similarity
1.1.6
Ähnlichkeit, Ähnlichkeitswert zwischen Textzeichenfolgen berechnen, in Java geschrieben.
Similarity, ein Toolkit zur Ähnlichkeitsberechnung, kann für die Textähnlichkeitsberechnung, Stimmungsanalyse usw. verwendet werden und ist in Java geschrieben.
Similarity ist eine Java-Version des Ähnlichkeitsberechnungs-Toolkits, das aus einer Reihe von Algorithmen besteht. Ziel ist es, die Ähnlichkeitsberechnungsmethode in der Verarbeitung natürlicher Sprache zu verbreiten. Ähnlichkeit zeichnet sich durch praktische Werkzeuge, effiziente Leistung, klare Struktur, aktuellen Korpus und Anpassbarkeit aus.
Ähnlichkeit bietet die folgende Funktionalität:
Berechnung der Wortähnlichkeit
Berechnung der Phrasenähnlichkeit
Berechnung der Satzähnlichkeit
Berechnung der Absatzähnlichkeit
CNKI Yiyuan
Stimmungsanalyse
Ungefähre Wörter
Während die internen Module von Similarity umfangreiche Funktionen bieten, bestehen sie auf einer geringen Kopplung, Modelle bestehen auf verzögertem Laden und Wörterbücher bestehen auf der Veröffentlichung im Klartext. Sie sind einfach zu verwenden und helfen Benutzern, ihre eigenen Korpora zu trainieren.
Stellen Sie das Jar-Paket vor
< repositories >
< repository >
< id >jitpack.io</ id >
< url >https://jitpack.io</ url >
</ repository >
</ repositories >< dependency >
< groupId >com.github.shibing624</ groupId >
< artifactId >similarity</ artifactId >
< version >1.1.6</ version >
</ dependency >Einführung von Gradle:
import org . xm . Similarity ;
import org . xm . tendency . word . HownetWordTendency ;
public class demo {
public static void main ( String [] args ) {
double result = Similarity . cilinSimilarity ( "电动车" , "自行车" );
System . out . println ( result );
String word = "混蛋" ;
HownetWordTendency hownetWordTendency = new HownetWordTendency ();
result = hownetWordTendency . getTendency ( word );
System . out . println ( word + " 词语情感趋势值:" + result );
}
}Textlänge: Wortgranularität
Es wird empfohlen, die Cilin-Ähnlichkeit zu verwenden: org.xm.Similarity.cilinSimilarity , eine Ähnlichkeitsberechnungsmethode, die auf den Cilin-Synonymen basiert
Beispiel: src/test/java/org.xm/WordSimilarityDemo.java
package org . xm ;
public class WordSimilarityDemo {
public static void main ( String [] args ) {
String word1 = "教师" ;
String word2 = "教授" ;
double cilinSimilarityResult = Similarity . cilinSimilarity ( word1 , word2 );
double pinyinSimilarityResult = Similarity . pinyinSimilarity ( word1 , word2 );
double conceptSimilarityResult = Similarity . conceptSimilarity ( word1 , word2 );
double charBasedSimilarityResult = Similarity . charBasedSimilarity ( word1 , word2 );
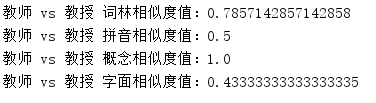
System . out . println ( word1 + " vs " + word2 + " 词林相似度值:" + cilinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 拼音相似度值:" + pinyinSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 概念相似度值:" + conceptSimilarityResult );
System . out . println ( word1 + " vs " + word2 + " 字面相似度值:" + charBasedSimilarityResult );
}
}
Textlänge: Phrasengranularität
Es wird empfohlen, Phrasenähnlichkeit zu verwenden: org.xm.Similarity.phraseSimilarity , bei der es sich im Wesentlichen um eine Methode zur Berechnung der Ähnlichkeit zweier Phrasen anhand derselben Zeichen und der Positionen derselben Zeichen handelt.
Beispiel: src/test/java/org.xm/PhraseSimilarityDemo.java
public static void main ( String [] args ) {
String phrase1 = "继续努力" ;
String phrase2 = "持续发展" ;
double result = Similarity . phraseSimilarity ( phrase1 , phrase2 );
System . out . println ( phrase1 + " vs " + phrase2 + " 短语相似度值:" + result );
}
Textlänge: Satzgranularität
Es wird empfohlen, Satzähnlichkeit in Wortform und Wortreihenfolge zu verwenden: org.xm.similarity.morphoSimilarity , eine Ähnlichkeitsmethode, die nicht nur das gleiche Textliteral zweier Sätze berücksichtigt, sondern auch die Reihenfolge, in der der gleiche Text erscheint.
Beispiel: src/test/java/org.xm/SentenceSimilarityDemo.java
public static void main ( String [] args ) {
String sentence1 = "中国人爱吃鱼" ;
String sentence2 = "湖北佬最喜吃鱼" ;
double morphoSimilarityResult = Similarity . morphoSimilarity ( sentence1 , sentence2 );
double editDistanceResult = Similarity . editDistanceSimilarity ( sentence1 , sentence2 );
double standEditDistanceResult = Similarity . standardEditDistanceSimilarity ( sentence1 , sentence2 );
double gregeorEditDistanceResult = Similarity . gregorEditDistanceSimilarity ( sentence1 , sentence2 );
System . out . println ( sentence1 + " vs " + sentence2 + " 词形词序句子相似度值:" + morphoSimilarityResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 优化的编辑距离句子相似度值:" + editDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " 标准编辑距离句子相似度值:" + standEditDistanceResult );
System . out . println ( sentence1 + " vs " + sentence2 + " gregeor编辑距离句子相似度值:" + gregeorEditDistanceResult );
}
Textlänge: Absatzgranularität (ein Absatz, 25 Zeichen < Länge(Text) < 500 Zeichen)
Es wird empfohlen, Satzähnlichkeit in Wortform und Wortreihenfolge zu verwenden: org.xm.similarity.text.CosineSimilarity , eine Methode, die denselben Text in zwei Absätzen betrachtet, ihn durch Wortsegmentierung, Worthäufigkeit und Wortartgewichtung gewichtet verwendet den Kosinus, um die Ähnlichkeit zu berechnen.
Beispiel: src/test/java/org.xm/similarity/text/CosineSimilarityTest.java
@ Test
public void getSimilarityScore () throws Exception {
String text1 = "对于俄罗斯来说,最大的战果莫过于夺取乌克兰首都基辅,也就是现任总统泽连斯基和他政府的所在地。目前夺取基辅的战斗已经打响。" ;
String text2 = "迄今为止,俄罗斯的入侵似乎没有完全按计划成功执行——英国国防部情报部门表示,在乌克兰军队激烈抵抗下,俄罗斯军队已经损失数以百计的士兵。尽管如此,俄军在继续推进。" ;
TextSimilarity cosSimilarity = new CosineSimilarity ();
double score1 = cosSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "cos相似度分值:" + score1 );
TextSimilarity editSimilarity = new EditDistanceSimilarity ();
double score2 = editSimilarity . getSimilarity ( text1 , text2 );
System . out . println ( "edit相似度分值:" + score2 );
}cos相似度分值:0.399143
edit相似度分值:0.0875Beispiel: src/test/java/org/xm/tendency/word/HownetWordTendencyTest.java
@ Test
public void getTendency () throws Exception {
HownetWordTendency hownet = new HownetWordTendency ();
String word = "美好" ;
double sim = hownet . getTendency ( word );
System . out . println ( word + ":" + sim );
System . out . println ( "混蛋:" + hownet . getTendency ( "混蛋" ));
}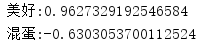
Bei diesem Beispiel handelt es sich um eine wortgranulare Stimmungspolaritätsanalyse basierend auf Sememe-Bäumen. Für die Textstimmungsanalyse gibt es den Pytextclassifier, der tiefe neuronale Netzwerkmodelle und SVM-Klassifizierungsalgorithmen verwendet, um bessere Ergebnisse zu erzielen.
Beispiel: src/test/java/org/xm/word2vec/Word2vecTest.java
@ Test
public void testHomoionym () throws Exception {
List < String > result = Word2vec . getHomoionym ( RAW_CORPUS_SPLIT_MODEL , "武功" , 10 );
System . out . println ( "武功 近似词:" + result );
}
@ Test
public void testHomoionymName () throws Exception {
String model = RAW_CORPUS_SPLIT_MODEL ;
List < String > result = Word2vec . getHomoionym ( model , "乔帮主" , 10 );
System . out . println ( "乔帮主 近似词:" + result );
List < String > result2 = Word2vec . getHomoionym ( model , "阿朱" , 10 );
System . out . println ( "阿朱 近似词:" + result2 );
List < String > result3 = Word2vec . getHomoionym ( model , "少林寺" , 10 );
System . out . println ( "少林寺 近似词:" + result3 );
}

Word2vec-Wortvektortraining ist eine Java-Version des Word2vec-Trainingstools Word2VEC_java. Das Trainingskorpus ist der Roman Tian Long Ba Bu, und Synonyme werden durch Wortvektorimplementierung erhalten. Benutzer können benutzerdefinierte Korpusse trainieren oder die chinesische Wikipedia verwenden, um universelle Wortvektoren zu trainieren.
Textähnlichkeitsmaß

Die Lizenzvereinbarung ist die Apache-Lizenz 2.0, die für die kommerzielle Nutzung kostenlos ist. Bitte fügen Sie der Produktbeschreibung einen Ähnlichkeitslink und eine Lizenzvereinbarung bei.
Der Projektcode ist noch sehr grob. Wenn Sie Verbesserungen am Code haben, können Sie ihn gerne an dieses Projekt zurücksenden. Bitte beachten Sie vor dem Absenden die folgenden zwei Punkte:
testAnschließend können Sie eine PR einreichen.


