vaex
Version linked to the paper
Vaex ist eine leistungsstarke Python-Bibliothek für verzögerte Out-of-Core-DataFrames (ähnlich wie Pandas), um große tabellarische Datensätze zu visualisieren und zu untersuchen. Es berechnet Statistiken wie Mittelwert, Summe, Anzahl, Standardabweichung usw. auf einem N-dimensionalen Gitter für mehr als eine Milliarde ( 10^9 ) Abtastwerte/Zeilen pro Sekunde . Die Visualisierung erfolgt mithilfe von Histogrammen , Dichtediagrammen und 3D-Volumenrendering und ermöglicht so die interaktive Erkundung großer Datenmengen. Vaex verwendet Speicherzuordnung, Null-Speicherkopie-Richtlinie und verzögerte Berechnungen für beste Leistung (keine Speicherverschwendung).
Mit Pip:
$ pip install vaex
Oder conda:
$ conda install -c conda-forge vaex
Weitere Einzelheiten finden Sie in der Dokumentation
HDF5 und Apache Arrow werden unterstützt.

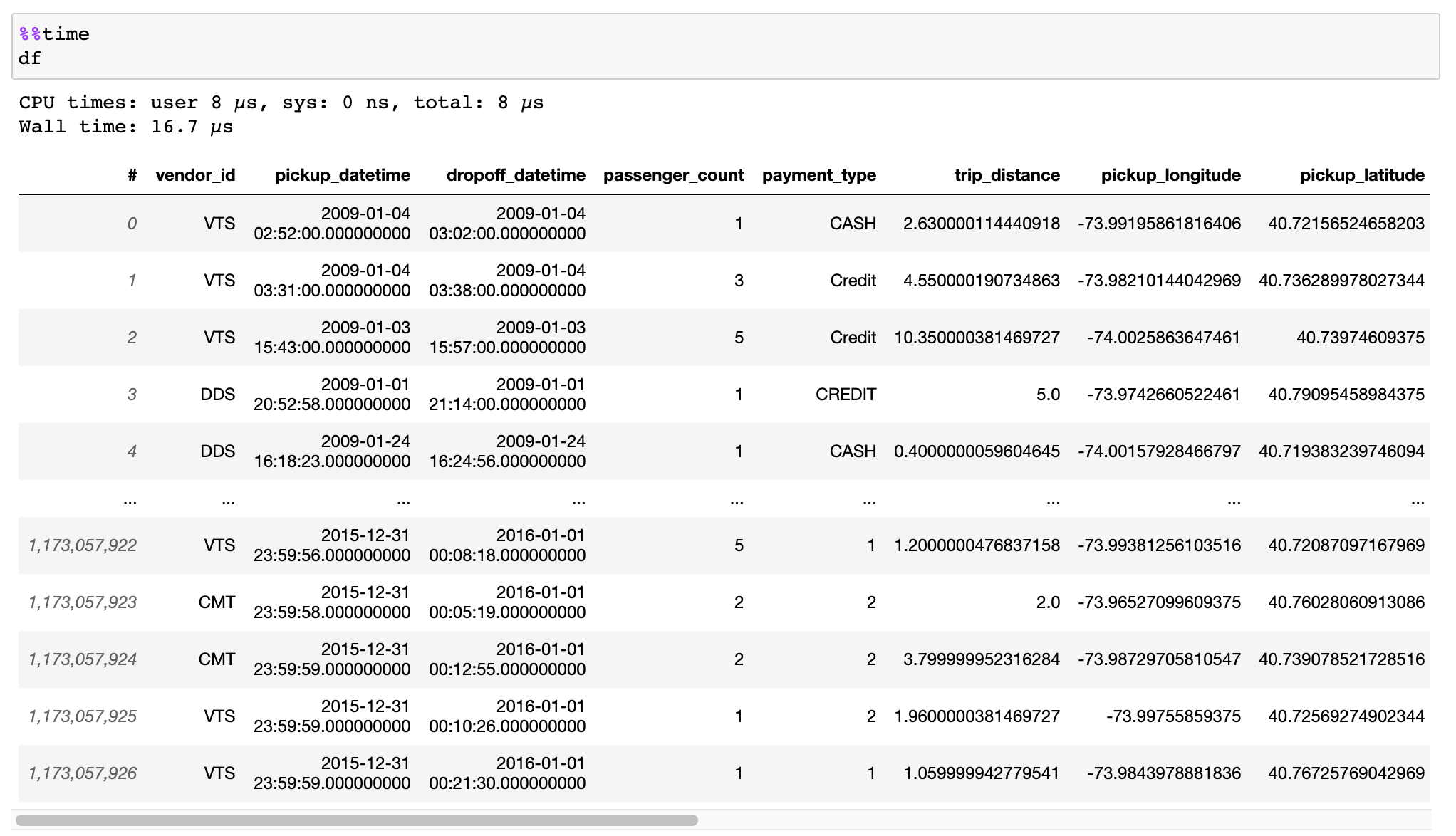
Lesen Sie die Dokumentation zur effizienten Konvertierung Ihrer Daten aus CSV-Dateien, Pandas DataFrames oder anderen Quellen.
Lazy Streaming von S3 wird in Kombination mit Speicherzuordnung unterstützt.

Verschwenden Sie weder Speicher noch Zeit mit Feature-Engineering, wir transformieren Ihre Daten bei Bedarf (träge).
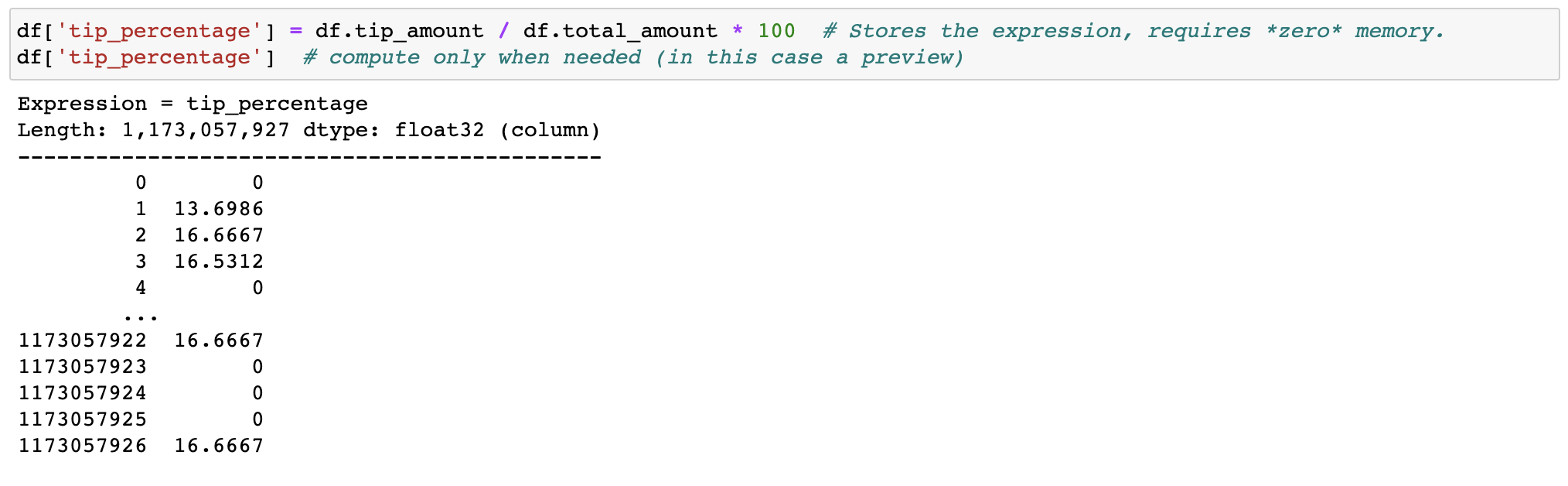
Durch das Filtern und Auswerten von Ausdrücken wird kein Speicher durch das Erstellen von Kopien verschwendet. Die Daten bleiben unberührt auf der Festplatte und werden nur bei Bedarf gestreamt. Verzögern Sie die Zeit, bevor Sie einen Cluster benötigen.
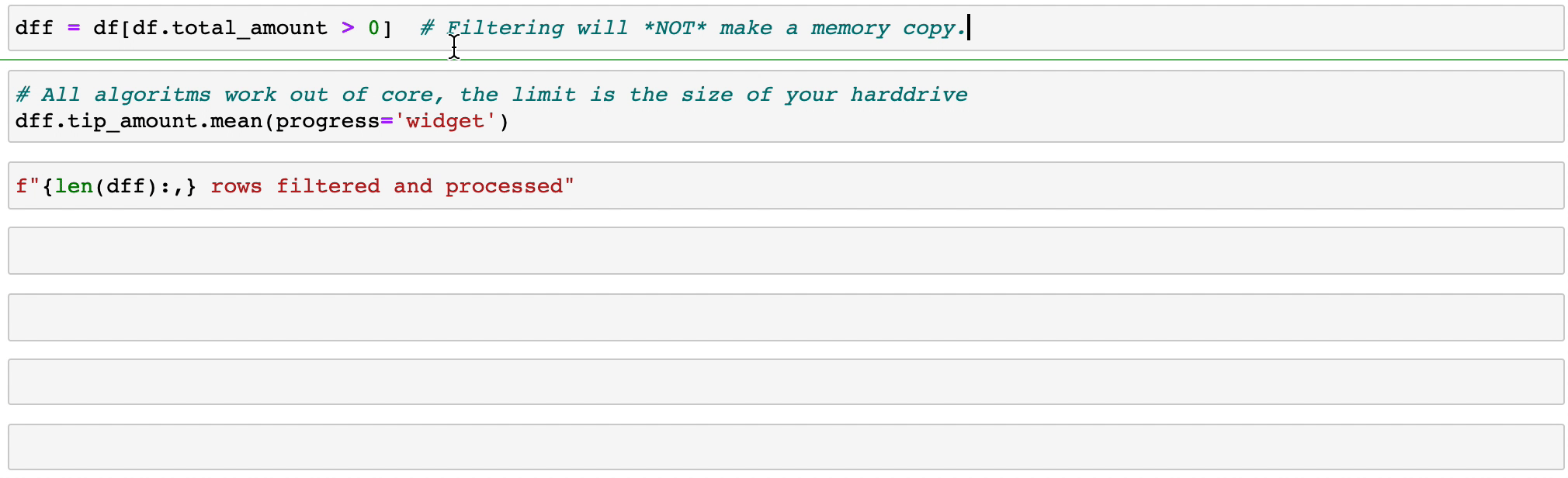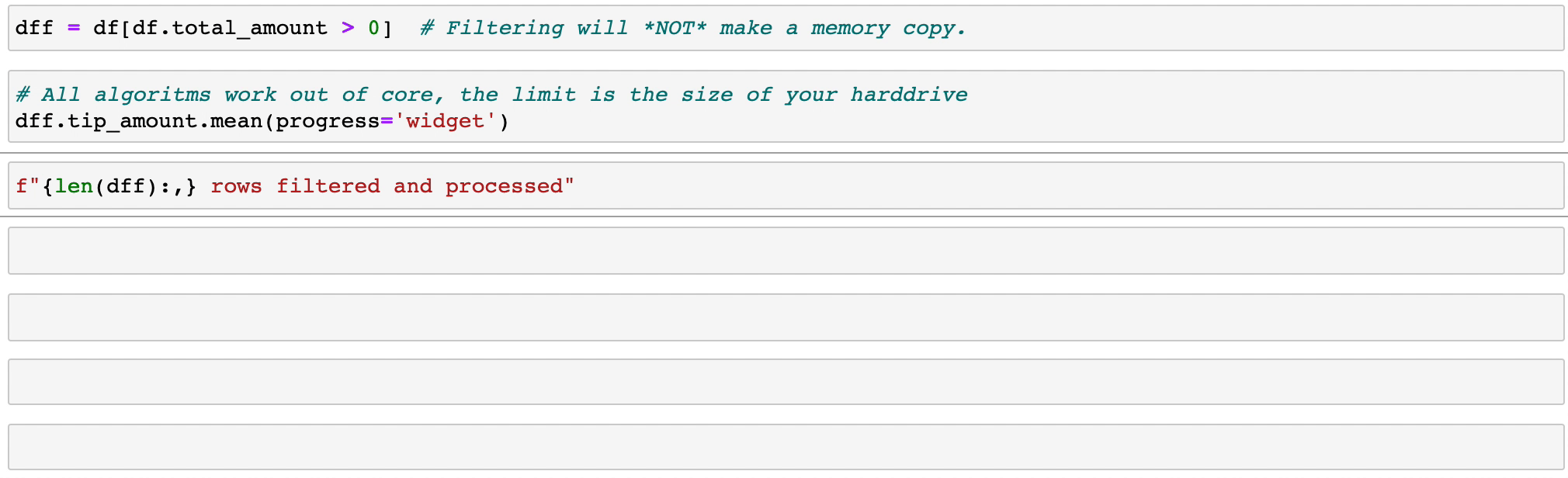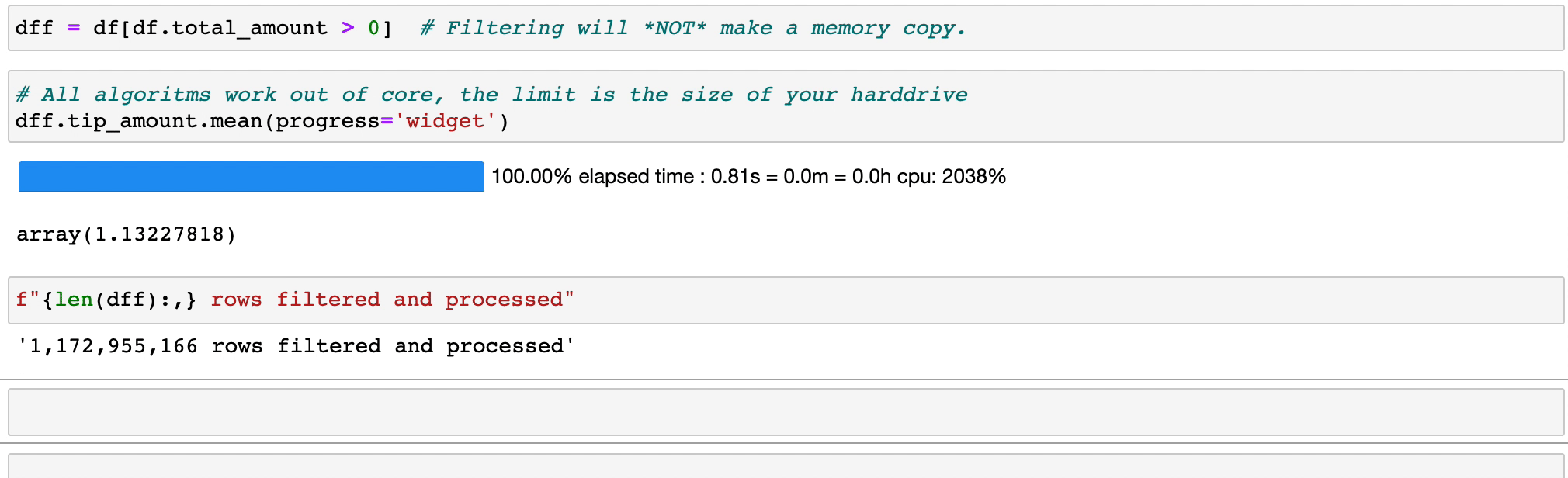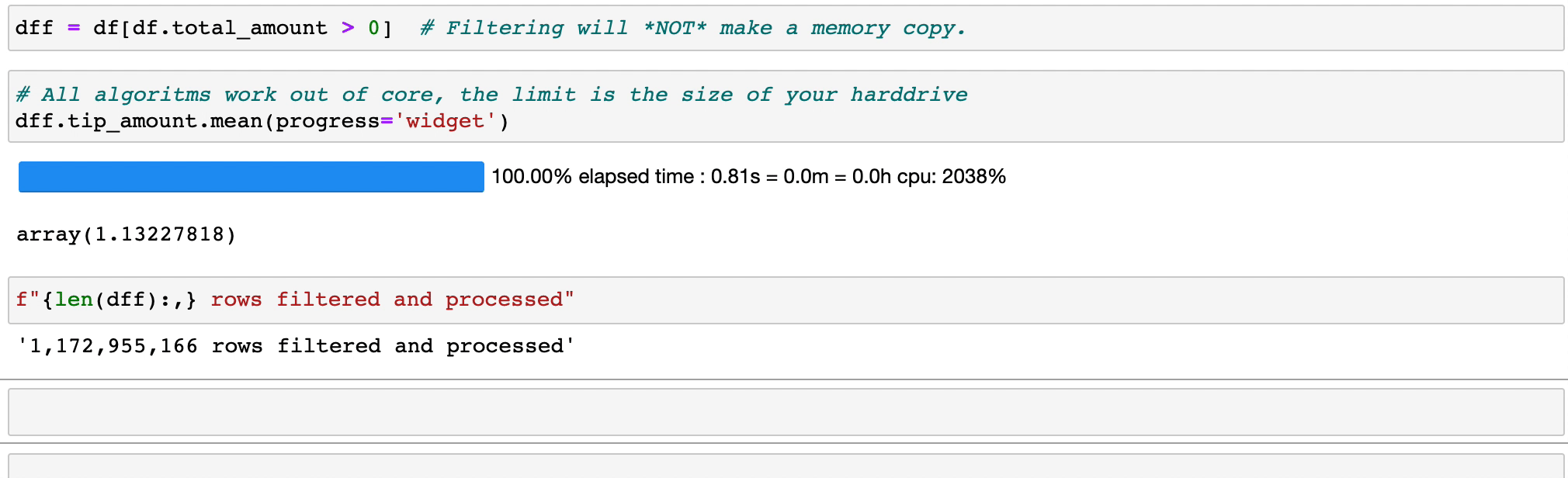
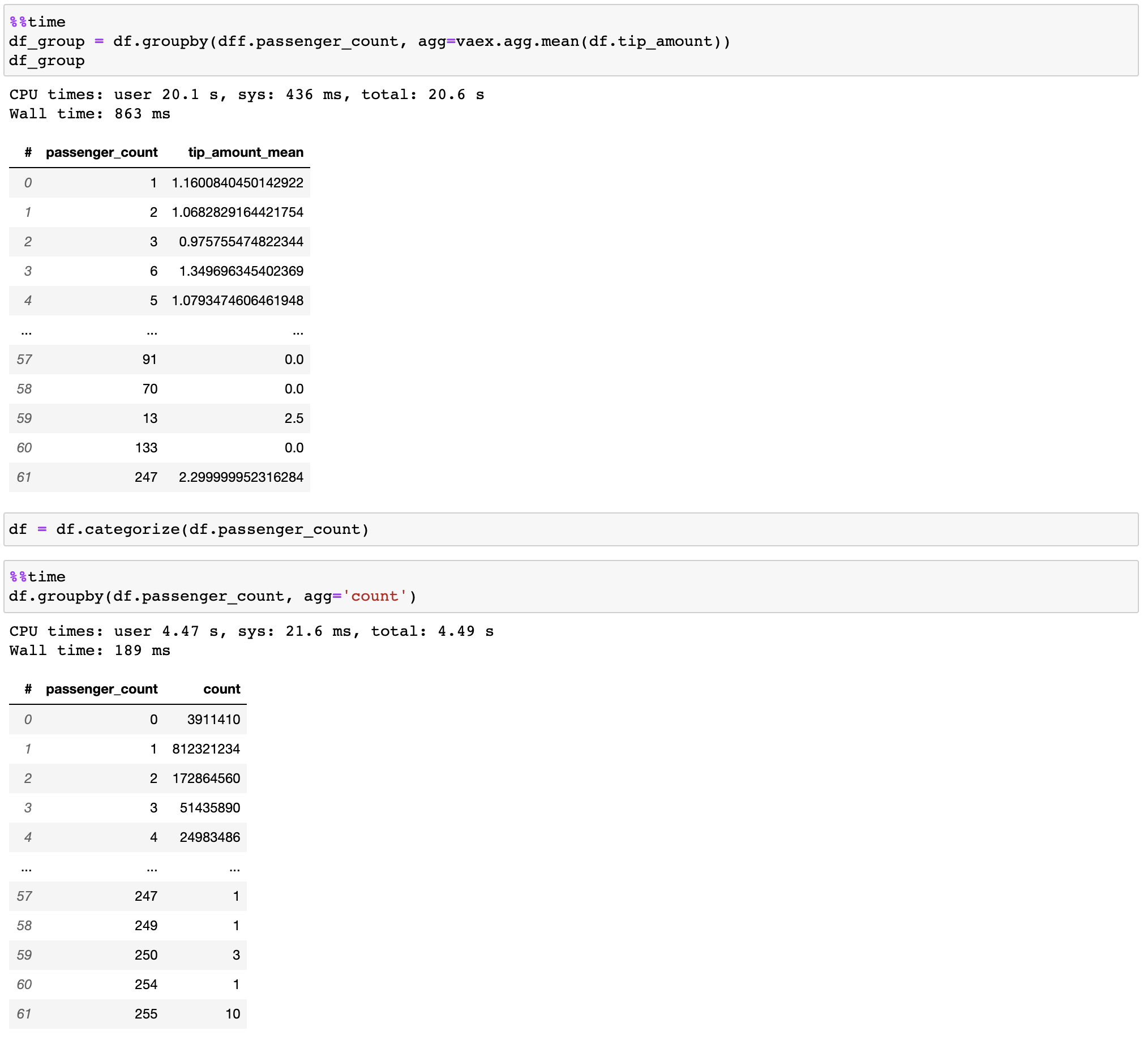
Vaex implementiert parallelisierte, hochleistungsfähige groupby -Operationen, insbesondere bei der Verwendung von Kategorien (>1 Milliarde/Sekunde).
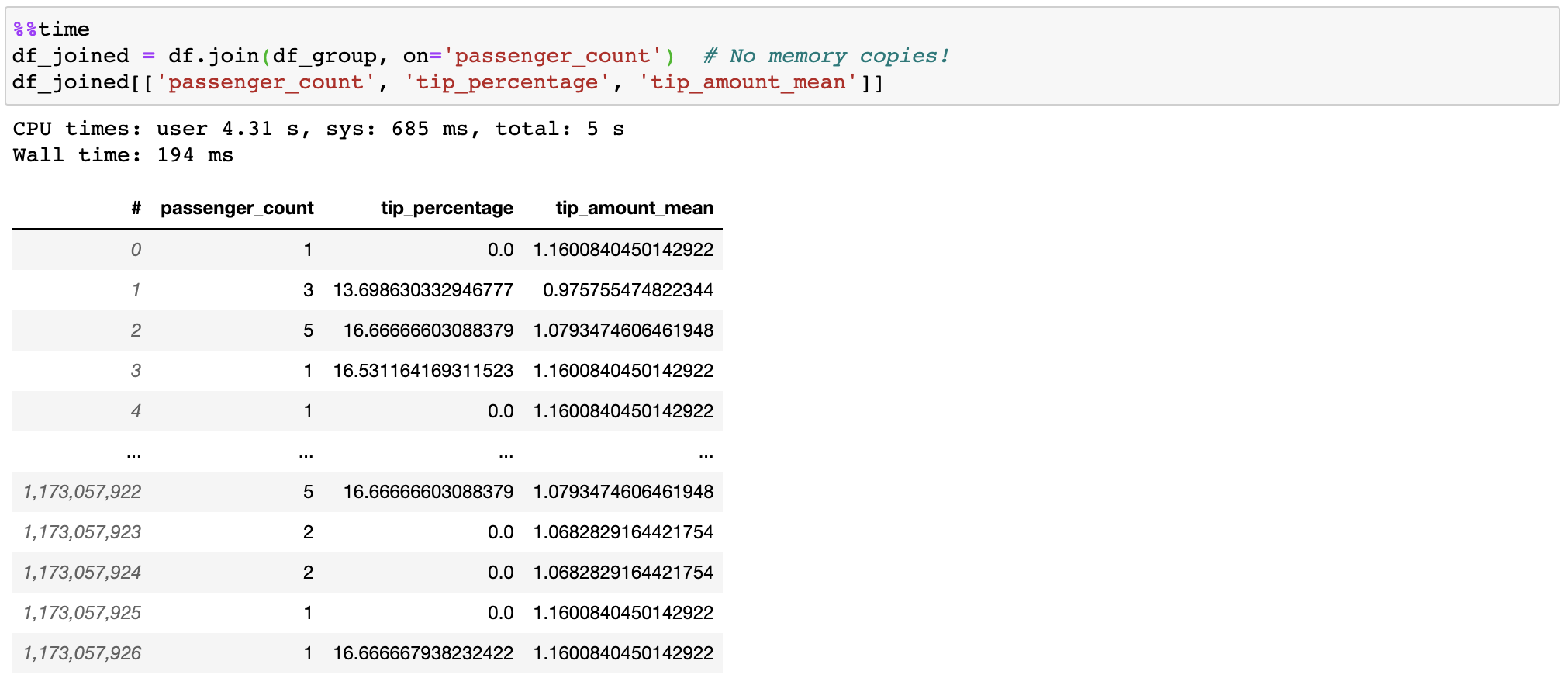
Vaex kopiert/materialisiert beim Beitritt nicht die „richtige“ Tabelle, wodurch Gigabyte an Speicher gespart werden. Mit der Verknüpfung von einer Milliarde Zeilen in Sekundenbruchteilen geht das ziemlich schnell!
Siehe Beitragsseite.
Beteiligen Sie sich an der Diskussion in unserem Slack-Kanal!
Artikel
Folgen Sie unseren Tutorials
Sehen Sie sich unsere neueren Vorträge an:
Kontaktieren Sie uns für Data-Science-Lösungen, Schulungen oder Unternehmensunterstützung unter https://vaex.io/


