qwen2 in a lambda
1.0.0
Aktualisiert am 09.11.2024
(Markieren Sie das Datum, da sich LLM-APIs in Python so schnell bewegen und möglicherweise wichtige Änderungen einführen, bis jemand anderes dies liest!)
Dies ist eine kleine Untersuchung darüber, wie wir Qwen GGUF-Modelldateien mithilfe von Docker und SAM CLI in AWS Lambda einfügen können
Angepasst von https://makit.net/blog/llm-in-a-lambda-function/
Ich wollte herausfinden, ob ich meine AWS-Ausgaben reduzieren kann, indem ich nur die Funktionen von Lambda und nicht Lambda + Bedrock nutze, da beide Dienste auf lange Sicht höhere Kosten verursachen würden.
Die Idee bestand darin, ein kleines Sprachmodell zu integrieren, das relativ gesehen nicht so ressourcenintensiv wäre, und hoffentlich eine Latenz von weniger als einer Sekunde bei einer Speicherkonfiguration von 128 bis 256 MB zu erreichen
Ich wollte auch GGUF-Modelle verwenden, um verschiedene Quantisierungsstufen zu verwenden und herauszufinden, welche Leistung/Dateigröße am besten zum Laden in den Speicher geeignet ist
qwen2-1_5b-instruct-q5_k_m.gguf in qwen_fuction/function/app.y / LOCAL_PATH qwen_function/function/requirements.txt (vorzugsweise in einer Venv/Conda-Umgebung).sam build / sam validate aussam local start-api aus, um lokal zu testencurl --header "Content-Type: application/json" --request POST --data '{"prompt":"hello"}' http://localhost:3000/generate aus, um den LLM aufzufordernsam deploy --guided aus, um die Bereitstellung in AWS durchzuführen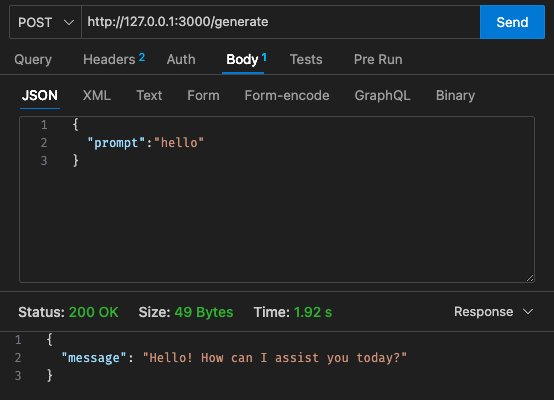
AWS
Erstkonfiguration – 128 MB, 30 Sekunden Zeitüberschreitung
Angepasste Konfiguration Nr. 1 – 512 MB, 30 Sekunden Zeitüberschreitung
Angepasste Konfiguration Nr. 2 – 512 MB, 30 Sekunden Zeitüberschreitung
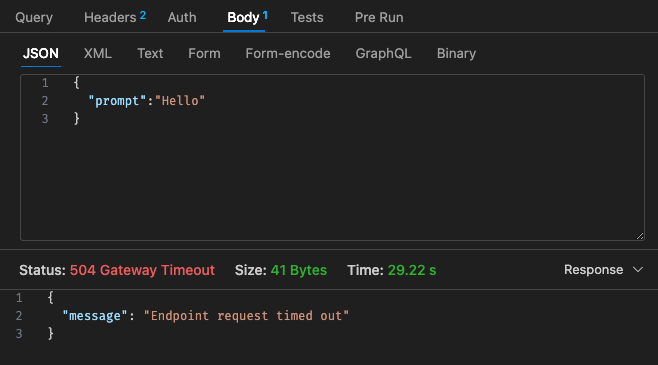
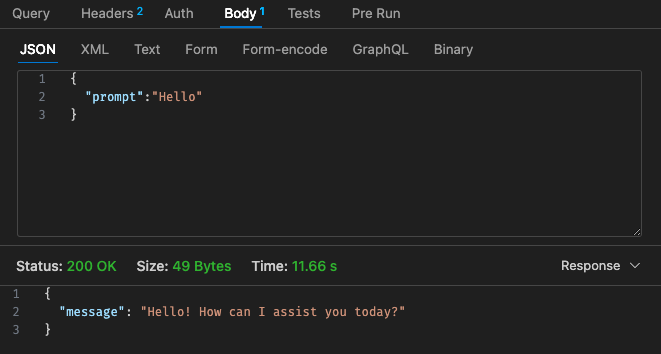
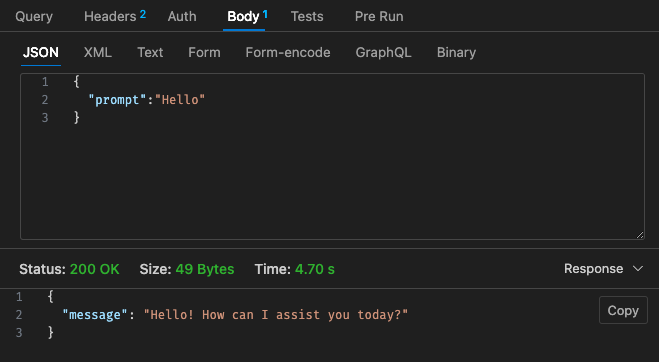
Zurück zur Preisstruktur von Lambda:
Es kann günstiger sein, einfach ein gehostetes LLM mit AWS Bedrock usw. in der Cloud zu verwenden, da die Preisstruktur für Lambda mit Qwen im Vergleich zu Claude 3 Haiku nicht wettbewerbsfähiger erscheint
Darüber hinaus lässt sich das API-Gateway-Timeout nicht einfach über das 30-Sekunden-Timeout hinaus konfigurieren. Abhängig von Ihrem Anwendungsfall ist dies möglicherweise nicht sehr ideal
Ergebnisse über lokal hängen von Ihren Maschinenspezifikationen ab!! und kann Ihre Wahrnehmung, Ihre Erwartungen gegenüber der Realität stark verzerren
Abhängig von Ihrem Anwendungsfall kann die Latenz pro Lambda-Aufruf und -Antworten auch zu einer schlechten Benutzererfahrung führen
Alles in allem denke ich, dass dies ein lustiges kleines Experiment war, auch wenn es den Budget- und Latenzanforderungen von Qwen 1.5b für mein Nebenprojekt nicht ganz entsprach. Nochmals vielen Dank an @makit für die Anleitung!


