MiniGPT 3D
1.0.0
Yuan Tang Xu Han Xianzhi Li* Qiao Yu Yixue Hao Long Hu Min Chen
Huazhong-Universität für Wissenschaft und Technologie, Südchinesische Technische Universität
ACM MM 2024
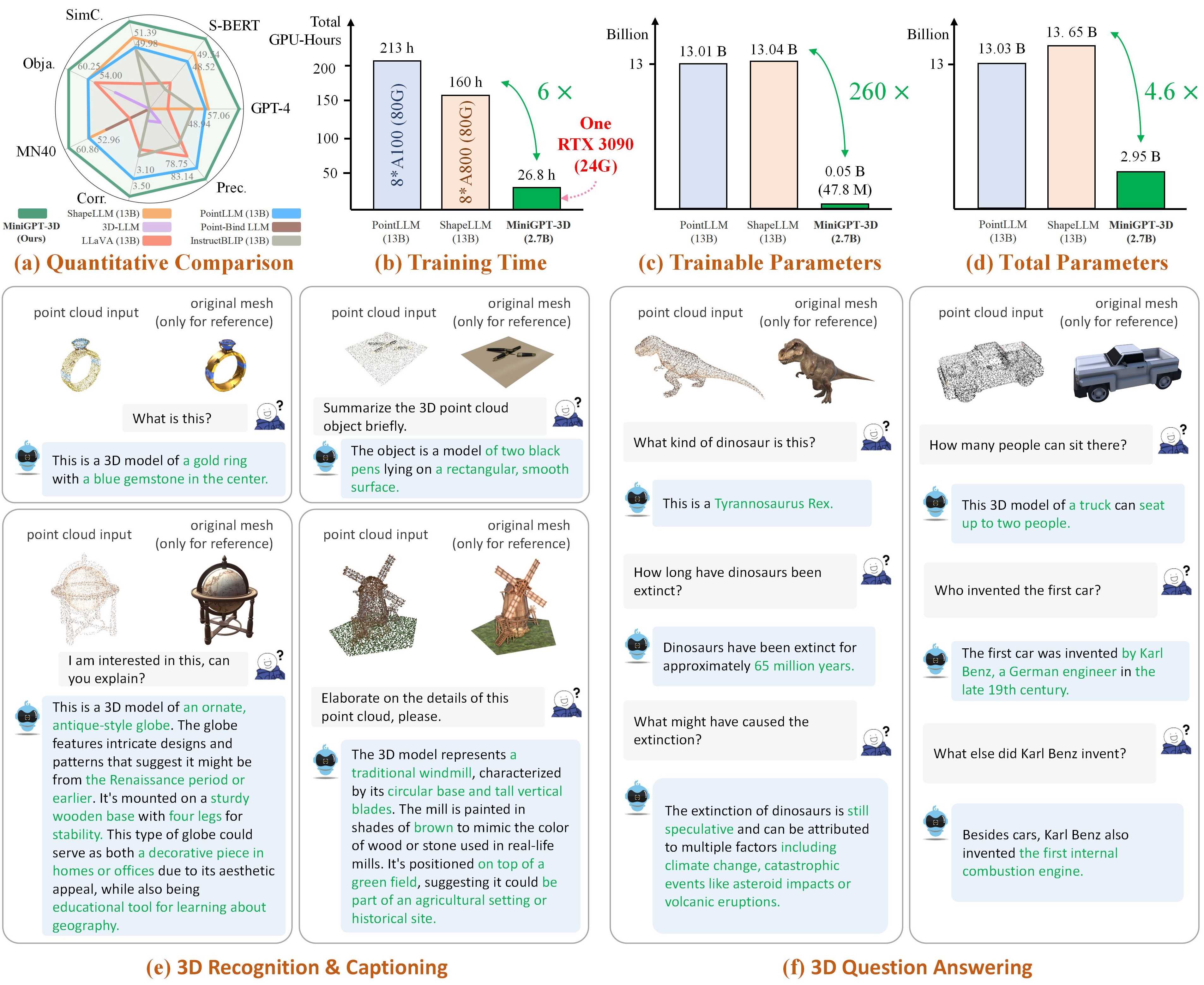

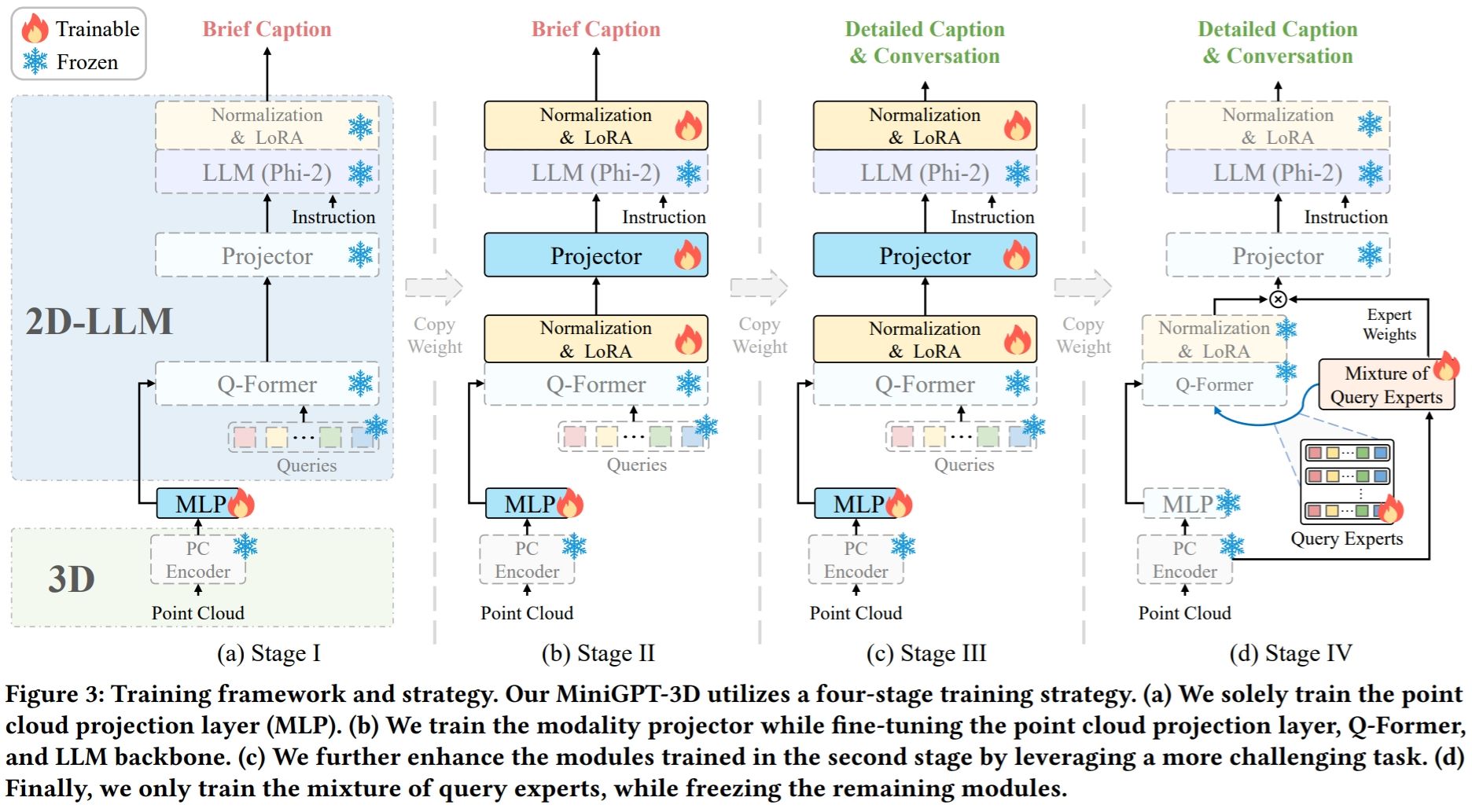
Hinweis: MiniGPT-3D macht den ersten Schritt in Richtung effizientes 3D-LLM . Wir hoffen, dass MiniGPT-3D dieser Community neue Erkenntnisse bringen kann.
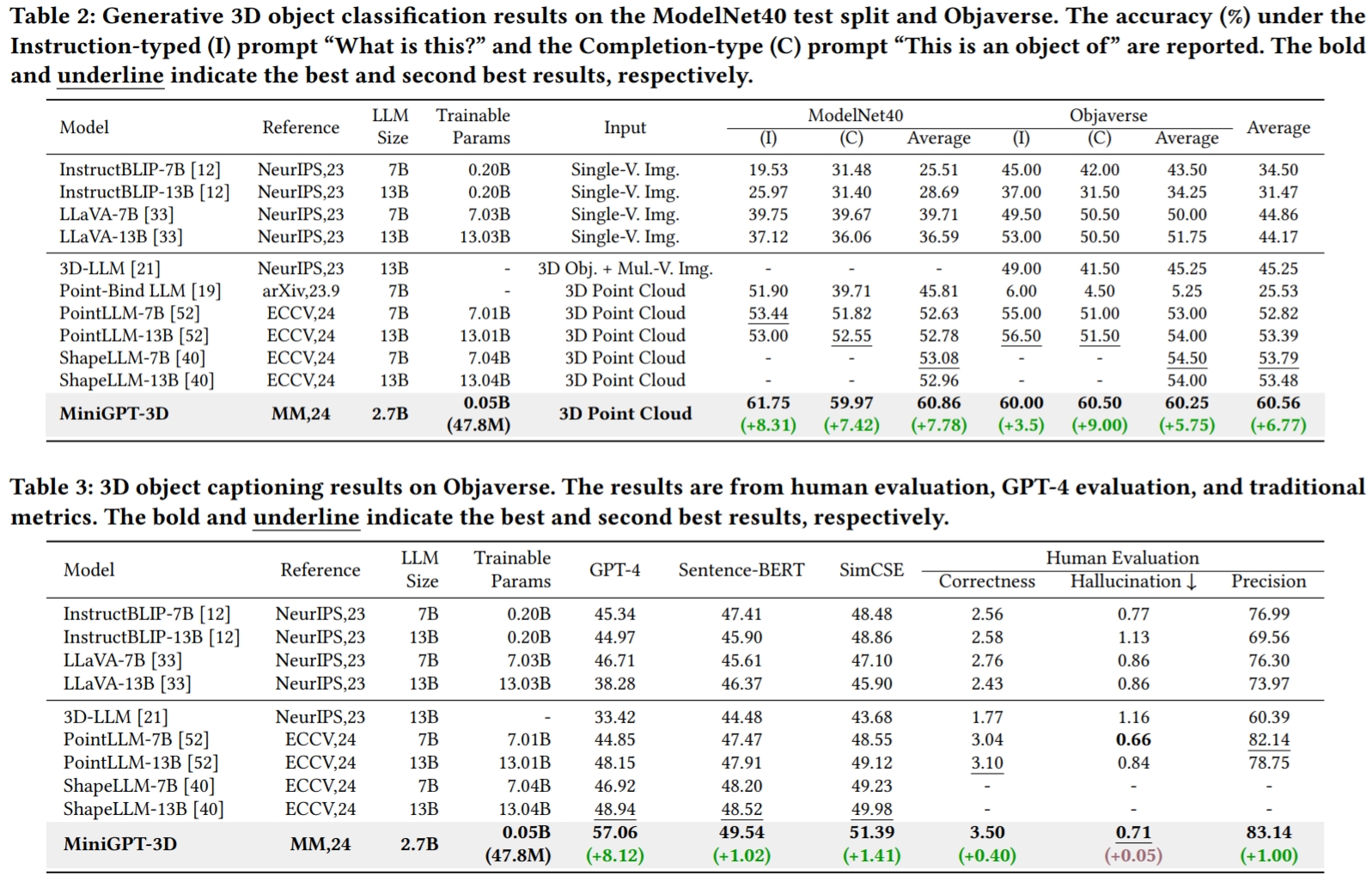
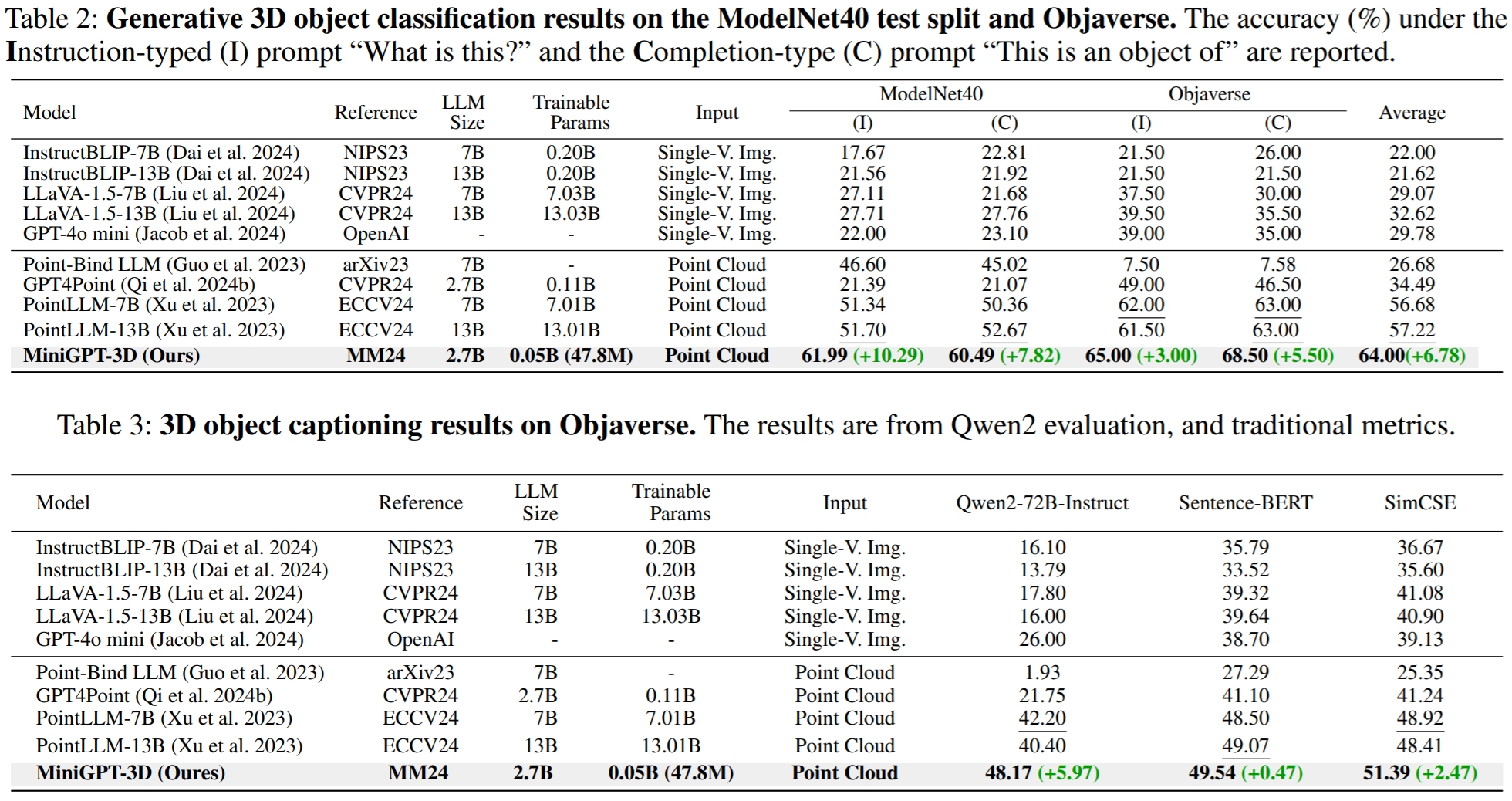
Die Ergebnisse beziehen sich auf GreenPLM.

Weitere Dialogbeispiele finden Sie in unserem Dokument.
Wir testen unsere Codes in der folgenden Umgebung:
Zu Beginn:
Klonen Sie dieses Repository.
git clone https://github.com/TangYuan96/MiniGPT-3D.git
cd MiniGPT-3DPakete installieren
Standardmäßig haben Sie Conda installiert.
conda env create -f environment.yml
conda activate minigpt_3d
bash env_install.sh8192_npy erstellt, der 660.000 Punktwolkendateien mit dem Namen {Objaverse_ID}_8192.npy enthält. Jede Datei ist ein Numpy-Array mit den Dimensionen (8192, 6), wobei die ersten drei Dimensionen xyz und die letzten drei Dimensionen rgb im Bereich [0, 1] sind. cat Objaverse_660K_8192_npy_split_a * > Objaverse_660K_8192_npy.tar.gz
tar -xvf Objaverse_660K_8192_npy.tar.gz8192_npy in den Ordner ./data/objaverse_data ../data/anno_data .modelnet40_test_8192pts_fps.dat in den Ordner ./data/modelnet40_data .Schließlich sollte die gesamte Datenverzeichnisstruktur wie folgt aussehen:
MiniGPT-3D/data
|-- anno_data
| |-- PointLLM_brief_description_660K.json
| |-- PointLLM_brief_description_660K_filtered.json
| |-- PointLLM_brief_description_val_200_GT.json
| |-- PointLLM_complex_instruction_70K.json
| |-- object_ids_660K.txt
| `-- val_object_ids_3000.txt
|-- modelnet40_data
| |-- modelnet40_test_8192pts_fps.dat
|-- objaverse_data
| |-- 00000054c36d44a2a483bdbff31d8edf_8192.npy
| |-- 00001ec0d78549e1b8c2083a06105c29_8192.npy
| .......
Wir klären die von MiniGPT-3D während des Trainings und der Inferenz benötigten Modellgewichte.
params_weight in MiniGPT-3D -Projektordner.Schließlich sollte die gesamte Datenverzeichnisstruktur wie folgt aussehen:
MiniGPT-3D
|-- params_weight
| |-- MiniGPT_3D_stage_3 # Our MiniGPT-3D stage III weight, needed to verify the results of paper
| |-- MiniGPT_3D_stage_4 # Our MiniGPT-3D stage IV weight, Needed to verify the results of paper
| |-- Phi_2 # LLM weight
| |-- TinyGPT_V_stage_3 # 2D-LLM weights including loRA & Norm of LLM and projector
| |-- all-mpnet-base-v2 # Used in the caption traditional evaluation
| |-- bert-base-uncased # Used in initialize Q-former
| |-- pc_encoder # point cloud encoder
| `-- sup-simcse-roberta-large # Used in the caption traditional evaluation
|-- train_configs
| `-- MiniGPT_3D
| .......
Sie können den folgenden Befehl ausführen, um eine lokale Gradio-Konversationsdemo zu starten:
python UI_demo.py --cfg-path ./eval_configs/MiniGPT_3D_conv_UI_demo.yaml --gpu-id 0 Kopieren Sie dann den Link http://127.0.0.1:7860/ in Ihren Browser. Sie können die unterstützte Objaverse-Objekt-ID (660.000 Objekte) eingeben oder eine Objektdatei (.ply oder .npy) hochladen, um mit unserem MiniGPT-3D zu kommunizieren .
Beispiel: Geben Sie die Objekt-ID ein: 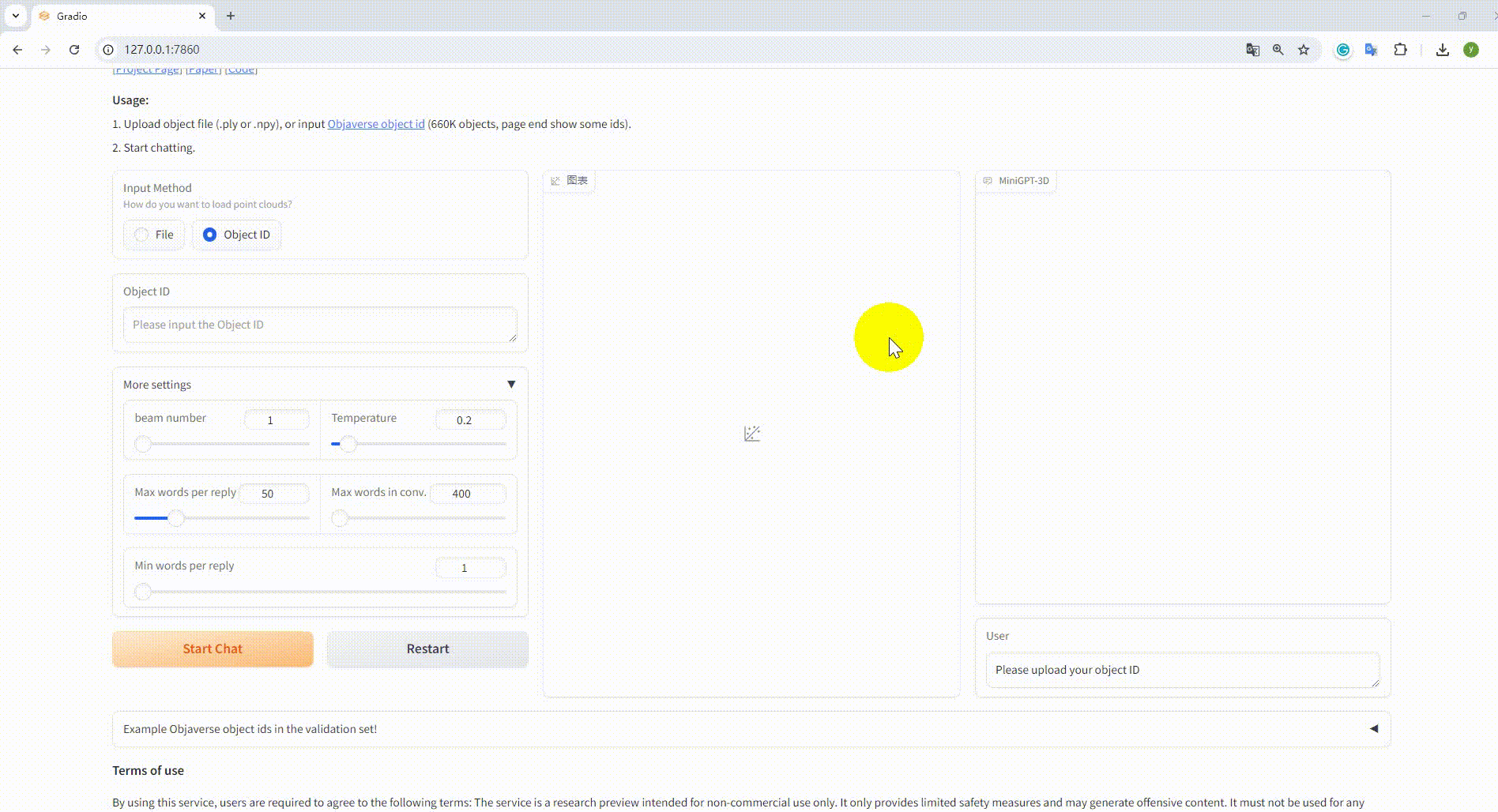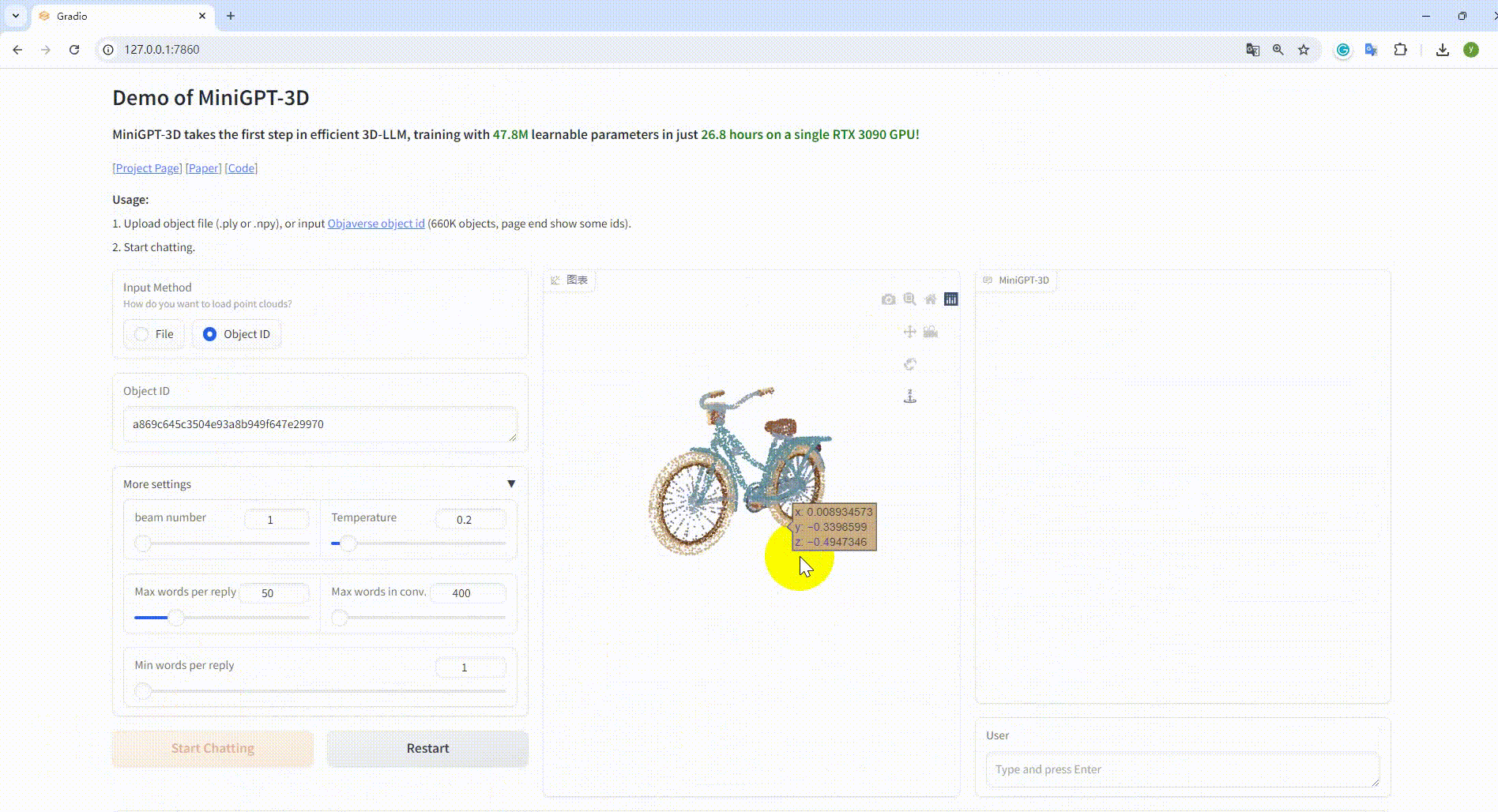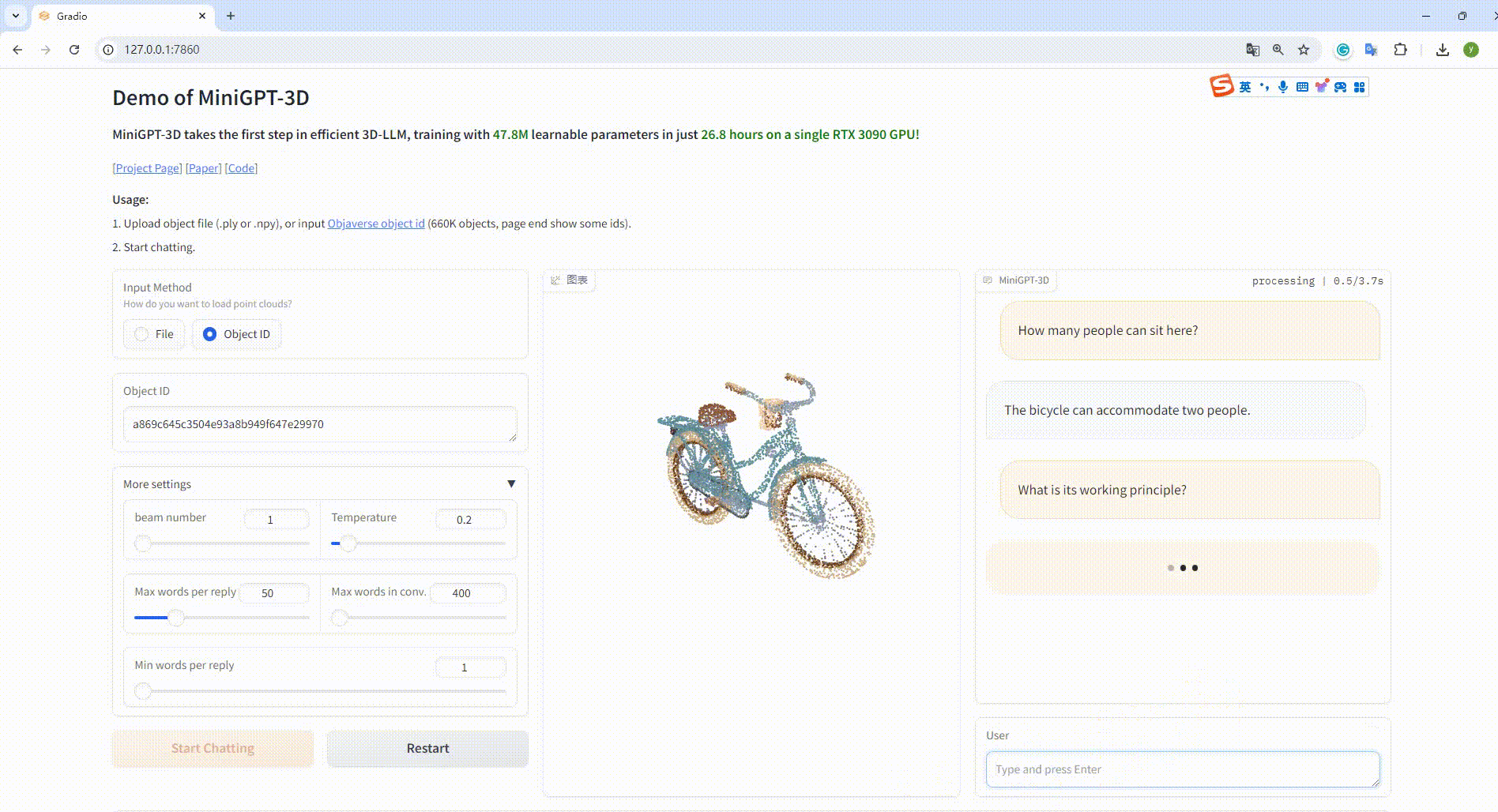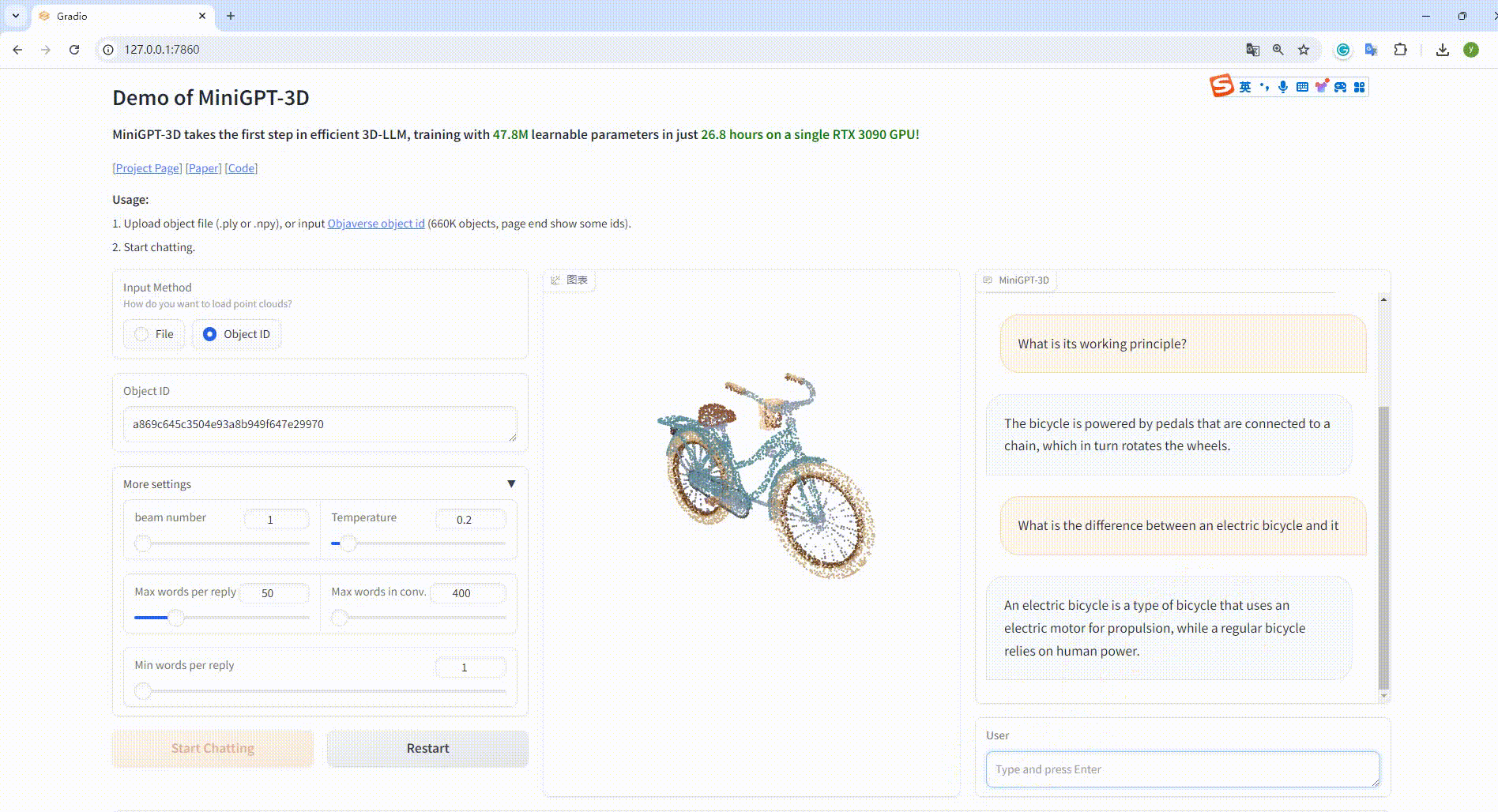
Beispiel: Laden Sie die Objektdatei hoch: 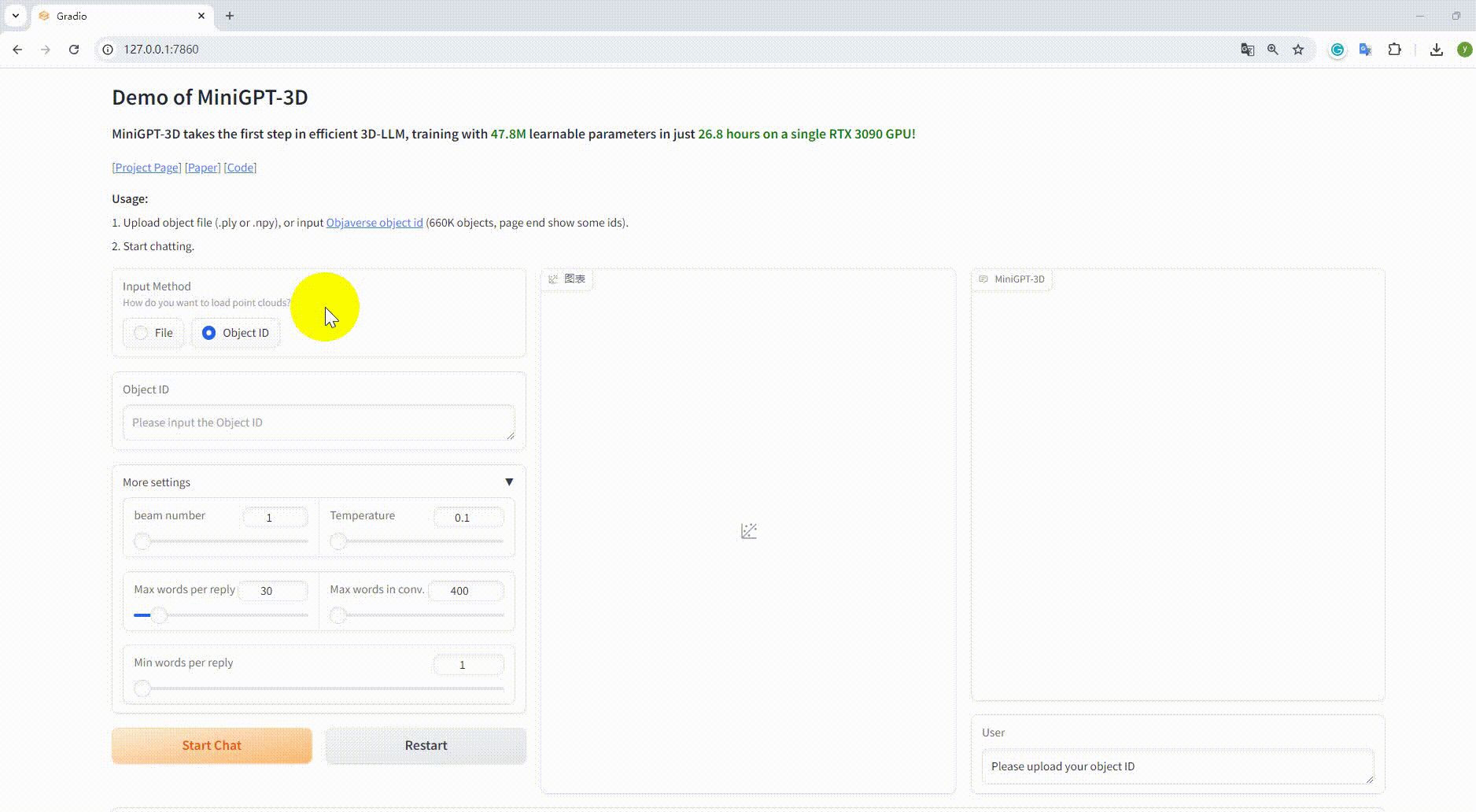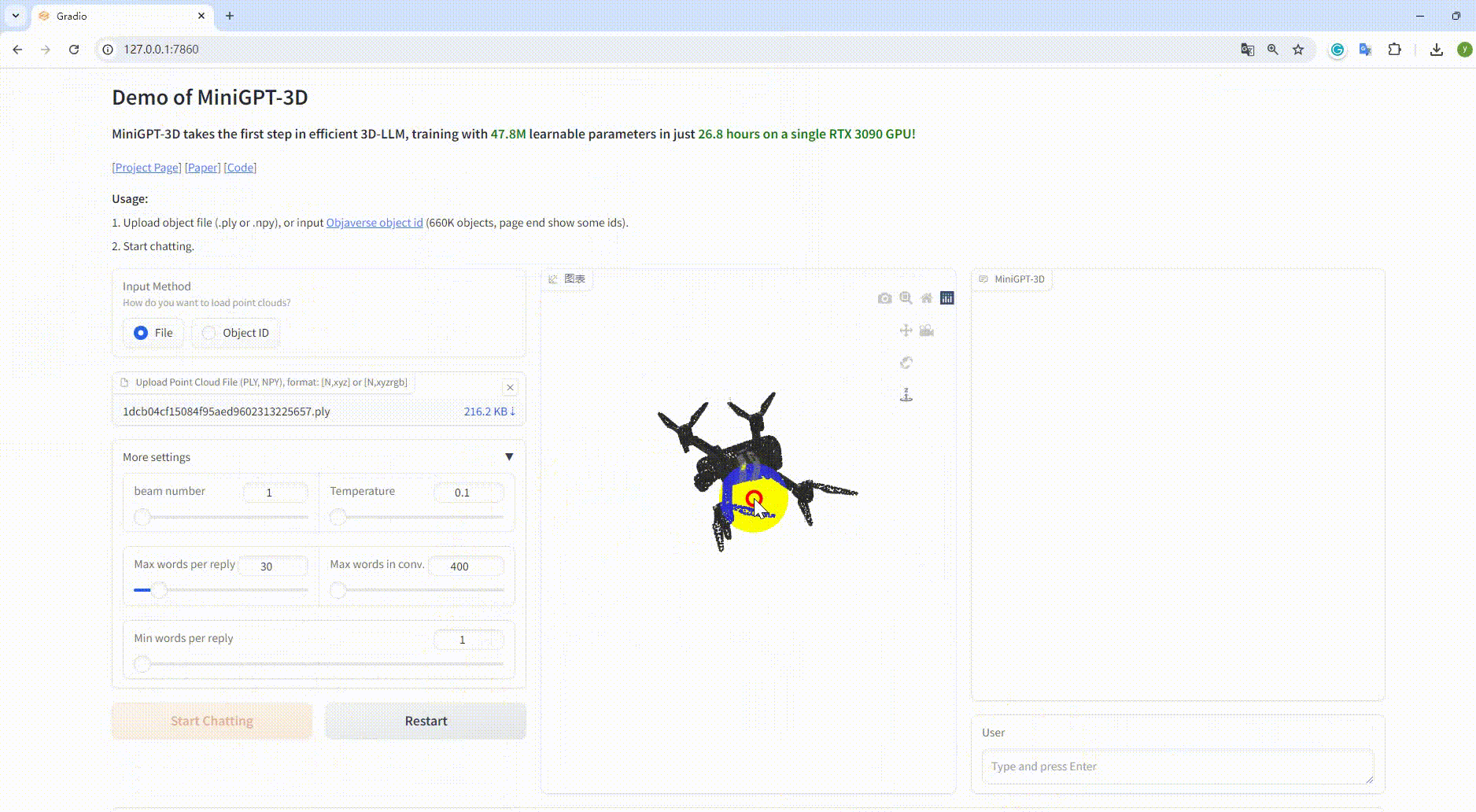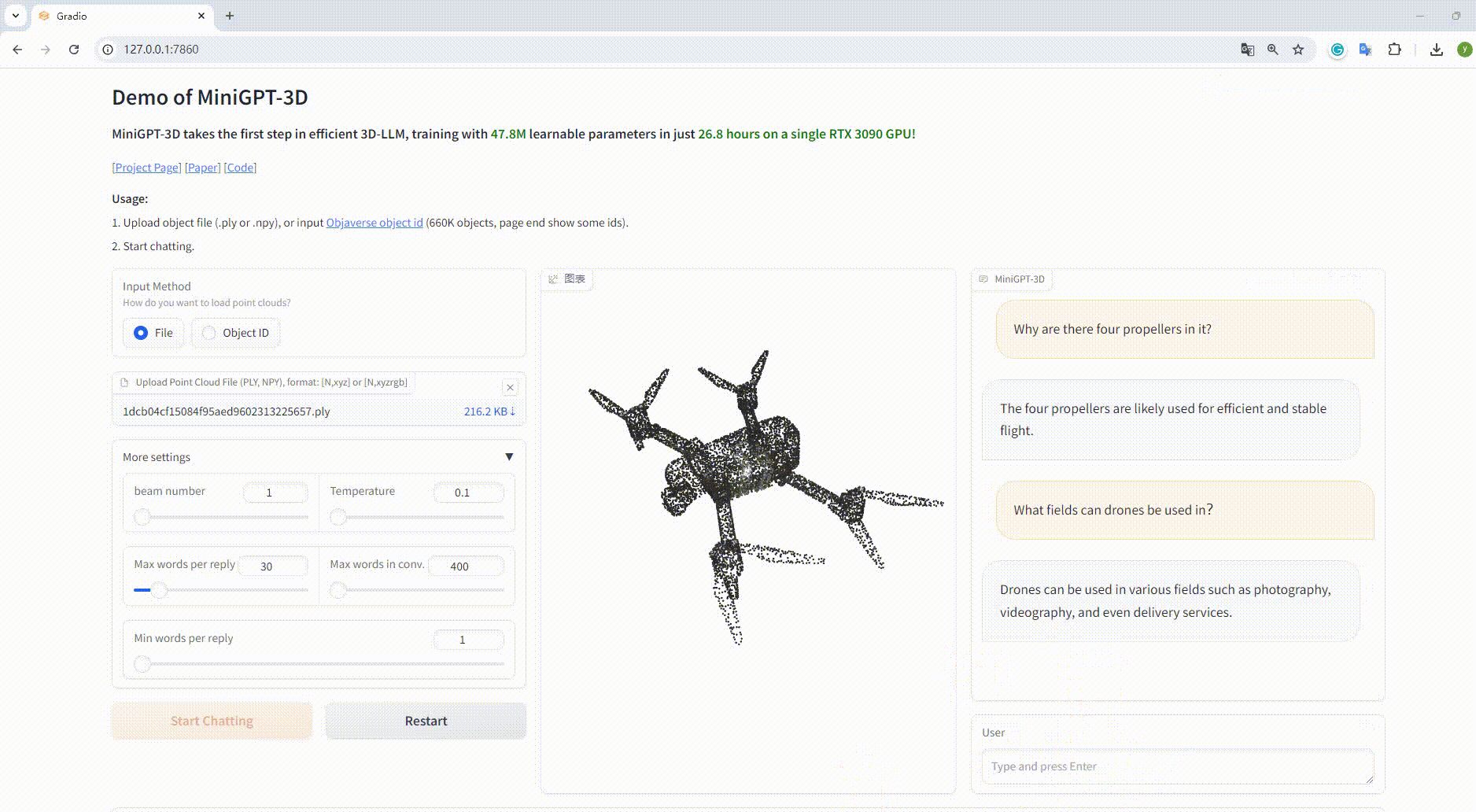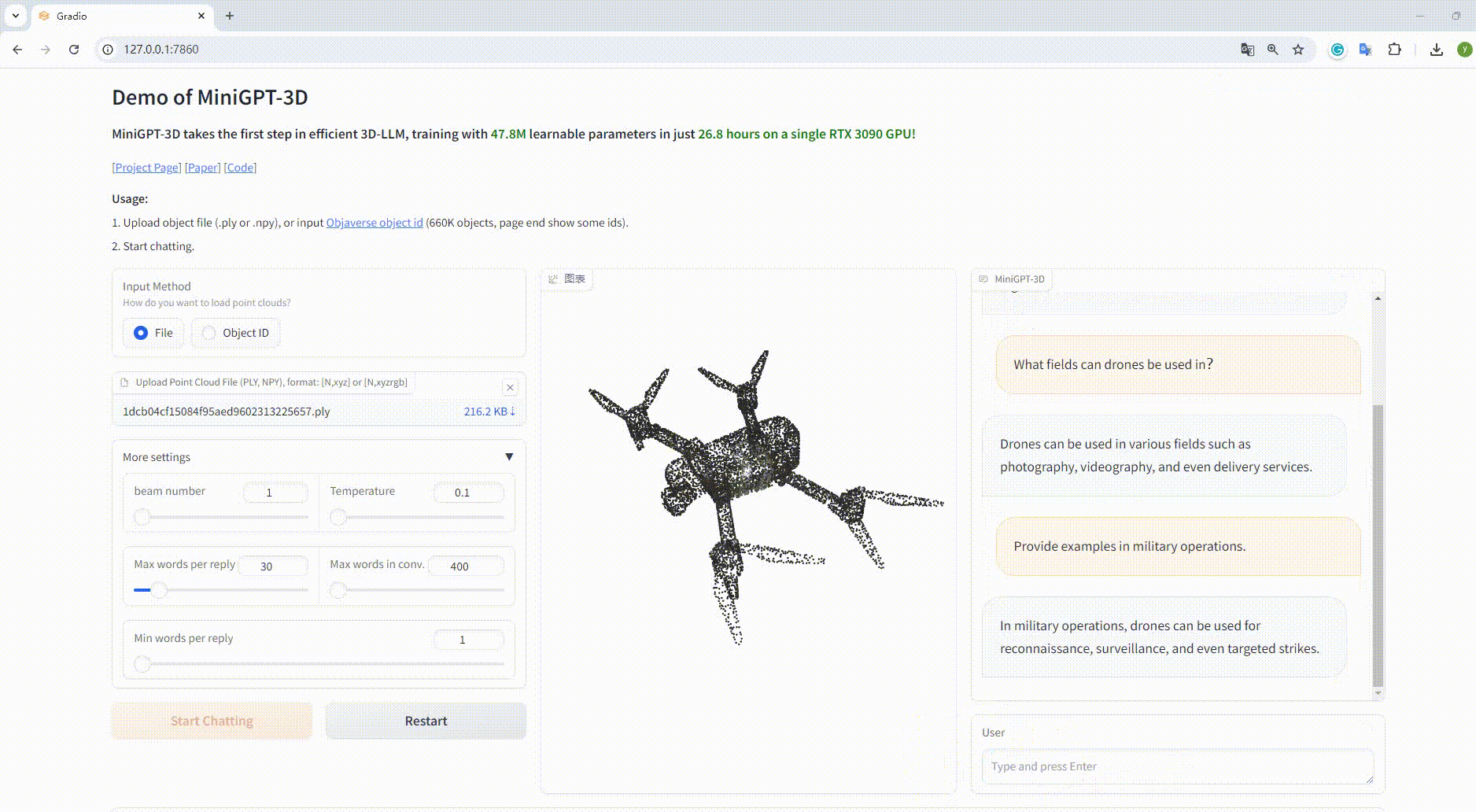
Wenn Sie den Standardausgabepfad jeder Stufe verwenden möchten, können Sie die folgenden Schritte ignorieren.
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_1.yaml
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_2.yaml
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_3.yaml
CUDA_VISIBLE_DEVICES=0 python train.py --cfg-path ./train_configs/MiniGPT_3D/stage_4.yaml
Wenn Sie nur die Ergebnisse unserer Arbeit überprüfen möchten, können Sie die folgenden Schritte ignorieren:
Stellen Sie den Ausgangspfad von Stufe III hier bei Zeile 8 ein.
Stellen Sie den Ausgabepfad von Stufe IV hier bei Zeile 9 ein.
Geben Sie das Ergebnis der Klassifizierung des offenen Vokabulars auf der Objaverse aus
# Prompt 0:
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_objaverse.py --out_path ./output/test --task_type classification --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 0 # Prompt 1:
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_objaverse.py --out_path ./output/test --task_type classification --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 1Geben Sie das Ergebnis der Close-Set-Zero-Shot-Klassifizierung auf ModelNet40 aus
# Prompt 0:
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_modelnet_cls.py --out_path ./output/test --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 0 # Prompt 1:
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_modelnet_cls.py --out_path ./output/test --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 1Geben Sie das Ergebnis der Objektbeschriftung auf der Vorderseite aus
export PYTHONPATH= $PWD
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/eval_objaverse.py --out_path ./output/test --task_type captioning --cfg-path ./eval_configs/benchmark_evaluation_paper.yaml --prompt_index 2Bei GreenPLM haben wir festgestellt, dass die Close-Source-LLMs GPT-3.5 und GPT-4 zwei große Nachteile haben: inkonsistente API-Versionen und hohe Evaluierungskosten (~35 CNY oder 5 USD pro Evaluierung) . Beispielsweise wird das in PointLLM und unserem MiniGPT-3D verwendete Modell GPT-3.5-turbo-0613 nicht mehr gepflegt, was es schwierig macht, die Ergebnisse zu reproduzieren .
export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt0.json --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15 export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt1.json --model_type gpt-4-0613 --eval_type open-free-form-classification --parallel --num_workers 15 export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/ModelNet_classification_prompt0.json --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15 export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/ModelNet_classification_prompt1.json --model_type gpt-3.5-turbo-0613 --eval_type modelnet-close-set-classification --parallel --num_workers 15 export PYTHONPATH= $PWD
export OPENAI_API_KEY=sk- ****
python pointllm/eval/evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_captioning_prompt2.json --model_type gpt-4-0613 --eval_type object-captioning --parallel --num_workers 15In GreenPLM schlagen wir neue 3D-Objektklassifizierungs- und Beschriftungs-Benchmarks unter Verwendung des Open-Source-Qwen2-72B-Instruct der GPT-4-Ebene vor, um Bewertungen kostengünstig und Ergebnisse konsistent reproduzierbar zu machen .
export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt0.json
--eval_type open-free-form-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4 export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_classification_prompt1.json
--eval_type open-free-form-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4 export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/ModelNet_classification_prompt0.json
--eval_type modelnet-close-set-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4 export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/ModelNet_classification_prompt1.json
--eval_type modelnet-close-set-classification
--model_type qwen2-72b-instruct
--parallel --num_workers 4 export PYTHONPATH= $PWD
export DASHSCOPE_API_KEY=sk-xxx
python ./pointllm/eval/evaluator_opensource_llm_QwenAPI.py
--results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_captioning_prompt2.json
--eval_type object-captioning
--model_type qwen2-72b-instruct
--parallel --num_workers 4Führen Sie für die Objektbeschriftungsaufgabe den folgenden Befehl aus, um die Modellausgaben mit den herkömmlichen Metriken Sentence-BERT und SimCSE auszuwerten.
CUDA_VISIBLE_DEVICES=0 python pointllm/eval/traditional_evaluator.py --results_path /path/to/evaluation/PointLLM_brief_description_val_200_GT_Objaverse_captioning_prompt2.jsonStellen Sie hier bei Zeile 8 den Ausgangspfad von Stufe III ein.
Stellen Sie hier in Zeile 9 den Ausgabepfad von Stufe IV ein.
Sie können den folgenden Befehl ausführen, um eine lokale Gradio-Konversationsdemo zu starten:
python UI_demo.py --cfg-path ./eval_configs/MiniGPT_3D_conv_UI_demo.yaml --gpu-id 0Wenn Sie unsere Arbeit hilfreich finden, denken Sie bitte darüber nach, Folgendes zu zitieren:
@article { tang2024minigpt ,
title = { MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors } ,
author = { Tang, Yuan and Han, Xu and Li, Xianzhi and Yu, Qiao and Hao, Yixue and Hu, Long and Chen, Min } ,
journal = { arXiv preprint arXiv:2405.01413 } ,
year = { 2024 }
}
Dieses Werk steht unter der Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Lassen Sie uns gemeinsam LLM für 3D großartig machen!
Wir möchten den Autoren von PointLLM, TinyGPT-V, MiniGPT-4 und Octavius für ihre großartigen Arbeiten und Repos danken.


