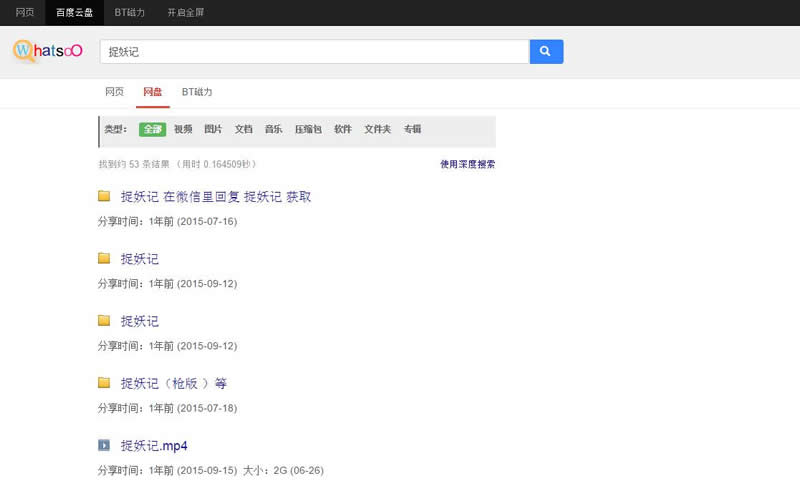
Baidu Cloud-Netzwerk-Disk-Suchmaschine v1.0
v0
Die Cloud-Netzwerk-Festplattensuchmaschine von Baidu ist ein mit PHP+MySQL entwickelter Quellcode für eine Netzwerkfestplatten-Suchmaschine. Laufumgebung: Bevor Sie beginnen, müssen Sie *PHP5.3.7+*MySQL*Python2.7~*[xunsearch](http://xunsearch.com/) installieren. Die Verzeichnisstruktur des Suchmaschinenprojekts ___ ist ungefähr so: -- indexer/#index---spider/#crawler---sql/---web/#website---application/---config/#configuration-verwandte---config.php---database. php#database Konfiguration... ---static/# Statische Ressourcen speichern, css|js|font---system/---index.php Bereitstellung starten Datenbank erstellen Erstellen Sie eine Datenbank mit dem Namen „pan“ und stellen Sie die Codierung auf ein „utf-8“. Importieren Sie dann „sql“, um die Erstellung der Tabelle abzuschließen. Die Website-Bereitstellung unterstützt „Nginx“- und „Apache“-Server. __apache__ muss *mod_rewrite* aktivieren. __nginx__ ist wie folgt konfiguriert: location/{indexindex.php;try_files$uri$uri//index.php/$uri;}
location~[^/].php(/|$){fastcgi_pass127.0.0.1:9000;fastcgi_indexindex.php;includefastcgi.conf;includepathinfo.conf;}
Änderung der Konfigurationsdatei: Die Datei „config.php“ ändert den Titel, die Beschreibung und andere Informationen der Website. „database.php“ ändert das Datenbankkonto, das Passwort und andere Informationen. Die Website wird auf Basis des CodeIgniter-Frameworks entwickelt. Wenn es Probleme bei der Installation oder Bereitstellung gibt , oder sekundäre Entwicklung, siehe [Offizielle Dokumentation](http://codeigniter.org.cn/user_guide/general/welcome.html)###Starten Sie den Crawler, geben Sie das Verzeichnis „spider/“ ein und ändern Sie die Datenbank Informationen in „spider.py“.
Wenn dies Ihre erste Bereitstellung ist, müssen Sie den folgenden Befehl ausführen, um das Seeding abzuschließen: pythonspider.py --seed-user Das Obige dient eigentlich dazu, die relevanten Informationen der beliebten Sharing-Benutzer von Baidu Cloud zu erfassen und dann mit dem Crawlen der Daten von ihnen zu beginnen und führen Sie dann pythonspider .py aus. Zu diesem Zeitpunkt hat der Crawler mit der Arbeit begonnen. ###Bei der Installation von xunsearch wird derzeit __xunsearch__ als Suchmaschine verwendet, die später durch „elasticsearch“ ersetzt wird. Bitte beachten Sie den Installationsprozess (keine Installation erforderlich, PHPSDK, ich habe es in das Web integriert) http://xunsearch.com/doc/php/guide/start.installation###Indexdaten Oben haben wir die Crawler-Daten vervollständigt Capture ist die Website erstellt, aber noch nicht durchsuchbar. Beginnen wir mit dem letzten Schritt, der Erstellung des Index. Geben Sie das Verzeichnis „indexer/“ ein, ersetzen Sie „$prefix“ in „indexer.php“ durch den Root-Pfad Ihres Web-Requirements „$prefix/application/helpers/xs/lib/XS.php“ und ändern Sie dann das Passwort des Datenbankkontos Führen Sie python./index.php aus