbots. Gespräche mit Chatbots sind nicht ideal, zeigen aber vielversprechende Ergebnisse. Chatbot-Antworten werden in grauen Blasen angezeigt.
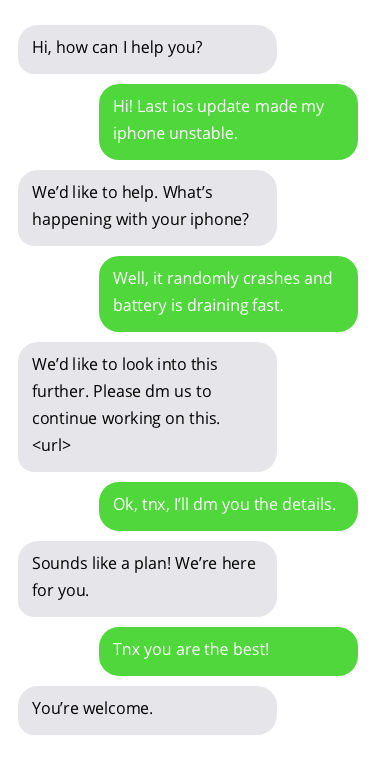
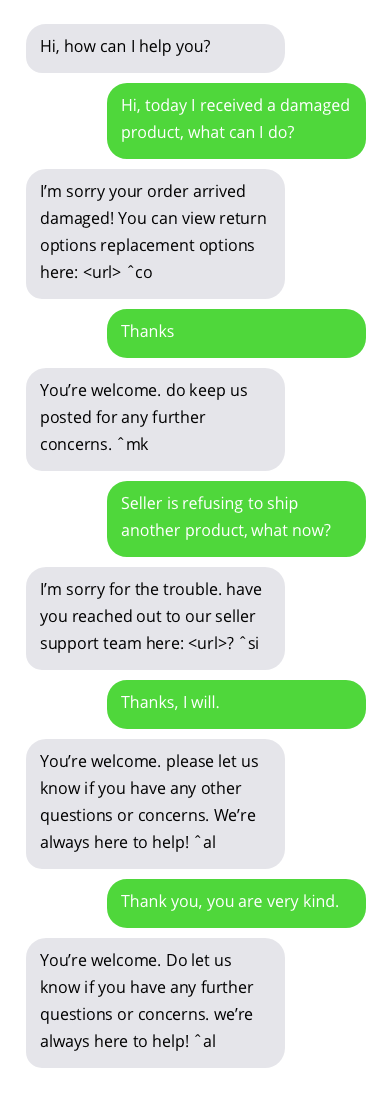
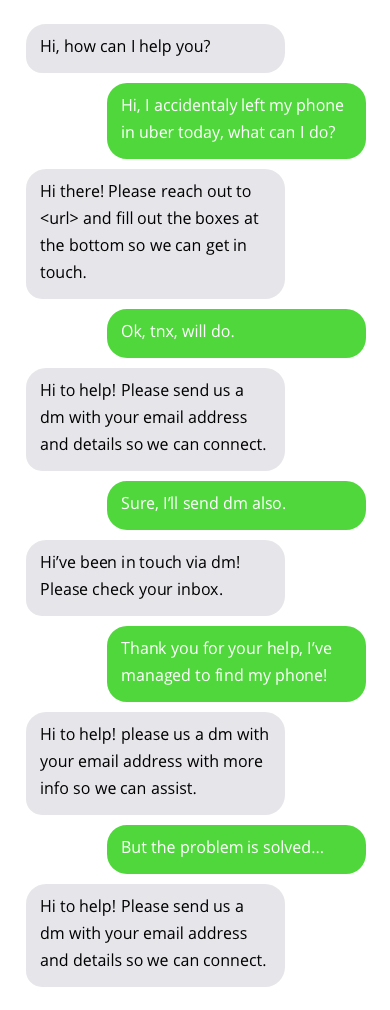
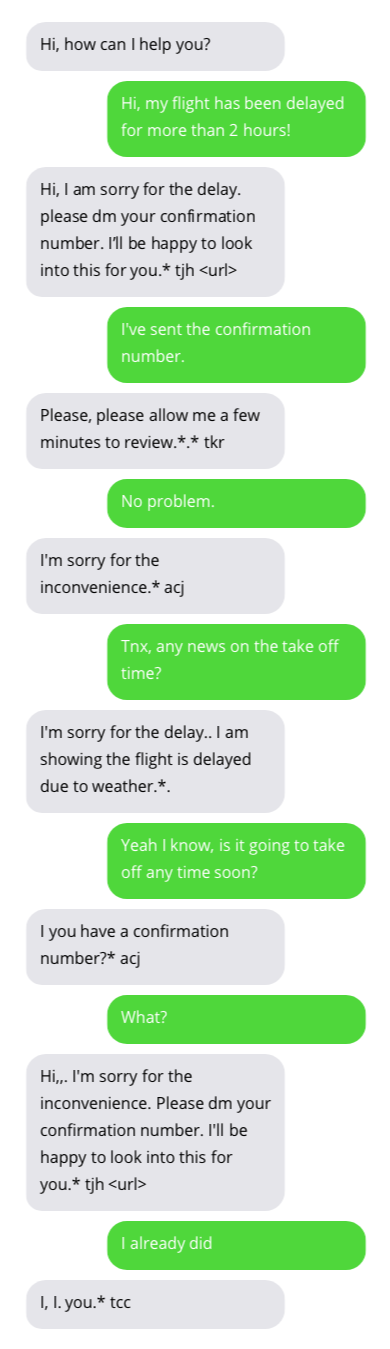
Den zum Training des Chatbots verwendeten Datensatz finden Sie hier. Dieser Datensatz wurde durch das Sammeln öffentlich zugänglicher Gespräche zwischen Kundensupports und Benutzern auf Twitter erstellt. Vielen Dank an den Autor des Datensatzes!
Sie können den Chatbot ausprobieren, indem Sie vorab trainierte Modelle verwenden oder Ihren eigenen Chatbot trainieren.
pip3 install -r requirements.txt
python3 -m spacy download enFühren Sie die folgenden Befehle im Stammverzeichnis dieses Repositorys aus, um vorab trainierte Kundenservice-Chatbots herunterzuladen.
wget https://www.dropbox.com/s/ibm49gx1gefpqju/pretrained-models.zip
unzip pretrained-models.zip
rm pretrained-models.zip
sudo chmod +x predict.py Jetzt können Sie mithilfe des predict.py -Skripts mit Kundendienst-Chatbots „sprechen“. Folgende Kundendienst-Chatbots sind verfügbar: apple,amazon,uber,delta,spotify . Das folgende Beispiel zeigt, wie apple -Kundendienst-Chatbot ausgeführt wird:
./predict.py -cs appleSie können den Chatbot selbst trainieren. Führen Sie die folgenden Befehle aus, um den in diesem Projekt verwendeten Twitter-Datensatz herunterzuladen und zu formatieren:
wget https://www.dropbox.com/s/nmnlcncn7jtb7i9/twcs.zip
unzip twcs.zip
mkdir data
mv twcs.csv data
rm twcs.zip
python3 datasets/twitter_customer_support/format.py # this runs for couple of hours
sudo chmod +x train.pyACHTUNG: Dieser Block wird einige Stunden lang ausgeführt!
Jetzt können Sie train.py verwenden, um den Chatbot zu trainieren.
train.py wird zum Training des seq2seq-Chatbots verwendet.
usage: train.py [-h] [--max-epochs MAX_EPOCHS] [--gradient-clip GRADIENT_CLIP]
[--batch-size BATCH_SIZE] [--learning-rate LEARNING_RATE]
[--train-embeddings] [--save-path SAVE_PATH]
[--save-every-epoch]
[--dataset {twitter-applesupport,twitter-amazonhelp,twitter-delta,twitter-spotifycares,twitter-uber_support,twitter-all,twitter-small}]
[--teacher-forcing-ratio TEACHER_FORCING_RATIO] [--cuda]
[--multi-gpu]
[--embedding-type {glove.42B.300d,glove.840B.300d,glove.twitter.27B.25d,glove.twitter.27B.50d,glove.twitter.27B.100d,glove.twitter.27B.200d,glove.6B.50d,glove.6B.100d,glove.6B.200d,glove.6B.300d} | --embedding-size EMBEDDING_SIZE]
[--encoder-rnn-cell {LSTM,GRU}]
[--encoder-hidden-size ENCODER_HIDDEN_SIZE]
[--encoder-num-layers ENCODER_NUM_LAYERS]
[--encoder-rnn-dropout ENCODER_RNN_DROPOUT]
[--encoder-bidirectional] [--decoder-type {bahdanau,luong}]
[--decoder-rnn-cell {LSTM,GRU}]
[--decoder-hidden-size DECODER_HIDDEN_SIZE]
[--decoder-num-layers DECODER_NUM_LAYERS]
[--decoder-rnn-dropout DECODER_RNN_DROPOUT]
[--luong-attn-hidden-size LUONG_ATTN_HIDDEN_SIZE]
[--luong-input-feed]
[--decoder-init-type {zeros,bahdanau,adjust_pad,adjust_all}]
[--attention-type {none,global,local-m,local-p}]
[--attention-score {dot,general,concat}]
[--half-window-size HALF_WINDOW_SIZE]
[--local-p-hidden-size LOCAL_P_HIDDEN_SIZE]
[--concat-attention-hidden-size CONCAT_ATTENTION_HIDDEN_SIZE]
Script for training seq2seq chatbot.
optional arguments:
-h, --help show this help message and exit
--max-epochs MAX_EPOCHS
Max number of epochs models will be trained.
--gradient-clip GRADIENT_CLIP
Gradient clip value.
--batch-size BATCH_SIZE
Batch size.
--learning-rate LEARNING_RATE
Initial learning rate.
--train-embeddings Should gradients be propagated to word embeddings.
--save-path SAVE_PATH
Folder where models (and other configs) will be saved
during training.
--save-every-epoch Save model every epoch regardless of validation loss.
--dataset {twitter-applesupport,twitter-amazonhelp,twitter-delta,twitter-spotifycares,twitter-uber_support,twitter-all,twitter-small}
Dataset for training model.
--teacher-forcing-ratio TEACHER_FORCING_RATIO
Teacher forcing ratio used in seq2seq models. [0-1]
--embedding-type {glove.42B.300d,glove.840B.300d,glove.twitter.27B.25d,glove.twitter.27B.50d,glove.twitter.27B.100d,glove.twitter.27B.200d,glove.6B.50d,glove.6B.100d,glove.6B.200d,glove.6B.300d}
Pre-trained embeddings type.
--embedding-size EMBEDDING_SIZE
Dimensionality of word embeddings.
GPU:
GPU related settings.
--cuda Use cuda if available.
--multi-gpu Use multiple GPUs if available.
Encoder:
Encoder hyperparameters.
--encoder-rnn-cell {LSTM,GRU}
Encoder RNN cell type.
--encoder-hidden-size ENCODER_HIDDEN_SIZE
Encoder RNN hidden size.
--encoder-num-layers ENCODER_NUM_LAYERS
Encoder RNN number of layers.
--encoder-rnn-dropout ENCODER_RNN_DROPOUT
Encoder RNN dropout probability.
--encoder-bidirectional
Use bidirectional encoder.
Decoder:
Decoder hyperparameters.
--decoder-type {bahdanau,luong}
Type of the decoder.
--decoder-rnn-cell {LSTM,GRU}
Decoder RNN cell type.
--decoder-hidden-size DECODER_HIDDEN_SIZE
Decoder RNN hidden size.
--decoder-num-layers DECODER_NUM_LAYERS
Decoder RNN number of layers.
--decoder-rnn-dropout DECODER_RNN_DROPOUT
Decoder RNN dropout probability.
--luong-attn-hidden-size LUONG_ATTN_HIDDEN_SIZE
Luong decoder attention hidden projection size
--luong-input-feed Whether Luong decoder should use input feeding
approach.
--decoder-init-type {zeros,bahdanau,adjust_pad,adjust_all}
Decoder initial RNN hidden state initialization.
Attention:
Attention hyperparameters.
--attention-type {none,global,local-m,local-p}
Attention type.
--attention-score {dot,general,concat}
Attention score function type.
--half-window-size HALF_WINDOW_SIZE
D parameter from Luong et al. paper. Used only for
local attention.
--local-p-hidden-size LOCAL_P_HIDDEN_SIZE
Local-p attention hidden size (used when predicting
window position).
--concat-attention-hidden-size CONCAT_ATTENTION_HIDDEN_SIZE
Attention layer hidden size. Used only with concat
score function.
predict.py wird zum „Sprechen“ mit dem seq2seq-Chatbot verwendet.
usage: predict.py [-h] [-cs {apple,amazon,uber,delta,spotify}] [-p MODEL_PATH]
[-e EPOCH] [--sampling-strategy {greedy,random,beam_search}]
[--max-seq-len MAX_SEQ_LEN] [--cuda]
Script for "talking" with pre-trained chatbot.
optional arguments:
-h, --help show this help message and exit
-cs {apple,amazon,uber,delta,spotify}, --customer-service {apple,amazon,uber,delta,spotify}
-p MODEL_PATH, --model-path MODEL_PATH
Path to directory with model args, vocabulary and pre-
trained pytorch models.
-e EPOCH, --epoch EPOCH
Model from this epoch will be loaded.
--sampling-strategy {greedy,random,beam_search}
Strategy for sampling output sequence.
--max-seq-len MAX_SEQ_LEN
Maximum length for output sequence.
--cuda Use cuda if available.


