cherche
2.2.1
Neuronale Suche

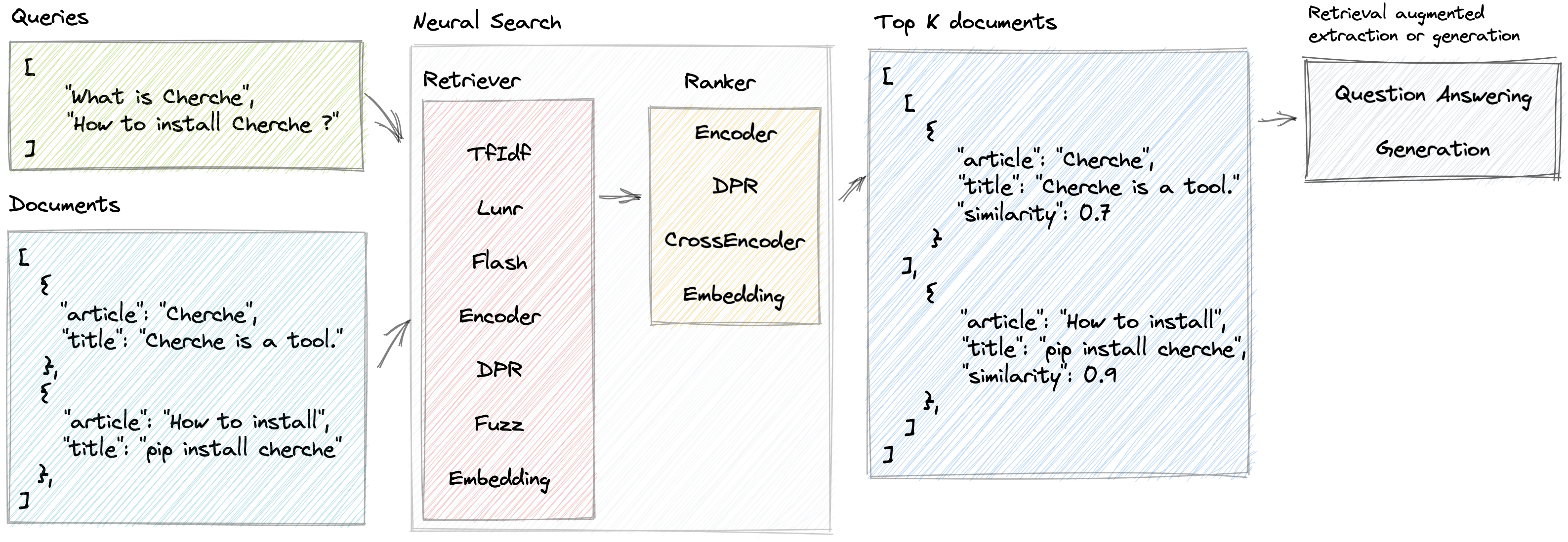
Cherche ermöglicht die Entwicklung einer neuronalen Suchpipeline, die Retriever und vorab trainierte Sprachmodelle sowohl als Retriever als auch als Ranker verwendet. Der Hauptvorteil von Cherche liegt in seiner Fähigkeit, End-to-End-Pipelines zu bauen. Darüber hinaus eignet sich Cherche aufgrund seiner Kompatibilität mit Batch-Berechnungen gut für die semantische Offline-Suche.
Hier sind einige der Funktionen, die Cherche bietet:
Live-Demo einer von Cherche betriebenen NLP-Suchmaschine
Um Cherche für die Verwendung mit einem einfachen Retriever auf der CPU zu installieren, z. B. TfIdf, Flash, Lunr, Fuzz, verwenden Sie den folgenden Befehl:
pip install chercheUm Cherche für die Verwendung mit einem semantischen Retriever oder Ranker auf der CPU zu installieren, verwenden Sie den folgenden Befehl:
pip install " cherche[cpu] "Wenn Sie abschließend planen, einen semantischen Retriever oder Rangierer auf der GPU zu verwenden, verwenden Sie den folgenden Befehl:
pip install " cherche[gpu] "Wenn Sie diese Installationsanweisungen befolgen, können Sie Cherche mit den entsprechenden Anforderungen für Ihre Anforderungen verwenden.
Die Dokumentation finden Sie hier. Es enthält Einzelheiten zu Retrievern, Ranglisten, Pipelines und Beispielen.
Mit Cherche können Sie innerhalb einer Objektliste das richtige Dokument finden. Hier ist ein Beispiel für einen Korpus.
from cherche import data
documents = data . load_towns ()
documents [: 3 ]
[{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris is the capital and most populous city of France.' },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : "Since the 17th century, Paris has been one of Europe's major centres of science, and arts." },
{ 'id' : 2 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'The City of Paris is the centre and seat of government of the region and province of Île-de-France.'
}]Hier ist ein Beispiel für eine neuronale Suchpipeline, die aus einem TF-IDF besteht, der Dokumente schnell abruft, gefolgt von einem Ranking-Modell. Das Ranking-Modell sortiert die vom Retriever erstellten Dokumente basierend auf der semantischen Ähnlichkeit zwischen der Abfrage und den Dokumenten. Wir können die Pipeline mithilfe einer Liste von Abfragen aufrufen und für jede Abfrage relevante Dokumente abrufen.
from cherche import data , retrieve , rank
from sentence_transformers import SentenceTransformer
from lenlp import sparse
# List of dicts
documents = data . load_towns ()
# Retrieve on fields title and article
retriever = retrieve . BM25 (
key = "id" ,
on = [ "title" , "article" ],
documents = documents ,
k = 30
)
# Rank on fields title and article
ranker = rank . Encoder (
key = "id" ,
on = [ "title" , "article" ],
encoder = SentenceTransformer ( "sentence-transformers/all-mpnet-base-v2" ). encode ,
k = 3 ,
)
# Pipeline creation
search = retriever + ranker
search . add ( documents = documents )
# Search documents for 3 queries.
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 , 'similarity' : 0.69513524 },
{ 'id' : 63 , 'similarity' : 0.6214994 },
{ 'id' : 65 , 'similarity' : 0.61809087 }],
[{ 'id' : 16 , 'similarity' : 0.59158516 },
{ 'id' : 0 , 'similarity' : 0.58217555 },
{ 'id' : 1 , 'similarity' : 0.57944715 }],
[{ 'id' : 26 , 'similarity' : 0.6925601 },
{ 'id' : 37 , 'similarity' : 0.63977146 },
{ 'id' : 28 , 'similarity' : 0.62772334 }]]Wir können den Index den Dokumenten zuordnen, um mithilfe von Pipelines auf deren Inhalte zuzugreifen:
search += documents
search ([ "Bordeaux" , "Paris" , "Toulouse" ])
[[{ 'id' : 57 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.69513524 },
{ 'id' : 63 ,
'title' : 'Bordeaux' ,
'similarity' : 0.6214994 },
{ 'id' : 65 ,
'title' : 'Bordeaux' ,
'url' : 'https://en.wikipedia.org/wiki/Bordeaux' ,
'similarity' : 0.61809087 }],
[{ 'id' : 16 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'article' : 'Paris received 12.' ,
'similarity' : 0.59158516 },
{ 'id' : 0 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.58217555 },
{ 'id' : 1 ,
'title' : 'Paris' ,
'url' : 'https://en.wikipedia.org/wiki/Paris' ,
'similarity' : 0.57944715 }],
[{ 'id' : 26 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.6925601 },
{ 'id' : 37 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.63977146 },
{ 'id' : 28 ,
'title' : 'Toulouse' ,
'url' : 'https://en.wikipedia.org/wiki/Toulouse' ,
'similarity' : 0.62772334 }]]Cherche bietet Retriever, die Eingabedokumente basierend auf einer Abfrage filtern.
Cherche bietet Ranglisten, die Dokumente in der Ausgabe von Retrievern filtern.
Cherche-Ranker sind mit SentenceTransformers-Modellen kompatibel, die auf dem Hugging Face-Hub verfügbar sind.
Cherche bietet Module zur Beantwortung von Fragen. Diese Module sind mit den vorab trainierten Modellen von Hugging Face kompatibel und vollständig in neuronale Suchpipelines integriert.
Cherche wurde für/von Renault entwickelt und ist jetzt für alle verfügbar. Wir freuen uns über alle Beiträge.

Lunr Retriever ist ein Wrapper um Lunr.py. Flash Retriever ist ein Wrapper für FlashText. DPR-, Encode- und CrossEncoder-Ranker sind Wrapper, die sich der Verwendung der vorab trainierten Modelle von SentenceTransformers in einer neuronalen Suchpipeline widmen.
Wenn Sie Cherche verwenden, um Ergebnisse für Ihre wissenschaftliche Veröffentlichung zu erstellen, lesen Sie bitte unser SIGIR-Papier:
@inproceedings { Sourty2022sigir ,
author = { Raphael Sourty and Jose G. Moreno and Lynda Tamine and Francois-Paul Servant } ,
title = { CHERCHE: A new tool to rapidly implement pipelines in information retrieval } ,
booktitle = { Proceedings of SIGIR 2022 } ,
year = { 2022 }
}Das Cherche-Entwicklerteam besteht aus Raphaël Sourty, François-Paul Servant, Nicolas Bizzozzero und Jose G Moreno. ?


