homemade machine learning
1.0.0
?? Die Ukraine wird von der russischen Armee angegriffen. ZIVILISTEN WERDEN GETÖTET. WOHNGEBIETE WERDEN BOMBARDIERT.
- Helfen Sie der Ukraine über:
- Serhiy Prytula Wohltätigkeitsstiftung
- Come Back Alive Charity Foundation
- Nationalbank der Ukraine
- Weitere Informationen auf war.ukraine.ua und MFA der Ukraine
Lesen Sie dies in anderen Sprachen: Español
Sie könnten interessiert sein an:
- Hausgemachtes GPT • JS
- Interaktive Experimente zum maschinellen Lernen
Die Octave/MatLab-Version dieses Repositorys finden Sie im Projekt „Machine-Learning-Octave“.
Dieses Repository enthält Beispiele beliebter Algorithmen für maschinelles Lernen, die in Python implementiert sind, wobei die dahinter stehende Mathematik erläutert wird. Jeder Algorithmus verfügt über eine interaktive Jupyter Notebook- Demo, mit der Sie mit Trainingsdaten und Algorithmuskonfigurationen experimentieren und die Ergebnisse, Diagramme und Vorhersagen sofort direkt in Ihrem Browser sehen können. In den meisten Fällen basieren die Erklärungen auf diesem großartigen Kurs zum maschinellen Lernen von Andrew Ng.
Der Zweck dieses Repositorys besteht nicht darin, Algorithmen für maschinelles Lernen mithilfe von Einzeilern aus Bibliotheken von Drittanbietern zu implementieren , sondern vielmehr darin, die Implementierung dieser Algorithmen von Grund auf zu üben und ein besseres Verständnis der Mathematik hinter jedem Algorithmus zu erlangen. Aus diesem Grund werden alle Algorithmenimplementierungen als „hausgemacht“ bezeichnet und sind nicht für die Verwendung in der Produktion gedacht.
Beim überwachten Lernen haben wir einen Satz Trainingsdaten als Eingabe und einen Satz Beschriftungen oder „richtige Antworten“ für jeden Trainingssatz als Ausgabe. Dann trainieren wir unser Modell (Parameter des maschinellen Lernalgorithmus), um die Eingabe korrekt der Ausgabe zuzuordnen (um eine korrekte Vorhersage zu treffen). Der ultimative Zweck besteht darin, solche Modellparameter zu finden, die auch für neue Eingabebeispiele erfolgreich die korrekte Eingabe-Ausgabe- Zuordnung (Vorhersagen) aufrechterhalten.
Bei Regressionsproblemen machen wir reale Wertvorhersagen. Grundsätzlich versuchen wir, entlang der Trainingsbeispiele eine Linie/Ebene/n-dimensionale Ebene zu zeichnen.
Anwendungsbeispiele: Aktienkursprognose, Verkaufsanalyse, Abhängigkeit von einer beliebigen Zahl usw.
country happiness anhand economy GDPcountry happiness anhand des economy GDP und freedom indexBei Klassifizierungsproblemen teilen wir Eingabebeispiele nach bestimmten Merkmalen auf.
Anwendungsbeispiele: Spam-Filter, Spracherkennung, Suche nach ähnlichen Dokumenten, Erkennung handschriftlicher Briefe usw.
class basierend auf petal_length und petal_widthvalidity basierend auf param_1 und param_228x28 Pixel großen Bildern erkennen28x28 -Pixel-Bildern erkennen Unüberwachtes Lernen ist ein Zweig des maschinellen Lernens, der aus Testdaten lernt, die nicht gekennzeichnet, klassifiziert oder kategorisiert wurden. Anstatt auf Feedback zu reagieren, identifiziert unüberwachtes Lernen Gemeinsamkeiten in den Daten und reagiert auf der Grundlage des Vorhandenseins oder Fehlens solcher Gemeinsamkeiten in jedem neuen Datenelement.
Bei Clustering-Problemen teilen wir die Trainingsbeispiele nach unbekannten Merkmalen auf. Der Algorithmus entscheidet selbst, welches Merkmal für die Aufteilung verwendet wird.
Anwendungsbeispiele: Marktsegmentierung, Analyse sozialer Netzwerke, Organisation von Computerclustern, Analyse astronomischer Daten, Bildkomprimierung usw.
petal_length und petal_width in Cluster aufUnter Anomalieerkennung (auch Ausreißererkennung) versteht man die Identifizierung seltener Elemente, Ereignisse oder Beobachtungen, die Verdacht erregen, weil sie erheblich von der Mehrzahl der Daten abweichen.
Anwendungsbeispiele: Erkennung von Eindringlingen, Betrugserkennung, Überwachung des Systemzustands, Entfernen anomaler Daten aus dem Datensatz usw.
latency und threshold Das neuronale Netzwerk selbst ist kein Algorithmus, sondern vielmehr ein Rahmenwerk für die Zusammenarbeit vieler verschiedener maschineller Lernalgorithmen und die Verarbeitung komplexer Dateneingaben.
Anwendungsbeispiele: als Ersatz für alle anderen Algorithmen im Allgemeinen, Bilderkennung, Spracherkennung, Bildverarbeitung (Anwenden eines bestimmten Stils), Sprachübersetzung usw.
28x28 Pixel großen Bildern erkennen28x28 -Pixel-Bildern 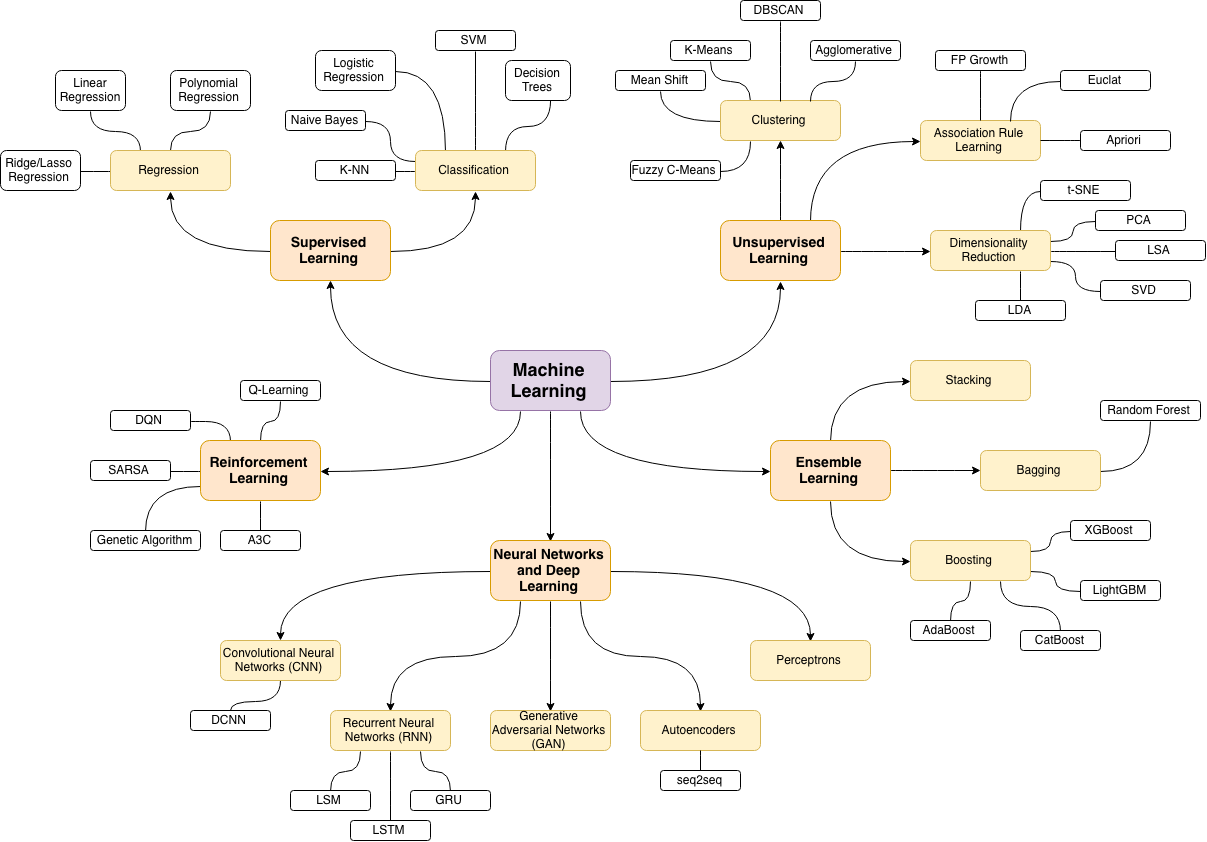
Die Quelle der folgenden Themenkarte zum maschinellen Lernen ist dieser wunderbare Blogbeitrag
Stellen Sie sicher, dass Python auf Ihrem Computer installiert ist.
Möglicherweise möchten Sie die venv-Standard-Python-Bibliothek verwenden, um virtuelle Umgebungen zu erstellen und Python, pip und alle abhängigen Pakete aus dem lokalen Projektverzeichnis zu installieren und bereitzustellen, um Probleme mit systemweiten Paketen und deren Versionen zu vermeiden.
Installieren Sie alle für das Projekt erforderlichen Abhängigkeiten, indem Sie Folgendes ausführen:
pip install -r requirements.txtAlle Demos im Projekt können direkt in Ihrem Browser ausgeführt werden, ohne dass Jupyter lokal installiert werden muss. Wenn Sie Jupyter Notebook jedoch lokal starten möchten, können Sie dies tun, indem Sie den folgenden Befehl im Stammordner des Projekts ausführen:
jupyter notebook Danach wird Jupyter Notebook über http://localhost:8888 zugänglich sein.
Jeder Algorithmusabschnitt enthält Demo-Links zu Jupyter NBViewer. Dies ist eine schnelle Online-Vorschau für Jupyter-Notebooks, mit der Sie Democode, Diagramme und Daten direkt in Ihrem Browser sehen können, ohne etwas lokal installieren zu müssen. Wenn Sie den Code ändern und mit dem Demo-Notebook experimentieren möchten, müssen Sie das Notebook in Binder starten. Sie können dies tun, indem Sie einfach auf den Link „Auf Binder ausführen“ in der oberen rechten Ecke des NBViewers klicken.
Die Liste der Datensätze, die für Jupyter Notebook-Demos verwendet werden, finden Sie im Datenordner.
Sie können dieses Projekt über ❤️ GitHub oder ❤️ Patreon unterstützen.


