memray
v1.15.0
Memray ist ein Speicherprofiler für Python. Es kann Speicherzuweisungen im Python-Code, in nativen Erweiterungsmodulen und im Python-Interpreter selbst verfolgen. Es können verschiedene Arten von Berichten erstellt werden, die Ihnen bei der Analyse der erfassten Speichernutzungsdaten helfen. Während es häufig als CLI-Tool verwendet wird, kann es auch als Bibliothek zur Durchführung detaillierterer Profilierungsaufgaben verwendet werden.
Bemerkenswerte Merkmale:
Memray kann bei folgenden Problemen helfen:
Hinweis: Memray funktioniert nur unter Linux und MacOS und kann nicht auf anderen Plattformen installiert werden.
Wir sind ständig auf der Suche nach Feedback von unserer großartigen Community ❤️. Wenn Sie Memray verwendet haben, um ein Problem zu lösen, ein Anwendungsprofil zu erstellen, einen Speicherverlust zu finden oder etwas anderes, lassen Sie es uns bitte wissen! Wir würden gerne von Ihren Erfahrungen hören und erfahren, wie Memray Ihnen geholfen hat.
Bitte denken Sie darüber nach, Ihre Geschichte auf der Diskussionsseite „Erfolgsgeschichten“ zu schreiben.
Es macht wirklich einen Unterschied!
Memray erfordert Python 3.7+ und kann mit den meisten gängigen Python-Paketierungstools einfach installiert werden. Wir empfehlen, die neueste stabile Version von PyPI mit pip zu installieren:
python3 -m pip install memrayBeachten Sie, dass Memray eine C-Erweiterung enthält, sodass Releases sowohl als Binärräder als auch als Quellcode verteilt werden. Wenn für Ihr System (Linux x86/x64 oder macOS) kein Binärrad verfügbar ist, müssen Sie sicherstellen, dass alle Abhängigkeiten auf dem System erfüllt sind, auf dem Sie die Installation durchführen.
Wenn Sie Memray aus dem Quellcode erstellen möchten, benötigen Sie die folgenden binären Abhängigkeiten in Ihrem System:
Überprüfen Sie in Ihrem Paketmanager, wie Sie diese Abhängigkeiten installieren (z. B. apt-get install build-essential python3-dev libdebuginfod-dev libunwind-dev liblz4-dev in Debian-basierten Systemen oder brew install lz4 in MacOS). Beachten Sie, dass Sie dem Compiler möglicherweise beibringen müssen, wo sich die Header- und Bibliotheksdateien der Abhängigkeiten befinden. Beispielsweise müssen Sie unter MacOS mit brew möglicherweise Folgendes ausführen:
export CFLAGS= " -I $( brew --prefix lz4 ) /include " LDFLAGS= " -L $( brew --prefix lz4 ) /lib -Wl,-rpath, $( brew --prefix lz4 ) /lib " vor der Installation memray . Weitere Informationen finden Sie in der Dokumentation Ihres Paketmanagers, um den Speicherort der Header- und Bibliotheksdateien zu erfahren.
Wenn Sie auf MacOS bauen, müssen Sie auch das Bereitstellungsziel festlegen.
export MACOSX_DEPLOYMENT_TARGET=10.14Sobald Sie die binären Abhängigkeiten installiert haben, können Sie das Repository klonen und mit dem normalen Erstellungsprozess fortfahren:
git clone [email protected]:bloomberg/memray.git memray
cd memray
python3 -m venv ../memray-env/ # just an example, put this wherever you want
source ../memray-env/bin/activate
python3 -m pip install --upgrade pip
python3 -m pip install -e . -r requirements-test.txt -r requirements-extra.txt Dadurch wird Memray in der virtuellen Umgebung im Entwicklungsmodus installiert (das -e des letzten pip install Installationsbefehls).
Wenn Sie einen Beitrag leisten möchten, sollten Sie die Pre-Commit-Hooks installieren:
pre-commit installDadurch wird sichergestellt, dass Ihr Beitrag unsere Flusenprüfungen besteht.
Die aktuellste verfügbare Dokumentation finden Sie hier.
Es gibt viele Möglichkeiten, Memray zu verwenden. Am einfachsten ist es, es als Befehlszeilentool zum Ausführen Ihres Skripts, Ihrer Anwendung oder Ihrer Bibliothek zu verwenden.
usage: memray [-h] [-v] {run,flamegraph,table,live,tree,parse,summary,stats} ...
Memory profiler for Python applications
Run `memray run` to generate a memory profile report, then use a reporter command
such as `memray flamegraph` or `memray table` to convert the results into HTML.
Example:
$ python3 -m memray run -o output.bin my_script.py
$ python3 -m memray flamegraph output.bin
positional arguments:
{run,flamegraph,table,live,tree,parse,summary,stats}
Mode of operation
run Run the specified application and track memory usage
flamegraph Generate an HTML flame graph for peak memory usage
table Generate an HTML table with all records in the peak memory usage
live Remotely monitor allocations in a text-based interface
tree Generate a tree view in the terminal for peak memory usage
parse Debug a results file by parsing and printing each record in it
summary Generate a terminal-based summary report of the functions that allocate most memory
stats Generate high level stats of the memory usage in the terminal
optional arguments:
-h, --help Show this help message and exit
-v, --verbose Increase verbosity. Option is additive and can be specified up to 3 times
-V, --version Displays the current version of Memray
Please submit feedback, ideas, and bug reports by filing a new issue at https://github.com/bloomberg/memray/issues
Um Memray über ein Skript oder eine einzelne Python-Datei zu verwenden, können Sie Folgendes verwenden:
python3 -m memray run my_script.py Wenn Sie Ihre Anwendung normalerweise mit python3 -m my_module ausführen, können Sie das Flag -m mit memray run verwenden:
python3 -m memray run -m my_module Sie können Memray auch als Befehlszeilentool aufrufen, ohne -m verwenden zu müssen, um es als Modul aufzurufen:
memray run my_script.py
memray run -m my_module Die Ausgabe ist eine Binärdatei (wie memray-my_script.2369.bin ), die Sie auf verschiedene Arten analysieren können. Eine Möglichkeit besteht darin, den Befehl memray flamegraph zu verwenden, um ein Flammendiagramm zu erstellen:
memray flamegraph my_script.2369.binDadurch wird eine HTML-Datei mit einem Flammendiagramm der Speichernutzung erstellt, das Sie mit Ihrem bevorzugten Browser überprüfen können. Es gibt mehrere andere Reporter, mit denen Sie andere Arten von Berichten erstellen können. Einige davon generieren terminalbasierte Ausgaben und andere generieren HTML-Dateien. Hier ist ein Beispiel für einen Memray-Flammengraphen:
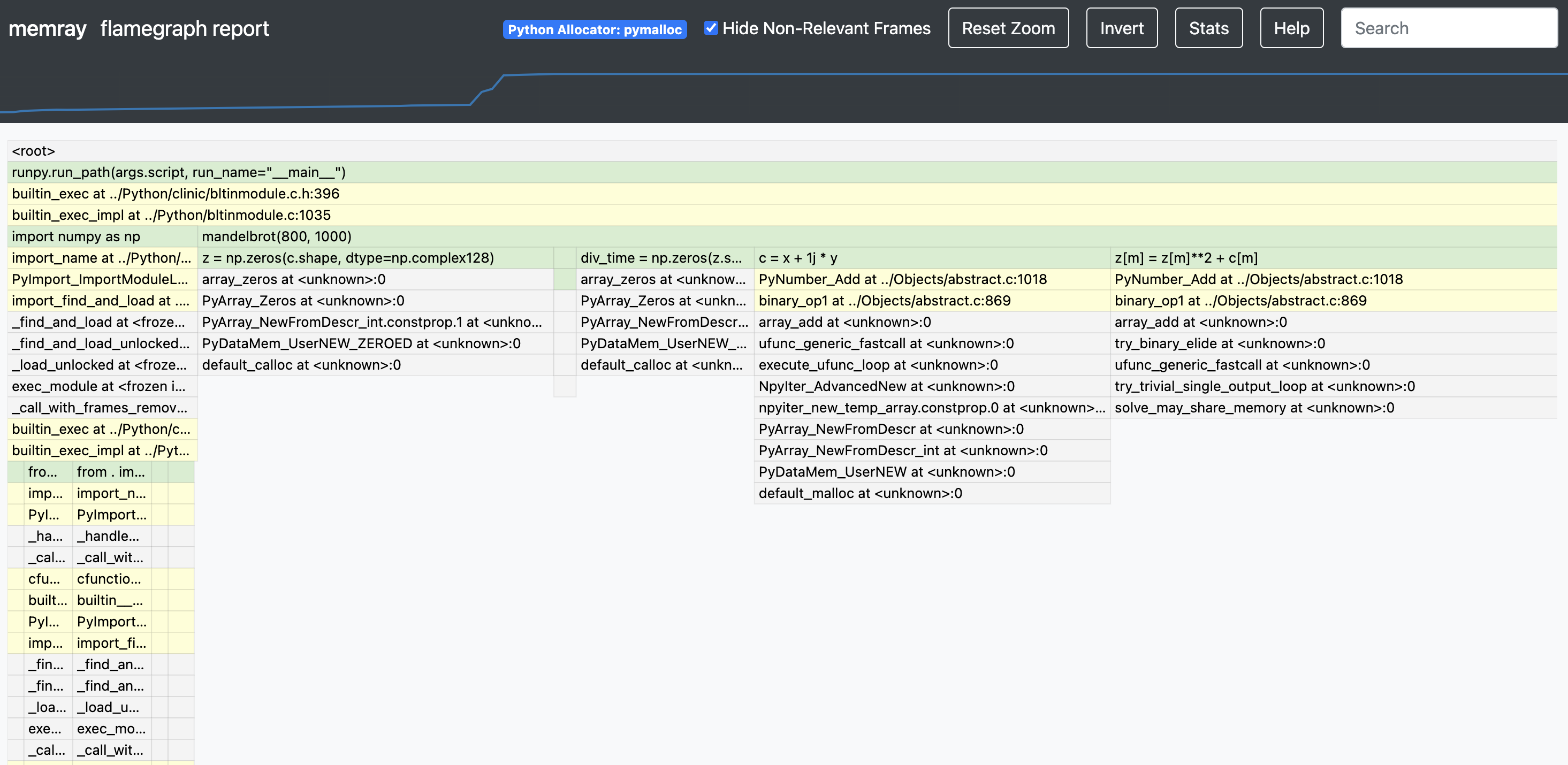
Wenn Sie memray in Ihrer Testsuite einfach und bequem verwenden möchten, können Sie die Verwendung von pytest-memray in Betracht ziehen. Nach der Installation können Sie mit diesem Pytest-Plugin einfach --memray zum Befehlszeilenaufruf hinzufügen:
pytest --memray tests/Und Sie erhalten automatisch einen Bericht wie diesen:
python3 -m pytest tests --memray
=============================================================================================================================== test session starts ================================================================================================================================
platform linux -- Python 3.8.10, pytest-6.2.4, py-1.10.0, pluggy-0.13.1
rootdir: /mypackage, configfile: pytest.ini
plugins: cov-2.12.0, memray-0.1.0
collected 21 items
tests/test_package.py ..................... [100%]
================================================================================================================================= MEMRAY REPORT ==================================================================================================================================
Allocations results for tests/test_package.py::some_test_that_allocates
? Total memory allocated: 24.4MiB
? Total allocations: 33929
Histogram of allocation sizes: |▂ █ |
? Biggest allocating functions:
- parse:/opt/bb/lib/python3.8/ast.py:47 -> 3.0MiB
- parse:/opt/bb/lib/python3.8/ast.py:47 -> 2.3MiB
- _visit:/opt/bb/lib/python3.8/site-packages/astroid/transforms.py:62 -> 576.0KiB
- parse:/opt/bb/lib/python3.8/ast.py:47 -> 517.6KiB
- __init__:/opt/bb/lib/python3.8/site-packages/astroid/node_classes.py:1353 -> 512.0KiB
Sie können einige der enthaltenen Markierungen auch verwenden, um Tests fehlschlagen zu lassen, wenn bei der Ausführung des Tests mehr Speicher als zulässig zugewiesen wird:
@ pytest . mark . limit_memory ( "24 MB" )
def test_foobar ():
# do some stuff that allocates memoryWeitere Informationen zur Verwendung und Konfiguration des Plugins finden Sie in der Plugin-Dokumentation.
Memray unterstützt die Verfolgung nativer C/C++-Funktionen sowie Python-Funktionen. Dies kann besonders nützlich sein, wenn ein Profil für Anwendungen erstellt wird, die über C-Erweiterungen verfügen (z. B. numpy oder pandas ), da dies eine ganzheitliche Vorstellung davon liefert, wie viel Speicher von der Erweiterung und wie viel von Python selbst zugewiesen wird.
Um das native Tracking zu aktivieren, müssen Sie das Argument --native angeben, wenn Sie den Unterbefehl run verwenden:
memray run --native my_script.pyDadurch werden der Ergebnisdatei automatisch native Informationen hinzugefügt und diese werden automatisch von jedem Reporter (z. B. Flamegraph oder Tabellenreporter) verwendet. Das bedeutet, dass, anstatt dies in den Flamegraphen zu sehen:
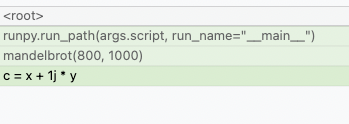
Sie können nun sehen, was in den Python-Aufrufen passiert:

Reporter zeigen native Frames in einer anderen Farbe an als Python-Frames. Sie können auch anhand des Dateispeicherorts in einem Frame unterschieden werden (Python-Frames werden im Allgemeinen aus Dateien mit der Erweiterung .py generiert, während native Frames aus Dateien mit Erweiterungen wie .c, .cpp oder .h generiert werden).
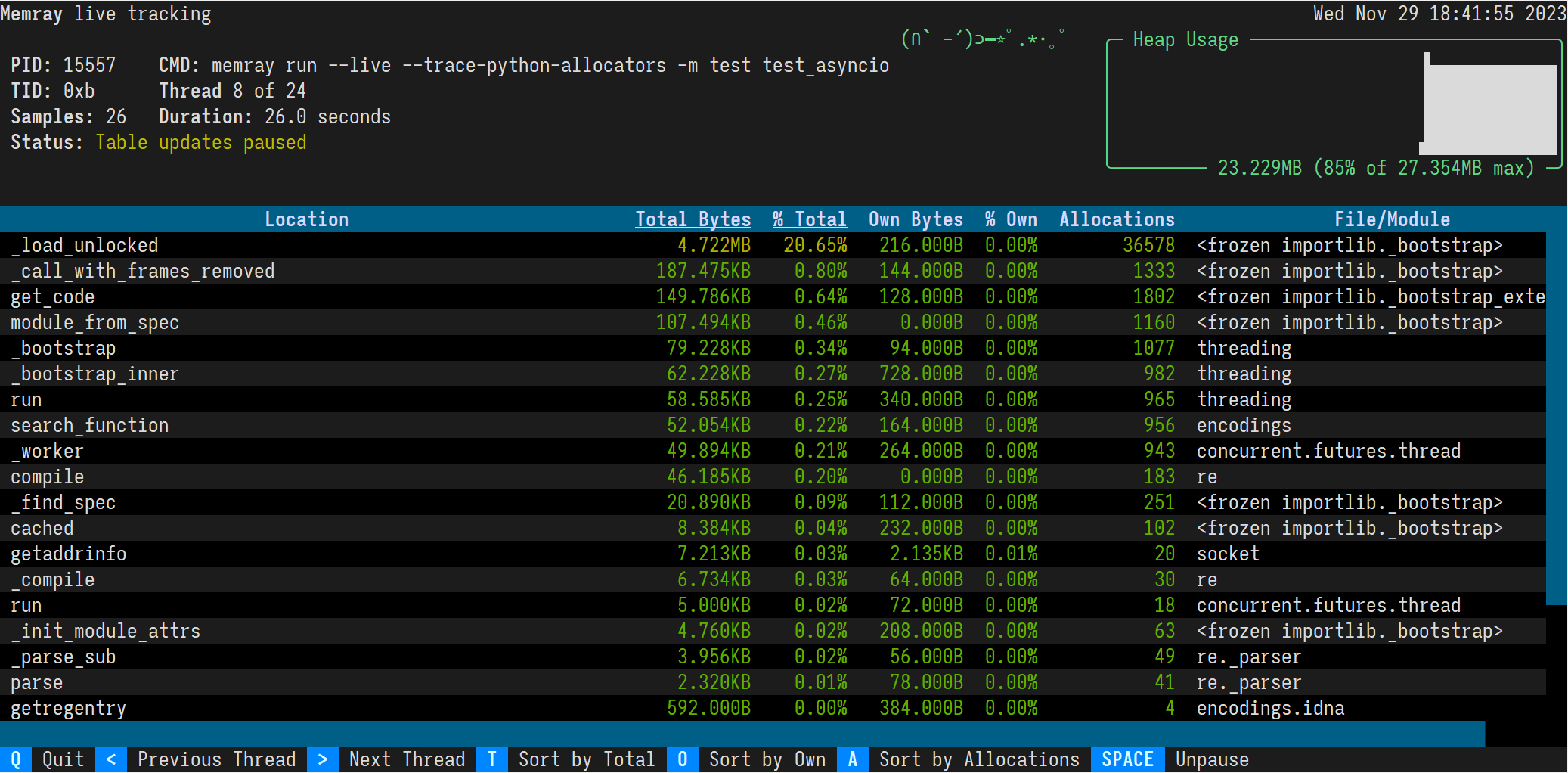
Im Live-Modus von Memray wird ein Skript oder ein Modul in einer terminalbasierten Schnittstelle ausgeführt, mit der Sie die Speichernutzung während der Ausführung interaktiv überprüfen können. Dies ist nützlich zum Debuggen von Skripten oder Modulen, deren Ausführung lange dauert oder die mehrere komplexe Speichermuster aufweisen. Mit der Option --live können Sie das Skript oder Modul im Live-Modus ausführen:
memray run --live my_script.pyoder wenn Sie ein Modul ausführen möchten:
memray run --live -m my_moduleDadurch wird die folgende TUI-Oberfläche in Ihrem Terminal angezeigt:
Die Ergebnisse werden in absteigender Reihenfolge des von einer Funktion zugewiesenen Gesamtspeichers und der von ihr aufgerufenen Unterfunktionen angezeigt. Sie können die Reihenfolge mit den folgenden Tastaturkürzeln ändern:
t (Standard): Nach Gesamtspeicher sortieren
o: Sortierung nach eigenem Speicher
a: Nach Zuordnungsanzahl sortieren
In den meisten Terminals können Sie auch auf die Schaltflächen „Nach Gesamt sortieren“, „Nach Eigenen sortieren“ und „Nach Zuweisungen sortieren“ in der Fußzeile klicken.
Die Überschrift der sortierten Spalte ist unterstrichen.
Standardmäßig präsentiert der Live-Befehl den Hauptthread des Programms. Sie können sich verschiedene Threads des Programms ansehen, indem Sie die Tasten „Größer als“ und „Kleiner als“ ( < und > drücken. In den meisten Terminals können Sie auch auf die Schaltflächen „Vorheriger Thread“ und „Nächster Thread“ in der Fußzeile klicken.
Neben der Verfolgung von Python-Prozessen über eine CLI mit memray run ist es auch möglich, die Verfolgung innerhalb eines laufenden Python-Programms programmgesteuert zu aktivieren.
import memray
with memray . Tracker ( "output_file.bin" ):
print ( "Allocations will be tracked until the with block ends" )Einzelheiten finden Sie in der API-Dokumentation.
Memray ist für Apache-2.0 lizenziert, wie in der LICENSE-Datei zu finden ist.
Dieses Projekt hat einen Verhaltenskodex verabschiedet. Wenn Sie Bedenken bezüglich des Kodex oder Verhaltensweisen haben, die Sie im Projekt erlebt haben, kontaktieren Sie uns bitte unter [email protected].
Wenn Sie glauben, eine Sicherheitslücke in diesem Projekt identifiziert zu haben, senden Sie bitte eine E-Mail an das Projektteam unter [email protected] und beschreiben Sie dabei das vermutete Problem und alle Methoden, die Sie gefunden haben, um es zu reproduzieren.
Bitte öffnen Sie KEIN Problem im GitHub-Repository, da wir Schwachstellenberichte lieber geheim halten möchten, bis wir Gelegenheit hatten, sie zu prüfen und zu beheben.
Wir freuen uns über Ihre Beiträge, die uns helfen, dieses Projekt zu verbessern und zu erweitern!
Nachfolgend finden Sie einige grundlegende Schritte, die erforderlich sind, um zum Projekt beitragen zu können. Wenn Sie Fragen zu diesem Prozess oder einem anderen Aspekt der Mitarbeit an einem Bloomberg-Open-Source-Projekt haben, senden Sie gerne eine E-Mail an [email protected] und wir werden Ihre Fragen so schnell wie möglich beantworten.
Da dieses Projekt unter den Bedingungen einer Open-Source-Lizenz vertrieben wird, unterliegen die von Ihnen geleisteten Beiträge den gleichen Bedingungen. Damit wir Ihre Beiträge annehmen können, benötigen wir eine ausdrückliche Bestätigung von Ihnen, dass Sie in der Lage und bereit sind, diese gemäß diesen Bedingungen bereitzustellen. Der Mechanismus, den wir hierfür verwenden, wird als „Developer's Certificate of Origin“ (DCO) bezeichnet. . Dies ist dem Prozess sehr ähnlich, der vom Linux-Kernel, Samba und vielen anderen großen Open-Source-Projekten verwendet wird.
Um gemäß diesen Bedingungen teilzunehmen, müssen Sie lediglich eine Zeile wie die folgende als letzte Zeile der Commit-Nachricht für jeden Commit in Ihrem Beitrag einfügen:
Signed-Off-By: Random J. Developer <[email protected]>
Der einfachste Weg, dies zu erreichen, besteht darin -s oder --signoff zu Ihrem git commit -Befehl hinzuzufügen.
Sie müssen Ihren richtigen Namen verwenden (leider keine Pseudonyme und keine anonymen Beiträge).


