nlp lt
1.0.0
Die Hauptabsicht dieser Forschung besteht darin, Prinzipien der natürlichen Sprachverarbeitung (NLP) für die litauische Sprache zu studieren und zu erlernen. Es ist interessant, klassische NLP-Methoden zu analysieren und zu sehen, wie sie darauf funktionieren. Deshalb habe ich in dieser Arbeit Textklassifizierung, Themenextraktion, Suchabfragen und Clustering-Ideen implementiert. Einzelheiten zur Implementierung und weitere Informationen finden Sie unter paper/paper.pdf
Eine Datenanalyse kann ohne Textdaten nicht durchgeführt werden, weshalb meine Arbeit damit begann, Rohdaten von der beliebtesten Nachrichten-Website www.delfi.lt zu sammeln. Ich habe beschlossen, Artikel aus 5 Kategorien zu crawlen (Kriminelle[227 Artikel], Musik[120 Artikel], Filme[167 Artikel], Sport[136 Artikel], Wissenschaft[204 Artikel]).
Die Klassifizierungsleistung wird mithilfe einer Verwirrungsmatrix gemessen, wobei die Zeilen die wahre Kategorie und die Spalten die vorhergesagte Kategorie darstellen. Darüber hinaus erreicht ein solcher Ansatz eine Erinnerung von über 90 % und eine Präzision von 90 %.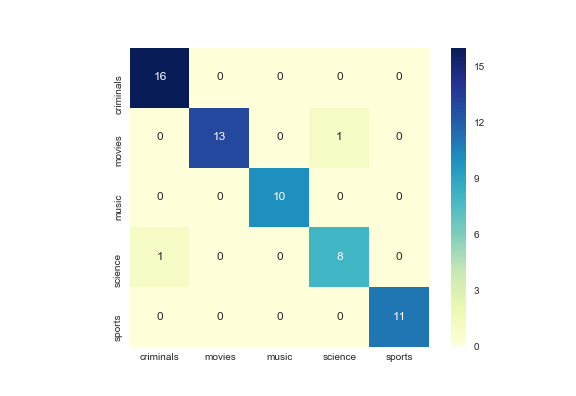
Abbildung zeigt 6 Komponenten mit 10 Token für jede Komponente. Anhand dieser Ergebnisse können wir die wichtigsten Wörter erkennen und intuitiv das Thema für jede Hauptkomponente erraten. Beispielsweise speichern die vier Hauptkomponenten Informationen über Sport und Musik, während die sechs Hauptkomponenten Informationen über Kriminelle speichern.
Die wichtigsten Ergebnisse sind nachstehend aufgeführt: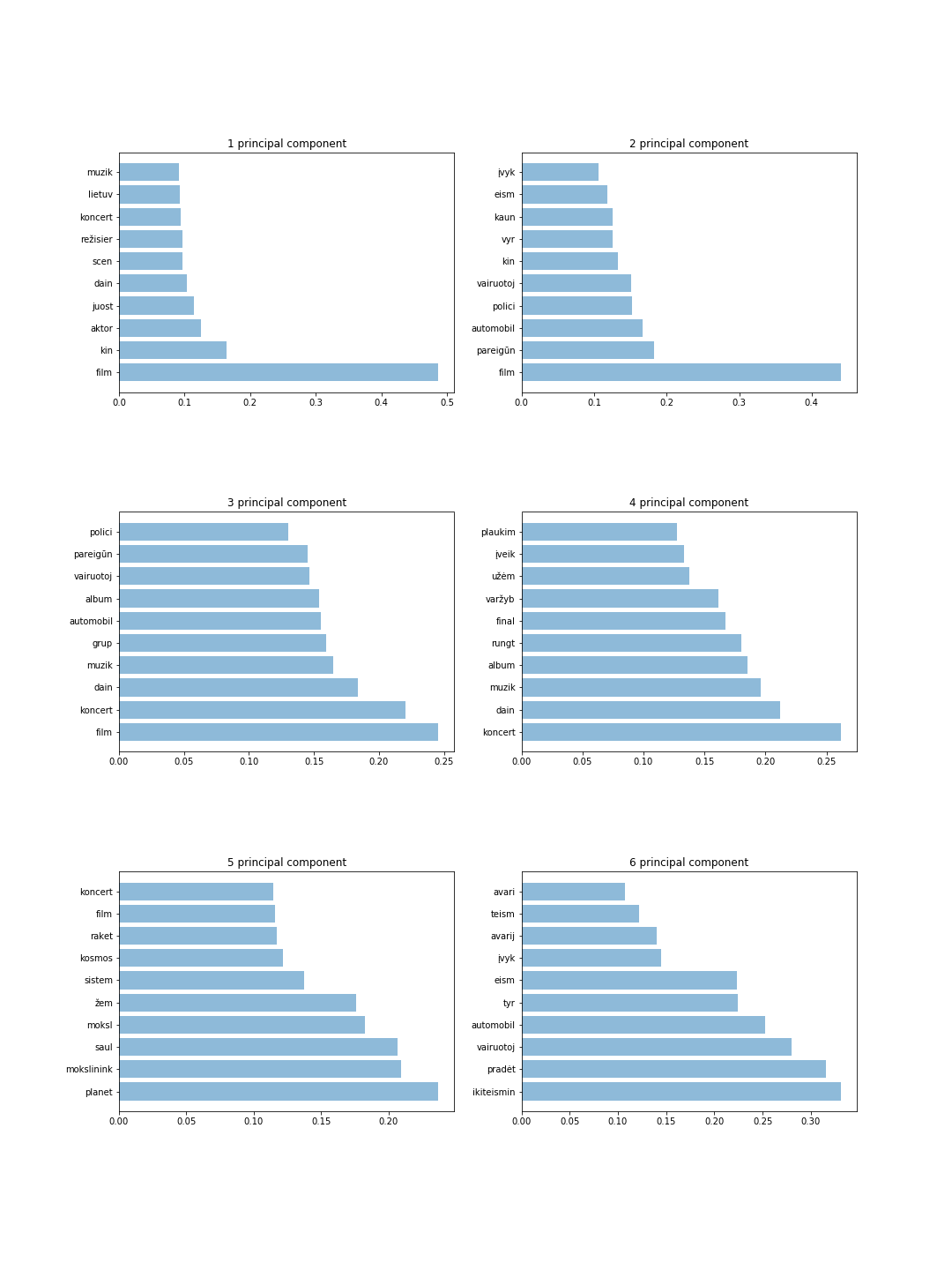
Die Suche basiert auf dem Artikel http://webhome.cs.uvic.ca/~thomo/svd.pdf, in dem LSA angewendet wird, um verwandte Dokumente zu finden, wobei nicht nur exakte Abfrageähnlichkeiten, sondern auch tiefere Beziehungen zwischen Dokumenten verwendet werden.
Abfrage = „švietim apdovanojam“
Ergebnis:
In Bearbeitung


