stumpy
v1.13.0

STUMPY ist eine leistungsstarke und skalierbare Python-Bibliothek, die effizient etwas berechnet, das als Matrixprofil bezeichnet wird. Dies ist nur eine akademische Art zu sagen: „Identifizieren Sie für jede (grüne) Teilsequenz innerhalb Ihrer Zeitreihe automatisch den entsprechenden nächsten Nachbarn (grau)“:
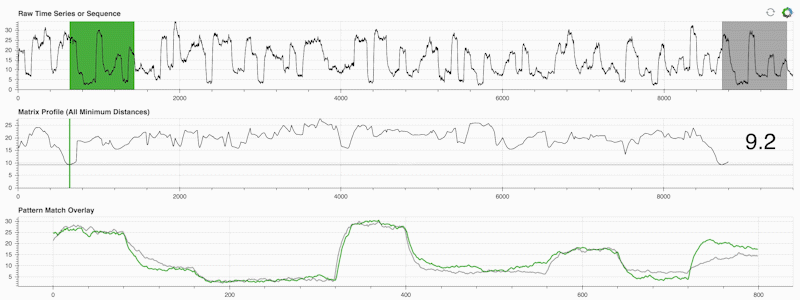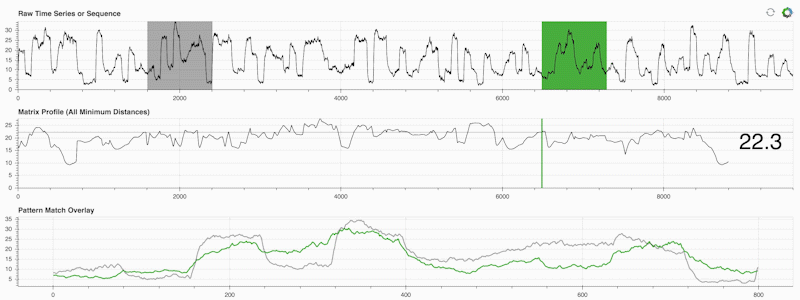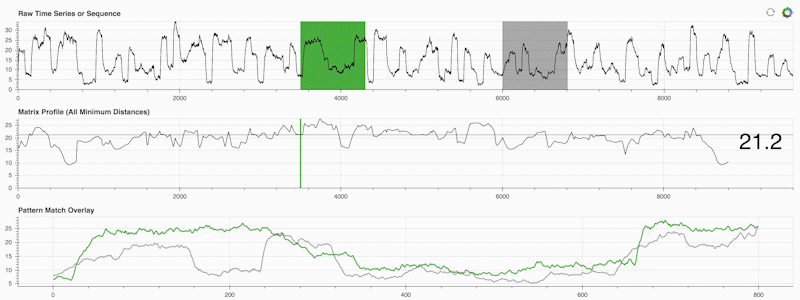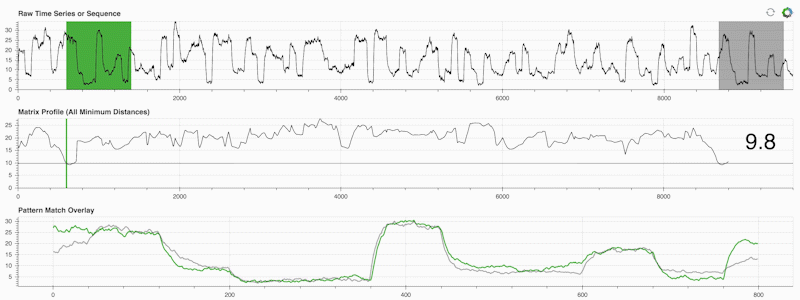
Wichtig ist, dass Ihr Matrixprofil (mittleres Feld oben) nach der Berechnung für eine Vielzahl von Zeitreihen-Data-Mining-Aufgaben verwendet werden kann, wie zum Beispiel:
Unabhängig davon, ob Sie Akademiker, Datenwissenschaftler, Softwareentwickler oder Zeitreihen-Enthusiast sind, STUMPY ist einfach zu installieren und unser Ziel ist es, Ihnen zu ermöglichen, schneller zu Ihren Zeitreihen-Erkenntnissen zu gelangen. Weitere Informationen finden Sie in der Dokumentation.
Eine vollständige Liste der verfügbaren Funktionen finden Sie in unserer API-Dokumentation. Ausführlichere Beispielanwendungsfälle finden Sie in unseren informativen Tutorials. Nachfolgend finden Sie Codeausschnitte, die die Verwendung von STUMPY schnell veranschaulichen.
Typische Verwendung (1-dimensionale Zeitreihendaten) mit STUMP:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )Verteilte Nutzung für eindimensionale Zeitreihendaten mit Dask, verteilt über STUMPED:
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stumped ( dask_client , your_time_series , m = window_size )GPU-Nutzung für eindimensionale Zeitreihendaten mit GPU-STUMP:
import stumpy
import numpy as np
from numba import cuda
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
all_gpu_devices = [ device . id for device in cuda . list_devices ()] # Get a list of all available GPU devices
matrix_profile = stumpy . gpu_stump ( your_time_series , m = window_size , device_id = all_gpu_devices )Mehrdimensionale Zeitreihendaten mit MSTUMP:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstump ( your_time_series , m = window_size )Verteilte mehrdimensionale Zeitreihendatenanalyse mit Dask Distributed MSTUMPED:
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstumped ( dask_client , your_time_series , m = window_size )Zeitreihenketten mit verankerten Zeitreihenketten (ATSC):
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
left_matrix_profile_index = matrix_profile [:, 2 ]
right_matrix_profile_index = matrix_profile [:, 3 ]
idx = 10 # Subsequence index for which to retrieve the anchored time series chain for
anchored_chain = stumpy . atsc ( left_matrix_profile_index , right_matrix_profile_index , idx )
all_chain_set , longest_unanchored_chain = stumpy . allc ( left_matrix_profile_index , right_matrix_profile_index )Semantische Segmentierung mit schneller, kostengünstiger unipotenter semantischer Segmentierung (FLUSS):
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
subseq_len = 50
correct_arc_curve , regime_locations = stumpy . fluss ( matrix_profile [:, 1 ],
L = subseq_len ,
n_regimes = 2 ,
excl_factor = 1
)Unterstützte Python- und NumPy-Versionen werden gemäß der NEP 29-Veraltungsrichtlinie bestimmt.
Conda-Installation (bevorzugt):
conda install -c conda-forge stumpyPyPI-Installation, vorausgesetzt, Sie haben Numpy, Scipy und Numba installiert:
python -m pip install stumpyUm Stumpy aus dem Quellcode zu installieren, lesen Sie die Anweisungen in der Dokumentation.
Um die zugrunde liegenden Algorithmen und Anwendungen vollständig zu verstehen und zu schätzen, ist es unbedingt erforderlich, dass Sie die Originalveröffentlichungen lesen. Ein detaillierteres Beispiel für die Verwendung von STUMPY finden Sie in der neuesten Dokumentation oder in unseren praktischen Tutorials.
Wir haben die Leistung der Berechnung des genauen Matrixprofils mithilfe der mit Numba JIT kompilierten Version des Codes an zufällig generierten Zeitreihendaten mit verschiedenen Längen (z. B. np.random.rand(n) ) zusammen mit unterschiedlichen CPU- und GPU-Hardwareressourcen getestet.
Die Rohergebnisse werden in der folgenden Tabelle als Stunden:Minuten:Sekunden.Millisekunden und mit einer konstanten Fenstergröße von m = 50 angezeigt. Beachten Sie, dass diese gemeldeten Laufzeiten die Zeit umfassen, die zum Verschieben der Daten vom Host auf alle benötigt wird GPU-Gerät(e). Möglicherweise müssen Sie zur rechten Seite der Tabelle scrollen, um alle Laufzeiten anzuzeigen.
| ich | n = 2 ich | GPU-STOMP | STUMPF.2 | STUMPF.16 | STUMPED.128 | STUMPED.256 | GPU-STUMP.1 | GPU-STUMP.2 | GPU-STUMP.DGX1 | GPU-STUMP.DGX2 |
|---|---|---|---|---|---|---|---|---|---|---|
| 6 | 64 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.77 | 00:00:06.08 | 00:00:00.03 | 00:00:01.63 | NaN | NaN |
| 7 | 128 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.93 | 00:00:07.29 | 00:00:00.04 | 00:00:01.66 | NaN | NaN |
| 8 | 256 | 00:00:10.00 | 00:00:00.00 | 00:00:00.01 | 00:00:05.95 | 00:00:07.59 | 00:00:00.08 | 00:00:01.69 | 00:00:06.68 | 00:00:25.68 |
| 9 | 512 | 00:00:10.00 | 00:00:00.00 | 00:00:00.02 | 00:00:05.97 | 00:00:07.47 | 00:00:00.13 | 00:00:01.66 | 00:00:06.59 | 00:00:27.66 |
| 10 | 1024 | 00:00:10.00 | 00:00:00.02 | 00:00:00.04 | 00:00:05.69 | 00:00:07.64 | 00:00:00.24 | 00:00:01.72 | 00:00:06.70 | 00:00:30.49 |
| 11 | 2048 | NaN | 00:00:00.05 | 00:00:00.09 | 00:00:05.60 | 00:00:07.83 | 00:00:00.53 | 00:00:01.88 | 00:00:06.87 | 00:00:31.09 |
| 12 | 4096 | NaN | 00:00:00.22 | 00:00:00.19 | 00:00:06.26 | 00:00:07.90 | 00:00:01.04 | 00:00:02.19 | 00:00:06.91 | 00:00:33,93 |
| 13 | 8192 | NaN | 00:00:00.50 | 00:00:00.41 | 00:00:06.29 | 00:00:07.73 | 00:00:01.97 | 00:00:02.49 | 00:00:06.61 | 00:00:33.81 |
| 14 | 16384 | NaN | 00:00:01.79 | 00:00:00,99 | 00:00:06.24 | 00:00:08.18 | 00:00:03.69 | 00:00:03.29 | 00:00:07.36 | 00:00:35.23 |
| 15 | 32768 | NaN | 00:00:06.17 | 00:00:02.39 | 00:00:06.48 | 00:00:08.29 | 00:00:07.45 | 00:00:04.93 | 00:00:07.02 | 00:00:36.09 |
| 16 | 65536 | NaN | 00:00:22.94 | 00:00:06.42 | 00:00:07.33 | 00:00:09.01 | 00:00:14.89 | 00:00:08.12 | 00:00:08.10 | 00:00:36.54 |
| 17 | 131072 | 00:00:10.00 | 00:01:29.27 | 00:00:19.52 | 00:00:09.75 | 00:00:10.53 | 00:00:29,97 | 00:00:15.42 | 00:00:09.45 | 00:00:37.33 |
| 18 | 262144 | 00:00:18.00 | 00:05:56.50 | 00:01:08.44 | 00:00:33.38 | 00:00:24.07 | 00:00:59.62 | 00:00:27.41 | 00:00:13.18 | 00:00:39.30 |
| 19 | 524288 | 00:00:46.00 | 00:25:34.58 | 00:03:56.82 | 00:01:35.27 | 00:03:43.66 | 00:01:56.67 | 00:00:54.05 | 00:00:19.65 | 00:00:41.45 |
| 20 | 1048576 | 00:02:30.00 | 01:51:13.43 | 00:19:54.75 | 00:04:37.15 | 00:03:01.16 | 00:05:06.48 | 00:02:24.73 | 00:00:32,95 | 00:00:46.14 |
| 21 | 2097152 | 00:09:15.00 | 09:25:47.64 | 03:05:07.64 | 00:13:36.51 | 00:08:47.47 | 00:20:27.94 | 00:09:41.43 | 00:01:06.51 | 00:01:02.67 |
| 22 | 4194304 | NaN | 36:12:23,74 | 10:37:51.21 | 00:55:44.43 | 00:32:06.70 | 01:21:12.33 | 00:38:30.86 | 00:04:03.26 | 00:02:23.47 |
| 23 | 8388608 | NaN | 143:16:09,94 | 38:42:51,42 | 03:33:30.53 | 02:00:49.37 | 05:11:44.45 | 02:33:14.60 | 00:15:46.26 | 00:08:03.76 |
| 24 | 16777216 | NaN | NaN | NaN | 14:39:11,99 | 07:13:47.12 | 20:43:03.80 | 09:48:43.42 | 01:00:24.06 | 00:29:07.84 |
| NaN | 17729800 | 09:16:12.00 | NaN | NaN | 15:31:31,75 | 07:18:42.54 | 23:09:22.43 | 10:54:08.64 | 01:07:35.39 | 00:32:51.55 |
| 25 | 33554432 | NaN | NaN | NaN | 56:03:46,81 | 26:27:41.29 | 83:29:21.06 | 39:17:43,82 | 03:59:32,79 | 01:54:56,52 |
| 26 | 67108864 | NaN | NaN | NaN | 211:17:37,60 | 106:40:17.17 | 328:58:04,68 | 157:18:30,50 | 15:42:15.94 | 07:18:52,91 |
| NaN | 100000000 | 291:07:12.00 | NaN | NaN | NaN | 234:51:35,39 | NaN | NaN | 35:03:44,61 | 16:22:40,81 |
| 27 | 134217728 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 64:41:55.09 | 29:13:48.12 |
GPU-STOMP: Diese Ergebnisse stammen aus dem Originalpapier zu Matrix Profile II – NVIDIA Tesla K80 (enthält 2 GPUs) und dienen als Leistungsbenchmark zum Vergleich.
STUMP.2: stumpy.stump wurde mit insgesamt 2 CPUs ausgeführt – 2x Intel(R) Xeon(R) CPU E5-2650 v4 @ 2,20 GHz Prozessoren parallelisiert mit Numba auf einem einzelnen Server ohne Dask.
STUMP.16: stumpy.stump wurde mit insgesamt 16 CPUs ausgeführt – 16x Intel(R)
STUMPED.128: stumpy.stumped wurde mit insgesamt 128 CPUs ausgeführt – 8x Intel(R)
STUMPED.256: stumpy.stumped wurde mit insgesamt 256 CPUs ausgeführt – 8x Intel(R)
GPU-STUMP.1: stumpy.gpu_stump, ausgeführt mit 1x NVIDIA GeForce GTX 1080 Ti GPU, 512 Threads pro Block, 200 W Leistungsbegrenzung, mit Numba zu CUDA kompiliert und mit Python-Multiprocessing parallelisiert
GPU-STUMP.2: stumpy.gpu_stump, ausgeführt mit 2x NVIDIA GeForce GTX 1080 Ti GPU, 512 Threads pro Block, 200 W Leistungsbegrenzung, mit Numba zu CUDA kompiliert und mit Python-Multiprocessing parallelisiert
GPU-STUMP.DGX1: stumpy.gpu_stump, ausgeführt mit 8x NVIDIA Tesla V100, 512 Threads pro Block, mit Numba zu CUDA kompiliert und mit Python-Multiprocessing parallelisiert
GPU-STUMP.DGX2: stumpy.gpu_stump, ausgeführt mit 16x NVIDIA Tesla V100, 512 Threads pro Block, mit Numba zu CUDA kompiliert und mit Python-Multiprocessing parallelisiert
Tests werden im tests geschrieben und mit PyTest verarbeitet und erfordern coverage.py für die Code-Coverage-Analyse. Tests können durchgeführt werden mit:
./test.shSTUMPY unterstützt Python 3.9+ und ist aufgrund der Verwendung von Unicode-Variablennamen/-Identifikatoren nicht mit Python 2.x kompatibel. Aufgrund der geringen Abhängigkeiten funktioniert STUMPY möglicherweise auf älteren Versionen von Python, dies liegt jedoch außerhalb des Rahmens unseres Supports und wir empfehlen Ihnen dringend, ein Upgrade auf die neueste Version von Python durchzuführen.
Bitte prüfen Sie zunächst die Diskussionen und Issues auf Github, um zu sehen, ob Ihre Frage dort bereits beantwortet wurde. Wenn dort keine Lösung verfügbar ist, können Sie gerne eine neue Diskussion oder ein neues Problem eröffnen. Die Autoren werden versuchen, zeitnah zu antworten.
Wir freuen uns über Beiträge in jeglicher Form! Hilfe bei der Dokumentation, insbesondere bei der Erweiterung von Tutorials, ist immer willkommen. Um einen Beitrag zu leisten, forken Sie bitte das Projekt, nehmen Sie Ihre Änderungen vor und senden Sie eine Pull-Anfrage. Wir werden unser Bestes tun, um etwaige Probleme mit Ihnen zu lösen und Ihren Code in den Hauptzweig einzubinden.
Wenn Sie diese Codebasis in einer wissenschaftlichen Veröffentlichung verwendet haben und sie zitieren möchten, verwenden Sie bitte den Artikel im Journal of Open Source Software.
SM Law, (2019). STUMPY: Eine leistungsstarke und skalierbare Python-Bibliothek für Time Series Data Mining . Journal of Open Source Software, 4(39), 1504.
@article { law2019stumpy ,
author = { Law, Sean M. } ,
title = { {STUMPY: A Powerful and Scalable Python Library for Time Series Data Mining} } ,
journal = { {The Journal of Open Source Software} } ,
volume = { 4 } ,
number = { 39 } ,
pages = { 1504 } ,
year = { 2019 }
}Yeh, Chin-Chia Michael et al. (2016) Matrixprofil I: Ähnlichkeitsverknüpfungen aller Paare für Zeitreihen: Eine vereinheitlichende Sicht, die Motive, Discords und Shapelets umfasst. ICDM:1317-1322. Link
Zhu, Yan et al. (2016) Matrix Profile II: Nutzung eines neuartigen Algorithmus und von GPUs, um die Hundert-Millionen-Grenze für Zeitreihenmotive und -verbindungen zu durchbrechen. ICDM:739-748. Link
Yeh, Chin-Chia Michael et al. (2017) Matrixprofil VI: Sinnvolle mehrdimensionale Motiventdeckung. ICDM:565-574. Link
Zhu, Yan et al. (2017) Matrixprofil VII: Time Series Chains: A New Primitive for Time Series Data Mining. ICDM:695-704. Link
Gharghabi, Shaghayegh et al. (2017) Matrixprofil VIII: Domain Agnostic Online Semantic Segmentation at Superhuman Performance Levels. ICDM:117-126. Link
Zhu, Yan et al. (2017) Nutzung eines neuartigen Algorithmus und von GPUs, um die Barriere von zehn Billiarden paarweisen Vergleichen für Zeitreihenmotive und -verknüpfungen zu durchbrechen. KAIS:203-236. Link
Zhu, Yan et al. (2018) Matrix Profile XI: SCRIMP++: Time Series Motif Discovery at Interactive Speeds. ICDM:837-846. Link
Yeh, Chin-Chia Michael et al. (2018) Time Series Joins, Motifs, Discords and Shapelets: eine einheitliche Sichtweise, die das Matrixprofil nutzt. Data Min Knowl Disc:83-123. Link
Gharghabi, Shaghayegh et al. (2018) „Matrixprofil XII: MPdist: Ein neuartiges Zeitreihen-Entfernungsmaß, um Data Mining in anspruchsvolleren Szenarien zu ermöglichen.“ ICDM:965-970. Link
Zimmerman, Zachary et al. (2019) Matrix Profile SoCC '19:74-86. Link
Akbarinia, Reza und Betrand Cloez. (2019) Effiziente Matrixprofilberechnung unter Verwendung verschiedener Abstandsfunktionen. arXiv:1901.05708. Link
Kamgar, Kaveh et al. (2019) Matrixprofil XV: Nutzung von Konsensmotiven für Zeitreihen, um Strukturen in Zeitreihensätzen zu finden. ICDM:1156-1161. Link


