
Dieses Repo enthält Fragen und Übungen zu verschiedenen technischen Themen, manchmal im Zusammenhang mit DevOps und SRE
Derzeit gibt es 2624 Übungen und Fragen
️ Sie können diese zur Vorbereitung auf ein Vorstellungsgespräch verwenden, die meisten Fragen und Übungen stellen jedoch kein tatsächliches Vorstellungsgespräch dar. Weitere Informationen finden Sie auf der FAQ-Seite
? Wenn Sie an einer Karriere als DevOps-Ingenieur interessiert sind, wäre es hilfreich, einige der hier genannten Konzepte zu erlernen. Sie sollten jedoch wissen, dass es nicht darum geht, alle in diesem Repository erwähnten Themen und Technologien zu erlernen
Sie können weitere Übungen hinzufügen, indem Sie Pull-Requests einreichen :) Lesen Sie hier die Beitragsrichtlinien

DevOps | 
Git | 
Netzwerk | 
Hardware | 
Kubernetes |

Softwareentwicklung | 
Python | 
Gehen | 
Perl | 
Regex |

Wolke | 
AWS | 
Azurblau | 
Google Cloud-Plattform | 
OpenStack |

Betriebssystem | 
Linux | 
Virtualisierung | 
DNS | 
Shell-Scripting |

Datenbanken | 
SQL | 
Mongo | 
Testen | 
Big Data |

CI/CD | 
Zertifikate | 
Container | 
OpenShift | 
Lagerung |

Terraform | 
Marionette | 
Verteilt | 
Fragen, die Sie stellen können | 
Ansible |

Beobachtbarkeit | 
Prometheus | 
Kreis CI | 
| 
Grafana |

Argo | 
Soft Skills | 
Sicherheit | 
Systemdesign |

Chaos-Engineering | 
Sonstiges | 
Elastisch | 
Kafka | 
NodeJs |
Netzwerk
Was brauchen Sie im Allgemeinen, um zu kommunizieren?
- Eine gemeinsame Sprache (damit beide Enden sie verstehen können)
- Eine Möglichkeit, mit wem Sie kommunizieren möchten
- A Connection (damit der Inhalt der Kommunikation die Empfänger erreichen kann)
Was ist TCP/IP?
Eine Reihe von Protokollen, die definieren, wie zwei oder mehr Geräte miteinander kommunizieren können.
Um mehr über TCP/IP zu erfahren, lesen Sie hier
Was ist Ethernet?
Ethernet bezieht sich einfach auf die heute am häufigsten verwendete Art von lokalem Netzwerk (LAN). Ein LAN ist – im Gegensatz zu einem WAN (Wide Area Network), das sich über einen größeren geografischen Bereich erstreckt – ein verbundenes Netzwerk von Computern in einem kleinen Bereich, wie Ihrem Büro, dem Universitätscampus oder sogar zu Hause.
Was ist eine MAC-Adresse? Wofür wird es verwendet?
Eine MAC-Adresse ist eine eindeutige Identifikationsnummer oder ein eindeutiger Code, der zur Identifizierung einzelner Geräte im Netzwerk verwendet wird.
Pakete, die über das Ethernet gesendet werden, kommen immer von einer MAC-Adresse und werden an eine MAC-Adresse gesendet. Wenn ein Netzwerkadapter ein Paket empfängt, vergleicht er die Ziel-MAC-Adresse des Pakets mit der eigenen MAC-Adresse des Adapters.
Wann wird diese MAC-Adresse verwendet?: ff:ff:ff:ff:ff:ff
Wenn ein Gerät ein Paket an die Broadcast-MAC-Adresse (FF:FF:FF:FF:FF:FF) sendet, wird es an alle Stationen im lokalen Netzwerk übermittelt. Ethernet-Broadcasts werden verwendet, um IP-Adressen auf der Datenverbindungsschicht in MAC-Adressen (per ARP) aufzulösen.
Was ist eine IP-Adresse?
Eine Internet Protocol-Adresse (IP-Adresse) ist eine numerische Bezeichnung, die jedem Gerät zugewiesen wird, das mit einem Computernetzwerk verbunden ist, das das Internet Protocol zur Kommunikation verwendet. Eine IP-Adresse erfüllt zwei Hauptfunktionen: Identifizierung des Hosts oder der Netzwerkschnittstelle und Standortadressierung.
Erklären Sie die Subnetzmaske und geben Sie ein Beispiel
Eine Subnetzmaske ist eine 32-Bit-Zahl, die eine IP-Adresse maskiert und die IP-Adressen in Netzwerkadressen und Hostadressen unterteilt. Die Subnetzmaske wird erstellt, indem die Netzwerkbits ausschließlich auf „1“ und die Hostbits ausschließlich auf „0“ gesetzt werden. Innerhalb eines Netzwerks sind von der Gesamtzahl der nutzbaren Hostadressen immer zwei für bestimmte Zwecke reserviert und können keinem Host zugeordnet werden. Dies sind die erste Adresse, die als Netzwerkadresse (auch Netzwerk-ID genannt) reserviert ist, und die letzte Adresse, die für die Netzwerkübertragung verwendet wird.
Beispiel
Was ist eine private IP-Adresse? In welchen Szenarien/Systemdesigns sollte man es verwenden?
Den Hosts im selben Netzwerk werden private IP-Adressen zugewiesen, um miteinander zu kommunizieren. Wie der Name „privat“ schon sagt, können die Geräte, denen die privaten IP-Adressen zugewiesen sind, von keinem externen Netzwerk aus erreicht werden. Wenn ich beispielsweise in einem Hostel wohne und möchte, dass meine Hostelkameraden dem von mir gehosteten Spieleserver beitreten, bitte ich sie, über die private IP-Adresse meines Servers beizutreten, da das Netzwerk lokal im Hostel ist. Was ist eine öffentliche IP-Adresse? In welchen Szenarien/Systemdesigns sollte man es verwenden?
Eine öffentliche IP-Adresse ist eine öffentlich zugängliche IP-Adresse. Für den Fall, dass Sie einen Spieleserver hosten, dem Ihre Freunde beitreten sollen, geben Sie Ihren Freunden Ihre öffentliche IP-Adresse, damit ihre Computer Ihr Netzwerk und Ihren Server identifizieren und lokalisieren können, damit die Verbindung hergestellt werden kann. Wenn Sie mit Freunden spielen, die mit demselben Netzwerk wie Sie verbunden sind, würden Sie in diesem Fall keine öffentliche IP-Adresse verwenden müssen. In diesem Fall würden Sie eine private IP-Adresse verwenden. Damit jemand eine Verbindung zu Ihrem internen Server herstellen kann, müssen Sie eine Portweiterleitung einrichten, um Ihrem Router mitzuteilen, dass er Datenverkehr aus dem öffentlichen Bereich in Ihr Netzwerk und umgekehrt zulässt. Erklären Sie das OSI-Modell. Welche Schichten gibt es? Wofür ist jede Schicht verantwortlich?
- Anwendung: Benutzerseite (HTTP ist hier)
- Präsentation: stellt Kontext zwischen Entitäten auf Anwendungsebene her (Verschlüsselung ist hier)
- Sitzung: stellt Verbindungen her, verwaltet und beendet
- Transport: überträgt Datensequenzen variabler Länge von einer Quelle zu einem Zielhost (TCP). & UDP sind hier)
- Netzwerk: überträgt Datagramme von einem Netzwerk zu einem anderen (IP ist hier)
- Datenverbindung: stellt eine Verbindung zwischen zwei direkt verbundenen Knoten her (MAC ist hier)
- Physisch: die elektrische und physikalische Spezifikation der Datenverbindung (Bits sind hier). )
Weitere Informationen zum OSI-Modell finden Sie auf penguintutor.com
Für jedes der folgenden Elemente wird bestimmt, zu welcher OSI-Schicht es gehört:- Fehlerkorrektur
- Paketrouting
- Kabel und elektrische Signale
- MAC-Adresse
- IP-Adresse
- Verbindungen beenden
- 3-Wege-Handshake
Fehlerkorrektur – Weiterleitung von Datenverbindungspaketen – Netzwerkkabel und elektrische Signale – Physische MAC-Adresse – Datenverbindungs -IP-Adresse – Netzwerkverbindungen beenden – Sitzung 3-Wege-Handschlag – Transport Welche Lieferformen kennen Sie?
Unicast: Eins-zu-eins-Kommunikation, bei der es einen Sender und einen Empfänger gibt.
Broadcast: Senden einer Nachricht an alle im Netzwerk. Für die Übertragung wird die Adresse ff:ff:ff:ff:ff:ff verwendet. Zwei gängige Protokolle, die Broadcast verwenden, sind ARP und DHCP.
Multicast: Senden einer Nachricht an eine Gruppe von Abonnenten. Es kann eins-zu-viele oder viele-zu-viele sein.
Was ist CSMA/CD? Wird es in modernen Ethernet-Netzwerken verwendet?
CSMA/CD steht für Carrier Sense Multiple Access/Collision Detection. Sein Hauptaugenmerk liegt auf der Verwaltung des Zugriffs auf ein gemeinsam genutztes Medium/Bus, auf dem zu einem bestimmten Zeitpunkt nur ein Host senden kann.
CSMA/CD-Algorithmus:
Vor dem Senden eines Frames wird geprüft, ob bereits ein anderer Host einen Frame sendet.- Wenn niemand sendet, beginnt die Übertragung des Frames.
- Wenn zwei Hosts gleichzeitig senden, liegt eine Kollision vor.
- Beide Hosts hören auf, den Frame zu senden, und senden allen ein „Jam-Signal“, um alle darüber zu informieren, dass eine Kollision aufgetreten ist
- Sie warten eine zufällige Zeit lang, bevor sie es erneut senden
- Sobald jeder Host eine zufällige Zeitspanne gewartet hat, versucht er erneut, den Frame zu senden, und so beginnt der Zyklus erneut
Beschreiben Sie die folgenden Netzwerkgeräte und den Unterschied zwischen ihnen:
Ein Router, ein Switch und ein Hub sind alles Netzwerkgeräte, die zum Verbinden von Geräten in einem lokalen Netzwerk (LAN) verwendet werden. Allerdings funktioniert jedes Gerät anders und hat seine spezifischen Anwendungsfälle. Hier finden Sie eine kurze Beschreibung der einzelnen Geräte und der Unterschiede zwischen ihnen:
Router: ein Netzwerkgerät, das mehrere Netzwerksegmente miteinander verbindet. Es arbeitet auf der Netzwerkschicht (Schicht 3) des OSI-Modells und verwendet Routing-Protokolle, um Daten zwischen Netzwerken zu leiten. Router verwenden IP-Adressen, um Geräte zu identifizieren und Datenpakete an das richtige Ziel weiterzuleiten.- Switch: ein Netzwerkgerät, das mehrere Geräte in einem LAN verbindet. Es arbeitet auf der Datenverbindungsschicht (Schicht 2) des OSI-Modells und verwendet MAC-Adressen, um Geräte zu identifizieren und Datenpakete an das richtige Ziel zu leiten. Mithilfe von Switches können Geräte im selben Netzwerk effizienter miteinander kommunizieren und Datenkollisionen verhindern, die auftreten können, wenn mehrere Geräte gleichzeitig Daten senden.
- Hub: Ein Netzwerkgerät, das mehrere Geräte über ein einziges Kabel verbindet und zum Verbinden mehrerer Geräte ohne Segmentierung eines Netzwerks verwendet wird. Im Gegensatz zu einem Switch arbeitet er jedoch auf der physikalischen Ebene (Schicht 1) des OSI-Modells und sendet Datenpakete einfach an alle mit ihm verbundenen Geräte, unabhängig davon, ob das Gerät der beabsichtigte Empfänger ist oder nicht. Dadurch kann es zu Datenkollisionen kommen und die Effizienz des Netzwerks kann darunter leiden. Hubs werden in modernen Netzwerkkonfigurationen im Allgemeinen nicht verwendet, da Switches effizienter sind und eine bessere Netzwerkleistung bieten.
Was ist eine „Kollisionsdomäne“?
Eine Kollisionsdomäne ist ein Netzwerksegment, in dem Geräte möglicherweise gegenseitig stören können, indem sie gleichzeitig versuchen, Daten zu übertragen. Wenn zwei Geräte gleichzeitig Daten übertragen, kann es zu einer Kollision kommen, die zum Verlust oder zur Beschädigung von Daten führt. In einer Kollisionsdomäne nutzen alle Geräte die gleiche Bandbreite und jedes Gerät kann möglicherweise die Datenübertragung durch andere Geräte stören. Was ist eine „Broadcast-Domain“?
Eine Broadcast-Domäne ist ein Netzwerksegment, in dem alle Geräte durch Senden von Broadcast-Nachrichten miteinander kommunizieren können. Eine Broadcast-Nachricht ist eine Nachricht, die an alle Geräte in einem Netzwerk und nicht nur an ein bestimmtes Gerät gesendet wird. In einer Broadcast-Domäne können alle Geräte Broadcast-Nachrichten empfangen und verarbeiten, unabhängig davon, ob die Nachricht für sie bestimmt war oder nicht. Drei Computer, die an einen Switch angeschlossen sind. Wie viele Kollisionsdomänen gibt es? Wie viele Broadcast-Domains?
Drei Kollisionsdomänen und eine Broadcast-Domäne
Wie funktioniert ein Router?
Ein Router ist ein physisches oder virtuelles Gerät, das Informationen zwischen zwei oder mehr paketvermittelten Computernetzwerken weiterleitet. Ein Router überprüft die Ziel-Internetprotokolladresse (IP-Adresse) eines bestimmten Datenpakets, berechnet den besten Weg, um sein Ziel zu erreichen, und leitet es dann entsprechend weiter.
Was ist NAT?
Network Address Translation (NAT) ist ein Prozess, bei dem eine oder mehrere lokale IP-Adressen in eine oder mehrere globale IP-Adressen und umgekehrt übersetzt werden, um den lokalen Hosts Internetzugriff zu ermöglichen.
Was ist ein Proxy? Wie funktioniert es? Wofür brauchen wir es?
Ein Proxyserver fungiert als Gateway zwischen Ihnen und dem Internet. Es handelt sich um einen Zwischenserver, der Endbenutzer von den Websites trennt, die sie durchsuchen.
Wenn Sie einen Proxyserver verwenden, fließt der Internetverkehr auf seinem Weg zur von Ihnen angeforderten Adresse über den Proxyserver. Die Anfrage kommt dann über denselben Proxyserver zurück (es gibt Ausnahmen von dieser Regel) und der Proxyserver leitet dann die von der Website empfangenen Daten an Sie weiter.
Proxyserver bieten je nach Anwendungsfall, Bedarf oder Unternehmensrichtlinie unterschiedliche Ebenen an Funktionalität, Sicherheit und Datenschutz.
Was ist TCP? Wie funktioniert es? Was ist der 3-Wege-Handshake?
TCP 3-Wege-Handshake oder Drei-Wege-Handshake ist ein Prozess, der in einem TCP/IP-Netzwerk verwendet wird, um eine Verbindung zwischen Server und Client herzustellen.
Ein Drei-Wege-Handshake wird hauptsächlich zum Erstellen einer TCP-Socket-Verbindung verwendet. Es funktioniert, wenn:
Ein Client-Knoten sendet ein SYN-Datenpaket über ein IP-Netzwerk an einen Server im selben oder einem externen Netzwerk. Das Ziel dieses Pakets besteht darin, zu fragen bzw. abzuleiten, ob der Server für neue Verbindungen geöffnet ist.- Der Zielserver muss über offene Ports verfügen, die neue Verbindungen akzeptieren und initiieren können. Wenn der Server das SYN-Paket vom Client-Knoten empfängt, antwortet er und sendet eine Bestätigungsbestätigung zurück – das ACK-Paket oder SYN/ACK-Paket.
- Der Client-Knoten empfängt das SYN/ACK vom Server und antwortet mit einem ACK-Paket.
Was ist eine Hin- und Rücklaufzeit?
Aus Wikipedia: „Die Zeitspanne, die benötigt wird, um ein Signal zu senden, plus die Zeitspanne, die benötigt wird, bis eine Bestätigung dieses Signals empfangen wird.“
Bonusfrage: Was ist die RTT von LAN?
Wie funktioniert ein SSL-Handshake?
SSL-Handshake ist ein Prozess, der eine sichere Verbindung zwischen einem Client und einem Server herstellt. Der Client sendet eine Client-Hello-Nachricht an den Server, die die Version des SSL/TLS-Protokolls des Clients, eine Liste der vom Client unterstützten kryptografischen Algorithmen und einen Zufallswert enthält.- Der Server antwortet mit einer Server-Hallo-Nachricht, die die Serverversion des SSL/TLS-Protokolls, einen Zufallswert und eine Sitzungs-ID enthält.
- Der Server sendet eine Zertifikatsnachricht, die das Zertifikat des Servers enthält.
- Der Server sendet eine Server Hello Done-Nachricht, die angibt, dass der Server mit dem Senden von Nachrichten für die Server Hello-Phase fertig ist.
- Der Client sendet eine Client Key Exchange-Nachricht, die den öffentlichen Schlüssel des Clients enthält.
- Der Client sendet eine Nachricht zum Ändern der Verschlüsselungsspezifikation, die den Server darüber informiert, dass der Client im Begriff ist, eine mit der neuen Verschlüsselungsspezifikation verschlüsselte Nachricht zu senden.
- Der Client sendet eine verschlüsselte Handshake-Nachricht, die das mit dem öffentlichen Schlüssel des Servers verschlüsselte Pre-Master-Geheimnis enthält.
- Der Server sendet eine Nachricht zum Ändern der Verschlüsselungsspezifikation, die den Client darüber informiert, dass der Server im Begriff ist, eine mit der neuen Verschlüsselungsspezifikation verschlüsselte Nachricht zu senden.
- Der Server sendet eine verschlüsselte Handshake-Nachricht, die das mit dem öffentlichen Schlüssel des Clients verschlüsselte Pre-Master-Geheimnis enthält.
- Client und Server können nun Anwendungsdaten austauschen.
Was ist der Unterschied zwischen TCP und UDP?
TCP stellt eine Verbindung zwischen dem Client und dem Server her, um die Reihenfolge der Pakete zu gewährleisten. UDP hingegen stellt keine Verbindung zwischen Client und Server her und verarbeitet keine Paketbestellungen. Dadurch ist UDP leichter als TCP und ein perfekter Kandidat für Dienste wie Streaming.
Penguintutor.com bietet eine gute Erklärung.
Welche TCP/IP-Protokolle kennen Sie?
Erklären Sie das „Standard-Gateway“
Ein Standard-Gateway dient als Zugangspunkt oder IP-Router, den ein vernetzter Computer verwendet, um Informationen an einen Computer in einem anderen Netzwerk oder im Internet zu senden.
Was ist ARP? Wie funktioniert es?
ARP steht für Address Resolution Protocol. Wenn Sie versuchen, eine IP-Adresse in Ihrem lokalen Netzwerk anzupingen, beispielsweise 192.168.1.1, muss Ihr System die IP-Adresse 192.168.1.1 in eine MAC-Adresse umwandeln. Dabei wird ARP zum Auflösen der Adresse verwendet, daher der Name.
Systeme führen eine ARP-Nachschlagetabelle, in der sie Informationen darüber speichern, welche IP-Adressen welchen MAC-Adressen zugeordnet sind. Wenn versucht wird, ein Paket an eine IP-Adresse zu senden, prüft das System zunächst anhand dieser Tabelle, ob die MAC-Adresse bereits bekannt ist. Wenn ein Wert zwischengespeichert ist, wird ARP nicht verwendet.
Was ist TTL? Was hilft es zu verhindern?
TTL (Time to Live) ist ein Wert in einem IP-Paket (Internet Protocol), der bestimmt, wie viele Hops oder Router ein Paket durchlaufen kann, bevor es verworfen wird. Jedes Mal, wenn ein Paket von einem Router weitergeleitet wird, wird der TTL-Wert um eins verringert. Wenn der TTL-Wert Null erreicht, wird das Paket verworfen und eine ICMP-Nachricht (Internet Control Message Protocol) wird an den Absender zurückgesendet, die angibt, dass das Paket abgelaufen ist.- TTL wird verwendet, um zu verhindern, dass Pakete unbegrenzt im Netzwerk zirkulieren, was zu einer Überlastung führen und die Netzwerkleistung beeinträchtigen kann.
- Es trägt auch dazu bei, zu verhindern, dass Pakete in Routing-Schleifen hängen bleiben, in denen Pakete kontinuierlich zwischen denselben Routern übertragen werden, ohne jemals ihr Ziel zu erreichen.
- Darüber hinaus kann TTL dazu verwendet werden, IP-Spoofing-Angriffe zu erkennen und zu verhindern, bei denen ein Angreifer versucht, sich mit einer falschen oder gefälschten IP-Adresse als ein anderes Gerät im Netzwerk auszugeben. Durch die Begrenzung der Anzahl der Hops, die ein Paket durchlaufen kann, kann TTL dazu beitragen, zu verhindern, dass Pakete an nicht legitime Ziele weitergeleitet werden.
Was ist DHCP? Wie funktioniert es?
Es steht für Dynamic Host Configuration Protocol und weist Hosts IP-Adressen, Subnetzmasken und Gateways zu. So funktioniert es:
- Ein Host sendet beim Betreten eines Netzwerks eine Nachricht auf der Suche nach einem DHCP-Server (DHCP DISCOVER).
- Eine Angebotsnachricht wird vom DHCP-Server als Paket mit Lease-Zeit, Subnetzmaske, IP-Adressen usw. zurückgesendet (DHCP-ANGEBOT).
- Abhängig davon, welches Angebot angenommen wird, sendet der Client einen Antwort-Broadcast zurück, der alle DHCP-Server darüber informiert (DHCP REQUEST).
- Der Server sendet eine Bestätigung (DHCP ACK)
Lesen Sie hier mehr
Können Sie zwei DHCP-Server im selben Netzwerk haben? Wie funktioniert es?
Es ist möglich, zwei DHCP-Server im selben Netzwerk zu haben, dies wird jedoch nicht empfohlen und es ist wichtig, sie sorgfältig zu konfigurieren, um Konflikte und Konfigurationsprobleme zu vermeiden.
Wenn zwei DHCP-Server im selben Netzwerk konfiguriert sind, besteht das Risiko, dass beide Server demselben Gerät IP-Adressen und andere Netzwerkkonfigurationseinstellungen zuweisen, was zu Konflikten und Verbindungsproblemen führen kann. Wenn die DHCP-Server außerdem mit unterschiedlichen Netzwerkeinstellungen oder -optionen konfiguriert sind, erhalten Geräte im Netzwerk möglicherweise widersprüchliche oder inkonsistente Konfigurationseinstellungen.- In einigen Fällen kann es jedoch erforderlich sein, zwei DHCP-Server im selben Netzwerk zu haben, beispielsweise in großen Netzwerken, in denen ein DHCP-Server möglicherweise nicht alle Anfragen verarbeiten kann. In solchen Fällen können DHCP-Server so konfiguriert werden, dass sie unterschiedliche IP-Adressbereiche oder unterschiedliche Subnetze bedienen, sodass sie sich nicht gegenseitig stören.
Was ist SSL-Tunneling? Wie funktioniert es?
- SSL-Tunneling (Secure Sockets Layer) ist eine Technik, mit der eine sichere, verschlüsselte Verbindung zwischen zwei Endpunkten über ein unsicheres Netzwerk wie das Internet hergestellt wird. Der SSL-Tunnel wird durch die Kapselung des Datenverkehrs innerhalb einer SSL-Verbindung erstellt, was Vertraulichkeit, Integrität und Authentifizierung gewährleistet.
So funktioniert SSL-Tunneling:
Ein Client initiiert eine SSL-Verbindung zu einem Server, was einen Handshake-Prozess zum Aufbau der SSL-Sitzung umfasst.- Sobald die SSL-Sitzung eingerichtet ist, verhandeln Client und Server Verschlüsselungsparameter wie den Verschlüsselungsalgorithmus und die Schlüssellänge und tauschen dann digitale Zertifikate aus, um sich gegenseitig zu authentifizieren.
- Der Client sendet dann Datenverkehr über den SSL-Tunnel an den Server, der den Datenverkehr entschlüsselt und an sein Ziel weiterleitet.
- Der Server sendet den Datenverkehr über den SSL-Tunnel zurück an den Client, der den Datenverkehr entschlüsselt und an die Anwendung weiterleitet.
Was ist eine Steckdose? Wo können Sie die Liste der Sockets in Ihrem System sehen?
Ein Socket ist ein Software-Endpunkt, der die bidirektionale Kommunikation zwischen Prozessen über ein Netzwerk ermöglicht. Sockets bieten eine standardisierte Schnittstelle für die Netzwerkkommunikation und ermöglichen es Anwendungen, Daten über ein Netzwerk zu senden und zu empfangen. So zeigen Sie die Liste der offenen Sockets auf einem Linux-System an: netstat -an- Dieser Befehl zeigt eine Liste aller offenen Sockets zusammen mit ihrem Protokoll, ihrer lokalen Adresse, ihrer Fremdadresse und ihrem Status an.
Was ist IPv6? Warum sollten wir darüber nachdenken, es zu verwenden, wenn wir IPv4 haben?
- IPv6 (Internet Protocol Version 6) ist die neueste Version des Internet Protocol (IP), die zur Identifizierung und Kommunikation mit Geräten in einem Netzwerk verwendet wird. IPv6-Adressen sind 128-Bit-Adressen und werden in hexadezimaler Schreibweise ausgedrückt, z. B. 2001:0db8:85a3:0000:0000:8a2e:0370:7334.
Es gibt mehrere Gründe, warum wir die Verwendung von IPv6 anstelle von IPv4 in Betracht ziehen sollten:
Adressraum: IPv4 verfügt über einen begrenzten Adressraum, der in vielen Teilen der Welt erschöpft ist. IPv6 bietet einen viel größeren Adressraum und ermöglicht Billionen einzigartiger IP-Adressen.- Sicherheit: IPv6 beinhaltet integrierte Unterstützung für IPsec, das eine End-to-End-Verschlüsselung und Authentifizierung für den Netzwerkverkehr bietet.
- Leistung: IPv6 umfasst Funktionen, die zur Verbesserung der Netzwerkleistung beitragen können, wie z. B. Multicast-Routing, das es ermöglicht, ein einzelnes Paket gleichzeitig an mehrere Ziele zu senden.
- Vereinfachte Netzwerkkonfiguration: IPv6 umfasst Funktionen, die die Netzwerkkonfiguration vereinfachen können, z. B. die zustandslose Autokonfiguration, die es Geräten ermöglicht, ihre eigenen IPv6-Adressen automatisch zu konfigurieren, ohne dass ein DHCP-Server erforderlich ist.
- Bessere Mobilitätsunterstützung: IPv6 umfasst Funktionen, die die Mobilitätsunterstützung verbessern können, wie z. B. Mobile IPv6, das es Geräten ermöglicht, ihre IPv6-Adressen beizubehalten, wenn sie zwischen verschiedenen Netzwerken wechseln.
Was ist VLAN?
- Ein VLAN (Virtual Local Area Network) ist ein logisches Netzwerk, das eine Reihe von Geräten in einem physischen Netzwerk zusammenfasst, unabhängig von ihrem physischen Standort. VLANs werden erstellt, indem Netzwerk-Switches so konfiguriert werden, dass sie Frames, die von Geräten gesendet werden, die mit einem bestimmten Port oder einer bestimmten Portgruppe am Switch verbunden sind, eine bestimmte VLAN-ID zuweisen.
Was ist MTU?
MTU steht für Maximum Transmission Unit. Dies ist die Größe der größten PDU (Protokolldateneinheit), die in einer einzelnen Transaktion gesendet werden kann.
Was passiert, wenn Sie ein Paket senden, das größer als die MTU ist?
Mit dem IPv4-Protokoll kann der Router die PDU fragmentieren und dann alle fragmentierten PDUs durch die Transaktion senden.
Beim IPv6-Protokoll wird ein Fehler an den Computer des Benutzers ausgegeben.
Wahr oder falsch? Ping verwendet UDP, weil ihm eine zuverlässige Verbindung egal ist
FALSCH. Ping verwendet tatsächlich ICMP (Internet Control Message Protocol), ein Netzwerkprotokoll, das zum Senden von Diagnosemeldungen und Steuermeldungen im Zusammenhang mit der Netzwerkkommunikation verwendet wird.
Was ist SDN?
SDN steht für Software-Defined Networking. Dabei handelt es sich um einen Ansatz zur Netzwerkverwaltung, bei dem die Zentralisierung der Netzwerksteuerung im Vordergrund steht und es Administratoren ermöglicht, das Netzwerkverhalten durch eine Software-Abstraktion zu verwalten.- In einem herkömmlichen Netzwerk werden Netzwerkgeräte wie Router, Switches und Firewalls einzeln mithilfe spezieller Software oder Befehlszeilenschnittstellen konfiguriert und verwaltet. Im Gegensatz dazu trennt SDN die Netzwerksteuerungsebene von der Datenebene, sodass Administratoren das Netzwerkverhalten über einen zentralen Software-Controller verwalten können.
Was ist ICMP? Wofür wird es verwendet?
- ICMP steht für Internet Control Message Protocol. Es handelt sich um ein Protokoll, das zu Diagnose- und Steuerungszwecken in IP-Netzwerken verwendet wird. Es ist Teil der Internet Protocol-Suite und arbeitet auf der Netzwerkebene.
ICMP-Nachrichten werden für verschiedene Zwecke verwendet, darunter:
Fehlerberichterstattung: ICMP-Nachrichten werden verwendet, um Fehler zu melden, die im Netzwerk auftreten, beispielsweise ein Paket, das nicht an sein Ziel zugestellt werden konnte.- Ping: ICMP wird zum Senden von Ping-Nachrichten verwendet, mit denen getestet wird, ob ein Host oder Netzwerk erreichbar ist, und um die Umlaufzeit für Pakete zu messen.
- Pfad-MTU-Erkennung: ICMP wird verwendet, um die Maximum Transmission Unit (MTU) eines Pfades zu ermitteln. Dies ist die größte Paketgröße, die ohne Fragmentierung übertragen werden kann.
- Traceroute: ICMP wird vom Dienstprogramm Traceroute verwendet, um den Pfad zu verfolgen, den Pakete durch das Netzwerk nehmen.
- Router-Erkennung: ICMP wird verwendet, um die Router in einem Netzwerk zu erkennen.
Was ist NAT? Wie funktioniert es?
NAT steht für Network Address Translation. Dies ist eine Möglichkeit, mehrere lokale private Adressen einer öffentlichen zuzuordnen, bevor die Informationen übertragen werden. Organisationen, die möchten, dass mehrere Geräte eine einzige IP-Adresse verwenden, verwenden NAT, ebenso wie die meisten Heimrouter. Die private IP-Adresse Ihres Computers könnte beispielsweise 192.168.1.100 lauten, Ihr Router ordnet den Datenverkehr jedoch seiner öffentlichen IP-Adresse zu (z. B. 1.1.1.1). Jedes Gerät im Internet würde den Datenverkehr sehen, der von Ihrer öffentlichen IP (1.1.1.1) statt von Ihrer privaten IP (192.168.1.100) kommt.
Welche Portnummer wird in jedem der folgenden Protokolle verwendet?:- SSH
- SMTP
- HTTP
- DNS
- HTTPS
- FTP
- SFTP
SSH - 22- SMTP – 25
- HTTP - 80
- DNS - 53
- HTTPS - 443
- FTP - 21
- SFTP – 22
Welche Faktoren beeinflussen die Netzwerkleistung?
Mehrere Faktoren können die Netzwerkleistung beeinflussen, darunter:
Bandbreite: Die verfügbare Bandbreite einer Netzwerkverbindung kann sich erheblich auf deren Leistung auswirken. Bei Netzwerken mit begrenzter Bandbreite kann es zu langsamen Datenübertragungsraten, hoher Latenz und schlechter Reaktionsfähigkeit kommen.- Latenz: Unter Latenz versteht man die Verzögerung, die auftritt, wenn Daten von einem Punkt in einem Netzwerk zu einem anderen übertragen werden. Hohe Latenzzeiten können zu einer langsamen Netzwerkleistung führen, insbesondere bei Echtzeitanwendungen wie Videokonferenzen und Online-Spielen.
- Netzwerküberlastung: Wenn zu viele Geräte gleichzeitig ein Netzwerk nutzen, kann es zu einer Netzwerküberlastung kommen, die zu langsamen Datenübertragungsraten und schlechter Netzwerkleistung führt.
- Paketverlust: Paketverlust tritt auf, wenn Datenpakete während der Übertragung verloren gehen. Dies kann zu langsameren Netzwerkgeschwindigkeiten und einer geringeren Gesamtleistung des Netzwerks führen.
- Netzwerktopologie: Der physische Aufbau eines Netzwerks, einschließlich der Platzierung von Switches, Routern und anderen Netzwerkgeräten, kann sich auf die Netzwerkleistung auswirken.
- Netzwerkprotokoll: Verschiedene Netzwerkprotokolle weisen unterschiedliche Leistungsmerkmale auf, die sich auf die Netzwerkleistung auswirken können. TCP ist beispielsweise ein zuverlässiges Protokoll, das die Übermittlung von Daten garantieren kann, aber aufgrund des für die Fehlerprüfung und erneute Übertragung erforderlichen Overheads auch zu einer langsameren Leistung führen kann.
- Netzwerksicherheit: Sicherheitsmaßnahmen wie Firewalls und Verschlüsselung können die Netzwerkleistung beeinträchtigen, insbesondere wenn sie erhebliche Rechenleistung erfordern oder zusätzliche Latenz verursachen.
- Entfernung: Die physische Entfernung zwischen Geräten in einem Netzwerk kann sich auf die Netzwerkleistung auswirken, insbesondere bei drahtlosen Netzwerken, bei denen Signalstärke und Interferenzen die Konnektivität und Datenübertragungsraten beeinträchtigen können.
Was ist APIPA?
APIPA ist ein Satz von IP-Adressen, die Geräten zugewiesen werden, wenn der Haupt-DHCP-Server nicht erreichbar ist
Welchen IP-Bereich verwendet APIPA?
APIPA verwendet den IP-Bereich: 169.254.0.1 – 169.254.255.254.
Kontrollebene und Datenebene
Was bedeutet „Kontrollebene“?
Die Kontrollebene ist ein Teil des Netzwerks, der entscheidet, wie Pakete an einen anderen Standort weitergeleitet und weitergeleitet werden.
Worauf bezieht sich „Datenebene“?
Die Datenebene ist ein Teil des Netzwerks, der die Daten/Pakete tatsächlich weiterleitet.
Was bedeutet „Managementebene“?
Es bezieht sich auf Überwachungs- und Managementfunktionen.
Zu welcher Ebene (Daten, Steuerung, ...) gehört die Erstellung von Routing-Tabellen?
Kontrollebene.
Erklären Sie das Spanning Tree Protocol (STP).
Was ist Link-Aggregation? Warum wird es verwendet?
Was ist asymmetrisches Routing? Wie damit umgehen?
Welche Overlay-(Tunnel-)Protokolle kennen Sie?
Was ist GRE? Wie funktioniert es?
Was ist VXLAN? Wie funktioniert es?
Was ist SNAT?
Erklären Sie OSPF.
OSPF (Open Shortest Path First) ist ein Routing-Protokoll, das auf verschiedenen Routertypen implementiert werden kann. Im Allgemeinen wird OSPF auf den meisten modernen Routern unterstützt, einschließlich denen von Anbietern wie Cisco, Juniper und Huawei. Das Protokoll ist für die Verwendung mit IP-basierten Netzwerken konzipiert, einschließlich IPv4 und IPv6. Außerdem wird ein hierarchisches Netzwerkdesign verwendet, bei dem Router in Bereiche gruppiert sind, wobei jeder Bereich über eine eigene Topologiekarte und Routing-Tabelle verfügt. Dieses Design trägt dazu bei, die Menge an Routing-Informationen zu reduzieren, die zwischen Routern ausgetauscht werden müssen, und die Netzwerkskalierbarkeit zu verbessern.
Die OSPF 4-Routertypen sind:
- Interner Router
- Bereichsgrenzrouter
- Grenzrouter für autonome Systeme
- Backbone-Router
Erfahren Sie mehr über OSPF-Routertypen: https://www.educba.com/ospf-router-types/
Was ist Latenz?
Latenz ist die Zeit, die Informationen benötigen, um von der Quelle ihr Ziel zu erreichen.
Was ist Bandbreite?
Unter Bandbreite versteht man die Fähigkeit eines Kommunikationskanals, zu messen, wie viele Daten dieser über einen bestimmten Zeitraum verarbeiten kann. Mehr Bandbreite würde mehr Verkehrsabwicklung und damit mehr Datenübertragung bedeuten.
Was ist Durchsatz?
Unter Durchsatz versteht man die Messung der tatsächlichen Datenmenge, die über einen bestimmten Zeitraum über einen beliebigen Übertragungskanal übertragen wird.
Was ist bei der Durchführung einer Suchanfrage wichtiger: Latenz oder Durchsatz? Und wie stellen wir sicher, dass wir die globale Infrastruktur verwalten?
Latenz. Um eine gute Latenz zu haben, sollte eine Suchanfrage an das nächstgelegene Rechenzentrum weitergeleitet werden.
Was ist beim Hochladen eines Videos wichtiger: Latenz oder Durchsatz? Und wie kann man das sicherstellen?
Durchsatz. Um einen guten Durchsatz zu erzielen, sollte der Upload-Stream an einen nicht ausreichend genutzten Link weitergeleitet werden.
Welche weiteren Überlegungen (außer Latenz und Durchsatz) gibt es bei der Weiterleitung von Anfragen?
- Halten Sie die Caches auf dem neuesten Stand (was bedeutet, dass die Anfrage möglicherweise nicht an das nächstgelegene Rechenzentrum weitergeleitet wird).
Erklären Sie Wirbelsäule und Blatt
„Spine & Leaf“ ist eine Netzwerktopologie, die häufig in Rechenzentrumsumgebungen verwendet wird, um mehrere Switches zu verbinden und den Netzwerkverkehr effizient zu verwalten. Sie wird auch als „Spine-Leaf“-Architektur oder „Leaf-Spine“-Topologie bezeichnet. Dieses Design bietet hohe Bandbreite, geringe Latenz und Skalierbarkeit und eignet sich daher ideal für moderne Rechenzentren, die große Daten- und Verkehrsmengen verarbeiten. Innerhalb eines Spine & Leaf-Netzwerks gibt es zwei Haupttypen von Switches:
- Spine-Switches: Spine-Switches sind Hochleistungsschalter, die in einer Spine-Schicht angeordnet sind. Diese Switches fungieren als Kern des Netzwerks und sind normalerweise mit jedem Leaf-Switch verbunden. Jeder Spine-Switch ist mit allen Leaf-Switches im Rechenzentrum verbunden.
- Leaf-Switches: Leaf-Switches werden mit Endgeräten wie Servern, Speicherarrays und anderen Netzwerkgeräten verbunden. Jeder Leaf-Switch ist mit jedem Spine-Switch im Rechenzentrum verbunden. Dadurch entsteht eine nicht blockierende, vollmaschige Konnektivität zwischen Leaf- und Spine-Switches, sodass jeder Leaf-Switch mit jedem anderen Leaf-Switch mit maximalem Durchsatz kommunizieren kann.
Die Spine & Leaf-Architektur erfreut sich in Rechenzentren immer größerer Beliebtheit, da sie den Anforderungen moderner Cloud-Computing-, Virtualisierungs- und Big-Data-Anwendungen gerecht wird und eine skalierbare, leistungsstarke und zuverlässige Netzwerkinfrastruktur bietet
Was ist eine Netzwerküberlastung? Was kann es verursachen?
Eine Netzwerküberlastung tritt auf, wenn in einem Netzwerk zu viele Daten übertragen werden müssen und das Netzwerk nicht über genügend Kapazität verfügt, um den Bedarf zu bewältigen.
Dies kann zu erhöhter Latenz und Paketverlust führen. Die Ursachen können vielfältig sein, z. B. hohe Netzwerkauslastung, große Dateiübertragungen, Malware, Hardwareprobleme oder Netzwerkdesignprobleme.
Um eine Überlastung des Netzwerks zu verhindern, ist es wichtig, die Netzwerknutzung zu überwachen und Strategien zur Begrenzung oder Steuerung der Nachfrage zu implementieren.
Was können Sie mir über das UDP-Paketformat sagen? Was ist mit dem TCP-Paketformat? Wie ist es anders?
Was ist der exponentielle Backoff-Algorithmus? Wo wird es verwendet?
Wie wäre unter Verwendung des Hamming-Codes das Codewort für das folgende Datenwort 100111010001101?
00110011110100011101
Nennen Sie Beispiele für Protokolle in der Anwendungsschicht
Hypertext Transfer Protocol (HTTP) – wird für Webseiten im Internet verwendet- Simple Mail Transfer Protocol (SMTP) – E-Mail-Übertragung
- Telekommunikationsnetzwerk – (TELNET) – Terminalemulation, um einem Client den Zugriff auf einen Telnet-Server zu ermöglichen
- File Transfer Protocol (FTP) – erleichtert die Übertragung von Dateien zwischen zwei beliebigen Computern
- Domain Name System (DNS) – Übersetzung von Domainnamen
- Dynamic Host Configuration Protocol (DHCP) – weist Hosts IP-Adressen, Subnetzmasken und Gateways zu
- Simple Network Management Protocol (SNMP) – sammelt Daten über Geräte im Netzwerk
Nennen Sie Beispiele für Protokolle, die in der Netzwerkschicht vorkommen
Internet Protocol (IP) – unterstützt die Weiterleitung von Paketen von einem Computer zum anderen- Internet Control Message Protocol (ICMP) – informiert Sie darüber, was gerade passiert, z. B. Fehlermeldungen und Debugging-Informationen
Was ist HSTS?
HTTP Strict Transport Security ist eine Webserver-Anweisung, die Benutzeragenten und Webbrowser durch einen Antwortheader, der ganz am Anfang und zurück an den Browser gesendet wird, darüber informiert, wie sie mit ihrer Verbindung umgehen sollen. Dadurch werden Verbindungen über HTTPS-Verschlüsselung erzwungen, wobei der Aufruf eines Skripts zum Laden einer Ressource in dieser Domäne über HTTP ignoriert wird. Lesen Sie mehr [hier](https://www.globalsign.com/en/blog/what-is-hsts-and-how-do-i-use-it#:~:text=HTTP%20Strict%20Transport%20Security %20(HSTS und %20zurück%20zum%20Browser.)
Netzwerk – Sonstiges
Was ist das Internet? Ist es dasselbe wie das World Wide Web?
Das Internet bezeichnet ein Netzwerk von Netzwerken, das riesige Datenmengen rund um den Globus überträgt.
Das World Wide Web ist eine Anwendung, die auf Millionen von Servern über dem Internet läuft und auf die über einen sogenannten Webbrowser zugegriffen wird
Was ist der ISP?
ISP (Internet Service Provider) ist der lokale Internetanbieter.
Betriebssystem
Betriebssystemübungen
| Name | Thema | Objektive & Anweisungen | Lösung | Kommentare |
|---|
| Gabel 101 | Gabel | Link | Link | |
| Gabel 102 | Gabel | Link | Link | |
Betriebssystem - Selbstbewertung
Was ist ein Betriebssystem?
Aus dem Buch "Betriebssysteme: Drei einfache Stücke":
"Verantwortlich dafür, Programme zu machen, um Programme auszuführen (auch wenn Sie scheinbar viele gleichzeitig ausführen können), damit Programme zum Austausch von Speicher und die Interaktion von Programmen mit Geräten und anderen lustigen Dingen wie dieser ermöglichen."
Betriebssystem - Prozess
Können Sie erklären, was ein Prozess ist?
Ein Prozess ist ein laufendes Programm. Ein Programm ist eine oder mehrere Anweisungen und das Programm (oder der Prozess) wird vom Betriebssystem ausgeführt.
Wenn Sie eine API für Prozesse in einem Betriebssystem entwerfen müssten, wie würde diese API aussehen?
Es würde Folgendes unterstützen:
Erstellen - Ermöglichen Sie neue Prozesse zu erstellen- Löschen - Ermöglichen Sie, Prozesse zu entfernen/zu zerstören
- Staat - Erlauben Sie, den Zustand des Prozesses zu überprüfen, egal ob er läuft, angehalten, warten usw.
- Stoppen - lassen Sie einen Laufprozess stoppen
Wie wird ein Prozess erstellt?
Das Betriebssystem liest den Code des Programms und zusätzliche relevante Daten- Der Code des Programms wird in den Speicher oder genauer gesagt in den Adressraum des Prozesses geladen.
- Der Speicher wird für den Stack des Programms (auch bekannt als Laufzeitstack) zugewiesen. Der Stapel wurde auch vom Betriebssystem mit Daten wie Argv, Argc und Parametern an Main () initialisiert.
- Der Speicher wird für das Programm des Programms zugewiesen, das für dynamisch zugewiesene Daten wie die verknüpften Datenstrukturen und Hash -Tabellen erforderlich ist
- E/A -Initialisierungsaufgaben werden wie in UNIX/Linux -basierten Systemen ausgeführt, wobei jeder Prozess 3 Dateideskriptoren hat (Eingabe, Ausgabe und Fehler)
- OS führt das Programm aus, beginnend von Main ()
Wahr oder falsch? Das Laden des Programms in den Speicher wird eifrig (auf einmal) erfolgen
FALSCH. Es war in der Vergangenheit zutreffend, aber die heutigen Betriebssysteme führen eine faule Belastung durch, was bedeutet, dass nur die relevanten Teile, die für den Ausführen erforderlich sind, zuerst geladen werden.
Was sind verschiedene Zustände eines Prozesses?
Ausführen - es führt Anweisungen aus- Bereit - es ist bereit zu rennen, aber aus verschiedenen Gründen ist es in der Warteschleife
- Blockiert - Es wartet, dass eine Operation abgeschlossen ist, z. B. E/A -Festplattenanforderung
Was sind einige Gründe, warum ein Prozess blockiert wird?
E/A -Operationen (z. B. Lesen von einer Festplatte)- Warten auf ein Paket aus einem Netzwerk
Was ist Inter Process Communication (IPC)?
Inter-Process Communication (IPC) bezieht sich auf die Mechanismen eines Betriebssystems, mit denen Prozesse gemeinsam genutzte Daten verwalten können.
Was ist "Zeitteilung"?
Selbst wenn ein System mit einer physischen CPU verwendet wird, können Sie mehreren Benutzern ermöglichen, daran zu arbeiten und Programme auszuführen. Dies ist mit der Zeitfreigabe möglich, wenn die Computerressourcen auf eine Weise geteilt werden, die dem Benutzer erscheint. Das System verfügt über mehrere CPUs. Tatsächlich ist es jedoch einfach eine CPU, die durch Anwenden von Multiprogrammierung und Multitasking geteilt wird.
Was ist "Space Sharing"?
Etwas Gegenteil von Tares Sharing. Während die Teilen einer Ressource für eine Weile von einer Entität verwendet werden und dann die gleiche Ressource von einer anderen Ressource verwendet werden kann, wird in der Freigabe des Raums von mehreren Entitäten gemeinsam genutzt, aber auf eine Weise, in der sie nicht zwischen ihnen übertragen wird.
Es wird von einer Entität verwendet, bis diese Entität beschließt, es loszuwerden. Nehmen Sie zum Beispiel Speicher. Im Speicher gehört eine Datei bei Ihnen, bis Sie sich entscheiden, sie zu löschen.
Welche Komponente bestimmt, welcher Prozess zu einem bestimmten Zeitpunkt ausgeführt wird?
CPU -Scheduler
Betriebssystem - Speicher
Was ist "virtuelles Gedächtnis" und welcher Zweck dient?
Der virtuelle Speicher kombiniert den RAM Ihres Computers mit vorübergehender Speicherplatz auf Ihrer Festplatte. Wenn RAM niedrig ausgeführt wird, hilft der virtuelle Speicher, Daten von RAM in einen Speicherplatz zu verschieben, der als Paging -Datei bezeichnet wird. Das Verschieben von Daten in die Paging -Datei kann den RAM freilegen, damit Ihr Computer seine Arbeiten erledigen kann. Je mehr RAM Ihr Computer hat, desto schneller werden die Programme ausgeführt. https://www.minitool.com/lib/virtual-memory.html
Was ist Nachfrage Paging?
Demand Paging ist eine Gedächtnisverwaltungstechnik, bei der Seiten nur dann in den physischen Speicher geladen werden, wenn er durch einen Prozess zugegriffen wird. Es optimiert die Speicherverwendung, indem Seiten auf Bedarf geladen werden, wodurch die Latenz und der Space Overhead von Starts reduziert werden. Es wird jedoch zum ersten Mal eine Latenz eingeführt, wenn Sie auf Seiten zugreifen. Insgesamt ist es ein kostengünstiger Ansatz für die Verwaltung von Speicherressourcen in Betriebssystemen.
Was ist Copy-on-Write?
Copy-on-Write (Cow) ist ein Ressourcenmanagementkonzept mit dem Ziel, unnötiges Kopieren von Informationen zu reduzieren. Es handelt sich um ein Konzept, das zum Beispiel innerhalb der POSIX -Fork -SYSCALL implementiert wird und einen doppelten Prozess des Aufrufprozesses erstellt. Die Idee:
Wenn Ressourcen zwischen 2 oder mehr Entitäten geteilt werden (z. B. gemeinsame Speichersegmente zwischen 2 Prozessen), müssen die Ressourcen nicht für jede Entität kopiert werden, sondern dass jede Entität über eine Berechtigung für den Operationszugriff auf der gemeinsamen Ressource verfügt. (Die gemeinsam genutzten Segmente sind als schreibgeschützt markiert) (denken Sie an jeden Unternehmen, der einen Zeiger auf den Ort der gemeinsamen Ressource hat, die den Wert des Wertes lesen kann.)- Wenn eine Entität einen Schreibvorgang in einer gemeinsamen Ressource ausführen würde, würde ein Problem auftreten, da die Ressource auch für alle anderen Unternehmen, die sie teilen, dauerhaft geändert werden. (Denken Sie an einen Prozess, der einige Variablen auf dem Stapel ändert oder einige Daten dynamisch auf dem Haufen zuweisen. Diese Änderungen an der gemeinsamen Ressource würden auch für alle anderen Prozesse gelten. Dies ist definitiv ein unerwünschtes Verhalten.)
- Nur als Lösung wird diese Ressource zuerst kopiert und dann die Änderungen angewendet.
Was ist ein Kernel und was macht er?
Der Kernel ist Teil des Betriebssystems und für Aufgaben verantwortlich wie:
Speicher zuweisen- Zeitplanprozesse
- Kontrolle der CPU
Wahr oder falsch? Einige Teile des Codes im Kernel werden in geschützte Bereiche des Speichers geladen, sodass Anwendungen sie nicht überschreiben können.
WAHR
Was ist POSIX?
POSIX (tragbare Betriebssystemschnittstelle) ist eine Reihe von Standards, die die Schnittstelle zwischen einem UNIX-ähnlichen Betriebssystem und Anwendungsprogrammen definieren.
Erklären Sie, was Semaphor ist und welche Rolle in Betriebssystemen ist.
Ein Semaphor ist ein Synchronisationsprimitive, der in Betriebssystemen und gleichzeitiger Programmierung verwendet wird, um den Zugriff auf gemeinsam genutzte Ressourcen zu steuern. Es handelt sich um einen variablen oder abstrakten Datentyp, der als Zähler oder Signalmechanismus für die Verwaltung des Zugriffs auf Ressourcen durch mehrere Prozesse oder Threads fungiert.
Was ist Cache? Was ist Puffer?
Cache: Cache wird normalerweise verwendet, wenn Prozesse lesen und auf die Festplatte schreiben, um den Prozess schneller zu gestalten, indem ähnliche Daten, die von verschiedenen Programmen verwendet werden, leicht zugänglich werden. Puffer: Reserved Place im RAM, der zum Zeitpunkt der vorübergehenden Zwecke verwendet wird.
Virtualisierung
Was ist Virtualisierung?
Virtualisierung verwendet Software, um eine Abstraktionsebene über Computerhardware zu erstellen, mit der die Hardwareelemente eines einzelnen Computers - Prozessoren, Speicher, Speicher und mehr - in mehrere virtuelle Computer unterteilt werden können, die häufig als virtuelle Maschinen (VMS) bezeichnet werden.
Was ist ein Hypervisor?
Red Hat: "Ein Hypervisor ist eine Software, die virtuelle Maschinen (VMs) erstellt und ausführt. Ein Hypervisor, manchmal als Virtual Machine Monitor (VMM) bezeichnet, isoliert das Hypervisor -Betriebssystem und die Ressourcen der virtuellen Maschinen und ermöglicht die Erstellung und Verwaltung dieser VMs. "
Lesen Sie hier mehr
Welche Arten von Hypervisoren gibt es?
Hosted Hypervisors und Bare-Metal Hypervisors.
Was sind die Vorteile und Nachteile des nackten Hypervisors gegenüber einem gehosteten Hypervisor?
Aufgrund seiner eigenen Fahrer und eines direkten Zugriffs zu Hardwarekomponenten hat ein baremetaler Hypervisor häufig bessere Leistungen sowie Stabilität und Skalierbarkeit.
Andererseits wird es wahrscheinlich eine Begrenzung in Bezug auf das Laden von Lade (alle) Treiber geben, sodass ein gehosteter Hypervisor normalerweise von einer besseren Hardwarekompatibilität profitiert.
Welche Arten von Virtualisierung gibt es?
Betriebssystem Virtualisierungsnetzwerkfunktionen Virtualisierung Desktop Virtualisierung
Ist Containerisierung eine Art von Virtualisierung?
Ja, es handelt sich um eine Virtualisierung auf Betriebssystemebene, in der der Kernel geteilt wird und mehrere isolierte Benutzer-Space-Instanzen verwenden kann.
Wie veränderte die Einführung virtueller Maschinen die Branche und die Art und Weise, wie Anwendungen eingesetzt wurden?
Durch die Einführung virtueller Maschinen konnten Unternehmen mehrere Geschäftsanwendungen auf derselben Hardware bereitstellen, während jede Anwendung auf gesicherte Weise voneinander getrennt ist, wobei jede auf ihrem eigenen separaten Betriebssystem ausgeführt wird.
Virtuelle Maschinen
Benötigen wir virtuelle Maschinen im Zeitalter der Behälter? Sind sie noch relevant?
Ja, virtuelle Maschinen sind auch im Alter der Behälter noch relevant. Während Behälter eine leichte und tragbare Alternative zu virtuellen Maschinen bieten, haben sie bestimmte Einschränkungen. Virtuelle Maschinen sind immer noch wichtig, da sie Isolation und Sicherheit anbieten, verschiedene Betriebssysteme ausführen können und für Legacy -Apps gut sind. Containerbeschränkungen zum Beispiel teilen den Host -Kernel.
Prometheus
Was ist Prometheus? Was sind einige der Hauptmerkmale von Prometheus?
Prometheus ist eine beliebte Open-Source-Systemüberwachung und Alarmentoolkit, die ursprünglich bei SoundCloud entwickelt wurde. Es wurde entwickelt, um Zeitreihendaten zu sammeln und zu speichern und die Abfragen und Analyse dieser Daten mithilfe einer leistungsstarken Abfragesprache namens PromQL zu ermöglichen. Prometheus wird häufig zur Überwachung von Cloud-nativen Anwendungen, Mikrodiensten und anderen modernen Infrastrukturen verwendet.
Einige der Hauptmerkmale von Prometheus sind:
1. Data model: Prometheus uses a flexible data model that allows users to organize and label their time-series data in a way that makes sense for their particular use case. Labels are used to identify different dimensions of the data, such as the source of the data or the environment in which it was collected.
2. Pull-based architecture: Prometheus uses a pull-based model to collect data from targets, meaning that the Prometheus server actively queries its targets for metrics data at regular intervals. This architecture is more scalable and reliable than a push-based model, which would require every target to push data to the server.
3. Time-series database: Prometheus stores all of its data in a time-series database, which allows users to perform queries over time ranges and to aggregate and analyze their data in various ways. The database is optimized for write-heavy workloads, and can handle a high volume of data with low latency.
4. Alerting: Prometheus includes a powerful alerting system that allows users to define rules based on their metrics data and to send alerts when certain conditions are met. Alerts can be sent via email, chat, or other channels, and can be customized to include specific details about the problem.
5. Visualization: Prometheus has a built-in graphing and visualization tool, called PromDash, which allows users to create custom dashboards to monitor their systems and applications. PromDash supports a variety of graph types and visualization options, and can be customized using CSS and JavaScript.
Insgesamt ist Prometheus ein leistungsstarkes und flexibles Instrument zur Überwachung und Analyse von Systemen und Anwendungen und wird in der Branche weit verbreitet für die Überwachung und Beobachtbarkeit von Cloud-nativen verwendet.
In welchen Szenarien könnte es besser sein, Prometheus nicht zu verwenden?
Aus Prometheus-Dokumentation: "Wenn Sie eine 100% ige Genauigkeit benötigen, z.
Beschreiben Sie Prometheus -Architektur und Komponenten
Die Prometheus -Architektur besteht aus vier Hauptkomponenten:
1. Prometheus Server: The Prometheus server is responsible for collecting and storing metrics data. It has a simple built-in storage layer that allows it to store time-series data in a time-ordered database.
2. Client Libraries: Prometheus provides a range of client libraries that enable applications to expose their metrics data in a format that can be ingested by the Prometheus server. These libraries are available for a range of programming languages, including Java, Python, and Go.
3. Exporters: Exporters are software components that expose existing metrics from third-party systems and make them available for ingestion by the Prometheus server. Prometheus provides exporters for a range of popular technologies, including MySQL, PostgreSQL, and Apache.
4. Alertmanager: The Alertmanager component is responsible for processing alerts generated by the Prometheus server. It can handle alerts from multiple sources and provides a range of features for deduplicating, grouping, and routing alerts to appropriate channels.
Insgesamt ist die Prometheus -Architektur sehr skalierbar und belastbar. Die Server- und Client-Bibliotheken können verteilt bereitgestellt werden, um die Überwachung in großflächigen, hochdynamischen Umgebungen zu unterstützen
Können Sie Prometheus zum Beispiel mit anderen Lösungen wie InfluxDB vergleichen?
Im Vergleich zu anderen Überwachungslösungen wie InfluxDB ist Prometheus für seine hohe Leistung und Skalierbarkeit bekannt. Es kann große Datenmengen behandeln und problemlos in andere Tools im Überwachungsökosystem integriert werden. InfluxDB hingegen ist bekannt für seine Benutzerfreundlichkeit und Einfachheit. Es verfügt über eine benutzerfreundliche Oberfläche und bietet eine benutzerfreundliche APIs für das Sammeln und Abfragen von Daten.
Eine weitere beliebte Lösung, Nagios, ist ein herkömmlicheres Überwachungssystem, das sich auf ein Push-basierter Modell zum Sammeln von Daten stützt. Nagios gibt es schon lange und ist bekannt für seine Stabilität und Zuverlässigkeit. Im Vergleich zu Prometheus fehlt Nagios jedoch einige der fortgeschritteneren Funktionen, wie z. B. mehrdimensionales Datenmodell und leistungsstarke Abfragesprache.
Insgesamt hängt die Auswahl einer Überwachungslösung von den spezifischen Anforderungen und Anforderungen des Unternehmens ab. Während Prometheus eine gute Wahl für die Überwachung und Alarmierung in großem Maßstab ist, passt InfluxDB möglicherweise besser zu kleineren Umgebungen, die eine einfache Verwendung und Einfachheit erfordern. Nagios bleibt eine solide Wahl für Organisationen, die Stabilität und Zuverlässigkeit vor fortgeschrittenen Funktionen priorisieren.
Was ist eine Warnung?
In Prometheus ist eine Warnung eine Benachrichtigung ausgelöst, wenn ein bestimmter Zustand oder eine bestimmte Schwelle erfüllt ist. Warnungen können so konfiguriert werden, dass bestimmte Metriken einen bestimmten Schwellenwert überschreiten oder wenn bestimmte Ereignisse auftreten. Sobald eine Warnung ausgelöst ist, kann es in verschiedene Kanäle wie E -Mail, Pager oder Chat übergeben werden, um relevante Teams oder Einzelpersonen zur Eradung geeigneter Maßnahmen zu benachrichtigen. Warnungen sind eine kritische Komponente eines Überwachungssystems, da Teams Probleme proaktiv erkennen und auf Probleme reagieren, bevor sie sich auf Benutzer auswirken oder Systemausfallzeiten verursachen. Was ist eine Instanz? Was ist ein Job?
In Prometheus bezieht sich eine Instanz auf ein einzelnes Ziel, das überwacht wird. Zum Beispiel ein einzelner Server oder Dienst. Ein Job ist eine Reihe von Instanzen, die dieselbe Funktion ausführen, z. B. eine Reihe von Webservern, die dieselbe Anwendung dienen. Mit Jobs können Sie eine Gruppe von Zielen gemeinsam definieren und verwalten.
Im Wesentlichen ist eine Instanz ein individuelles Ziel, von dem Prometheus Metriken sammelt, während ein Job eine Sammlung ähnlicher Fälle ist, die als Gruppe verwaltet werden können.
Welche Kernmetriken -Typen unterstützt Prometheus?
Prometheus unterstützt verschiedene Arten von Metriken, darunter: 1. Counter: A monotonically increasing value used for tracking counts of events or samples. Examples include the number of requests processed or the total number of errors encountered. 2. Gauge: A value that can go up or down, such as CPU usage or memory usage. Unlike counters, gauge values can be arbitrary, meaning they can go up and down based on changes in the system being monitored. 3. Histogram: A set of observations or events that are divided into buckets based on their value. Histograms help in analyzing the distribution of a metric, such as request latencies or response sizes. 4. Summary: A summary is similar to a histogram, but instead of buckets, it provides a set of quantiles for the observed values. Summaries are useful for monitoring the distribution of request latencies or response sizes over time.
Prometheus unterstützt auch verschiedene Funktionen und Betreiber für die Aggregation und Manipulation von Metriken wie Summe, Max, Min und Rate. Diese Funktionen machen es zu einem leistungsstarken Werkzeug zur Überwachung und Alarmierung von Systemmetriken.
Was ist ein Exporteur? Wofür wird es verwendet?
Der Exporteur dient als Brücke zwischen dem Drittanbietersystem oder der Anwendung und dem Prometheus, was es Prometheus ermöglicht, Daten aus diesem System oder Anwendung zu überwachen und zu sammeln. Der Exporteur fungiert als Server und hört einen bestimmten Netzwerkport für Anforderungen von Prometheus zu, um Metriken zu kratzen. Es sammelt Metriken aus dem Drittanbietersystem oder der Anwendung und verwandelt sie in ein Format, das von Prometheus verstanden werden kann. Der Exporteur setzt diese Metriken dann Prometheus über einen HTTP -Endpunkt aus und stellt sie zur Sammlung und Analyse zur Verfügung.
Exporteure werden üblicherweise verwendet, um verschiedene Arten von Infrastrukturkomponenten wie Datenbanken, Webservern und Speichersystemen zu überwachen. Beispielsweise stehen Exporteure zur Überwachung populärer Datenbanken wie MySQL und PostgreSQL sowie Webservern wie Apache und NGINX zur Verfügung.
Insgesamt sind Exporteure ein kritischer Bestandteil des Prometheus -Ökosystems, der die Überwachung einer Vielzahl von Systemen und Anwendungen ermöglicht und der Plattform ein hohes Maß an Flexibilität und Erweiterbarkeit bietet.
Welche Prometheus -Best Practices?
Hier sind drei von ihnen: 1. Label carefully: Careful and consistent labeling of metrics is crucial for effective querying and alerting. Labels should be clear, concise, and include all relevant information about the metric. 2. Keep metrics simple: The metrics exposed by exporters should be simple and focus on a single aspect of the system being monitored. This helps avoid confusion and ensures that the metrics are easily understandable by all members of the team. 3. Use alerting sparingly: While alerting is a powerful feature of Prometheus, it should be used sparingly and only for the most critical issues. Setting up too many alerts can lead to alert fatigue and result in important alerts being ignored. It is recommended to set up only the most important alerts and adjust the thresholds over time based on the actual frequency of alerts.
Wie bekomme ich in einem bestimmten Zeitraum totale Anfragen?
Um die Gesamtanforderungen in einem bestimmten Zeitraum mit Prometheus zu erhalten, können Sie die Funktion * sum * zusammen mit der Funktion * rate * verwenden. Hier ist eine Beispielabfrage, die Ihnen die Gesamtzahl der Anforderungen in der letzten Stunde gibt: sum(rate(http_requests_total[1h]))
In dieser Abfrage ist http_requests_total der Name der Metrik, die die Gesamtzahl der HTTP-Anforderungen verfolgt, und die Ratenfunktion berechnet den Anfragen von pro Sekunde in der letzten Stunde. Die Summenfunktion addiert dann alle Anfragen, um Ihnen die Gesamtzahl der Anfragen in der letzten Stunde zu geben.
Sie können den Zeitbereich anpassen, indem Sie die Dauer in der Ratenfunktion ändern. Wenn Sie beispielsweise die Gesamtzahl der Anforderungen am letzten Tag erhalten möchten, können Sie die Funktion in Bewertung ändern (http_requests_total [1d]) .
Was bedeutet HA in Prometheus?
HA steht für hohe Verfügbarkeit. Dies bedeutet, dass das System sehr zuverlässig und immer verfügbar ist, selbst angesichts von Fehlern oder anderen Problemen. In der Praxis beinhaltet dies normalerweise die Einrichtung mehrerer Prometheus -Instanzen und sicherzustellen, dass sie alle synchronisiert und in der Lage sind, nahtlos zusammenzuarbeiten. Dies kann durch eine Vielzahl von Techniken wie Lastausgleich, Replikation und Failovermechanismen erreicht werden. Durch die Implementierung von HA in Prometheus können Benutzer sicherstellen, dass ihre Überwachungsdaten immer verfügbar und aktuell sind, selbst angesichts von Hardware- oder Softwarefehlern, Netzwerkproblemen oder anderen Problemen, die sonst Ausfallzeiten oder Datenverlust verursachen könnten.
Wie beitreten Sie zwei Metriken?
In Prometheus können mit der Funktion * join () * zwei Metriken mit der Funktion * join () * erreicht werden. Die Funktion * join () * kombiniert zwei oder mehr Zeitreihen basierend auf ihren Etikettenwerten. Es braucht zwei obligatorische Argumente: *auf *und *Tabelle *. Das On -Argument gibt an, dass die Beschriftungen * auf * und das Argument * Tabelle * die Zeitreihen angeben. Hier ist ein Beispiel dafür, wie Sie mit der Funktion " join () zwei Metriken miteinander verbinden können:
sum_series(
join(
on(service, instance) request_count_total,
on(service, instance) error_count_total,
)
)
In diesem Beispiel kombiniert die Funktion Join () die Zeitreihe Request_Count_Total und ERROR_COUNT_TOTAL Basierend auf ihren Dienst- und Instanzetikettenwerten . Die Funktion Sum_Series () berechnet dann die Summe der resultierenden Zeitreihen
Wie schreibe ich eine Abfrage, die den Wert eines Etiketts zurückgibt?
Um eine Abfrage zu schreiben, die den Wert eines Etiketts in Prometheus zurückgibt, können Sie die Funktion * label_values * verwenden. Die Funktion * label_values * nimmt zwei Argumente ein: den Namen des Etiketts und den Namen der Metrik. Wenn Sie beispielsweise eine Metrik namens http_requests_total mit einer Etikett namens Methode haben und alle Werte der Methodenbezeichnung zurückgeben möchten, können Sie die folgende Abfrage verwenden:
label_values(http_requests_total, method)
Dadurch wird eine Liste aller Werte für die Methodenkennzeichnung in der Metrik http_requests_total zurückgegeben. Sie können diese Liste dann in weiteren Abfragen verwenden oder Ihre Daten filtern.
Wie konvertieren Sie CPU_USER_SECONDS in Prozentsatz in die CPU -Nutzung?
Um * CPU_USER_SECONDS * in den prozentualen CPU -Gebrauch umzuwandeln, müssen Sie sie durch die Gesamtzeit und die Anzahl der CPU -Kerne teilen und dann mit 100 multiplizieren. Die Formel lautet wie folgt: 100 * sum(rate(process_cpu_user_seconds_total{job="<job-name>"}[<time-period>])) by (instance) / (<time-period> * <num-cpu-cores>)
Hier, ist der Name des Jobs, den Sie abfragen möchten, ist der Zeitbereich, den Sie abfragen möchten (z. B. 5m , 1H ), und Ist die Anzahl der CPU -Kerne auf der Maschine, die Sie abfragen.
Um beispielsweise die CPU-Nutzung in den letzten 5 Minuten für einen Job namens My-Job auf einer Maschine mit 4 CPU-Kernen in Prozentsatz zu bringen, können Sie die folgende Abfrage verwenden:
100 * sum(rate(process_cpu_user_seconds_total{job="my-job"}[5m])) by (instance) / (5m * 4)
Gehen
Was sind einige Eigenschaften der Go -Programmiersprache?
- Starke und statische Tippen - Der Typ der Variablen kann im Laufe der Zeit nicht geändert werden und sie müssen bei Kompilierzeit
- -Einfachheit
mit - schneller Kompilierung
- integriert werden
- , um die unabhängige
Kompilierung - von Binärdateien
- in Einklang zu bringen - alles, was Sie benötigen, um Ihre App auszuführen wird zu einem Binärer zusammengestellt. Sehr nützlich für das Versionsverwaltung in der Laufzeit.
Go hat auch eine gute Gemeinschaft.
Was ist der Unterschied zwischen var x int = 2 und x := 2 ?
Das Ergebnis ist das gleiche, eine Variable mit dem Wert 2.
Mit var x int = 2 setzen wir den variablen Typ auf Ganzzahl ein, während wir mit x := 2 den Typ selbst herausfinden lassen.
Wahr oder falsch? In Go können wir Variablen neu anklagen und sobald wir es deklariert haben, müssen wir sie verwenden.
FALSCH. Wir können Variablen nicht neu anklären, aber ja, wir müssen deklarierte Variablen verwenden.
Welche Bibliotheken von Go haben Sie verwendet?
Dies sollte anhand Ihrer Verwendung beantwortet werden, aber einige Beispiele sind:
Was ist das Problem mit dem folgenden Codeblock? Wie repariere ich es? func main() {
var x float32 = 13.5
var y int
y = x
}
Der folgende Codeblock versucht, die Ganzzahl 101 in eine Zeichenfolge umzuwandeln, aber stattdessen erhalten wir "e". Warum ist das so? Wie repariere ich es? package main
import "fmt"
func main () {
var x int = 101
var y string
y = string ( x )
fmt . Println ( y )
}
Es sieht aus, wie der Unicode -Wert auf 101 eingestellt ist, und verwendet ihn, um die Ganzzahl in eine Zeichenfolge zu konvertieren. Wenn Sie "101" erhalten möchten, sollten Sie das Paket "StrConv" verwenden und y = string(x) durch y = strconv.Itoa(x) ersetzen.
Was ist los mit dem folgenden Code ?: package main
func main() {
var x = 2
var y = 3
const someConst = x + y
}
Konstanten in Go können nur mit konstanten Ausdrücken deklariert werden. Aber x , y und ihre Summe sind variabel.
const initializer x + y is not a constant
Was wird die Ausgabe des folgenden Codeblocks sein ?: package main
import "fmt"
const (
x = iota
y = iota
)
const z = iota
func main () {
fmt . Printf ( "%v n " , x )
fmt . Printf ( "%v n " , y )
fmt . Printf ( "%v n " , z )
}
Die IOTA -Kennung von Go wird in Const -Deklarationen verwendet, um die Definitionen von Inkrementierungsnummern zu vereinfachen. Da es in Ausdrücken verwendet werden kann, bietet es eine Allgemeinheit, die über die von einfachen Aufzählungen hinausgeht.
x und y in der ersten IOTA -Gruppe, z in der zweiten.
IOTA -Seite in Go Wiki
Was wird in Go verwendet?
Es vermeidet es, alle Variablen für die Return -Werte zu deklarieren. Es wird die leere Kennung genannt.
antworte in so
Was wird die Ausgabe des folgenden Codeblocks sein ?: package main
import "fmt"
const (
_ = iota + 3
x
)
func main () {
fmt . Printf ( "%v n " , x )
}
Da das erste IOTA mit dem Wert 3 ( + 3 ) deklariert wird, hat der nächste den Wert 4
Was wird die Ausgabe des folgenden Codeblocks sein ?: package main
import (
"fmt"
"sync"
"time"
)
func main () {
var wg sync. WaitGroup
wg . Add ( 1 )
go func () {
time . Sleep ( time . Second * 2 )
fmt . Println ( "1" )
wg . Done ()
}()
go func () {
fmt . Println ( "2" )
}()
wg . Wait ()
fmt . Println ( "3" )
}
Ausgabe: 2 1 3
Aritcle über Synchronisation/Karteigruppe
Golang -Paket Synchronisierung
Was wird die Ausgabe des folgenden Codeblocks sein ?: package main
import (
"fmt"
)
func mod1 ( a [] int ) {
for i := range a {
a [ i ] = 5
}
fmt . Println ( "1:" , a )
}
func mod2 ( a [] int ) {
a = append ( a , 125 ) // !
for i := range a {
a [ i ] = 5
}
fmt . Println ( "2:" , a )
}
func main () {
s1 := [] int { 1 , 2 , 3 , 4 }
mod1 ( s1 )
fmt . Println ( "1:" , s1 )
s2 := [] int { 1 , 2 , 3 , 4 }
mod2 ( s2 )
fmt . Println ( "2:" , s2 )
}
Ausgabe:
1 [5 5 5 5]
1 [5 5 5 5]
2 [5 5 5 5 5]
2 [1 2 3 4]
In mod1 A ist Link und wenn wir a[i] verwenden, ändern wir s1 -Wert auf. Aber in mod2 erstellt append neue Slice, und wir ändern nur a Wert, nicht s2 .
Aritcle über Arrays, Blog -Beitrag über append
Was wird die Ausgabe des folgenden Codeblocks sein ?: package main
import (
"container/heap"
"fmt"
)
// An IntHeap is a min-heap of ints.
type IntHeap [] int
func ( h IntHeap ) Len () int { return len ( h ) }
func ( h IntHeap ) Less ( i , j int ) bool { return h [ i ] < h [ j ] }
func ( h IntHeap ) Swap ( i , j int ) { h [ i ], h [ j ] = h [ j ], h [ i ] }
func ( h * IntHeap ) Push ( x interface {}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
* h = append ( * h , x .( int ))
}
func ( h * IntHeap ) Pop () interface {} {
old := * h
n := len ( old )
x := old [ n - 1 ]
* h = old [ 0 : n - 1 ]
return x
}
func main () {
h := & IntHeap { 4 , 8 , 3 , 6 }
heap . Init ( h )
heap . Push ( h , 7 )
fmt . Println (( * h )[ 0 ])
}
Ausgabe: 3
Golang Container/Heap -Paket
Mongo
Was sind die Vorteile von MongoDB? Oder mit anderen Worten, warum die Auswahl von MongoDB und nicht in einer anderen Implementierung von NoSQL?
MongoDB -Vorteile sind wie folgt:
- Schemaless
- Leicht zu skalieren
- Kein komplexer Verbindungen
- Die Struktur eines einzelnen Objekts ist klar
Was ist der Unterschied zwischen SQL und NoSQL?
Der Hauptunterschied besteht darin, dass SQL -Datenbanken strukturiert sind (Daten werden in Form von Tabellen mit Zeilen und Spalten gespeichert - wie eine Excel -Tabellenkalkulelle), während NoSQL unstrukturiert ist und die Datenspeicherung je nach der Einrichtung des NoSQL -DB variieren kann. wie Schlüsselwertpaar, dokumentorientiertes usw.
In welchen Szenarien würden Sie es vorziehen, NoSQL/Mongo über SQL zu verwenden?
Heterogene Daten, die sich häufig ändern- Datenkonsistenz und Integrität haben keine oberste Priorität
- Am besten, wenn die Datenbank schnell skalieren muss
Was ist ein Dokument? Was ist eine Sammlung?
Ein Dokument ist ein Datensatz in MongoDB, das im BSON -Format (binary JSON) gespeichert ist und die Grundeinheit der Daten in MongoDB ist.- Eine Sammlung ist eine Gruppe verwandter Dokumente, die in einer einzigen Datenbank in MongoDB gespeichert sind.
Was ist ein Aggregator?
- Ein Aggregator ist ein Framework in MongoDB, das Operationen in einer Datenmenge ausführt, um ein einzelnes berechnete Ergebnis zurückzugeben.
Was ist besser? Eingebettete Dokumente oder verwiesen?
- Es gibt keine endgültige Antwort darauf, welche besser ist, es hängt von den spezifischen Anwendungsfall und den Anforderungen ab. Einige Erklärungen: Eingebettete Dokumente liefern Atomaktualisierungen, während verwiesene Dokumente eine bessere Normalisierung ermöglichen.
Haben Sie Datenabrufoptimierungen in Mongo durchgeführt? Wenn nicht, können Sie darüber nachdenken, wie Sie einen langsamen Datenabruf optimieren können?
- Einige Möglichkeiten zur Optimierung des Datenabrufs in MongoDB sind: Indexierung, ordnungsgemäßes Schema -Design, Abfrageoptimierung und Datenbanklastausgleich.
Abfragen
Erklären Sie diese Abfrage: db.books.find({"name": /abc/})
Erklären Sie diese Abfrage: db.books.find().sort({x:1})
Was ist der Unterschied zwischen find () und find_one ()?
find() gibt alle Dokumente zurück, die den Abfragebedingungen entsprechen.- find_one () gibt nur ein Dokument zurück, das den Abfragebedingungen entspricht (oder Null, wenn keine Übereinstimmung gefunden wird).
Wie können Sie Daten von Mongo DB exportieren?
Mongoexport- Programmiersprachen
SQL
SQL Übungen
| Name | Thema | Objektive & Anweisungen | Lösung | Kommentare |
|---|
| Funktionen gegen Vergleiche | Abfragen Verbesserungen | Übung | Lösung | |
SQL Self Assessment
Was ist SQL?
SQL (Structured Query Language) ist eine Standardsprache für relationale Datenbanken (wie MySQL, Mariadb, ...).
Es wird zum Lesen, Aktualisieren, Entfernen und Erstellen von Daten in einer relationalen Datenbank verwendet.
Wie unterscheidet sich SQL von NoSQL?
Der Hauptunterschied besteht darin, dass SQL -Datenbanken strukturiert sind (Daten werden in Form von Tabellen mit Zeilen und Spalten gespeichert - wie eine Excel -Tabellenkalkulelle), während NoSQL unstrukturiert ist und die Datenspeicherung je nach der Einrichtung des NoSQL -DB variieren kann. wie Schlüsselwertpaar, dokumentorientiertes usw.
Wann ist es am besten, SQL zu verwenden? NoSQL?
SQL - am besten verwendet, wenn die Datenintegrität von entscheidender Bedeutung ist. SQL wird aufgrund seiner Säure -Compliance in der Regel mit vielen Unternehmen und Bereichen im Finanzbereich implementiert.
NoSQL - Großartig, wenn Sie die Dinge schnell skalieren müssen. NoSQL wurde mit Blick auf Webanwendungen entwickelt. Daher funktioniert es hervorragend, wenn Sie dieselben Informationen schnell auf mehrere Server verbreiten müssen
Da NoSQL nicht an die strenge Tabelle mit Spalten und Zeilenstruktur hält, die relationale Datenbanken benötigen, können Sie verschiedene Datentypen zusammen speichern.
Praktische SQL - Grundlagen
Für diese Fragen verwenden wir die unten gezeigten Kunden und Bestellentabellen:
Kunden
| Customer_id | Customer_name | Items_in_cart | Cash_Spent_to_date |
|---|
| 100204 | John Smith | 0 | 20.00 |
| 100205 | Jane Smith | 3 | 40.00 |
| 100206 | Bobby Frank | 1 | 100.20 |
BESTELLUNGEN
| Customer_id | Order_id | Artikel | Preis | DATE_Sold |
|---|
| 100206 | A123 | Gummi Ducky | 2.20 | 2019-09-18 |
| 100206 | A123 | Schaumbad | 8.00 | 2019-09-18 |
| 100206 | Q987 | 80-Pack TP | 90.00 | 2019-09-20 |
| 100205 | Z001 | Katzenfutter - Thunfischfisch | 10.00 | 2019-08-05 |
| 100205 | Z001 | Katzenfutter - Huhn | 10.00 | 2019-08-05 |
| 100205 | Z001 | Katzenfutter - Rindfleisch | 10.00 | 2019-08-05 |
| 100205 | Z001 | Katzenfutter - Kitty Quesadilla | 10.00 | 2019-08-05 |
| 100204 | X202 | Kaffee | 20.00 | 2019-04-29 |
Wie würde ich alle Felder aus dieser Tabelle auswählen?
Wählen *
Von Kunden;
Wie viele Gegenstände sind in Johns Warenkorb?
Wählen Sie items_in_cart
Von Kunden
Wo customer_name = "John Smith";
Was ist die Summe aller von allen Kunden ausgegebenen Bargeld?
Wählen Sie SUM (Cash_Spent_to_date) als sum_cash
Von Kunden;
Wie viele Leute haben Gegenstände in ihrem Karren?
Wählen Sie Graf (1) als number_of_people_w_items
Von Kunden
wo items_in_cart> 0;
Wie würden Sie der Kundentabelle zur Bestellentabelle beitreten?
Sie würden sich ihnen auf dem einzigartigen Schlüssel anschließen. In diesem Fall ist der eindeutige Schlüssel Customer_ID sowohl in der Tabelle Kunden als auch in der Bestellung
Wie würden Sie zeigen, welcher Kunden welche Artikel bestellt hat?
Wählen Sie C.Customer_Name, O.Item
Von Kunden c
Links Join -Bestellungen o
Auf c.Customer_id = o.customer_id;
Wie würden Sie zeigen, wer Katzenfutter bestellt hat, und welcher Gesamtbetrag an Geld ausgegeben hat?
mit cat_food als (
Wählen Sie Customer_id, Summe (Preis) als Total_price aus
Aus Bestellungen
Wo Gegenstand "%Cat Food%"
Gruppe von Customer_id
)
Wählen Sie Customer_Name, Total_price
Von Kunden c
Innere Join Cat_food f
Auf c.customer_id = f.customer_id
wo c.customer_id in (Wählen Sie Customer_id von Cat_food);
Obwohl dies eine einfache Aussage war, scheint die "mit" Klausel wirklich, wenn eine komplexe Abfrage auf einer Tabelle ausgeführt werden muss, bevor sie zu einer anderen verbindet. Mit Aussagen sind schön, da Sie beim Ausführen Ihrer Abfrage eine Pseudo -Temperatur erstellen, anstatt eine ganz neue Tabelle zu erstellen.
Die Summe aller Einkäufe von Katzenfutter war nicht ohne weiteres verfügbar. Daher verwendeten wir eine mit Anweisung, um die Pseudo -Tabelle zu erstellen, um die Summe der von jedem Kunden ausgegebenen Preise abzurufen, und dann normal an der Tabelle teilnehmen.
Welche der folgenden Fragen würden Sie verwenden? SELECT count(*) SELECT count(*)
FROM shawarma_purchases FROM shawarma_purchases
WHERE vs. WHERE
YEAR(purchased_at) == '2017' purchased_at >= '2017-01-01' AND
purchased_at <= '2017-31-12'
SELECT count(*) FROM shawarma_purchases WHERE purchased_at >= '2017-01-01' AND purchased_at <= '2017-31-12'
Wenn Sie eine Funktion ( YEAR(purchased_at) ) verwenden, muss sie die gesamte Datenbank scannen, anstatt in ihrem natürlichen Zustand die Verwendung von Indizes und im Grunde die Spalte zu verwenden.
OpenStack
Mit welchen Komponenten/Projekten von OpenStack kennen Sie?
Können Sie mir sagen, wofür jedes der folgenden Dienste/Projekte verantwortlich ist ?:- Nova
- Neutron
- Asche
- Blick
- Schlussstein
Nova - Virtuelle Instanzen verwalten- Neutron - Verwalten Sie das Netzwerk, indem Sie Netzwerk als Service (NAAS) bereitstellen
- Aschenpinder - Blockspeicher
- Blick - Verwalten Sie Bilder für virtuelle Maschinen und Container (Suche, Get und Registrieren)
- Keystone - Authentifizierungsdienst in der Cloud
Identifizieren Sie den Service/Projekt, der für jede der folgenden folgenden verwendet wird:- Kopieren oder Schnappschussinstanzen
- GUI zum Anzeigen und Ändern von Ressourcen
- Blockspeicher
- Virtuelle Instanzen verwalten
Blick - Bilder Service. Wird auch zum Kopieren oder Snapshot -Instanzen verwendet- Horizon - GUI zum Betrachten und Ändern von Ressourcen
- Aschenpinder - Blockspeicher
- Nova - Virtuelle Instanzen verwalten
Was ist ein Mieter/ein Projekt?
Bestimmen Sie wahr oder falsch:- OpenStack ist kostenlos zu bedienen
- Der für die Vernetzung verantwortliche Dienst ist ein Blick
- Der Zweck von Mieter/Projekt besteht darin, Ressourcen zwischen verschiedenen Projekten und Benutzern von OpenStack zu teilen
Beschreiben Sie ausführlich, wie Sie eine Instanz mit einer schwebenden IP aufbringen
Sie erhalten einen Anruf von einem Kunden, der sagt: "Ich kann meine Instanz pingen, kann es aber nicht verbinden (SSH)." Was könnte das Problem sein?
Welche Arten von Netzwerken OpenStack -Unterstützung?
Wie debuggen Sie OpenStack -Speicherprobleme? (Tools, Protokolle, ...)
Wie debugge du OpenStack -Computerprobleme? (Tools, Protokolle, ...)
OpenStack -Bereitstellung & Tripleo
Haben Sie in der Vergangenheit OpenStack bereitgestellt? Wenn ja, können Sie beschreiben, wie Sie es gemacht haben?
Kennen Sie Tripleo? Wie unterscheidet es sich von DevStack oder Packstack?
Sie können hier über Tripleo lesen
OpenStack Compute
Können Sie Nova im Detail beschreiben?
Wird verwendet, um virtuelle Instanzen bereitzustellen und zu verwalten- Es unterstützt Multi-Messen in verschiedenen Ebenen-Protokollierung, Endbenutzerkontrolle, Prüfung usw.
- Hoch skalierbar
- Die Authentifizierung kann mit internem System oder LDAP durchgeführt werden
- Unterstützt mehrere Arten von Blockspeicher
- Versucht Hardware und Hypervisor -Agnostice zu sein
Was wissen Sie über NOVA -Architektur und Komponenten?
Nova -API - Der Server, der Metadaten bedient und APIs berechnet- Die verschiedenen NOVA -Komponenten kommunizieren mit einer Warteschlange (normalerweise Rabbitmq) und einer Datenbank
- Eine Anfrage zur Erstellung einer Instanz wird von Nova-Scheduler überprüft, die feststellt, wo die Instanz erstellt wird und ausgeführt wird
- Nova-Compute ist die Komponente, die für die Kommunikation mit dem Hypervisor für die Erstellung der Instanz und die Verwaltung seines Lebenszyklus verantwortlich ist
OpenStack Networking (Neutron)
Erklären Sie Neutron im Detail
Eine der Kernkomponenten von OpenStack und einem eigenständigen Projekt- Neutron konzentriert sich auf die Bereitstellung von Networking als Service
- Mit Neutron können Benutzer Netzwerke in der Cloud einrichten und verschiedene Netzwerkdienste konfigurieren und verwalten
- Neutron interagiert mit:
Keystone - API -Anrufe autorisieren
- Nova - Nova kommuniziert mit Neutron, um die NICs in ein Netzwerk anzuschließen
- Horizon - Unterstützt Networking -Unternehmen im Dashboard und bietet auch Topologieansicht, die Netzwerkdetails enthält
Erläutern Sie jede der folgenden Komponenten:- Neutronen-DHCP-Agent
- Neutron-L3-Agent
- Neutronenmessung
- Neutron-*-Agtent
- Neutronenserver
Neutron-L3-Agent-L3/NAT-Weiterleitung (bietet beispielsweise externe Netzwerkzugriff für VMs).- Neutronen-DHCP-Agent-DHCP-Dienste
- Neutronenmessung-L3-Verkehrsmessung
- Neutron-*-AGTENT-Verwaltet die lokale Vswitch-Konfiguration für jeden Computer (basierend auf dem ausgewählten Plugin)
- Neutronenserver - Enthält die Netzwerk -API und übergibt bei Bedarf an andere Plugins an andere Plugins
Erklären Sie diese Netzwerkarten:- Verwaltungsnetzwerk
- Gastnetzwerk
- API -Netzwerk
- Externes Netzwerk
Verwaltungsnetzwerk - Wird für die interne Kommunikation zwischen OpenStack -Komponenten verwendet. Jede IP -Adresse in diesem Netzwerk ist nur innerhalb des Datacetner zugegriffen- Gastnetzwerk - Wird für die Kommunikation zwischen Instanzen/VMs verwendet
- API -Netzwerk - Wird für Dienste API -Kommunikation verwendet. Jede IP -Adresse in diesem Netzwerk ist öffentlich zugänglich
- Externes Netzwerk - Wird für die öffentliche Kommunikation verwendet. Jede IP -Adresse in diesem Netzwerk ist von anderen im Internet zugegriffen
In welcher Reihenfolge sollten Sie die folgenden Einheiten entfernen:- Netzwerk
- Hafen
- Router
- Subnetz
- Port
- -Subnetz
- -Router
- -Netzwerk
Dafür gibt es viele Gründe. Zum Beispiel können Sie den Router nicht entfernen, wenn aktive Ports zugewiesen sind.
Was ist ein Anbieternetzwerk?
Welche Komponenten und Dienste gibt es für L2 und L3?
Was ist das ML2-Plug-In? Erklären Sie seine Architektur
Was ist der L2 -Agent? Wie funktioniert es und wofür ist es verantwortlich?
Was ist der L3 -Agent? Wie funktioniert es und wofür ist es verantwortlich?
Erklären Sie, wofür der Metadatenagent verantwortlich ist
What networking entities Neutron supports?
How do you debug OpenStack networking issues? (tools, logs, ...)
OpenStack - Glance
Explain Glance in detail
Glance is the OpenStack image service- It handles requests related to instances disks and images
- Glance also used for creating snapshots for quick instances backups
- Users can use Glance to create new images or upload existing ones
Describe Glance architecture
glance-api - responsible for handling image API calls such as retrieval and storage. It consists of two APIs: 1. registry-api - responsible for internal requests 2. user API - can be accessed publicly- glance-registry - responsible for handling image metadata requests (eg size, type, etc). This component is private which means it's not available publicly
- metadata definition service - API for custom metadata
- database - for storing images metadata
- image repository - for storing images. This can be a filesystem, swift object storage, HTTP, etc.
OpenStack - Swift
Explain Swift in detail
Swift is Object Store service and is an highly available, distributed and consistent store designed for storing a lot of data- Swift is distributing data across multiple servers while writing it to multiple disks
- One can choose to add additional servers to scale the cluster. All while swift maintaining integrity of the information and data replications.
Can users store by default an object of 100GB in size?
Not by default. Object Storage API limits the maximum to 5GB per object but it can be adjusted.
Explain the following in regards to Swift:
Container - Defines a namespace for objects.- Account - Defines a namespace for containers
- Object - Data content (eg image, document, ...)
Wahr oder falsch? there can be two objects with the same name in the same container but not in two different containers
FALSCH. Two objects can have the same name if they are in different containers.
OpenStack - Cinder
Explain Cinder in detail
Cinder is OpenStack Block Storage service- It basically provides used with storage resources they can consume with other services such as Nova
- One of the most used implementations of storage supported by Cinder is LVM
- From user perspective this is transparent which means the user doesn't know where, behind the scenes, the storage is located or what type of storage is used
Describe Cinder's components
cinder-api - receives API requests- cinder-volume - manages attached block devices
- cinder-scheduler - responsible for storing volumes
OpenStack - Keystone
Can you describe the following concepts in regards to Keystone?- Rolle
- Tenant/Project
- Service
- Endpoint
- Token
Role - A list of rights and privileges determining what a user or a project can perform- Tenant/Project - Logical representation of a group of resources isolated from other groups of resources. It can be an account, organization, ...
- Service - An endpoint which the user can use for accessing different resources
- Endpoint - a network address which can be used to access a certain OpenStack service
- Token - Used for access resources while describing which resources can be accessed by using a scope
What are the properties of a service? In other words, how a service is identified?
Using:
Name- ID-Nummer
- Typ
- Beschreibung
Explain the following: - PublicURL - InternalURL - AdminURL
PublicURL - Publicly accessible through public internet- InternalURL - Used for communication between services
- AdminURL - Used for administrative management
What is a service catalog?
A list of services and their endpoints
OpenStack Advanced - Services
Describe each of the following services- Schnell
- Sahara
- Ironisch
- Trove
- Aodh
- Ceilometer
Swift - highly available, distributed, eventually consistent object/blob store- Sahara - Manage Hadoop Clusters
- Ironic - Bare Metal Provisioning
- Trove - Database as a service that runs on OpenStack
- Aodh - Alarms Service
- Ceilometer - Track and monitor usage
Identify the service/project used for each of the following:- Database as a service which runs on OpenStack
- Bare Metal Provisioning
- Track and monitor usage
- Alarms Service
- Manage Hadoop Clusters
- highly available, distributed, eventually consistent object/blob store
Database as a service which runs on OpenStack - Trove- Bare Metal Provisioning - Ironic
- Track and monitor usage - Ceilometer
- Alarms Service - Aodh
- Manage Hadoop Clusters
- Manage Hadoop Clusters - Sahara
- highly available, distributed, eventually consistent object/blob store - Swift
OpenStack Advanced - Keystone
Can you describe Keystone service in detail?
You can't have OpenStack deployed without Keystone- It Provides identity, policy and token services
- The authentication provided is for both users and services
- The authorization supported is token-based and user-based.
- There is a policy defined based on RBAC stored in a JSON file and each line in that file defines the level of access to apply
Describe Keystone architecture
There is a service API and admin API through which Keystone gets requests- Keystone has four backends:
- Token Backend - Temporary Tokens for users and services
- Policy Backend - Rules management and authorization
- Identity Backend - users and groups (either standalone DB, LDAP, ...)
- Catalog Backend - Endpoints
- It has pluggable environment where you can integrate with:
- KVS (Key Value Store)
- SQL
- PAM
- Im Speicher gespeichert
Describe the Keystone authentication process
Keystone gets a call/request and checks whether it's from an authorized user, using username, password and authURL- Once confirmed, Keystone provides a token.
- A token contains a list of user's projects so there is no to authenticate every time and a token can submitted instead
OpenStack Advanced - Compute (Nova)
What each of the following does?:- nova-api
- nova-compuate
- nova-conductor
- nova-cert
- nova-consoleauth
- nova-scheduler
nova-api - responsible for managing requests/calls- nova-compute - responsible for managing instance lifecycle
- nova-conductor - Mediates between nova-compute and the database so nova-compute doesn't access it directly
What types of Nova proxies are you familiar with?
Nova-novncproxy - Access through VNC connections- Nova-spicehtml5proxy - Access through SPICE
- Nova-xvpvncproxy - Access through a VNC connection
OpenStack Advanced - Networking (Neutron)
Explain BGP dynamic routing
What is the role of network namespaces in OpenStack?
OpenStack Advanced - Horizon
Can you describe Horizon in detail?
Django-based project focusing on providing an OpenStack dashboard and the ability to create additional customized dashboards- You can use it to access the different OpenStack services resources - instances, images, networks, ...
- By accessing the dashboard, users can use it to list, create, remove and modify the different resources
- It's also highly customizable and you can modify or add to it based on your needs
What can you tell about Horizon architecture?
API is backward compatible- There are three type of dashboards: user, system and settings
- It provides core support for all OpenStack core projects such as Neutron, Nova, etc. (out of the box, no need to install extra packages or plugins)
- Anyone can extend the dashboards and add new components
- Horizon provides templates and core classes from which one can build its own dashboard
Marionette
What is Puppet? How does it works?
- Puppet is a configuration management tool ensuring that all systems are configured to a desired and predictable state.
Explain Puppet architecture
- Puppet has a primary-secondary node architecture. The clients are distributed across the network and communicate with the primary-secondary environment where Puppet modules are present. The client agent sends a certificate with its ID to the server; the server then signs that certificate and sends it back to the client. This authentication allows for secure and verifiable communication between the client and the master.
Can you compare Puppet to other configuration management tools? Why did you chose to use Puppet?
- Puppet is often compared to other configuration management tools like Chef, Ansible, SaltStack, and cfengine. The choice to use Puppet often depends on an organization's needs, such as ease of use, scalability, and community support.
Explain the following:
Modules - are a collection of manifests, templates, and files- Manifests - are the actual codes for configuring the clients
- Node - allows you to assign specific configurations to specific nodes
Explain Facter
- Facter is a standalone tool in Puppet that collects information about a system and its configuration, such as the operating system, IP addresses, memory, and network interfaces. This information can be used in Puppet manifests to make decisions about how resources should be managed, and to customize the behavior of Puppet based on the characteristics of the system. Facter is integrated into Puppet, and its facts can be used within Puppet manifests to make decisions about resource management.
What is MCollective?
- MCollective is a middleware system that integrates with Puppet to provide orchestration, remote execution, and parallel job execution capabilities.
Do you have experience with writing modules? Which module have you created and for what?
Explain what is Hiera
- Hiera is a hierarchical data store in Puppet that is used to separate data from code, allowing data to be more easily separated, managed, and reused.
Elastisch
What is the Elastic Stack?
The Elastic Stack consists of:
- Elasticsearch
- Kibana
- Logstash
- Schläge
- Elastic Hadoop
- APM Server
Elasticsearch, Logstash and Kibana are also known as the ELK stack.
Explain what is Elasticsearch
From the official docs:
"Elasticsearch is a distributed document store. Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents"
What is Logstash?
From the blog:
"Logstash is a powerful, flexible pipeline that collects, enriches and transports data. It works as an extract, transform & load (ETL) tool for collecting log messages."
Explain what beats are
Beats are lightweight data shippers. These data shippers installed on the client where the data resides. Examples of beats: Filebeat, Metricbeat, Auditbeat. There are much more.
What is Kibana?
From the official docs:
"Kibana is an open source analytics and visualization platform designed to work with Elasticsearch. You use Kibana to search, view, and interact with data stored in Elasticsearch indices. You can easily perform advanced data analysis and visualize your data in a variety of charts, tables, and maps."
Describe what happens from the moment an app logged some information until it's displayed to the user in a dashboard when the Elastic stack is used
The process may vary based on the chosen architecture and the processing you may want to apply to the logs. One possible workflow is:
The data logged by the application is picked by filebeat and sent to logstash- Logstash process the log based on the defined filters. Once done, the output is sent to Elasticsearch
- Elasticsearch stores the document it got and the document is indexed for quick future access
- The user creates visualizations in Kibana which based on the indexed data
- The user creates a dashboard which composed out of the visualization created in the previous step
Elasticsearch
What is a data node?
This is where data is stored and also where different processing takes place (eg when you search for a data).
What is a master node?
Part of a master node responsibilities:
- Track the status of all the nodes in the cluster
- Verify replicas are working and the data is available from every data node.
- No hot nodes (no data node that works much harder than other nodes)
While there can be multiple master nodes in reality only of them is the elected master node.
What is an ingest node?
A node which responsible for processing the data according to ingest pipeline. In case you don't need to use logstash then this node can receive data from beats and process it, similarly to how it can be processed in Logstash.
What is Coordinating only node?
From the official docs:
Coordinating only nodes can benefit large clusters by offloading the coordinating node role from data and master-eligible nodes. They join the cluster and receive the full cluster state, like every other node, and they use the cluster state to route requests directly to the appropriate place(s).
How data is stored in Elasticsearch?
Data is stored in an index- The index is spread across the cluster using shards
What is an Index?
Index in Elasticsearch is in most cases compared to a whole database from the SQL/NoSQL world.
You can choose to have one index to hold all the data of your app or have multiple indices where each index holds different type of your app (eg index for each service your app is running).
The official docs also offer a great explanation (in general, it's really good documentation, as every project should have):
"An index can be thought of as an optimized collection of documents and each document is a collection of fields, which are the key-value pairs that contain your data"
Explain Shards
An index is split into shards and documents are hashed to a particular shard. Each shard may be on a different node in a cluster and each one of the shards is a self contained index.
This allows Elasticsearch to scale to an entire cluster of servers.
What is an Inverted Index?
From the official docs:
"An inverted index lists every unique word that appears in any document and identifies all of the documents each word occurs in."
What is a Document?
Continuing with the comparison to SQL/NoSQL a Document in Elasticsearch is a row in table in the case of SQL or a document in a collection in the case of NoSQL. As in NoSQL a document is a JSON object which holds data on a unit in your app. What is this unit depends on the your app. If your app related to book then each document describes a book. If you are app is about shirts then each document is a shirt.
You check the health of your elasticsearch cluster and it's red. Was bedeutet es? What can cause the status to be yellow instead of green?
Red means some data is unavailable in your cluster. Some shards of your indices are unassigned. There are some other states for the cluster. Yellow means that you have unassigned shards in the cluster. You can be in this state if you have single node and your indices have replicas. Green means that all shards in the cluster are assigned to nodes and your cluster is healthy.
Wahr oder falsch? Elasticsearch indexes all data in every field and each indexed field has the same data structure for unified and quick query ability
FALSCH. From the official docs:
"Each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees."
What reserved fields a document has?
Explain Mapping
What are the advantages of defining your own mapping? (or: when would you use your own mapping?)
You can optimize fields for partial matching- You can define custom formats of known fields (eg date)
- You can perform language-specific analysis
Explain Replicas
In a network/cloud environment where failures can be expected any time, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index's shards into what are called replica shards, or replicas for short.
Can you explain Term Frequency & Document Frequency?
Term Frequency is how often a term appears in a given document and Document Frequency is how often a term appears in all documents. They both are used for determining the relevance of a term by calculating Term Frequency / Document Frequency.
You check "Current Phase" under "Index lifecycle management" and you see it's set to "hot". Was bedeutet es?
"The index is actively being written to". More about the phases here
What this command does? curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'{ "name": "John Doe" }'
It creates customer index if it doesn't exists and adds a new document with the field name which is set to "John Dow". Also, if it's the first document it will get the ID 1.
What will happen if you run the previous command twice? What about running it 100 times?
If name value was different then it would update "name" to the new value- In any case, it bumps version field by one
What is the Bulk API? Wofür würden Sie es verwenden?
Bulk API is used when you need to index multiple documents. For high number of documents it would be significantly faster to use rather than individual requests since there are less network roundtrips.
Query DSL
Explain Elasticsearch query syntax (Booleans, Fields, Ranges)
Explain what is Relevance Score
Explain Query Context and Filter Context
From the official docs:
"In the query context, a query clause answers the question “How well does this document match this query clause?” Besides deciding whether or not the document matches, the query clause also calculates a relevance score in the _score meta-field."
"In a filter context, a query clause answers the question “Does this document match this query clause?” The answer is a simple Yes or No — no scores are calculated. Filter context is mostly used for filtering structured data"
Describe how would an architecture of production environment with large amounts of data would be different from a small-scale environment
There are several possible answers for this question. One of them is as follows:
A small-scale architecture of elastic will consist of the elastic stack as it is. This means we will have beats, logstash, elastcsearch and kibana.
A production environment with large amounts of data can include some kind of buffering component (eg Reddis or RabbitMQ) and also security component such as Nginx.
Logstash
What are Logstash plugins? What plugins types are there?
Input Plugins - how to collect data from different sources- Filter Plugins - processing data
- Output Plugins - push data to different outputs/services/platforms
What is grok?
A logstash plugin which modifies information in one format and immerse it in another.
How grok works?
What grok patterns are you familiar with?
What is `_grokparsefailure?`
How do you test or debug grok patterns?
What are Logstash Codecs? What codecs are there?
Kibana
What can you find under "Discover" in Kibana?
The raw data as it is stored in the index. You can search and filter it.
You see in Kibana, after clicking on Discover, "561 hits". Was bedeutet es?
Total number of documents matching the search results. If not query used then simply the total number of documents.
What can you find under "Visualize"?
"Visualize" is where you can create visual representations for your data (pie charts, graphs, ...)
What visualization types are supported/included in Kibana?
What visualization type would you use for statistical outliers
Describe in detail how do you create a dashboard in Kibana
Filebeat
What is Filebeat?
Filebeat is used to monitor the logging directories inside of VMs or mounted as a sidecar if exporting logs from containers, and then forward these logs onward for further processing, usually to logstash.
If one is using ELK, is it a must to also use filebeat? In what scenarios it's useful to use filebeat?
Filebeat is a typical component of the ELK stack, since it was developed by Elastic to work with the other products (Logstash and Kibana). It's possible to send logs directly to logstash, though this often requires coding changes for the application. Particularly for legacy applications with little test coverage, it might be a better option to use filebeat, since you don't need to make any changes to the application code.
What is a harvester?
Read here
Wahr oder falsch? a single harvester harvest multiple files, according to the limits set in filebeat.yml
FALSCH. One harvester harvests one file.
What are filebeat modules?
These are pre-configured modules for specific types of logging locations (eg, Traefik, Fargate, HAProxy) to make it easy to configure forwarding logs using filebeat. They have different configurations based on where you're collecting logs from.
Elastischer Stapel
How do you secure an Elastic Stack?
You can generate certificates with the provided elastic utils and change configuration to enable security using certificates model.
Verteilt
Explain Distributed Computing (or Distributed System)
According to Martin Kleppmann:
"Many processes running on many machines...only message-passing via an unreliable network with variable delays, and the system may suffer from partial failures, unreliable clocks, and process pauses."
Another definition: "Systems that are physically separated, but logically connected"
What can cause a system to fail?
Netzwerk- CPU
- Erinnerung
- Scheibe
Do you know what is "CAP theorem"? (aka as Brewer's theorem)
According to the CAP theorem, it's not possible for a distributed data store to provide more than two of the following at the same time:
Availability: Every request receives a response (it doesn't has to be the most recent data)- Consistency: Every request receives a response with the latest/most recent data
- Partition tolerance: Even if some the data is lost/dropped, the system keeps running
What are the problems with the following design? How to improve it?
1. The transition can take time. In other words, noticeable downtime. 2. Standby server is a waste of resources - if first application server is running then the standby does nothing What are the problems with the following design? How to improve it?
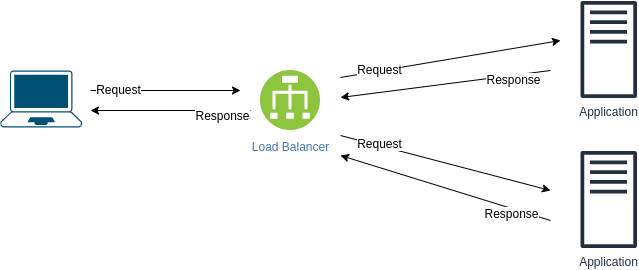
Issues: If load balancer dies , we lose the ability to communicate with the application. Ways to improve:
Add another load balancer- Use DNS A record for both load balancers
- Use message queue
What is "Shared-Nothing" architecture?
It's an architecture in which data is and retrieved from a single, non-shared, source usually exclusively connected to one node as opposed to architectures where the request can get to one of many nodes and the data will be retrieved from one shared location (storage , Erinnerung, ...).
Explain the Sidecar Pattern (Or sidecar proxy)
Sonstiges
| Name | Thema | Objective & Instructions | Lösung | Kommentare |
|---|
| Highly Available "Hello World" | Übung | Lösung | | |
What happens when you type in a URL in an address bar in a browser?
- The browser searches for the record of the domain name IP address in the DNS in the following order:
- Browser cache
- Operating system cache
- The DNS server configured on the user's system (can be ISP DNS, public DNS, ...)
- If it couldn't find a DNS record locally, a full DNS resolution is started.
- It connects to the server using the TCP protocol
- The browser sends an HTTP request to the server
- The server sends an HTTP response back to the browser
- The browser renders the response (eg HTML)
- The browser then sends subsequent requests as needed to the server to get the embedded links, javascript, images in the HTML and then steps 3 to 5 are repeated.
TODO: add more details!
API
Explain what is an API
I like this definition from blog.christianposta.com:
"An explicitly and purposefully defined interface designed to be invoked over a network that enables software developers to get programmatic access to data and functionality within an organization in a controlled and comfortable way."
What is an API specification?
From swagger.io:
"An API specification provides a broad understanding of how an API behaves and how the API links with other APIs. It explains how the API functions and the results to expect when using the API"
Wahr oder falsch? API Definition is the same as API Specification
FALSCH. From swagger.io:
"An API definition is similar to an API specification in that it provides an understanding of how an API is organized and how the API functions. But the API definition is aimed at machine consumption instead of human consumption of APIs."
What is an API gateway?
An API gateway is like the gatekeeper that controls how different parts talk to each other and how information is exchanged between them.
The API gateway provides a single point of entry for all clients, and it can perform several tasks, including routing requests to the appropriate backend service, load balancing, security and authentication, rate limiting, caching, and monitoring.
By using an API gateway, organizations can simplify the management of their APIs, ensure consistent security and governance, and improve the performance and scalability of their backend services. They are also commonly used in microservices architectures, where there are many small, independent services that need to be accessed by different clients.
What are the advantages of using/implementing an API gateway?
Vorteile:
- Simplifies API management: Provides a single entry point for all requests, which simplifies the management and monitoring of multiple APIs.
- Improves security: Able to implement security features like authentication, authorization, and encryption to protect the backend services from unauthorized access.
- Enhances scalability: Can handle traffic spikes and distribute requests to backend services in a way that maximizes resource utilization and improves overall system performance.
- Enables service composition: Can combine different backend services into a single API, providing more granular control over the services that clients can access.
- Facilitates integration with external systems: Can be used to expose internal services to external partners or customers, making it easier to integrate with external systems and enabling new business models.
What is a Payload in API?
What is Automation? How it's related or different from Orchestration?
Automation is the act of automating tasks to reduce human intervention or interaction in regards to IT technology and systems.
While automation focuses on a task level, Orchestration is the process of automating processes and/or workflows which consists of multiple tasks that usually across multiple systems.
Tell me about interesting bugs you've found and also fixed
What is a Debugger and how it works?
What services an application might have?
Genehmigung- Protokollierung
- Authentifizierung
- Bestellung
- Frontend
- Back-end ...
What is Metadata?
Data about data. Basically, it describes the type of information that an underlying data will hold.
You can use one of the following formats: JSON, YAML, XML. Which one would you use? Warum?
I can't answer this for you :)
What's KPI?
What's OKR?
What's DSL (Domain Specific Language)?
Domain Specific Language (DSLs) are used to create a customised language that represents the domain such that domain experts can easily interpret it.
What's the difference between KPI and OKR?
YAML
What is YAML?
Data serialization language used by many technologies today like Kubernetes, Ansible, etc.
Wahr oder falsch? Any valid JSON file is also a valid YAML file
WAHR. Because YAML is superset of JSON.
What is the format of the following data? {
applications: [
{
name: "my_app",
language: "python",
version: 20.17
}
]
}
JSON What is the format of the following data? applications:
- app: "my_app"
language: "python"
version: 20.17
YAML How to write a multi-line string with YAML? What use cases is it good for?
someMultiLineString: | look mama I can write a multi-line string I love YAML
It's good for use cases like writing a shell script where each line of the script is a different command.
What is the difference between someMultiLineString: | to someMultiLineString: > ?
using > will make the multi-line string to fold into a single line
someMultiLineString: >
This is actually
a single line
do not let appearances fool you
What are placeholders in YAML?
They allow you reference values instead of directly writing them and it is used like this:
username: {{ my.user_name }}
How can you define multiple YAML components in one file?
Using this: --- For Examples:
document_number: 1
---
document_number: 2
Firmware
Explain what is a firmware
Wikipedia: "In computing, firmware is a specific class of computer software that provides the low-level control for a device's specific hardware. Firmware, such as the BIOS of a personal computer, may contain basic functions of a device, and may provide hardware abstraction services to higher-level software such as operating systems."
Kassandra
When running a cassandra cluster, how often do you need to run nodetool repair in order to keep the cluster consistent?- Within the columnFamily GC-grace Once a week
- Less than the compacted partition minimum bytes
- Depended on the compaction strategy
HTTP
What is HTTP?
Avinetworks: HTTP stands for Hypertext Transfer Protocol. HTTP uses TCP port 80 to enable internet communication. It is part of the Application Layer (L7) in OSI Model.
Describe HTTP request lifecycle
Resolve host by request to DNS resolver- Client SYN
- Server SYN+ACK
- Client SYN
- HTTP request
- HTTP response
Wahr oder falsch? HTTP is stateful
FALSCH. It doesn't maintain state for incoming request.
How HTTP request looks like?
It consists of:
Request line - request type- Headers - content info like length, encoding, etc.
- Body (not always included)
What HTTP method types are there?
ERHALTEN- POST
- KOPF
- SETZEN
- LÖSCHEN
- VERBINDEN
- OPTIONEN
- VERFOLGEN
What HTTP response codes are there?
1xx - informational- 2xx - Success
- 3xx - Redirect
- 4xx - Error, client fault
- 5xx - Error, server fault
What is HTTPS?
HTTPS is a secure version of the HTTP protocol used to transfer data between a web browser and a web server. It encrypts the communication using SSL/TLS encryption to ensure that the data is private and secure.
Learn more: https://www.cloudflare.com/learning/ssl/why-is-http-not-secure/
Explain HTTP Cookies
HTTP is stateless. To share state, we can use Cookies.
TODO: explain what is actually a Cookie
What is HTTP Pipelining?
You get "504 Gateway Timeout" error from an HTTP server. Was bedeutet es?
The server didn't receive a response from another server it communicates with in a timely manner.
What is a proxy?
A proxy is a server that acts as a middleman between a client device and a destination server. It can help improve privacy, security, and performance by hiding the client's IP address, filtering content, and caching frequently accessed data.
- Proxies can be used for load balancing, distributing traffic across multiple servers to help prevent server overload and improve website or application performance. They can also be used for data analysis, as they can log requests and traffic, providing useful insights into user behavior and preferences.
What is a reverse proxy?
A reverse proxy is a type of proxy server that sits between a client and a server, but it is used to manage traffic going in the opposite direction of a traditional forward proxy. In a forward proxy, the client sends requests to the proxy server, which then forwards them to the destination server. However, in a reverse proxy, the client sends requests to the destination server, but the requests are intercepted by the reverse proxy before they reach the server.
- They're commonly used to improve web server performance, provide high availability and fault tolerance, and enhance security by preventing direct access to the back-end server. They are often used in large-scale web applications and high-traffic websites to manage and distribute requests to multiple servers, resulting in improved scalability and reliability.
When you publish a project, you usually publish it with a license. What types of licenses are you familiar with and which one do you prefer to use?
Explain what is "X-Forwarded-For"
Wikipedia: "The X-Forwarded-For (XFF) HTTP header field is a common method for identifying the originating IP address of a client connecting to a web server through an HTTP proxy or load balancer."
Load Balancers
What is a load balancer?
A load balancer accepts (or denies) incoming network traffic from a client, and based on some criteria (application related, network, etc.) it distributes those communications out to servers (at least one).
Why to used a load balancer?
Scalability - using a load balancer, you can possibly add more servers in the backend to handle more requests/traffic from the clients, as opposed to using one server.- Redundancy - if one server in the backend dies, the load balancer will keep forwarding the traffic/requests to the second server so users won't even notice one of the servers in the backend is down.
What load balancer techniques/algorithms are you familiar with?
Round Robin- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
What are the drawbacks of round robin algorithm in load balancing?
A simple round robin algorithm knows nothing about the load and the spec of each server it forwards the requests to. It is possible, that multiple heavy workloads requests will get to the same server while other servers will got only lightweight requests which will result in one server doing most of the work, maybe even crashing at some point because it unable to handle all the heavy workloads requests by its own.- Each request from the client creates a whole new session. This might be a problem for certain scenarios where you would like to perform multiple operations where the server has to know about the result of operation so basically, being sort of aware of the history it has with the client. In round robin, first request might hit server X, while second request might hit server Y and ask to continue processing the data that was processed on server X already.
What is an Application Load Balancer?
In which scenarios would you use ALB?
At what layers a load balancer can operate?
L4 and L7
Can you perform load balancing without using a dedicated load balancer instance?
Yes, you can use DNS for performing load balancing.
What is DNS load balancing? What its advantages? When would you use it?
Load Balancers - Sticky Sessions
What are sticky sessions? What are their pros and cons?
Recommended read:
Nachteile:
Can cause uneven load on instance (since requests routed to the same instances) Pros:- Ensures in-proc sessions are not lost when a new request is created
Name one use case for using sticky sessions
You would like to make sure the user doesn't lose the current session data.
What sticky sessions use for enabling the "stickiness"?
Kekse. There are application based cookies and duration based cookies.
Explain application-based cookies
Generated by the application and/or the load balancer- Usually allows to include custom data
Explain duration-based cookies
Generated by the load balancer- Session is not sticky anymore once the duration elapsed
Load Balancers - Load Balancing Algorithms
Explain each of the following load balancing techniques- Round Robin
- Weighted Round Robin
- Least Connection
- Weighted Least Connection
- Resource Based
- Fixed Weighting
- Weighted Response Time
- Source IP Hash
- URL Hash
Explain use case for connection draining?
To ensure that a Classic Load Balancer stops sending requests to instances that are de-registering or unhealthy, while keeping the existing connections open, use connection draining. This enables the load balancer to complete in-flight requests made to instances that are de-registering or unhealthy. The maximum timeout value can be set between 1 and 3,600 seconds on both GCP and AWS.
Lizenzen
Are you familiar with "Creative Commons"? What do you know about it?
The Creative Commons license is a set of copyright licenses that allow creators to share their work with the public while retaining some control over how it can be used. The license was developed as a response to the restrictive standards of traditional copyright laws, which limited access of creative works. Its creators to choose the terms under which their works can be shared, distributed, and used by others. They're six main types of Creative Commons licenses, each with different levels of restrictions and permissions, the six licenses are:
- Attribution (CC BY): Allows others to distribute, remix, and build upon the work, even commercially, as long as they credit the original creator.
- Attribution-ShareAlike (CC BY-SA): Allows others to remix and build upon the work, even commercially, as long as they credit the original creator and release any new creations under the same license.
- Attribution-NoDerivs (CC BY-ND): Allows others to distribute the work, even commercially, but they cannot remix or change it in any way and must credit the original creator.
- Attribution-NonCommercial (CC BY-NC): Allows others to remix and build upon the work, but they cannot use it commercially and must credit the original creator.
- Attribution-NonCommercial-ShareAlike (CC BY-NC-SA): Allows others to remix and build upon the work, but they cannot use it commercially, must credit the original creator, and must release any new creations under the same license.
- Attribution-NonCommercial-NoDerivs (CC BY-NC-ND): Allows others to download and share the work, but they cannot use it commercially, remix or change it in any way, and must credit the original creator.
Simply stated, the Creative Commons licenses are a way for creators to share their work with the public while retaining some control over how it can be used. The licenses promote creativity, innovation, and collaboration, while also respecting the rights of creators while still encouraging the responsible use of creative works.
More information: https://creativecommons.org/licenses/
Explain the differences between copyleft and permissive licenses
In Copyleft, any derivative work must use the same licensing while in permissive licensing there are no such condition. GPL-3 is an example of copyleft license while BSD is an example of permissive license.
Zufällig
How a search engine works?
How auto completion works?
What is faster than RAM?
CPU cache. Quelle
What is a memory leak?
A memory leak is a programming error that occurs when a program fails to release memory that is no longer needed, causing the program to consume increasing amounts of memory over time.
The leaks can lead to a variety of problems, including system crashes, performance degradation, and instability. Usually occurring after failed maintenance on older systems and compatibility with new components over time.
What is your favorite protocol?
SSH HTTP DHCP DNS ...
What is Cache API?
What is the C10K problem? Is it relevant today?
https://idiallo.com/blog/c10k-2016
Lagerung
What types of storage are there?
Explain Object Storage
Data is divided to self-contained objects- Objects can contain metadata
What are the pros and cons of object storage?
Vorteile:
Usually with object storage, you pay for what you use as opposed to other storage types where you pay for the storage space you allocate- Scalable storage: Object storage mostly based on a model where what you use, is what you get and you can add storage as need Cons:
- Usually performs slower than other types of storage
- No granular modification: to change an object, you have re-create it
What are some use cases for using object storage?
Explain File Storage
File Storage used for storing data in files, in a hierarchical structure- Some of the devices for file storage: hard drive, flash drive, cloud-based file storage
- Files usually organized in directories
What are the pros and cons of File Storage?
Vorteile:
Users have full control of their own files and can run variety of operations on the files: delete, read, write and move.- Security mechanism allows for users to have a better control at things such as file locking
What are some examples of file storage?
Local filesystem Dropbox Google Drive
What types of storage devices are there?
Explain IOPS
Explain storage throughput
What is a filesystem?
A file system is a way for computers and other electronic devices to organize and store data files. It provides a structure that helps to organize data into files and directories, making it easier to find and manage information. A file system is crucial for providing a way to store and manage data in an organized manner.
Commonly used filed systems: Windows:
Mac OS:
Explain Dark Data
Explain MBR
Questions you CAN ask
A list of questions you as a candidate can ask the interviewer during or after the interview. These are only a suggestion, use them carefully. Not every interviewer will be able to answer these (or happy to) which should be perhaps a red flag warning for your regarding working in such place but that's really up to you.
What do you like about working here?
How does the company promote personal growth?
What is the current level of technical debt you are dealing with?
Be careful when asking this question - all companies, regardless of size, have some level of tech debt. Phrase the question in the light that all companies have the deal with this, but you want to see the current pain points they are dealing with
This is a great way to figure how managers deal with unplanned work, and how good they are at setting expectations with projects.
Why I should NOT join you? (or 'what you don't like about working here?')
What was your favorite project you've worked on?
This can give you insights in some of the cool projects a company is working on, and if you would enjoy working on projects like these. This is also a good way to see if the managers are allowing employees to learn and grow with projects outside of the normal work you'd do.
If you could change one thing about your day to day, what would it be?
Similar to the tech debt question, this helps you identify any pain points with the company. Additionally, it can be a great way to show how you'd be an asset to the team.
For Example, if they mention they have problem X, and you've solved that in the past, you can show how you'd be able to mitigate that problem.
Let's say that we agree and you hire me to this position, after X months, what do you expect that I have achieved?
Not only this will tell you what is expected from you, it will also provide big hint on the type of work you are going to do in the first months of your job.
Testen
Explain white-box testing
Explain black-box testing
What are unit tests?
Unit test are a software testing technique that involves systimatically breaking down a system and testing each individual part of the assembly. These tests are automated and can be run repeatedly to allow developers to catch edge case scenarios or bugs quickly while developing.
The main objective of unit tests are to verify each function is producing proper outputs given a set of inputs.
What types of tests would you run to test a web application?
Explain test harness?
What is A/B testing?
What is network simulation and how do you perform it?
What types of performances tests are you familiar with?
Explain the following types of tests:- Load Testing
- Stress Testing
- Capacity Testing
- Volume Testing
- Endurance Testing
Regex
Given a text file, perform the following exercises
Extrakt
Extract all the numbers
Extract the first word of each line
"^w+" Bonus: extract the last word of each line
-
"w+(?=W*$)" (in most cases, depends on line formatting)
Extract all the IP addresses
- "b(?:d{1,3} .){3}d{1,3}b" IPV4:(This format looks for 1 to 3 digit sequence 3 times)
Extract dates in the format of yyyy-mm-dd or yyyy-dd-mm
Extract email addresses
- "b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+ .[A-Za-z]{2,}b"
Ersetzen
Replace tabs with four spaces
Replace 'red' with 'green'
System Design
Explain what a "single point of failure" is.
A "single point of failure", in a system or organization, if it were to fail would cause the entire system to fail or significantly disrupt it's operation. In other words, it is a vulnerability where there is no backup in place to compensate for the failure. What is CDN?
CDN (Content Delivery Network) responsible for distributing content geographically. Part of it, is what is known as edge locations, aka cache proxies, that allows users to get their content quickly due to cache features and geographical distribution.
Explain Multi-CDN
In single CDN, the whole content is originated from content delivery network.
In multi-CDN, content is distributed across multiple different CDNs, each might be on a completely different provider/cloud.
What are the benefits of Multi-CDN over a single CDN?
Resiliency: Relying on one CDN means no redundancy. With multiple CDNs you don't need to worry about your CDN being down- Flexibility in Costs: Using one CDN enforces you to specific rates of that CDN. With multiple CDNs you can take into consideration using less expensive CDNs to deliver the content.
- Performance: With Multi-CDN there is bigger potential in choosing better locations which more close to the client asking the content
- Scale: With multiple CDNs, you can scale services to support more extreme conditions
Explain "3-Tier Architecture" (including pros and cons)
A "3-Tier Architecture" is a pattern used in software development for designing and structuring applications. It divides the application into 3 interconnected layers: Presentation, Business logic and Data storage. PROS: * Scalability * Security * Reusability CONS: * Complexity * Performance overhead * Cost and development time Explain Mono-repo vs. Multi-repo.What are the cons and pros of each approach?
In a Mono-repo, all the code for an organization is stored in a single,centralized repository. PROS (Mono-repo): * Unified tooling * Code Sharing CONS (Mono-repo): * Increased complexity * Slower cloning In a Multi-repo setup, each component is stored in it's own separate repository. Each repository has it's own version control history. PROS (Multi-repo):
Simpler to manage- Different teams and developers can work on different parts of the project independently, making parallel development easier. CONS (Multi-repo):
- Code duplication
- Integration challenges
What are the drawbacks of monolithic architecture?
Not suitable for frequent code changes and the ability to deploy new features- Not designed for today's infrastructure (like public clouds)
- Scaling a team to work monolithic architecture is more challenging
- If a single component in this architecture fails, then the entire application fails.
What are the advantages of microservices architecture over a monolithic architecture?
Each of the services individually fail without escalating into an application-wide outage.- Each service can be developed and maintained by a separate team and this team can choose its own tools and coding language
What's a service mesh?
It is a layer that facilitates communication management and control between microservices in a containerized application. It handles tasks such as load balancing, encryption, and monitoring. Explain "Loose Coupling"
In "Loose Coupling", components of a system communicate with each other with a little understanding of each other's internal workings. This improves scalability and ease of modification in complex systems. What is a message queue? When is it used?
It is a communication mechanism used in distributed systems to enable asynchronous communication between different components. It is generally used when the systems use a microservices approach. Skalierbarkeit
Explain Scalability
The ability easily grow in size and capacity based on demand and usage.
Explain Elasticity
The ability to grow but also to reduce based on what is required
Explain Disaster Recovery
Disaster recovery is the process of restoring critical business systems and data after a disruptive event. The goal is to minimize the impact and resume normal business activities quickly. This involves creating a plan, testing it, backing up critical data, and storing it in safe locations. In case of a disaster, the plan is then executed, backups are restored, and systems are hopefully brought back online. The recovery process may take hours or days depending on the damages of infrastructure. This makes business planning important, as a well-designed and tested disaster recovery plan can minimize the impact of a disaster and keep operations going.
Explain Fault Tolerance and High Availability
Fault Tolerance - The ability to self-heal and return to normal capacity. Also the ability to withstand a failure and remain functional.
High Availability - Being able to access a resource (in some use cases, using different platforms)
What is the difference between high availability and Disaster Recovery?
wintellect.com: "High availability, simply put, is eliminating single points of failure and disaster recovery is the process of getting a system back to an operational state when a system is rendered inoperative. In essence, disaster recovery picks up when high availability fails, so HA first."
Explain Vertical Scaling
Vertical Scaling is the process of adding resources to increase power of existing servers. For example, adding more CPUs, adding more RAM, etc.
What are the disadvantages of Vertical Scaling?
With vertical scaling alone, the component still remains a single point of failure. In addition, it has hardware limit where if you don't have more resources, you might not be able to scale vertically.
Which type of cloud services usually support vertical scaling?
Databases, cache. It's common mostly for non-distributed systems.
Explain Horizontal Scaling
Horizontal Scaling is the process of adding more resources that will be able handle requests as one unit
What is the disadvantage of Horizontal Scaling? What is often required in order to perform Horizontal Scaling?
A load balancer. You can add more resources, but if you would like them to be part of the process, you have to serve them the requests/responses. Also, data inconsistency is a concern with horizontal scaling.
Explain in which use cases will you use vertical scaling and in which use cases you will use horizontal scaling
Explain Resiliency and what ways are there to make a system more resilient
Explain "Consistent Hashing"
How would you update each of the services in the following drawing without having app (foo.com) downtime?
What is the problem with the following architecture and how would you fix it?
The load on the producers or consumers may be high which will then cause them to hang or crash.
Instead of working in "push mode", the consumers can pull tasks only when they are ready to handle them. It can be fixed by using a streaming platform like Kafka, Kinesis, etc. This platform will make sure to handle the high load/traffic and pass tasks/messages to consumers only when the ready to get them.

Users report that there is huge spike in process time when adding little bit more data to process as an input. What might be the problem?

How would you scale the architecture from the previous question to hundreds of users?
Cache
What is "cache"? In which cases would you use it?
What is "distributed cache"?
What is a "cache replacement policy"?
Schauen Sie hier vorbei
Which cache replacement policies are you familiar with?
You can find a list here
Explain the following cache policies:
Read about it here
Why not writing everything to cache instead of a database/datastore?
Caching and databases serve different purposes and are optimized for different use cases. Caching is used to speed up read operations by storing frequently accessed data in memory or on a fast storage medium. By keeping data close to the application, caching reduces the latency and overhead of accessing data from a slower, more distant storage system such as a database or disk.
On the other hand, databases are optimized for storing and managing persistent data. Databases are designed to handle concurrent read and write operations, enforce consistency and integrity constraints, and provide features such as indexing and querying.
Migrationen
How you prepare for a migration? (or plan a migration)
You can mention:
roll-back & roll-forward cut over dress rehearsals DNS redirection
Explain "Branch by Abstraction" technique
Design a system
Can you design a video streaming website?
Can you design a photo upload website?
How would you build a URL shortener?
More System Design Questions
Additional exercises can be found in system-design-notebook repository.

Hardware
What is a CPU?
A central processing unit (CPU) performs basic arithmetic, logic, controlling, and input/output (I/O) operations specified by the instructions in the program. This contrasts with external components such as main memory and I/O circuitry, and specialized processors such as graphics processing units (GPUs).
Was ist RAM?
RAM (Random Access Memory) is the hardware in a computing device where the operating system (OS), application programs and data in current use are kept so they can be quickly reached by the device's processor. RAM is the main memory in a computer. It is much faster to read from and write to than other kinds of storage, such as a hard disk drive (HDD), solid-state drive (SSD) or optical drive.
What is a GPU?
A GPU, or Graphics Processing Unit, is a specialized electronic circuit designed to expedite image and video processing for display on a computer screen.
What is an embedded system?
An embedded system is a computer system - a combination of a computer processor, computer memory, and input/output peripheral devices—that has a dedicated function within a larger mechanical or electronic system. It is embedded as part of a complete device often including electrical or electronic hardware and mechanical parts.
Can you give an example of an embedded system?
A common example of an embedded system is a microwave oven's digital control panel, which is managed by a microcontroller.
When committed to a certain goal, Raspberry Pi can serve as an embedded system.
What types of storage are there?
There are several types of storage, including hard disk drives (HDDs), solid-state drives (SSDs), and optical drives (CD/DVD/Blu-ray). Other types of storage include USB flash drives, memory cards, and network-attached storage (NAS).
What are some considerations DevOps teams should keep in mind when selecting hardware for their job?
Choosing the right DevOps hardware is essential for ensuring streamlined CI/CD pipelines, timely feedback loops, and consistent service availability. Here's a distilled guide on what DevOps teams should consider:
Understanding Workloads :
- CPU : Consider the need for multi-core or high-frequency CPUs based on your tasks.
- RAM : Enough memory is vital for activities like large-scale coding or intensive automation.
- Storage : Evaluate storage speed and capacity. SSDs might be preferable for swift operations.
Expandability :
- Horizontal Growth : Check if you can boost capacity by adding more devices.
- Vertical Growth : Determine if upgrades (like RAM, CPU) to individual machines are feasible.
Connectivity Considerations :
- Data Transfer : Ensure high-speed network connections for activities like code retrieval and data transfers.
- Speed : Aim for low-latency networks, particularly important for distributed tasks.
- Backup Routes : Think about having backup network routes to avoid downtimes.
Consistent Uptime :
- Plan for hardware backups like RAID configurations, backup power sources, or alternate network connections to ensure continuous service.
System Compatibility :
- Make sure your hardware aligns with your software, operating system, and intended platforms.
Power Efficiency :
- Hardware that uses energy efficiently can reduce costs in long-term, especially in large setups.
Safety Measures :
- Explore hardware-level security features, such as TPM, to enhance protection.
Overseeing & Control :
- Tools like ILOM can be beneficial for remote handling.
- Make sure the hardware can be seamlessly monitored for health and performance.
Budgeting :
- Consider both initial expenses and long-term costs when budgeting.
Support & Community :
- Choose hardware from reputable vendors known for reliable support.
- Check for available drivers, updates, and community discussions around the hardware.
Planning Ahead :
- Opt for hardware that can cater to both present and upcoming requirements.
Operational Environment :
- Temperature Control : Ensure cooling systems to manage heat from high-performance units.
- Space Management : Assess hardware size considering available rack space.
- Reliable Power : Factor in consistent and backup power sources.
Cloud Coordination :
- If you're leaning towards a hybrid cloud setup, focus on how local hardware will mesh with cloud resources.
Life Span of Hardware :
- Be aware of the hardware's expected duration and when you might need replacements or upgrades.
Optimized for Virtualization :
- If utilizing virtual machines or containers, ensure the hardware is compatible and optimized for such workloads.
Adaptability :
- Modular hardware allows individual component replacements, offering more flexibility.
Avoiding Single Vendor Dependency :
- Try to prevent reliance on a single vendor unless there are clear advantages.
Eco-Friendly Choices :
- Prioritize sustainably produced hardware that's energy-efficient and environmentally responsible.
In essence, DevOps teams should choose hardware that is compatible with their tasks, versatile, gives good performance, and stays within their budget. Furthermore, long-term considerations such as maintenance, potential upgrades, and compatibility with impending technological shifts must be prioritized.
What is the role of hardware in disaster recovery planning and implementation?
Hardware is critical in disaster recovery (DR) solutions. While the broader scope of DR includes things like standard procedures, norms, and human roles, it's the hardware that keeps business processes running smoothly. Here's an outline of how hardware works with DR:
Storing Data and Ensuring Its Duplication :
- Backup Equipment : Devices like tape storage, backup servers, and external HDDs keep essential data stored safely at a different location.
- Disk Arrays : Systems such as RAID offer a safety net. If one disk crashes, the others compensate.
Alternate Systems for Recovery :
- Backup Servers : These step in when the main servers falter, maintaining service flow.
- Traffic Distributors : Devices like load balancers share traffic across servers. If a server crashes, they reroute users to operational ones.
Alternate Operation Hubs :
- Ready-to-use Centers : Locations equipped and primed to take charge immediately when the main center fails.
- Basic Facilities : Locations with necessary equipment but lacking recent data, taking longer to activate.
- Semi-prepped Facilities : Locations somewhat prepared with select systems and data, taking a moderate duration to activate.
Power Backup Mechanisms :
- Instant Power Backup : Devices like UPS offer power during brief outages, ensuring no abrupt shutdowns.
- Long-term Power Solutions : Generators keep vital systems operational during extended power losses.
Networking Equipment :
- Backup Internet Connections : Having alternatives ensures connectivity even if one provider faces issues.
- Secure Connection Tools : Devices ensuring safe remote access, especially crucial during DR situations.
On-site Physical Setup :
- Organized Housing : Structures like racks to neatly store and manage hardware.
- Emergency Temperature Control : Backup cooling mechanisms to counter server overheating in HVAC malfunctions.
Alternate Communication Channels :
- Orbit-based Phones : Handy when regular communication methods falter.
- Direct Communication Devices : Devices like radios useful when primary systems are down.
Protection Mechanisms :
- Electronic Barriers & Alert Systems : Devices like firewalls and intrusion detection keep DR systems safeguarded.
- Physical Entry Control : Systems controlling entry and monitoring, ensuring only cleared personnel have access.
Uniformity and Compatibility in Hardware :
- It's simpler to manage and replace equipment in emergencies if hardware configurations are consistent and compatible.
Equipment for Trials and Upkeep :
- DR drills might use specific equipment to ensure the primary systems remain unaffected. This verifies the equipment's readiness and capacity to manage real crises.
In summary, while software and human interventions are important in disaster recovery operations, it is the hardware that provides the underlying support. It is critical for efficient disaster recovery plans to keep this hardware resilient, duplicated, and routinely assessed.
What is a RAID?
RAID is an acronym that stands for "Redundant Array of Independent Disks." It is a technique that combines numerous hard drives into a single device known as an array in order to improve performance, expand storage capacity, and/or offer redundancy to prevent data loss. RAID levels (for example, RAID 0, RAID 1, and RAID 5) provide varied benefits in terms of performance, redundancy, and storage efficiency.
What is a microcontroller?
A microcontroller is a small integrated circuit that controls certain tasks in an embedded system. It typically includes a CPU, memory, and input/output peripherals.
What is a Network Interface Controller or NIC?
A Network Interface Controller (NIC) is a piece of hardware that connects a computer to a network and allows it to communicate with other devices.
What is a DMA?
Direct memory access (DMA) is a feature of computer systems that allows certain hardware subsystems to access main system memory independently of the central processing unit (CPU).DMA enables devices to share and receive data from the main memory in a computer. It does this while still allowing the CPU to perform other tasks.
What is a Real-Time Operating Systems?
A real-time operating system (RTOS) is an operating system (OS) for real-time computing applications that processes data and events that have critically defined time constraints. An RTOS is distinct from a time-sharing operating system, such as Unix, which manages the sharing of system resources with a scheduler, data buffers, or fixed task prioritization in a multitasking or multiprogramming environment. Processing time requirements need to be fully understood and bound rather than just kept as a minimum. All processing must occur within the defined constraints. Real-time operating systems are event-driven and preemptive, meaning the OS can monitor the relevant priority of competing tasks, and make changes to the task priority. Event-driven systems switch between tasks based on their priorities, while time-sharing systems switch the task based on clock interrupts.
List of interrupt types
There are six classes of interrupts possible:
Extern- Machine check
- E/A
- Programm
- Neustart
- Supervisor call (SVC)
Big Data
Explain what is exactly Big Data
As defined by Doug Laney:
Volume: Extremely large volumes of data- Velocity: Real time, batch, streams of data
- Variety: Various forms of data, structured, semi-structured and unstructured
- Veracity or Variability: Inconsistent, sometimes inaccurate, varying data
What is DataOps? How is it related to DevOps?
DataOps seeks to reduce the end-to-end cycle time of data analytics, from the origin of ideas to the literal creation of charts, graphs and models that create value. DataOps combines Agile development, DevOps and statistical process controls and applies them to data analytics.
What is Data Architecture?
An answer from talend.com:
"Data architecture is the process of standardizing how organizations collect, store, transform, distribute, and use data. The goal is to deliver relevant data to people who need it, when they need it, and help them make sense of it."
Explain the different formats of data
Structured - data that has defined format and length (eg numbers, words)- Semi-structured - Doesn't conform to a specific format but is self-describing (eg XML, SWIFT)
- Unstructured - does not follow a specific format (eg images, test messages)
What is a Data Warehouse?
Wikipedia's explanation on Data Warehouse Amazon's explanation on Data Warehouse
What is Data Lake?
Data Lake - Wikipedia
Can you explain the difference between a data lake and a data warehouse?
What is "Data Versioning"? What models of "Data Versioning" are there?
What is ETL?
Apache Hadoop
Explain what is Hadoop
Apache Hadoop - Wikipedia
Explain Hadoop YARN
Responsible for managing the compute resources in clusters and scheduling users' applications
Explain Hadoop MapReduce
A programming model for large-scale data processing
Explain Hadoop Distributed File Systems (HDFS)
Distributed file system providing high aggregate bandwidth across the cluster.- For a user it looks like a regular file system structure but behind the scenes it's distributed across multiple machines in a cluster
- Typical file size is TB and it can scale and supports millions of files
- It's fault tolerant which means it provides automatic recovery from faults
- It's best suited for running long batch operations rather than live analysis
What do you know about HDFS architecture?
HDFS Architecture
Master-slave architecture- Namenode - master, Datanodes - slaves
- Files split into blocks
- Blocks stored on datanodes
- Namenode controls all metadata
Ceph
Explain what is Ceph
Ceph is an Open-Source Distributed Storage System designed to provide excellent performance, reliability, and scalability. It's often used in cloud computing environments and Data Centers. Wahr oder falsch? Ceph favor consistency and correctness over performances
WAHR Which services or types of storage Ceph supports?
Object (RGW)- Block (RBD)
- File (CephFS)
What is RADOS?
Reliable Autonomic Distributed Object Storage- Provides low-level data object storage service
- Strong Consistency
- Simplifies design and implementation of higher layers (block, file, object)
Describe RADOS software components
Monitor- Central authority for authentication, data placement, policy
- Coordination point for all other cluster components
- Protect critical cluster state with Paxos
- Manager
- Aggregates real-time metrics (throughput, disk usage, etc.)
- Host for pluggable management functions
- 1 active, 1+ standby per cluster
- OSD (Object Storage Daemon)
Stores data on an HDD or SSD
- Services client IO requests
What is the workflow of retrieving data from Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data:
Client could be any of the following
- Ceph Block Device
- Ceph Object Gateway
- Any third party ceph client
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a OSD.
- Once the placement group and the OSD Daemon are determined, the client can retrieve the data from the appropriate OSD
What is the workflow of writing data to Ceph?
The work flow is as follows: - The client sends a request to the ceph cluster to retrieve data
- The client retrieves the latest cluster map from the Ceph Monitor
- The client uses the CRUSH algorithm to map the object to a placement group. The placement group is then assigned to a Ceph OSD Daemon dynamically.
- The client sends the data to the primary OSD of the determined placement group. If the data is stored in an erasure-coded pool, the primary OSD is responsible for encoding the object into data chunks and coding chunks, and distributing them to the other OSDs.
What are "Placement Groups"?
Describe in the detail the following: Objects -> Pool -> Placement Groups -> OSDs
What is OMAP?
What is a metadata server? Wie funktioniert es?
Packer
What is Packer? Wofür wird es verwendet?
In general, Packer automates machine images creation. It allows you to focus on configuration prior to deployment while making the images. This allows you start the instances much faster in most cases.
Packer follows a "configuration->deployment" model or "deployment->configuration"?
A configuration->deployment which has some advantages like:
Deployment Speed - you configure once prior to deployment instead of configuring every time you deploy. This allows you to start instances/services much quicker.- More immutable infrastructure - with configuration->deployment it's not likely to have very different deployments since most of the configuration is done prior to the deployment. Issues like dependencies errors are handled/discovered prior to deployment in this model.
Freigeben
Explain Semantic Versioning
This page explains it perfectly:
Given a version number MAJOR.MINOR.PATCH, increment the:
MAJOR version when you make incompatible API changes
MINOR version when you add functionality in a backwards compatible manner
PATCH version when you make backwards compatible bug fixes
Additional labels for pre-release and build metadata are available as extensions to the MAJOR.MINOR.PATCH format.
Zertifikate
If you are looking for a way to prepare for a certain exam this is the section for you. Here you'll find a list of certificates, each references to a separate file with focused questions that will help you to prepare to the exam. Viel Glück :)
AWS
- Cloud Practitioner (Latest update: 2020)
- Solutions Architect Associate (Latest update: 2021)
- Cloud SysOps Administration Associate (Latest update: Oct 2022)
Azurblau
- AZ-900 (Latest update: 2021)
Kubernetes
- Certified Kubernetes Administrator (CKA) (Latest update: 2022)
Additional DevOps and SRE Projects




Credits
Thanks to all of our amazing contributors who make it easy for everyone to learn new things :)
Logos credits can be found here
Lizenz


