Seq2seq Chatbot for Keras
1.0.0
Dieses Repository enthält ein neues generatives Chatbot-Modell basierend auf der seq2seq-Modellierung. Weitere Einzelheiten zu diesem Modell finden Sie in Abschnitt 3 des Dokuments „End-to-end Adversarial Learning for Generative Conversational Agents“. Im Falle einer Veröffentlichung, die Ideen oder Codeteile aus diesem Repository verwendet, zitieren Sie bitte dieses Dokument.
Das hier verfügbare trainierte Modell verwendete einen kleinen Datensatz bestehend aus ca. 8.000 Kontextpaaren (die letzten beiden Äußerungen des Dialogs bis zum aktuellen Punkt) und entsprechenden Antworten. Die Daten wurden aus Dialogen von Online-Englischkursen gesammelt. Dieses trainierte Modell kann mithilfe eines geschlossenen Domänendatensatzes an reale Anwendungen angepasst werden.
Das kanonische seq2seq-Modell wurde in der neuronalen maschinellen Übersetzung populär, einer Aufgabe, die unterschiedliche A-priori-Wahrscheinlichkeitsverteilungen für die Wörter aufweist, die zu den Eingabe- und Ausgabesequenzen gehören, da die Eingabe- und Ausgabeäußerungen in verschiedenen Sprachen verfasst sind. Die hier vorgestellte Architektur geht von denselben vorherigen Verteilungen für Eingabe- und Ausgabewörter aus. Daher teilt es durch die Einführung eines neuen Modells eine Einbettungsschicht (vorab trainierte Worteinbettung von Glove) zwischen den Kodierungs- und Dekodierungsprozessen. Um die Kontextsensitivität zu verbessern, kodiert der Gedankenvektor (also der Encoder-Ausgang) die letzten beiden Äußerungen des Gesprächs bis zum aktuellen Punkt. Um zu vermeiden, dass der Kontext bei der Antwortgenerierung vergessen wird, wird der Gedankenvektor zu einem dichten Vektor verkettet, der die bis zum aktuellen Punkt generierte unvollständige Antwort kodiert. Der resultierende Vektor wird dichten Schichten bereitgestellt, die den aktuellen Token der Antwort vorhersagen. Einen besseren Einblick in die Vorteile unseres Modells finden Sie in Abschnitt 3.1 unseres Dokuments.
Der Algorithmus iteriert, indem er das vorhergesagte Token in die unvollständige Antwort einbezieht und es an die rechte Eingabeebene des unten gezeigten Modells zurückgibt.
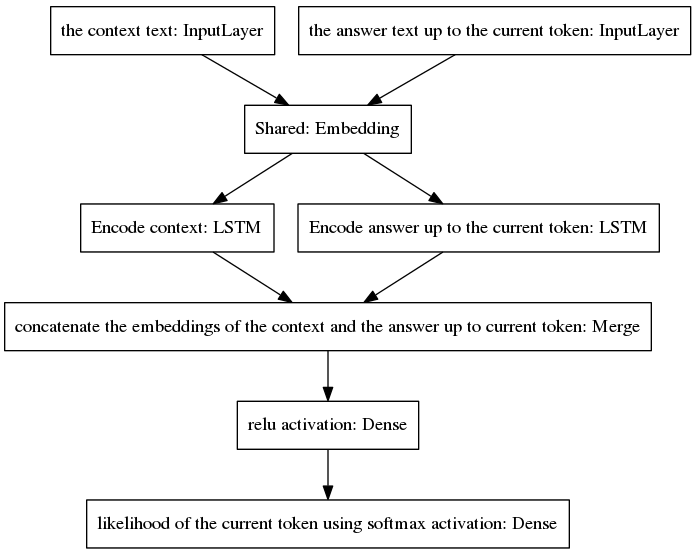
Wie in der Abbildung oben zu sehen ist, sind die beiden LSTMs parallel angeordnet, während beim kanonischen seq2seq die wiederkehrenden Schichten von Encoder und Decoder in Reihe angeordnet sind. Wiederkehrende Schichten werden während der zeitlichen Rückausbreitung entfaltet, was zu einer großen Anzahl verschachtelter Funktionen und damit einem höheren Risiko eines verschwindenden Gradienten führt, was durch die Kaskade wiederkehrender Schichten des kanonischen seq2seq-Modells sogar im Fall von Gated-Architekturen noch verschlimmert wird wie die LSTMs. Ich glaube, das ist einer der Gründe, warum sich mein Modell beim Training besser verhält als das kanonische seq2seq.
Der folgende Pseudocode erläutert den Algorithmus.

Das Training dieses neuen Modells konvergiert in wenigen Epochen. Unter Verwendung unseres Datensatzes von 8K-Trainingsbeispielen waren nur 100 Epochen erforderlich, um einen kategorialen Kreuzentropieverlust von 0,0318 zu erreichen, was 139 s/Epoche bei der Ausführung auf einer GTX980-GPU kostete. Die Leistung dieses trainierten Modells (in diesem Repository bereitgestellt) scheint genauso überzeugend wie die Leistung eines Vanilla-seq2seq-Modells, das auf den ~300.000 Trainingsbeispielen des Cornell Movie Dialogs Corpus trainiert wurde, erfordert jedoch viel weniger Rechenaufwand für das Training.
So chatten Sie mit dem vorab trainierten Modell:
Laden Sie die Python-Datei „conversation.py“, die Vokabeldatei „vocabulary_movie“ und die Nettogewichte „my_model_weights20“ herunter, die Sie hier finden.
Führen Sie „conversation.py“ aus.
So chatten Sie mit dem neuen Modell, das von unserem neuen GAN-basierten Trainingsalgorithmus trainiert wurde:
Laden Sie die Python-Datei „conversation_discriminator.py“, die Vokabeldatei „vocabulary_movie“ und die Nettogewichte „my_model_weights20.h5“, „my_model_weights.h5“ und „my_model_weights_discriminator.h5“ herunter, die Sie hier finden.
Führen Sie „conversation_discriminator.py“ aus.
Dieses Modell weist bei Verwendung derselben Trainingsdaten eine bessere Leistung auf. Der Diskriminator des GAN-basierten Modells wird verwendet, um die beste Antwort zwischen zwei Modellen auszuwählen, von denen eines durch Lehrerzwang trainiert wurde und das andere durch unsere neue GAN-ähnliche Trainingsmethode trainiert wurde, deren Einzelheiten in diesem Artikel zu finden sind.
So trainieren Sie ein neues Modell oder optimieren Ihre eigenen Daten:
Wenn Sie von Grund auf trainieren möchten, löschen Sie die Datei my_model_weights20.h5. Bewahren Sie diese Datei zur Feinabstimmung Ihrer Daten auf;
Laden Sie den Glove-Ordner „glove.6B“ herunter und fügen Sie diesen Ordner in das Verzeichnis des Chatbots ein (diesen Ordner finden Sie hier). Dieser Algorithmus wendet Transferlernen an, indem er eine vorab trainierte Worteinbettung verwendet, die während des Trainings fein abgestimmt wird;
Führen Sie split_qa.py aus, um den Inhalt Ihrer Trainingsdaten in zwei Dateien aufzuteilen: „context“ und „answers“ und get_train_data.py, um die aufgefüllten Sätze in den Dateien „Padded_context“ und „Padded_answers“ zu speichern.
Führen Sie train_bot.py aus, um den Chatbot zu trainieren (es wird die Verwendung einer GPU empfohlen, geben Sie dazu Folgendes ein: THEANO_FLAGS=mode=FAST_RUN,device=gpu,floatX=float32,Exception_verbosity=high python train_bot.py);
Benennen Sie Ihre Trainingsdaten als „data.txt“. Diese Datei muss eine Dialogäußerung pro Zeile enthalten. Wenn Ihr Datensatz groß ist, setzen Sie die Variable num_subsets (in Zeile 29 von train_bot.py) auf eine größere Zahl.
Weights_file = 'my_model_weights20.h5' Weights_file_GAN = 'my_model_weights.h5' Weights_file_discrim = 'my_model_weights_discriminator.h5'
Eine schöne Übersicht über die aktuellen Implementierungen neuronaler Konversationsmodelle für verschiedene Frameworks (zusammen mit einigen Ergebnissen) finden Sie hier.
Unser Modell kann auf andere NLP-Aufgaben angewendet werden, beispielsweise auf die Zusammenfassung von Texten, siehe beispielsweise Alternative 2: Rekursives Modell A. Wir empfehlen die Anwendung unseres Modells auf andere Aufgaben. In diesem Fall bitten wir Sie, unsere Arbeit so weit wie möglich zu zitieren sind in diesem Dokument zu sehen, registriert im Juli 2017.
Diese Codes können in Ubuntu 14.04.3 LTS, Python 2.7.6, Theano 0.9.0 und Keras 2.0.4 ausgeführt werden. Die Verwendung einer anderen Konfiguration kann einige kleinere Anpassungen erfordern.


