Sound Content Music Recommendation System
1.0.0

Wenn du wie ich bist, liebst du Musik. Ich liebe Musik und ich liebe es, neue Musik zu finden. Spotify ist einer der Top-Streaming-Dienste für Musik im Internet und enthält bereits erstaunliche Tools, mit denen Sie neue Musik basierend auf dem, was Sie hören, entdecken können. Dies geschieht durch eine Kombination verschiedener Algorithmen, einschließlich kollaborativer Filterung, bei der eine ähnliche Nutzung zwischen Benutzern verfolgt und zur Generierung von Empfehlungen oder inhaltsbasierten Empfehlungen verwendet wird, die neue Songs auf der Grundlage ähnlicher Informationen zwischen den mit einem Song verknüpften Informationen empfehlen. Wie ein Lied? Auf Spotify können Sie das „Radio“ dieses Lieds anhören, das eine Gruppe von Liedern sammelt, die diesem Lied in irgendeiner Weise oder auf eine Kombination von Arten ähneln. Was ist, wenn Ihnen ein Song gefällt, Ihnen aber keine anderen Informationen als nur der Klang darin wichtig sind? Manchmal ist das alles, was ich hören möchte.
Ich habe dieses Projekt ins Leben gerufen, um ein Musikempfehlungssystem zu entwickeln, das allein auf den Informationen im Klang der Musik basiert. Es hilft einem Benutzer, neue Musik anhand ähnlich klingender Songs zu finden. Zu diesem Zweck werden auch die Ähnlichkeiten zwischen allen Musikstücken untersucht und versucht, die Klangfarbe, den Rhythmus und den Stil eines Liedes mathematisch zu erfassen.
Klang ist immer um uns herum. Im Laufe unseres Lebens lernen wir, unterschiedliche Geräusche von anderen zu unterscheiden. Musik ist nicht anders – es gibt viele Arten von Musik und Musik ist oft eine Kombination aus vielen verschiedenen Arten von Klängen und Rhythmen, die wir auch getrennt von anderen unterscheiden können. Aber können wir diese Informationen für uns selbst quantifizieren? Manchmal wird Musik in Genres eingeteilt, was bedeutet, dass ein Genre eine Gruppe von Musikern mit ähnlichen Qualitäten in Bezug auf Stil, Form, Rhythmus, Klangfarbe, Instrumente oder Kultur ist. Aber nicht jeder Musiker erzeugt Klänge im gleichen Genre und nicht jedes Genre enthält die gleiche Art von Musik. Was ist also Schall und wie unterscheiden wir verschiedene Arten von Schall?
Schall ist eine Schwingung akustischer Wellen, die wir durch unsere Ohren wahrnehmen, wenn diese Wellen unser Trommelfell zum Schwingen bringen. Eine Schallwelle ist ein Signal und die Geschwindigkeit, mit der dieses Signal schwingt, wird als Frequenz bezeichnet. Wenn eine Schallfrequenz höher ist, empfinden wir den Ton als höher. In der Musik erzeugen Instrumente wie Bass oder Bassdrum Klänge, die mit einer niedrigeren Frequenz schwingen, während hohe Töne eine höhere Frequenz haben. Klingt wie das Klirren eines Beckens oder Hi-Hats, ist eine Kombination aus vielen Wellen mit unterschiedlichen Frequenzen und wird durch eine „rauschende“, fast zufällig aussehende Welle dargestellt.
Wie sieht Klang aus? Eine Möglichkeit, Schall zu visualisieren, besteht darin, ein Signal über die Zeit darzustellen:
Wenn wir das Zeitfenster für jede Nebenhandlung verkürzen, können wir das Audiosignal viel näher sehen. Beachten Sie, dass die Welle im am stärksten vergrößerten Bild des Signals eine Ansammlung verschiedener Frequenzen ist. Möglicherweise gibt es ein Niederfrequenzsignal, das mit kleineren Hochfrequenzsignalen kombiniert wird.
Wir können uns also ein Signal über die Zeit vorstellen, aber wir können bereits erkennen, dass es schwierig ist, viel über diese Schallwelle zu verstehen, wenn man sich nur diese Visualisierung ansieht. Welche Arten von Frequenzen sind in diesem 0,01-Sekunden-Fenster vorhanden? Um dies zu beantworten, verwenden wir eine Fourier-Transformation, um ein Spektrogramm zu berechnen.
Die Fourier-Transformation ist eine Methode zur Berechnung der Amplitude von Frequenzen, die in einem Abschnitt eines Audiosignals vorhanden sind. Wie Sie in der Grafik oben sehen können, können Wellen komplex sein und jede Variation im Signal repräsentiert eine andere Frequenz (die Schwingungsgeschwindigkeit). Eine Fourier-Transformation extrahiert im Wesentlichen die Frequenzen für jeden Zeitabschnitt und erzeugt ein zweidimensionales Array von Frequenzamplituden über der Zeit. Das Produkt einer Fourier-Transformation ist ein Spektrogramm. Aus dem Spektrogramm konvertieren wir die erzeugten Frequenzen in die Mel-Skala, um ein Mel-Spektrogramm zu erstellen. Das Mel-Spektrogramm stellt den wahrgenommenen Abstand zwischen den Frequenzen besser dar, wenn wir sie hören.
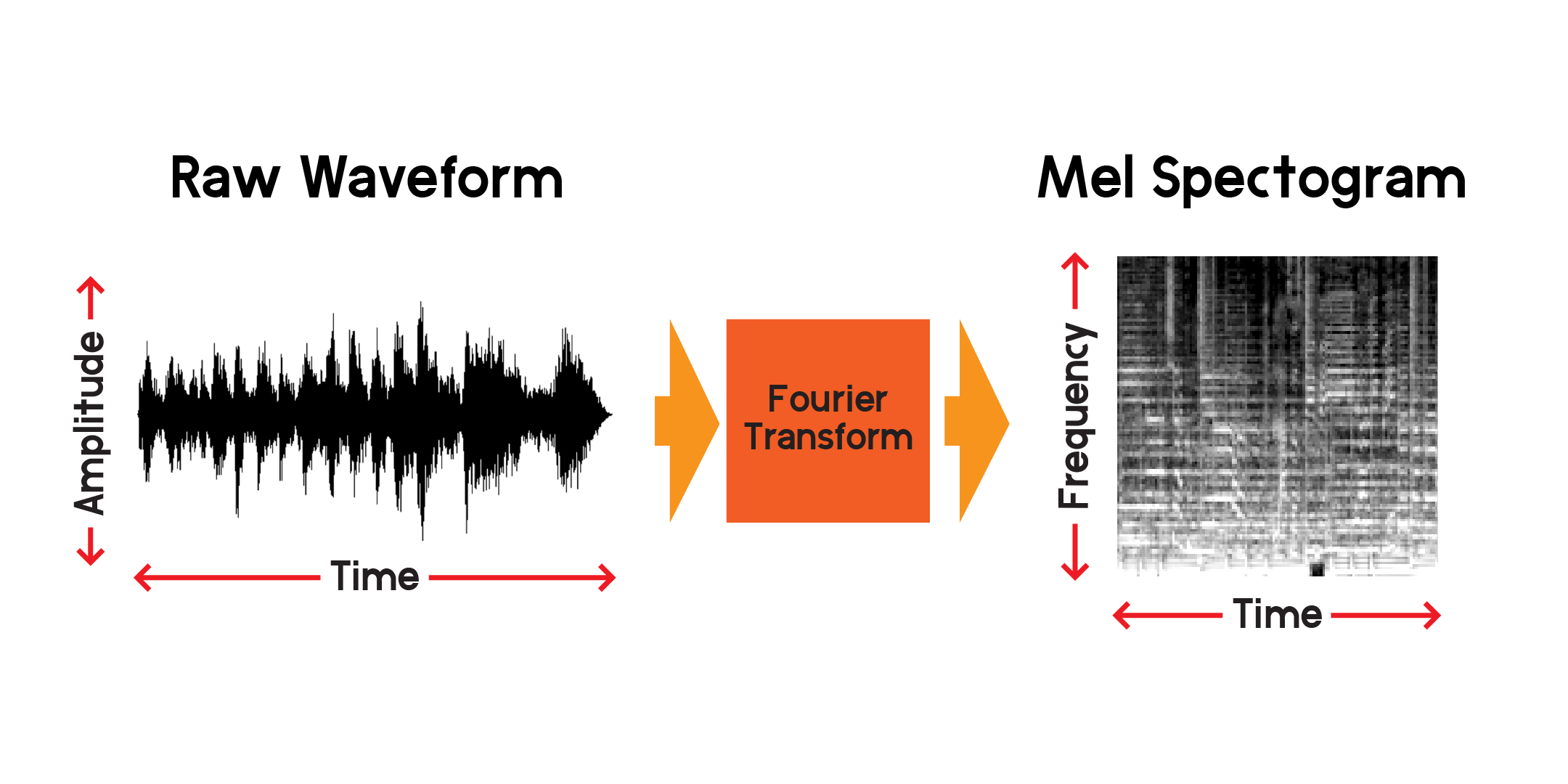
Lassen Sie uns ein Beispiel eines Mel-Spektrogramms aus demselben Audiobeispiel zeichnen, das wir oben aufgezeichnet haben:
Mithilfe der öffentlichen API von Spotify habe ich Songinformationen aus einem früheren Notizbuch herausgesucht. Von dort kann ich eine 30-sekündige MP3-Vorschau jedes Songs herunterladen und sie in ein Mel-Spektrogramm umwandeln, um es in einem neuronalen Netzwerk zu verwenden, das auf Bildern trainiert. Werfen wir zunächst einen Blick auf den Datenrahmen, den wir zum Sammeln der MP3-Vorschauen verwenden werden.
In einem anderen Notizbuch habe ich Vorschau-Links von der Spotify-API übernommen, die MP3s heruntergeladen und die Sounddateien in ein zusammengesetztes Bild konvertiert, das das Mel-Spektrogramm, den Mel-Frequenz-Cepstral-Koeffizienten und das Chromagramm enthält. Ich habe dieses zusammengesetzte Bild mit der Absicht erstellt, diese anderen Transformationen zu verwenden, aber für dieses Projekt werde ich das neuronale Netzwerk nur anhand der Mel-Spektrogramme trainieren.
Um Empfehlungen für ähnliche Songs allein auf der Grundlage des Soundinhalts abzugeben, muss ich Funktionen erstellen, die den Inhalt der Songs irgendwie erklären. Um dies schnell zu erledigen, muss ich außerdem die Informationen zu jedem Song in einen kleineren Zahlensatz komprimieren als die Eingabe von Mel-Spektrogrammen.
Für jede Song-Vorschaudatei gibt es über 600.000 Samples. In jedem Mel-Spektrogramm gibt es 512 x 128 Pixel, also insgesamt 65.536 Pixel. Selbst ein 128x128-Bild enthält 16.384 Pixel. Dieses Autoencoder-Modell komprimiert den Inhalt eines Songs in nur 256 Zahlen. Sobald der Autoencoder ausreichend trainiert ist, kann das Netzwerk mit minimalem Verlust einen Song aus diesem Vektor der Länge 256 rekonstruieren.
Ein Autoencoder ist eine Art neuronales Netzwerk, das aus einem Encoder und einem Decoder besteht. Erstens komprimiert der Encoder die Informationen der Eingabe in eine viel kleinere Datenmenge und der Decoder rekonstruiert die Daten so, dass sie der ursprünglichen Ausgabe so nahe wie möglich kommen.
Ein Autoencoder ist auch insofern eine besondere Art eines neuronalen Netzwerks, als er nicht überwacht wird, obwohl er nicht ganz unüberwacht ist. Es ist selbstüberwacht, da es seine Eingaben verwendet, um die Ausgaben des Modells zu trainieren.
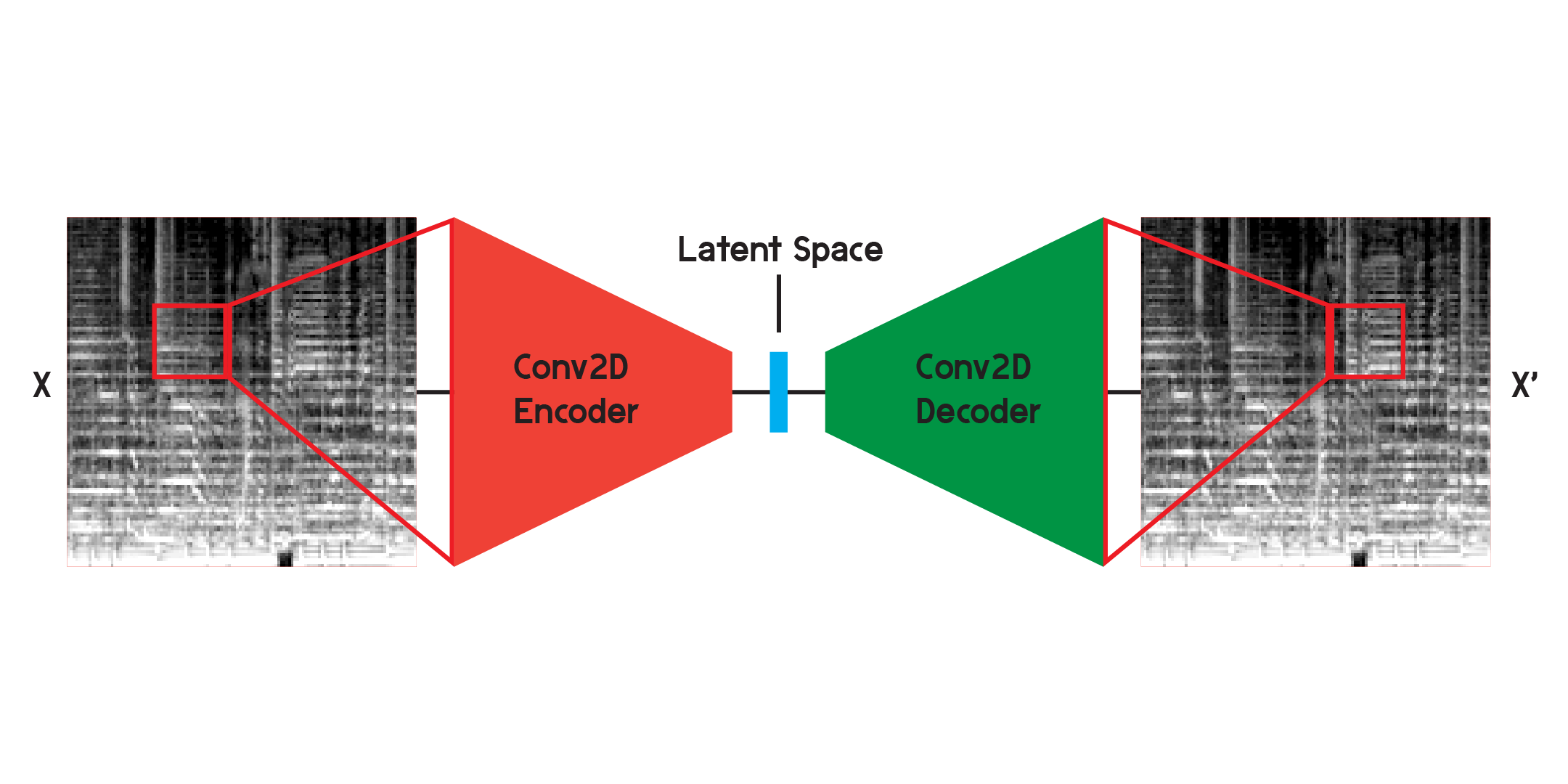
Bei der Arbeit mit Bildern ist der Encoder eine Folge zweidimensionaler Faltungsschichten, die gewichtete Filter erstellen, um Muster im Bild zu extrahieren und gleichzeitig das Bild in eine immer kleinere Form zu komprimieren. Der Decoder ist ein Spiegelbild des Prozesses im Encoder, der eine kleine Datenmenge umformt und zu einer größeren erweitert. Das Modell minimiert den mittleren quadratischen Fehler zwischen Original und Rekonstruktion. Sobald das Modell ausreichend trainiert ist, ist der mittlere quadratische Fehler zwischen dem Original und der Ausgabe des Modells sehr gering. Obwohl der mittlere quadratische Fehler minimal sein wird, gibt es dennoch einen visuellen Unterschied zwischen der Rekonstruktion und dem Originalbild, insbesondere in den kleinsten Details. Der Autoencoder ist ein Rauschunterdrücker. Wir möchten so viele Details wie möglich extrahieren, aber letztendlich wird der Autoencoder auch einige Details vermischen.
Ich habe das Netzwerk zunächst mit der oben dargestellten Struktur trainiert, stellte jedoch fest, dass in den Rekonstruktionen viele Details fehlten. Die Faltungsschichten suchen nach Mustern, die nur einen kleinen Ausschnitt des gesamten Bildes darstellen. Nach dem Training und Beobachten der Filter ist es jedoch schwierig, die extrahierten Muster zu verstehen.
Autoencoder wie dieser können für verschiedene Probleme verwendet werden, und mit Faltungsschichten gibt es viele Anwendungen für die Bilderkennung und -generierung. Da das Mel-Spektrogramm jedoch nicht nur ein Bild, sondern ein Diagramm der Frequenzen im Toninhalt über die Zeit ist, glaube ich, dass eine etwas andere Struktur implementiert werden kann, um den Verlust bei der Rekonstruktion zu minimieren und gleichzeitig die durch die zweidimensionale Faltung verursachte Unsicherheit zu minimieren Schichten.
In dem für die Endergebnisse des Modells verwendeten Modell habe ich den Encoder in zwei separate Encoder aufgeteilt. Jeder Encoder verwendet eindimensionale Faltungsschichten, um den Bildraum zu komprimieren. Ein Encoder trainiert auf X, während der andere auf X-Transponierung oder einer um 90 Grad gedrehten Version der Eingabe trainiert. Auf diese Weise lernt ein Encoder Informationen von der Zeitachse des Bildes und der andere von der Frequenzachse.
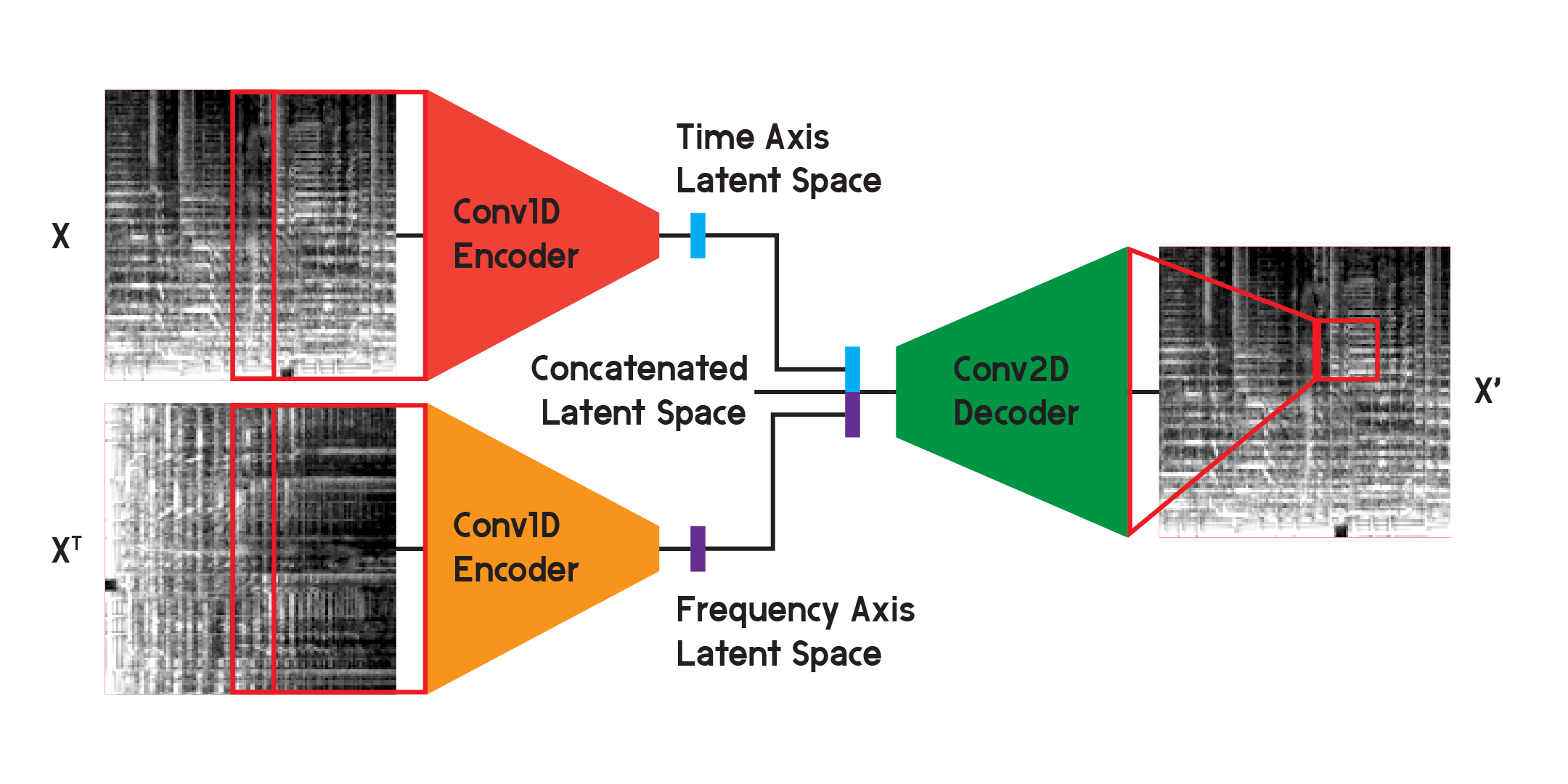
Nachdem die Eingabe jeden Encoder durchlaufen hat, werden die resultierenden codierten Vektoren zu einem Vektor verkettet und wie zuvor dargestellt in den zweidimensionalen Faltungsdecoder eingegeben. Die Ausgänge werden trainiert, um den Verlust zwischen den Eingängen wie zuvor zu minimieren.
Am Ende war der Verlust im endgültigen Modell viel geringer als in der Grundstruktur und erreichte nach 20 Epochen einen mittleren quadratischen Fehler von 0,0037 (Training) und 0,0037 (Validierung), mit 125.440 Bildern im Trainingssatz und 2560 im Validierungssatz.
Wir werden das Modell hier nur zu Demonstrationszwecken bauen, da ich das Modell in einem anderen Notebook trainiert habe und die Gewichte aus dem trainierten Modell laden werde, sobald es gebaut ist.
Mithilfe einer benutzerdefinierten Klasse zum Ausführen von Inferenzen durch das Netzwerk und zum Speichern von Ergebnissen können wir den latenten Raum für jedes Mel-Spektrogramm erstellen, das wir haben. Wir können dies erreichen, indem wir die Daten nur durch den Encoder laufen lassen und einen Vektor mit der Größe erhalten, mit der wir das Modell initialisiert haben, in diesem Fall mit 256 Dimensionen.
Um die abstrakte Landschaft, die durch den latenten Raum der Daten entsteht, durch das Modell zu erkunden, können wir die Dimensionsreduktion verwenden. UMAP kann wie T-SNE einen mehrdimensionalen Raum zur Visualisierung in einem Diagramm in zwei Dimensionen reduzieren.
Die benutzerdefinierte LatentSpace-Klasse sucht mithilfe der Kosinusähnlichkeit für jeden Vektor nach Empfehlungen.
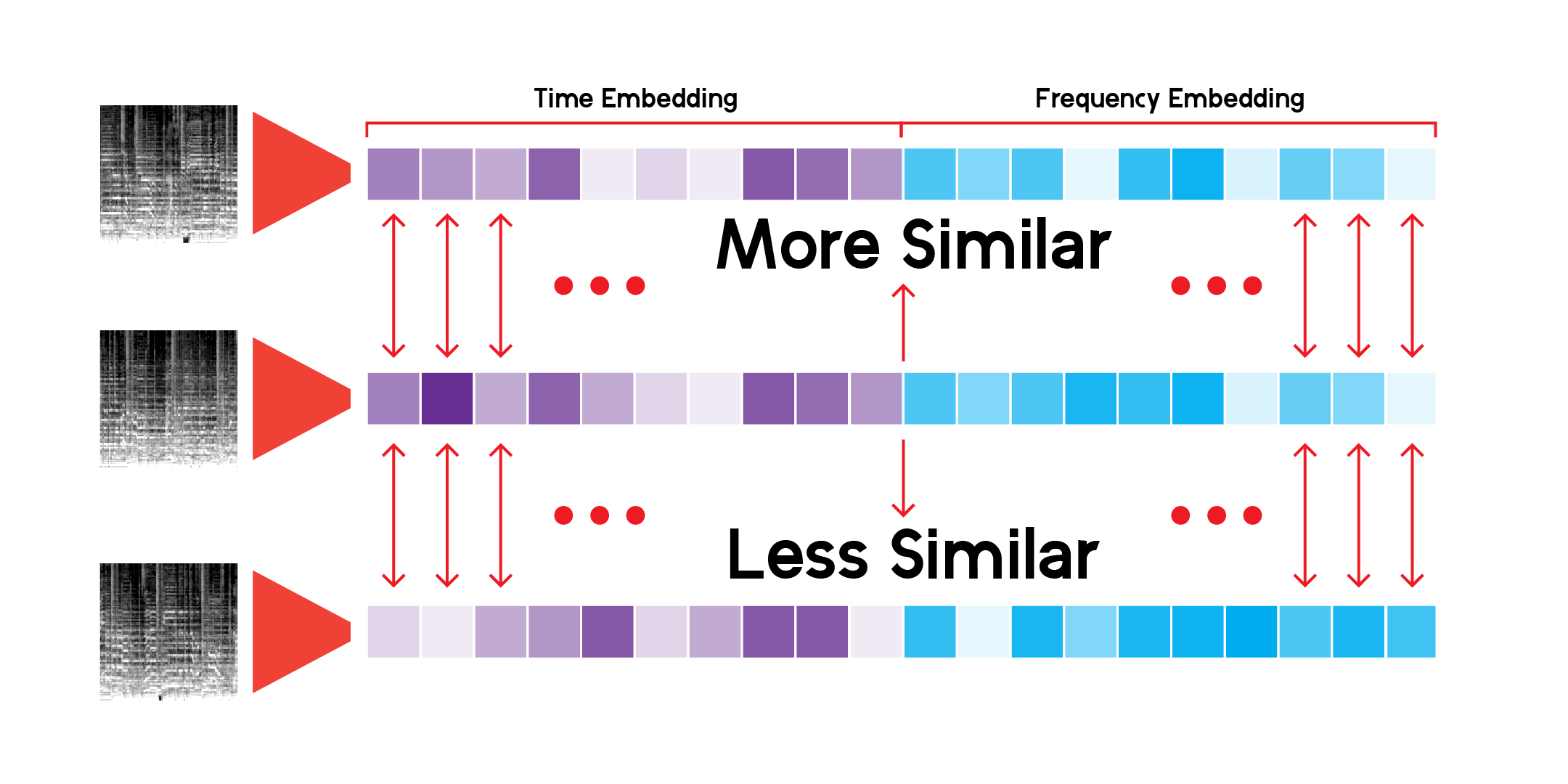
Ich habe dieses Empfehlungssystem endlos durchforstet und bin zufrieden, dass das Modell sehr interessante Verbindungen zwischen verschiedenen, aber auch ähnlichen Musikklängen erkennen kann. Hier sind einige meiner Schlussfolgerungen:
Damit meine ich, dass das Modell Empfehlungen auf der Grundlage des Klanginhalts in jedem Song abgibt, sich den Song aber nicht anhört. Es erstellt ein Mel-Spektrogramm und führt einen mathematischen Vergleich durch.
Manchmal empfiehlt das System ein Lied basierend auf seinem Alter. Wenn ein Lied vor langer Zeit aufgenommen wurde, werden diese bestimmten Frequenzen des Aufnahmematerials oder der Ausrüstung vom Modell erfasst und die Ergebnisse angezeigt.
Außerdem eignet sich das Modell sehr gut für die Aufnahme von Stimmen oder bestimmten Instrumenten. Aus diesem Grund werden bei einem Lied, in dem viel geredet oder gesungen wird, möglicherweise nur Spoken-Word-Tracks empfohlen. Wenn ein Lied stark verzerrt ist, werden möglicherweise Regengeräusche oder Vogelgesänge empfohlen.
Einige Titelvorschauen sind in der Spotify-API nicht verfügbar, wie in meinem ersten EDA erwähnt. Daher fehlt auch ihr Beitrag zum Modell und stellt keine Empfehlung dar, wenn sie möglicherweise perfekt dazu passen. Es gibt beispielsweise keine Lieder von James Brown, den Beatles oder Prince. Benötigt mehr Daten.
Das System verwendet über 278.000 Vorschauen, um Empfehlungen abzugeben, und das ist immer noch nicht genug. Wenn man sich die UMAP-Projektion für alle Tracks ansieht, gibt es eine große Kontinuität in den Daten, aber es gibt auch einige Lücken. Im Idealfall könnte das System auf viel mehr Daten zurückgreifen.
Was ein Empfehlungssystem bzw. einen Empfehlungsdienst wie Spotify so gut für die Abgabe von Empfehlungen macht, ist die Tatsache, dass es viele verschiedene Arten von Empfehlungssystemen und Funktionen wie dieses kombiniert, um Empfehlungen bereitzustellen. Von der Verfolgung dessen, was Sie regelmäßig hören, bis hin zur Verwendung kollaborativer Filterung, um Empfehlungen basierend auf ähnlicher Benutzernutzung zu finden, kann Spotify viel ausgewogenere Vorhersagen darüber treffen, was jemand mögen und hören wird. Ich finde dieses Modell zwar interessant, um Vorhersagen zu treffen, aber es kann durch das Hinzufügen weiterer Funktionen wie ähnlicher Genres, Veröffentlichungsjahre und ähnlicher Benutzerdaten erweitert werden, um bessere Vorhersagen zu treffen.
Alles in allem glaube ich, dass die wahre Bedeutung dieses Modells, abgesehen von Vorhersagen und Empfehlungen, darin besteht, die Kontinuität und das Spektrum der musikalischen Sprache und des Klangs zu erklären. Genres sind Bezeichnungen, die Menschen einem Künstler oder Sound geben, aber Genres vermischen sich und jeder Sound existiert in diesem kontinuierlichen Raum, zumindest mathematisch gesehen.
Auch Musik kennt keine Barrieren. Wenn man im Empfehlungssystem nach einem Lied sucht, kommen die Ergebnisse meistens aus allen Epochen und von allen Orten. Da keine der Metadaten eines Songs eine Eingabe für den Autoencoder sind, basieren die Ergebnisse auf ihrer klanglichen Ähnlichkeit und nicht mehr.


