Multi Modality Arena
1.0.0
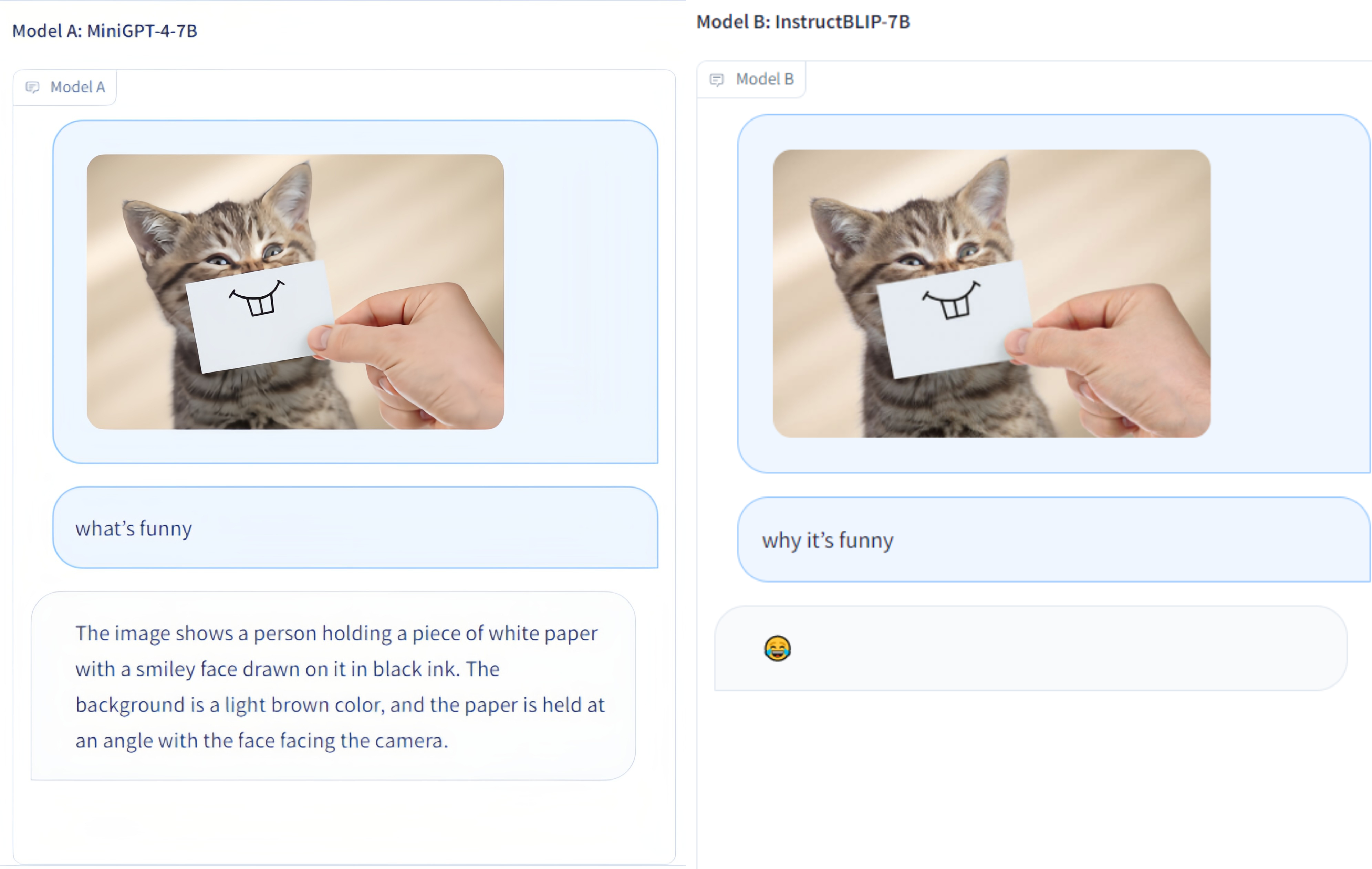
Multi-Modality Arena ist eine Evaluierungsplattform für große Multimodalitätsmodelle. Im Anschluss an Fastchat werden zwei anonyme Modelle nebeneinander bei einer visuellen Frage-Antwort-Aufgabe verglichen. Wir veröffentlichen die Demo und begrüßen die Teilnahme aller an dieser Evaluierungsinitiative.
OmniMedVQA-Datensatz: enthält 118.010 Bilder mit 127.995 QA-Elementen, deckt 12 verschiedene Modalitäten ab und bezieht sich auf mehr als 20 menschliche anatomische Regionen. Der Datensatz kann hier heruntergeladen werden.
12 Modelle: 8 allgemeine LVLMs und 4 medizinisch spezialisierte LVLMs.
Winzige Datensätze: Nur 50 zufällig ausgewählte Stichproben für jeden Datensatz, d. h. 42 textbezogene visuelle Benchmarks und insgesamt 2,1.000 Stichproben für eine einfachere Verwendung.
Weitere Modelle: weitere 4 Modelle, also insgesamt 12 Modelle, einschließlich Google Bard .
ChatGPT-Ensemble-Bewertung : Bessere Übereinstimmung mit der menschlichen Bewertung als beim vorherigen Wortvergleichsansatz.
LVLM-eHub ist ein umfassender Bewertungsbenchmark für öffentlich verfügbare große multimodale Modelle (LVLM). Es wertet ausführlich aus
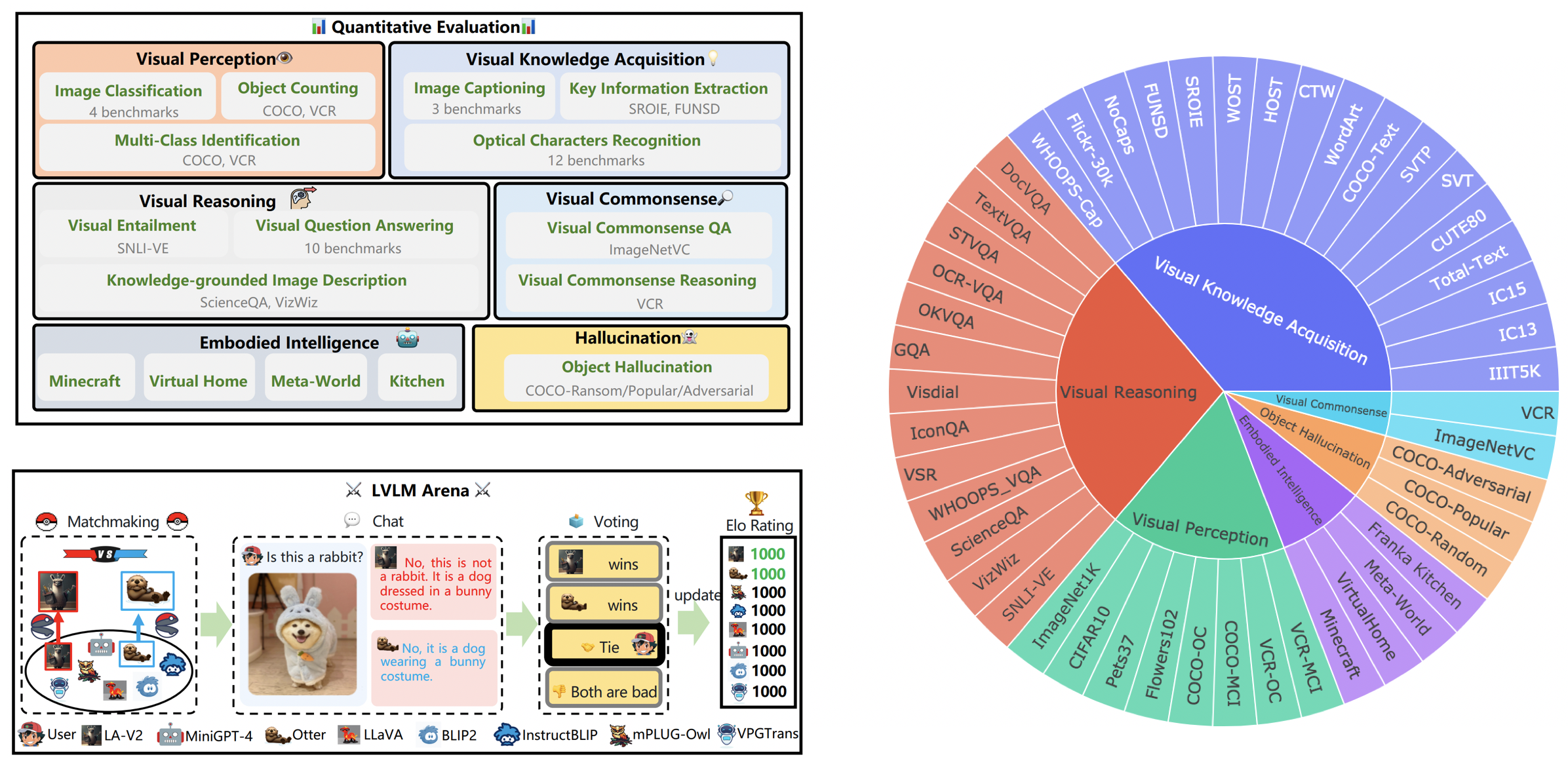
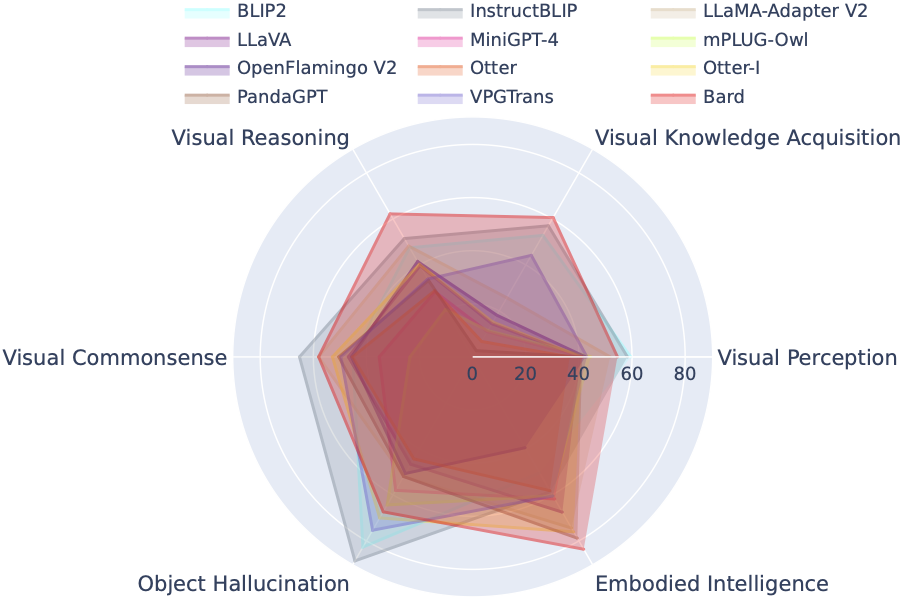
Das LVLM Leaderboard kategorisiert die in der Tiny LVLM Evaluation vorgestellten Datensätze systematisch nach ihren spezifischen Zielfähigkeiten, einschließlich visueller Wahrnehmung, visuellem Denken, visuellem gesunden Menschenverstand, visuellem Wissenserwerb und Objekthalluzination. Diese Rangliste enthält kürzlich veröffentlichte Modelle, um die Vollständigkeit zu erhöhen.
Sie können den Benchmark hier herunterladen. Weitere Details finden Sie hier.
| Rang | Modell | Version | Punktzahl |
|---|---|---|---|
| 1 | InternVL | InternVL-Chat | 327,61 |
| 2 | InternLM-XComposer-VL | InternLM-XComposer-VL-7B | 322,51 |
| 3 | Barde | Barde | 319,59 |
| 4 | Qwen-VL-Chat | Qwen-VL-Chat | 316,81 |
| 5 | LLaVA-1.5 | Vicuna-7B | 307.17 |
| 6 | InstructBLIP | Vicuna-7B | 300,64 |
| 7 | InternLM-XComposer | InternLM-XComposer-7B | 288,89 |
| 8 | BLIP2 | FlanT5xl | 284,72 |
| 9 | BLIVA | Vicuna-7B | 284.17 |
| 10 | Luchs | Vicuna-7B | 279,24 |
| 11 | Gepard | Vicuna-7B | 258,91 |
| 12 | LLaMA-Adapter-v2 | LLaMA-7B | 229.16 |
| 13 | VPGTrans | Vicuna-7B | 218,91 |
| 14 | Otter-Bild | Otter-9B-LA-InContext | 216,43 |
| 15 | VisualGLM-6B | VisualGLM-6B | 211,98 |
| 16 | mPLUG-Eule | LLaMA-7B | 209,40 |
| 17 | LLaVA | Vicuna-7B | 200,93 |
| 18 | MiniGPT-4 | Vicuna-7B | 192,62 |
| 19 | Otter | Otter-9B | 180,87 |
| 20 | OFv2_4BI | RedPajama-INCITE-Instruct-3B-v1 | 176,37 |
| 21 | PandaGPT | Vicuna-7B | 174,25 |
| 22 | LaVIN | LLaMA-7B | 97,51 |
| 23 | MIC | FlanT5xl | 94.09 |
31. März 2024. Wir veröffentlichen OmniMedVQA, einen umfassenden umfassenden Bewertungsbenchmark für medizinische LVLMs. Mittlerweile gibt es 8 allgemeine LVLMs und 4 medizinisch spezialisierte LVLMs. Weitere Informationen finden Sie im MedicalEval.
16. Okt. 2023. Wir präsentieren eine vom LVLM-eHub abgeleitete Aufteilung des Datensatzes auf Fähigkeitsebene, ergänzt durch die Einbeziehung von acht kürzlich veröffentlichten Modellen. Für Zugriff auf die Datensatzaufteilungen, den Bewertungscode, die Ergebnisse der Modellinferenz und umfassende Leistungstabellen besuchen Sie bitte tiny_lvlm_evaluation ✅.
8. August 2023. Wir haben [Tiny LVLM-eHub] veröffentlicht. Evaluierungsquellcodes und Modellinferenzergebnisse sind Open-Source unter tiny_lvlm_evaluation.
15. Juni 2023. Wir veröffentlichen [LVLM-eHub] , einen Bewertungsbenchmark für große Vision-Sprachmodelle. Der Code kommt bald.
8. Juni 2023. Vielen Dank, Dr. Zhang, der Autor von VPGTrans, für seine Korrekturen. Die Autoren von VPGTrans kommen hauptsächlich von der NUS und der Tsinghua-Universität. Bei der Neuimplementierung von VPGTrans hatten wir zuvor einige kleinere Probleme, aber wir haben festgestellt, dass die Leistung tatsächlich besser ist. Für weitere Modellautoren kontaktieren Sie mich bitte zur Diskussion per E-Mail. Bitte folgen Sie auch unserer Modell-Rangliste, wo genauere Ergebnisse verfügbar sind.
Mai. 22, 2023. Vielen Dank, Dr. Ye, der Autor von mPLUG-Owl, für seine Korrekturen. Wir beheben einige kleinere Probleme in unserer Implementierung von mPLIG-Owl.
Die folgenden Modelle nehmen derzeit an Zufallsgefechten teil:
KAUST/MiniGPT-4
Salesforce/BLIP2
Salesforce/InstructBLIP
DAMO Academy/mPLUG-Owl
NTU/Otter
Universität von Wisconsin-Madison/LLaVA
Shanghai AI Lab/llama_adapter_v2
NUS/VPGTrans
Weitere Details zu diesen Modellen finden Sie unter ./model_detail/.model.jpg . Wir werden versuchen, Rechenressourcen einzuplanen, um mehr multimodale Modelle in der Arena zu hosten.
Wenn Sie an Teilen unserer VLarena-Plattform interessiert sind, können Sie sich gerne der Wechat-Gruppe anschließen.

Erstellen Sie eine Conda-Umgebung
conda create -n arena python=3.10 Conda Arena aktivieren
Installieren Sie die zum Ausführen des Controllers und Servers erforderlichen Pakete
pip install numpy gradio uvicorn fastapi
Dann benötigen sie möglicherweise für jedes Modell widersprüchliche Versionen von Python-Paketen. Wir empfehlen, für jedes Modell eine spezifische Umgebung basierend auf ihrem GitHub-Repo zu erstellen.
Für die Bereitstellung über die Web-Benutzeroberfläche benötigen Sie drei Hauptkomponenten: Webserver, die mit Benutzern kommunizieren, Modellarbeiter, die zwei oder mehr Modelle hosten, und einen Controller zur Koordinierung des Webservers und der Modellarbeiter.
Hier sind die Befehle, die Sie in Ihrem Terminal befolgen müssen:
Python-Controller.py
Dieser Controller verwaltet die verteilten Worker.
python model_worker.py --model-name SELECTED_MODEL --device TARGET_DEVICE
Warten Sie, bis der Vorgang das Laden des Modells abgeschlossen hat und „Uvicorn läuft auf ...“ angezeigt wird. Der Modellarbeiter registriert sich beim Controller. Für jeden Modellarbeiter müssen Sie das Modell und das Gerät angeben, das Sie verwenden möchten.
Python server_demo.py
Dies ist die Benutzeroberfläche, mit der Benutzer interagieren.
Wenn Sie diese Schritte befolgen, können Sie Ihre Modelle über die Web-Benutzeroberfläche bereitstellen. Sie können jetzt Ihren Browser öffnen und mit einem Model chatten. Wenn die Modelle nicht angezeigt werden, versuchen Sie, den Gradio-Webserver neu zu starten.
Wir schätzen alle Beiträge, die darauf abzielen, die Qualität unserer Bewertungen zu verbessern, sehr. Dieser Abschnitt umfasst zwei Hauptsegmente: Contributions to LVLM Evaluation und Contributions to LVLM Arena .
Sie können auf die neueste Version unseres Evaluierungscodes im Ordner LVLM_evaluation zugreifen. Dieses Verzeichnis umfasst einen umfassenden Satz an Evaluierungscodes sowie die erforderlichen Datensätze. Wenn Sie an der Teilnahme am Evaluierungsprozess interessiert sind, zögern Sie bitte nicht, uns Ihre Evaluierungsergebnisse oder die Modellinferenz-API per E-Mail an [email protected] mitzuteilen.
Wir bedanken uns für Ihr Interesse an der Integration Ihres Modells in unsere LVLM Arena! Wenn Sie Ihr Modell in unsere Arena integrieren möchten, bereiten Sie bitte einen Modelltester vor, der wie folgt aufgebaut ist:
class ModelTester:def __init__(self, device=None) -> None:# TODO: Initialisierung des Modells und erforderliche Vorprozessorendef move_to_device(self, device) -> None:# TODO: Diese Funktion wird verwendet, um das Modell zwischen CPU und zu übertragen GPU (optional)def generic(self, image, questions) -> str: # TODO: Modellinferenzcode
Darüber hinaus sind wir offen für Online-Links zur Modellinferenz, wie sie beispielsweise von Plattformen wie Gradio bereitgestellt werden. Ihre Beiträge werden von ganzem Herzen geschätzt.
Wir danken dem geschätzten Team von ChatBot Arena und ihrem Aufsatz „Judging LLM-as-a-judge“ für ihre einflussreiche Arbeit, die als Inspiration für unsere LVLM-Bewertungsbemühungen diente. Wir möchten auch den Anbietern von LVLMs unseren aufrichtigen Dank aussprechen, deren wertvolle Beiträge erheblich zum Fortschritt und zur Weiterentwicklung großer Vision-Sprachmodelle beigetragen haben. Abschließend danken wir den Anbietern der in unserem LVLM-eHub verwendeten Datensätze.
Bei dem Projekt handelt es sich um ein experimentelles Forschungsinstrument ausschließlich für nichtkommerzielle Zwecke. Es verfügt nur über begrenzte Sicherheitsvorkehrungen und kann unangemessene Inhalte generieren. Es darf nicht für illegale, schädliche, gewalttätige, rassistische oder sexuelle Zwecke verwendet werden.


