gutenberg dialog
1.0.0
Code zum Herunterladen und Erstellen Ihrer eigenen Version des Gutenberg-Dialogdatensatzes. Leicht erweiterbar mit neuen Sprachen. Probieren Sie hier trainierte Chatbots in verschiedenen Sprachen aus: https://ricsinaruto.github.io/chatbot.html.
| Download-Link | Anzahl der Äußerungen | Durchschnittliche Äußerungslänge | Anzahl der Dialoge | Durchschnittliche Dialoglänge |
|---|---|---|---|---|
| Englisch | 14 773 741 | 22.17 | 2 526 877 | 5,85 |
| Deutsch | 226 015 | 24.44 | 43 440 | 5.20 |
| Niederländisch | 129 471 | 24.26 | 23 541 | 5,50 |
| Spanisch | 58 174 | 18.62 | 6 912 | 8.42 |
| Italienisch | 41 388 | 19.47 | 6 664 | 6.21 |
| ungarisch | 18 816 | 14.68 | 2 826 | 6,66 |
| Portugiesisch | 16 228 | 21.40 | 2 233 | 7.27 |
? Generieren Sie Ihren eigenen Datensatz, indem Sie Parameter optimieren, die sich auf den Kompromiss zwischen Größe und Qualität des Datensatzes auswirken
Die modulare Schnittstelle ermöglicht eine einfache Erweiterung des Datensatzes auf andere Sprachen
? Sie können Bücher beim Erstellen des Datensatzes ganz einfach manuell ausschließen
Führen Sie setup.py aus, das die erforderlichen Pakete installiert.
python setup.py
Die Hauptdatei sollte vom Stammverzeichnis des Repos aufgerufen werden. Der folgende Befehl führt die Dataset-Building-Pipeline für die durch Kommas getrennten Sprachen aus, die als Argument angegeben sind. Derzeit werden Englisch, Deutsch, Niederländisch, Spanisch, Portugiesisch, Italienisch und Ungarisch unterstützt.
python code/main.py -l=en,de,nl,es,pt,it,hu -a
Alle einstellbaren Argumente sind unten zu sehen: 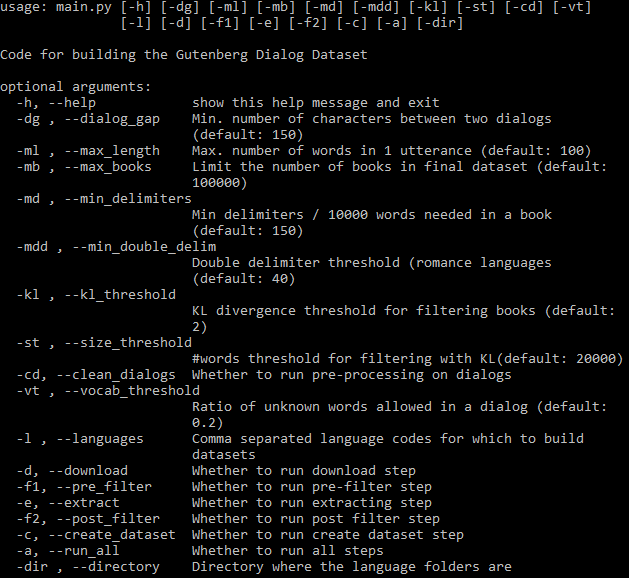
Das Flag -a steuert, ob die gesamte Pipeline automatisch ausgeführt werden soll. Wenn -a weggelassen wird, muss eine Teilmenge der Schritte mithilfe von Flags angegeben werden (siehe Hilfe oben). Sobald ein Schritt abgeschlossen ist, kann seine Ausgabe in nachfolgenden Schritten verwendet werden und er wird nur dann erneut ausgeführt, wenn Parameter oder Code im Zusammenhang mit diesem Schritt geändert werden. Alle Schritte laufen für jede Sprache separat ab.
Laden Sie Bücher für bestimmte Sprachen herunter.
Hinweis: Wenn der Download aller Bücher mit der Fehlermeldung „Buch konnte nicht heruntergeladen werden“ fehlschlägt, liegt die wahrscheinliche Ursache darin, dass auf den vom Gutenberg -Paket verwendeten Standardspiegel nicht mehr zugegriffen werden kann. In diesem Fall ist es möglich, über die Umgebungsvariable GUTENBERG_MIRROR einen der unter https://www.gutenberg.org/MIRRORS.ALL aufgeführten alternativen Spiegel zu verwenden. Zum Beispiel:
export GUTENBERG_MIRROR="https://gutenberg.pglaf.org"
python code/main.py ...
Durch die Vorfilterung werden einige alte Bücher und Rauschen entfernt.
Dialoge werden aus Büchern extrahiert. Wenn Sie den Datensatz auf neue Sprachen erweitern (siehe Abschnitt unten), kann dieser Schritt geändert werden. Daher können vorherige Schritte nach Abschluss übersprungen werden.
Ein zweiter Filterschritt entfernt einige Dialoge basierend auf dem Vokabular.
Zusammenstellen des endgültigen Datensatzes und Aufteilen in Trainings-/Entwicklungs-/Testdaten. Im letzten Schritt wird die Datei „author_and_title.txt“ im Ausgabeverzeichnis erstellt, die alle Bücher (plus Titel und Autoren) enthält, die zum Extrahieren des endgültigen Datensatzes verwendet werden. Benutzer können manuell Zeilen aus dieser Datei in banned_books.txt kopieren, die den Büchern entsprechen, die im Datensatz nicht zulässig sein sollen. Bei nachfolgenden Durchläufen beliebiger Schritte werden Bücher in dieser Datei nicht berücksichtigt.
Der Code kann leicht erweitert werden, um andere Sprachen zu verarbeiten. Im Sprachenordner muss eine Datei mit dem Namen <Sprachcode>.py erstellt werden. Hier sollte eine Klasse mit dem Namen des Sprachcodes in Großbuchstaben (z. B. En für Englisch) definiert werden, mit LANG oder einer der anderen Unterklassen als übergeordnete Klasse. Mit self.cfg kann auf Konfigurationsparameter zugegriffen werden. Innerhalb dieser Klasse müssen die drei folgenden Funktionen definiert werden. Ein Beispiel finden Sie in it.py.
Sprachenstatistik
Diese Funktion sollte ein Wörterbuch zurückgeben, in dem die Schlüssel potenzielle Trennzeichen sind. Für jedes Trennzeichen sollte eine Funktion definiert werden (Werte im Wörterbuch), die eine Zeile als Eingabe nimmt und eine Zahl zurückgibt. Bei dieser Zahl kann es sich beispielsweise um die Anzahl der Trennzeichen, eine Markierung, ob in der Zeile ein Trennzeichen vorhanden ist, usw. handeln. In der Regel empfiehlt sich eine gewichtete Zählung, abhängig von der Bedeutung der unterschiedlichen Trennzeichen. Die Werte werden verwendet, um das Trennzeichen zu bestimmen, das im jeweiligen Buch verwendet werden soll (wird an die Funktion unten übergeben) und um Bücher zu filtern, die eine geringe Anzahl an Trennzeichen enthalten. en.py enthält Beispiele für mehrere Trennzeichen.
Diese Funktion sollte die Dialoge aus einem Buch extrahieren und sie an self.dialogs anhängen, was eine Liste von Dialogen ist und jeder Dialog eine Liste aufeinanderfolgender Äußerungen ist. absatzliste enthält das Buch als Liste aufeinanderfolgender Absätze. Trennzeichen ist das häufigste Trennzeichen in dieser Datei, das zum Extrahieren von Dialogen verwendet werden sollte.
Diese Funktion dient der Nachbearbeitung von Dialogen (z. B. Entfernen bestimmter Zeichen). Als Eingabe wird eine Äußerung benötigt. Bitte beachten Sie, dass die NLTK-Wort-Tokenisierung automatisch ausgeführt wird.
Dieses Projekt ist unter der MIT-Lizenz lizenziert – Einzelheiten finden Sie in der LIZENZ-Datei.
Bitte fügen Sie einen Link zu diesem Repo hinzu, wenn Sie einen Datensatz oder Code in Ihrer Arbeit verwenden und erwägen, das folgende Dokument zu zitieren:
@inproceedings{Csaky:2021,
title = "The Gutenberg Dialogue Dataset",
author = "Cs{'a}ky, Rich{'a}rd and Recski, G{'a}bor",
booktitle = "Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics",
month = apr,
year = "2021",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.12752",
}


