Interactive RAG
1.0.0
Agenten revolutionieren die Art und Weise, wie wir Sprachmodelle für die Entscheidungsfindung und Aufgabenerfüllung nutzen. Agenten sind Systeme, die Sprachmodelle verwenden, um Entscheidungen zu treffen und Aufgaben auszuführen. Sie sind für die Bewältigung komplexer Szenarien konzipiert und bieten im Vergleich zu herkömmlichen Ansätzen mehr Flexibilität. Agenten können als Reasoning-Engines betrachtet werden, die Sprachmodelle nutzen, um Informationen zu verarbeiten, relevante Daten abzurufen, aufzunehmen (zu unterteilen/einzubetten) und Antworten zu generieren.
In Zukunft werden Agenten eine entscheidende Rolle bei der Verarbeitung von Texten, der Automatisierung von Aufgaben und der Verbesserung der Mensch-Computer-Interaktionen im Zuge der Weiterentwicklung der Sprachmodelle spielen.
In diesem Beispiel konzentrieren wir uns speziell auf die Nutzung von Agenten in der dynamischen Retrieval Augmented Generation (RAG). Mit ActionWeaver und MongoDB Atlas haben Sie die Möglichkeit, Ihre RAG-Strategie in Echtzeit durch Konversationsinteraktionen zu ändern. Unabhängig davon, ob Sie mehr Blöcke auswählen, die Blockgröße erhöhen oder andere Parameter optimieren, können Sie Ihren RAG-Ansatz optimieren, um die gewünschte Antwortqualität und -genauigkeit zu erreichen. Sie können sogar Quellen in natürlicher Sprache zu Ihrer Vektordatenbank hinzufügen/entfernen!
# LLM Config
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
"summarize_chunks": True, # adds latency at ingest, everything comes at a cost
}
Das Klumpen von Text ist großartig, aber wie speichert man ihn?
Das Zusammenfassen spart Platz und beschleunigt die Arbeit, kann jedoch dazu führen, dass Details verloren gehen.
Das Speichern von Rohdaten ist genau, aber umfangreich, langsamer und „verrauscht“.
Vorteile der Zusammenfassung:
Nachteile der Zusammenfassung:
Was ist das Richtige für Sie? Es kommt auf Ihre Bedürfnisse an! Halten:
DEMO 1
Erstellen Sie eine neue Python-Umgebung
python3 -m venv envAktivieren Sie die neue Python-Umgebung
source env/bin/activateInstallieren Sie die Anforderungen
pip3 install -r requirements.txtLegen Sie die Parameter in params.py fest:
# MongoDB
MONGODB_URI = " "
DATABASE_NAME = " genai "
COLLECTION_NAME = " rag "
# If using OpenAI
OPENAI_API_KEY = " "
# If using Azure OpenAI
OPENAI_TYPE = " azure "
OPENAI_API_VERSION = " 2023-10-01-preview "
OPENAI_AZURE_ENDPOINT = " https://.openai.azure.com/ "
OPENAI_AZURE_DEPLOYMENT = " "
Erstellen Sie einen Suchindex mit der folgenden Definition
{
"mappings" : {
"dynamic" : true ,
"fields" : {
"embedding" : {
"dimensions" : 384 ,
"similarity" : " cosine " ,
"type" : " knnVector "
}
}
}
}Legen Sie die Umgebung fest
export OPENAI_API_KEY=Zum Ausführen der RAG-Anwendung
env/bin/streamlit run rag/app.pyVon der Anwendung generierte Protokollinformationen werden an app.log angehängt.
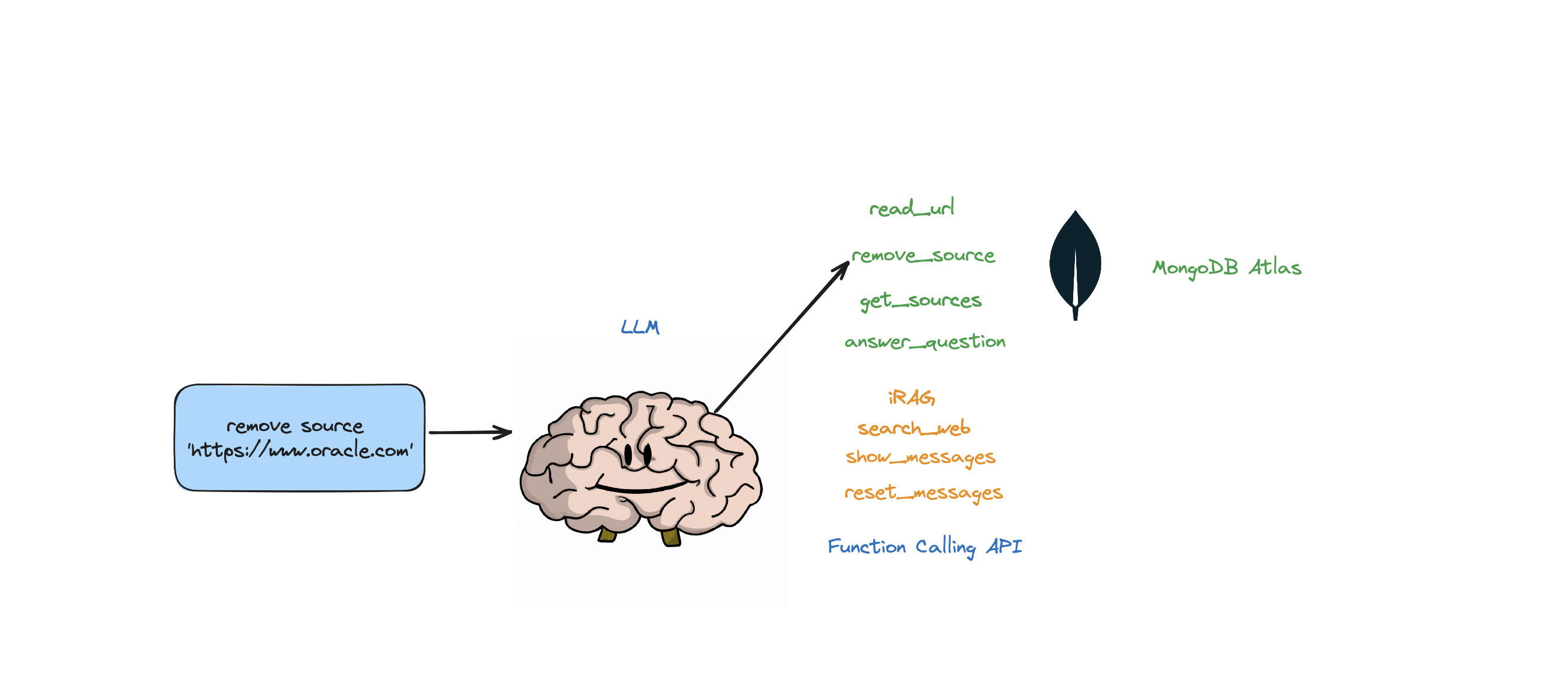
Dieser Bot unterstützt die folgenden Aktionen: Frage beantworten, das Web durchsuchen, URLs lesen, Quellen entfernen, alle Quellen auflisten und Nachrichten zurücksetzen. Es unterstützt auch eine Aktion namens iRAG, mit der Sie die RAG-Strategie Ihres Agenten dynamisch steuern können.
Beispiel: „Setze die RAG-Konfiguration auf 3 Quellen und die Chunk-Größe 1250“ => Neue RAG-Konfiguration:{'num_sources': 3, 'source_chunk_size': 1250, 'min_rel_score': 0, 'unique': True}.
def __call__(self, text):
text = self.preprocess_query(text)
self.messages += [{"role": "user", "content":text}]
response = self.llm.create(messages=self.messages, actions = [
self.read_url,self.answer_question,self.remove_source,self.reset_messages,
self.iRAG, self.get_sources_list,self.search_web
], stream=True)
return response
Wenn der Bot anhand der im Atlas Vector Store gespeicherten Daten und Ihrer RAG-Strategie (Anzahl der Quellen, Blockgröße, min_rel_score usw.) keine Antwort auf die Frage liefern kann, startet er eine Websuche, um relevante Informationen zu finden. Anschließend können Sie den Bot anweisen, diese Ergebnisse zu lesen und daraus zu lernen.
RAG ist cool und so, aber die richtige „RAG-Strategie“ zu finden, ist schwierig. Die Blockgröße und die Anzahl der eindeutigen Quellen haben einen direkten Einfluss auf die vom LLM generierte Antwort.
Bei der Entwicklung einer effektiven RAG-Strategie spielen der Aufnahmeprozess von Webquellen, Chunking, Einbettung, Chunk-Größe und die Menge der verwendeten Quellen eine entscheidende Rolle. Beim Chunking wird der Eingabetext zum besseren Verständnis aufgeschlüsselt, beim Einbetten wird die Bedeutung erfasst und die Anzahl der Quellen wirkt sich auf die Antwortvielfalt aus. Für genaue und relevante Antworten ist es wichtig, das richtige Gleichgewicht zwischen Blockgröße und Anzahl der Quellen zu finden. Um optimale Einstellungen zu ermitteln, sind Experimente und Feinabstimmungen erforderlich.
Bevor wir uns mit „Abrufen“ befassen, sprechen wir zunächst über den „Ingest-Prozess“.
Warum sollten Sie einen separaten Prozess zum „Aufnehmen“ Ihrer Inhalte in Ihre Vektordatenbank verwenden? Mithilfe der Magie von Agenten können wir ganz einfach neue Inhalte zur Vektordatenbank hinzufügen.
Es gibt viele Arten von Datenbanken, die diese Einbettungen speichern können, jede mit ihrem eigenen speziellen Verwendungszweck. Für Aufgaben mit GenAI-Anwendungen empfehle ich jedoch MongoDB.
Stellen Sie sich MongoDB als einen Kuchen vor, den Sie sowohl essen als auch essen können. Es bietet Ihnen die Leistungsfähigkeit seiner Sprache zum Erstellen von Abfragen, der Mongo Query Language. Es enthält außerdem alle großartigen Funktionen von MongoDB. Darüber hinaus können Sie diese Bausteine (Vektoreinbettungen) speichern und mathematische Operationen an ihnen durchführen, alles an einem Ort. Dies macht MongoDB Atlas zu einem One-Stop-Shop für alle Ihre Anforderungen an die Vektoreinbettung!
@action("read_url", stop=True)
def read_url(self, urls: List[str]):
"""
Invoke this ONLY when the user asks you to 'read', 'add' or 'learn' some URL(s).
This function reads the content from specified sources, and ingests it into the Knowledgebase.
URLs may be provided as a single string or as a list of strings.
IMPORTANT! Use conversation history to make sure you are reading/learning/adding the right URLs.
Parameters
----------
urls : List[str]
List of URLs to scrape.
Returns
-------
str
A message indicating successful reading of content from the provided URLs.
"""
with self.st.spinner(f"```Analyzing the content in {urls}```"):
loader = PlaywrightURLLoader(urls=urls, remove_selectors=["header", "footer"])
documents = loader.load_and_split(self.text_splitter)
self.index.add_documents(
documents
)
return f"```Contents in URLs {urls} have been successfully ingested (vector embeddings + content).```"
{
"mappings": {
"dynamic": true,
"fields": {
"embedding": {
"dimensions": 384, #dimensions depends on the model
"similarity": "cosine",
"type": "knnVector"
}
}
}
}
def recall(self, text, n_docs=2, min_rel_score=0.25, chunk_max_length=800,unique=True):
#$vectorSearch
print("recall=>"+str(text))
response = self.collection.aggregate([
{
"$vectorSearch": {
"index": "default",
"queryVector": self.gpt4all_embd.embed_query(text), #GPT4AllEmbeddings()
"path": "embedding",
#"filter": {},
"limit": 15, #Number (of type int only) of documents to return in the results. Value can't exceed the value of numCandidates.
"numCandidates": 50 #Number of nearest neighbors to use during the search. You can't specify a number less than the number of documents to return (limit).
}
},
{
"$addFields":
{
"score": {
"$meta": "vectorSearchScore"
}
}
},
{
"$match": {
"score": {
"$gte": min_rel_score
}
}
},{"$project":{"score":1,"_id":0, "source":1, "text":1}}])
tmp_docs = []
str_response = []
for d in response:
if len(tmp_docs) == n_docs:
break
if unique and d["source"] in tmp_docs:
continue
tmp_docs.append(d["source"])
str_response.append({"URL":d["source"],"content":d["text"][:chunk_max_length],"score":d["score"]})
kb_output = f"Knowledgebase Results[{len(tmp_docs)}]:n```{str(str_response)}```n## n```SOURCES: "+str(tmp_docs)+"```nn"
self.st.write(kb_output)
return str(kb_output)
Mithilfe von ActionWeaver, einem leichtgewichtigen Wrapper für die Funktionsaufruf-API, können wir einen Benutzer-Proxy-Agenten erstellen, der mithilfe von MongoDB Atlas relevante Informationen effizient abruft und aufnimmt.
Ein Proxy-Agent ist ein Mittelsmann, der Client-Anfragen an andere Server oder Ressourcen sendet und dann Antworten zurückbringt.
Dieser Agent präsentiert dem Benutzer die Daten auf interaktive und anpassbare Weise und verbessert so das gesamte Benutzererlebnis.
Der UserProxyAgent verfügt über mehrere RAG-Parameter, die angepasst werden können, z. B. chunk_size (z. B. 1000), num_sources (z. B. 2), unique (z. B. True) und min_rel_score (z. B. 0,00).
class UserProxyAgent:
def __init__(self, logger, st):
self.rag_config = {
"num_sources": 2,
"source_chunk_size": 1000,
"min_rel_score": 0.00,
"unique": True,
}
Hier sind einige wichtige Vorteile, die unsere Entscheidung für ActionWeaver beeinflusst haben:
Ein Agent ist im Grunde nur ein Computerprogramm oder -system, das dazu dient, seine Umgebung wahrzunehmen, Entscheidungen zu treffen und bestimmte Ziele zu erreichen.
Stellen Sie sich einen Agenten als eine Softwareeinheit vor, die ein gewisses Maß an Autonomie aufweist und im Namen ihres Benutzers oder Eigentümers Aktionen in ihrer Umgebung ausführt, jedoch auf relativ unabhängige Weise. Es ergreift Initiativen, um eigenständig Maßnahmen durchzuführen, indem es über Optionen zur Erreichung seiner Ziele nachdenkt. Die Kernidee von Agenten besteht darin, mithilfe eines Sprachmodells eine Abfolge auszuführender Aktionen auszuwählen. Im Gegensatz zu Ketten, bei denen eine Abfolge von Aktionen fest im Code codiert ist, verwenden Agenten ein Sprachmodell als Argumentationsmaschine, um zu bestimmen, welche Aktionen in welcher Reihenfolge ausgeführt werden sollen.
Aktionen sind Funktionen, die ein Agent aufrufen kann. Es gibt zwei wichtige Designüberlegungen im Zusammenhang mit Aktionen:
Giving the agent access to the right actions
Describing the actions in a way that is most helpful to the agent
Ohne beides zu durchdenken, wird es Ihnen nicht gelingen, einen funktionierenden Agenten aufzubauen. Wenn Sie dem Agenten keinen Zugriff auf die richtigen Aktionen gewähren, wird er nie in der Lage sein, die von Ihnen vorgegebenen Ziele zu erreichen. Wenn Sie die Aktionen nicht gut beschreiben, weiß der Agent nicht, wie er sie richtig verwenden soll.
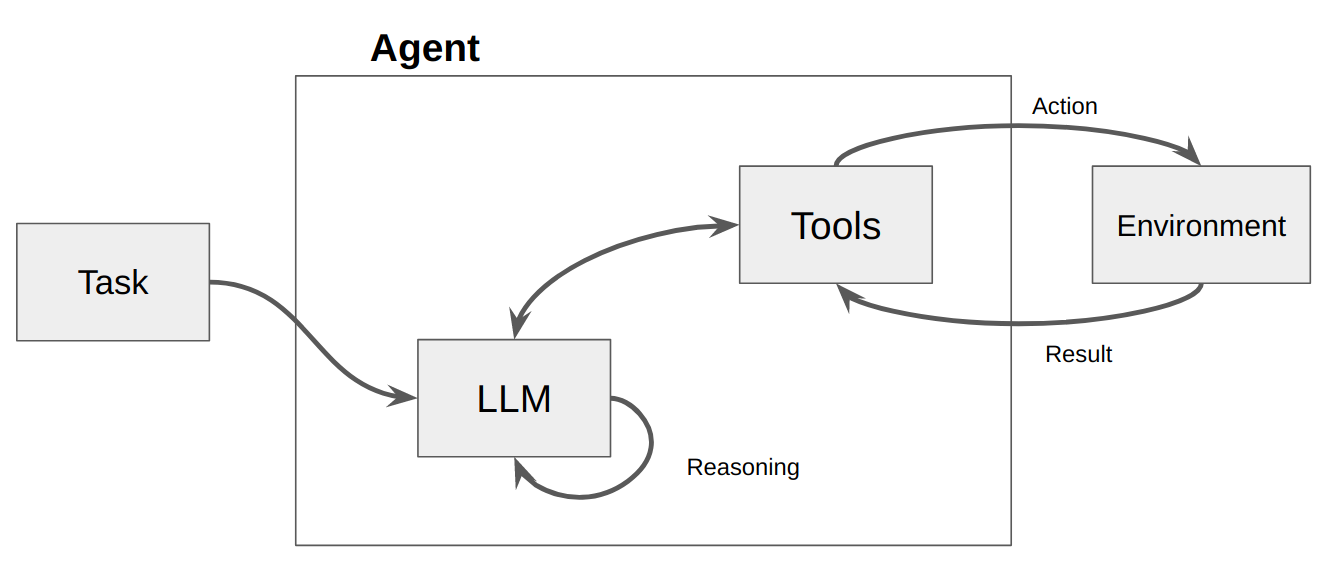
Anschließend wird ein LLM aufgerufen, was entweder zu einer Antwort an den Benutzer ODER zu auszuführenden Aktionen führt. Wenn festgestellt wird, dass eine Antwort erforderlich ist, wird diese an den Benutzer weitergeleitet und der Zyklus ist abgeschlossen. Wenn festgestellt wird, dass eine Aktion erforderlich ist, wird diese Aktion ausgeführt und eine Beobachtung (Aktionsergebnis) durchgeführt. Diese Aktion und die entsprechende Beobachtung werden wieder zur Eingabeaufforderung hinzugefügt (wir nennen dies ein „Agenten-Notizblock“), und die Schleife wird zurückgesetzt, d. h. Das LLM wird erneut aufgerufen (mit dem aktualisierten Agenten-Scratchpad).
In ActionWeaver können wir die Schleife beeinflussen, indem wir stop=True|False zu einer Aktion hinzufügen. Wenn stop=True , gibt das LLM sofort die Ausgabe der Funktion zurück. Dadurch wird auch verhindert, dass das LLM mehrere Funktionsaufrufe durchführt. In dieser Demo verwenden wir nur stop=True
ActionWeaver unterstützt auch eine komplexere Schleifensteuerung mit orch_expr(SelectOne[actions]) und orch_expr(RequireNext[actions]) , aber das belasse ich für TEIL II.
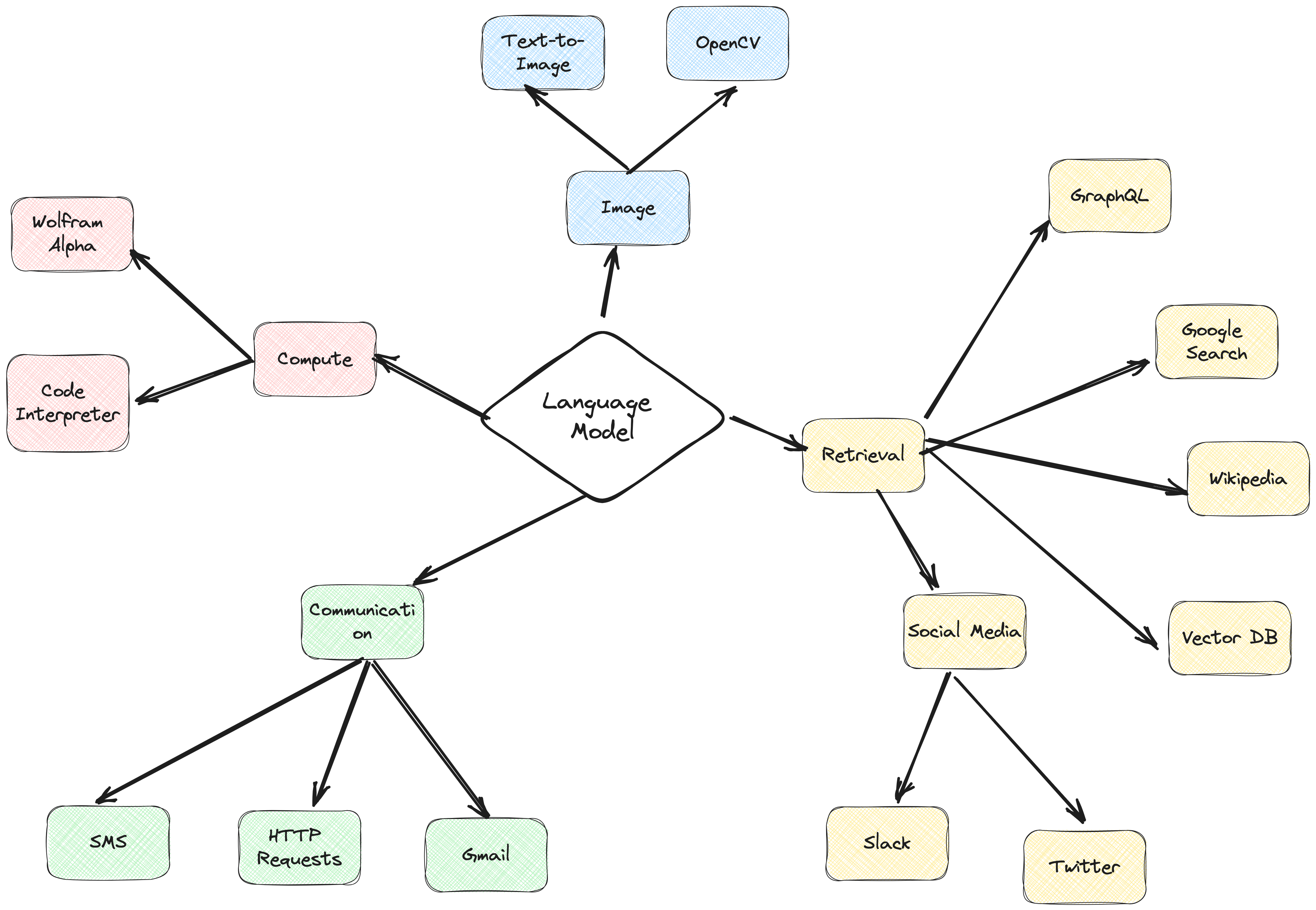
Das ActionWeaver-Agent-Framework ist ein KI-Anwendungsframework, bei dem Funktionsaufrufe im Mittelpunkt stehen. Es wurde entwickelt, um eine nahtlose Zusammenführung traditioneller Computersysteme mit den leistungsstarken Argumentationsfunktionen von Sprachmodellmodellen zu ermöglichen. ActionWeaver basiert auf dem Konzept des LLM-Funktionsaufrufs, während beliebte Frameworks wie Langchain und HayStack auf dem Konzept von Pipelines basieren.

Lesen Sie mehr unter: https://thinhdanggroup.github.io/function-calling-openai/
Entwickler können mit einem einfachen Dekorator JEDE Python-Funktion als Werkzeug anhängen. Im folgenden Beispiel führen wir die Aktion get_sources_list ein, die von der OpenAI-API aufgerufen wird.
ActionWeaver verwendet die Signatur und den Dokumentstring der dekorierten Methode als Beschreibung und übergibt sie an die Funktions-API von OpenAI.
ActionWeaver bietet einen leichten Wrapper, der sich um die Konvertierung der Docstring-/Decorator-Informationen in das richtige Format für die OpenAI-API kümmert.
@action(name="get_sources_list", stop=True)
def get_sources_list(self):
"""
Invoke this to respond to list all the available sources in your knowledge base.
Parameters
----------
None
"""
sources = self.collection.distinct("source")
if sources:
result = f"Available Sources [{len(sources)}]:n"
result += "n".join(sources[:5000])
return result
else:
return "N/A"
Wenn „stop=True“ zu einer Aktion hinzugefügt wird, bedeutet dies, dass der LLM die Ausgabe der Funktion sofort zurückgibt. Dadurch wird jedoch auch verhindert, dass der LLM mehrere Funktionsaufrufe durchführt. Wenn man beispielsweise nach dem Wetter in NYC und San Francisco fragt, ruft das Modell nacheinander zwei separate Funktionen für jede Stadt auf. Bei stop=True wird dieser Vorgang jedoch unterbrochen, sobald die erste Funktion Wetterinformationen für NYC oder San Francisco zurückgibt, je nachdem, welche Stadt sie zuerst abfragt.
Weitere Informationen zur Funktionsweise dieses Bots finden Sie in der Datei bot.py. Darüber hinaus können Sie das ActionWeaver-Repository nach weiteren Details durchsuchen.
Durch die Generierung von Argumentationsspuren kann das Modell Aktionspläne auslösen, verfolgen und aktualisieren und sogar Ausnahmen behandeln. In diesem Beispiel wird ReAct in Kombination mit Chain-of-Thinking (CoT) verwendet.
Gedankenkette
Argumentation + Aktion
[EXAMPLES]
- User Input: What is MongoDB?
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "answer_question".
- Action: "answer_question"('What is MongoDB?')
- User Input: Reset chat history
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "reset_messages".
- Action: "reset_messages"()
- User Input: remove source https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "remove_source".
- Action: "remove_source"(['https://www.google.com', 'https://www.example.com'])
- User Input: read https://www.google.com, https://www.example.com
- Thought: I have to think step by step. I should not answer directly, let me check my available actions before responding.
- Observation: I have an action available "read_url".
- Action: "read_url"(['https://www.google.com','https://www.example.com'])
[END EXAMPLES]
In diesen Beispielen kommen sowohl Chain of Thought (CoT) als auch ReAct-Prompting-Techniken ins Spiel. So geht's:
Chain of Thought (CoT)-Aufforderung:
ReAct-Eingabeaufforderung:
Zusammenfassend spielen sowohl CoT als auch ReAct in diesen Beispielen eine entscheidende Rolle. CoT ermöglicht es dem Modell, Schritt für Schritt zu argumentieren und geeignete Maßnahmen auszuwählen, während ReAct diese Funktionalität erweitert, indem es dem Modell ermöglicht, mit seiner Umgebung zu interagieren und seine Pläne entsprechend zu aktualisieren. Diese Kombination aus Argumentation und Aktion macht große Sprachmodelle flexibler und vielseitiger und ermöglicht es ihnen, ein breiteres Spektrum an Aufgaben und Situationen zu bewältigen.
Beginnen wir damit, unserem Agenten eine Frage zu stellen. In diesem Fall: „Was ist eine Mango?“ . Das erste, was passieren wird, ist, dass versucht wird, alle relevanten Informationen mithilfe der Vektoreinbettungsähnlichkeit „abzurufen“. Anschließend formuliert es eine Antwort mit dem Inhalt, an den es sich „erinnert“ hat, oder führt eine Websuche durch. Da unsere Wissensdatenbank derzeit leer ist, müssen wir einige Quellen hinzufügen, bevor wir eine Antwort formulieren können.
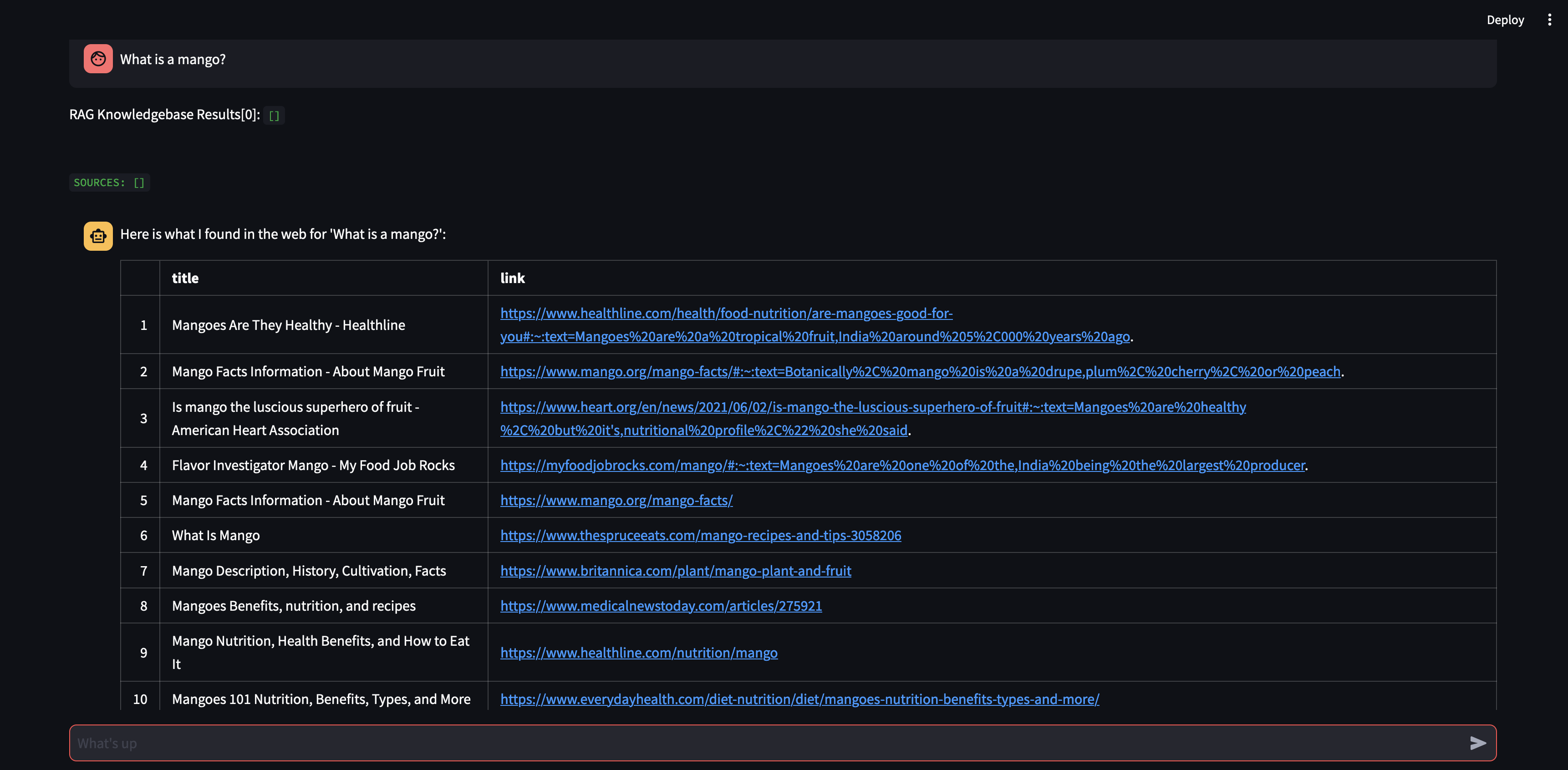
Da der Bot anhand des Inhalts der Vektordatenbank keine Antwort liefern kann, hat er eine Google-Suche gestartet, um relevante Informationen zu finden. Wir können ihm nun sagen, welche Quellen er „lernen“ soll. In diesem Fall weisen wir es an, die ersten beiden Quellen aus den Suchergebnissen zu lernen.
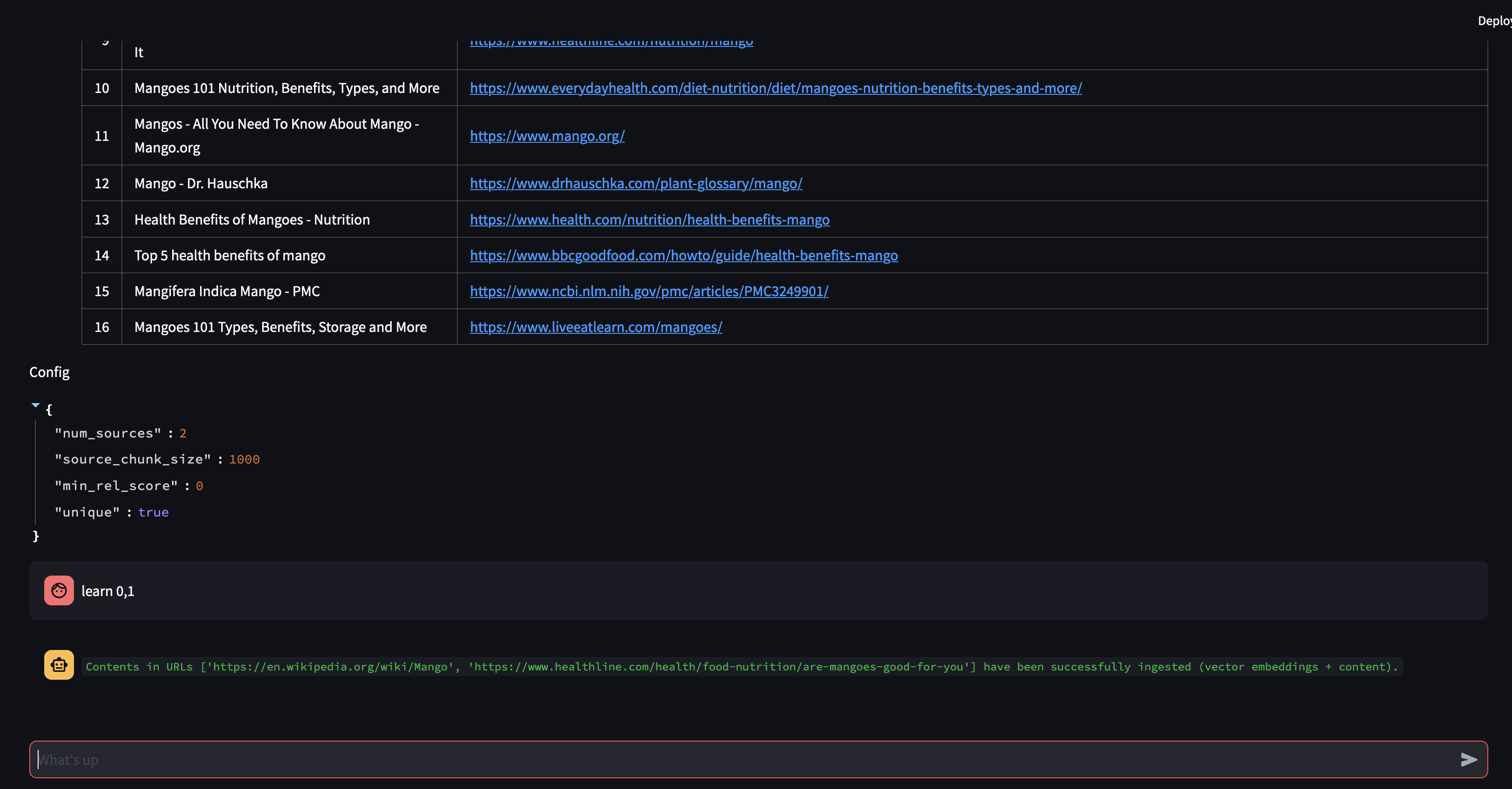
Als nächstes ändern wir die RAG-Strategie! Sorgen wir dafür, dass nur eine Quelle verwendet wird und eine kleine Blockgröße von 500 Zeichen verwendet wird.
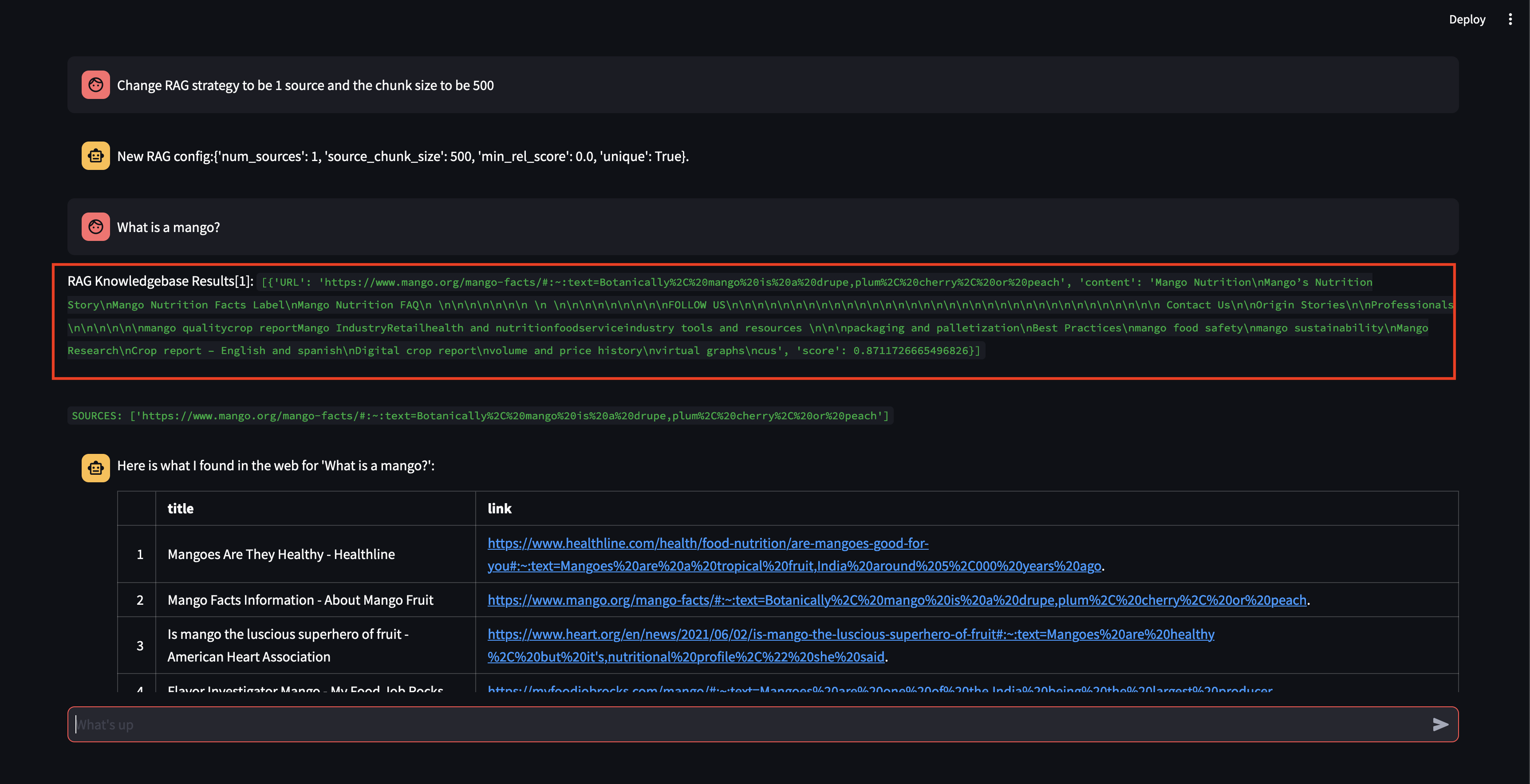
Beachten Sie, dass zwar ein Block mit einem relativ hohen Relevanzwert abgerufen werden konnte, jedoch keine Antwort generiert werden konnte, da die Blockgröße zu klein und der Blockinhalt nicht relevant genug war, um eine Antwort zu formulieren. Da mit dem kleinen Block keine Antwort generiert werden konnte, führte es im Namen des Benutzers eine Websuche durch.
Sehen wir uns an, was passiert, wenn wir die Blockgröße auf 3000 statt 500 Zeichen erhöhen.
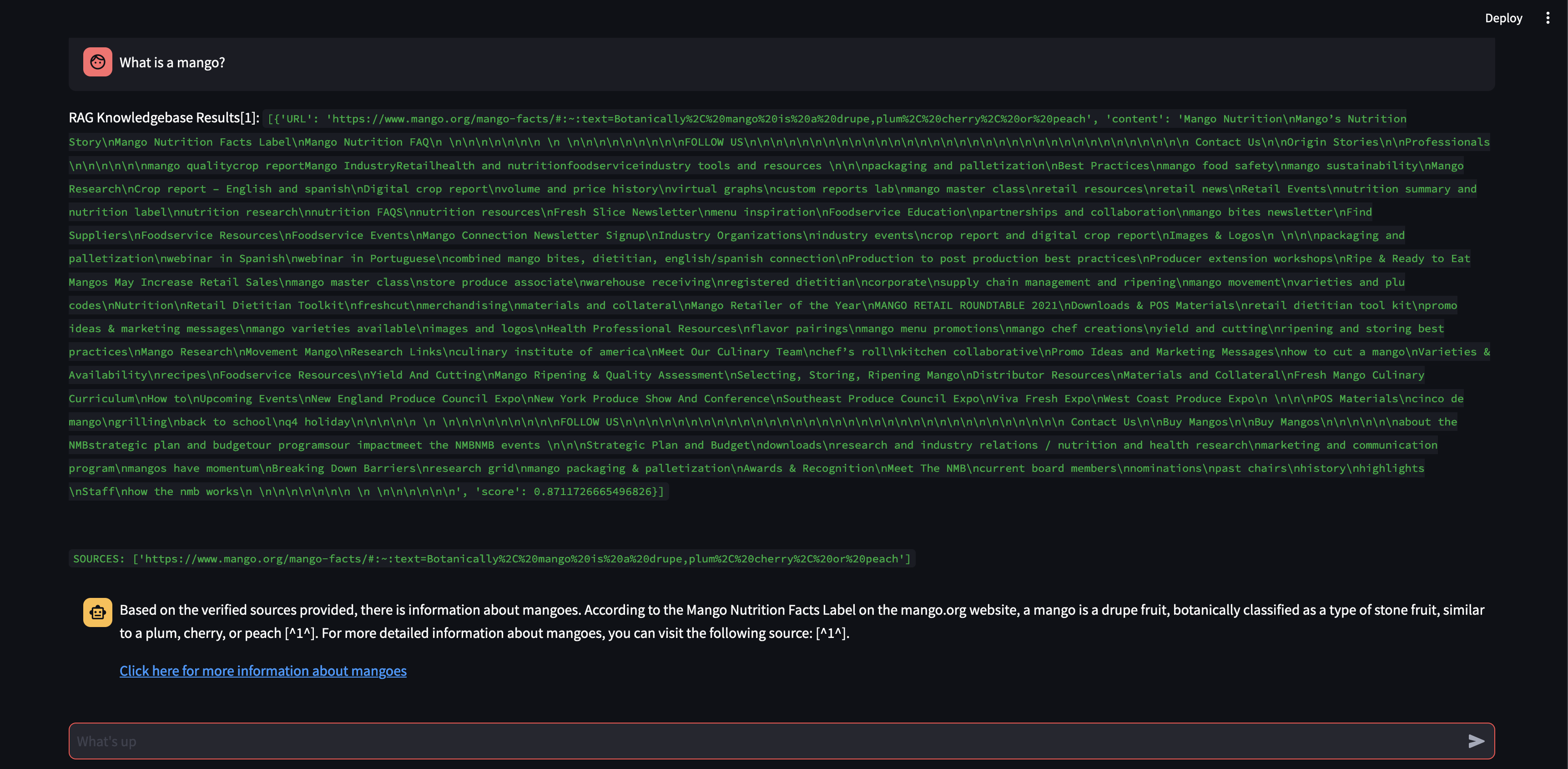
Mit einer größeren Blockgröße war es nun möglich, die Antwort mithilfe des Wissens aus der Vektordatenbank genau zu formulieren!
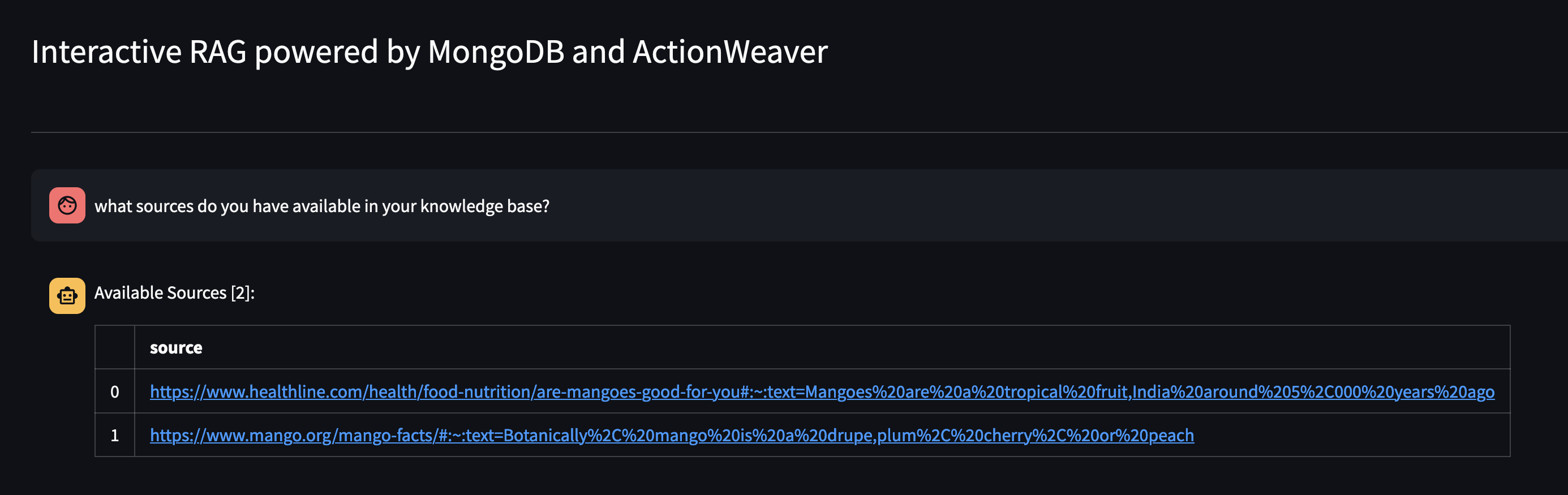
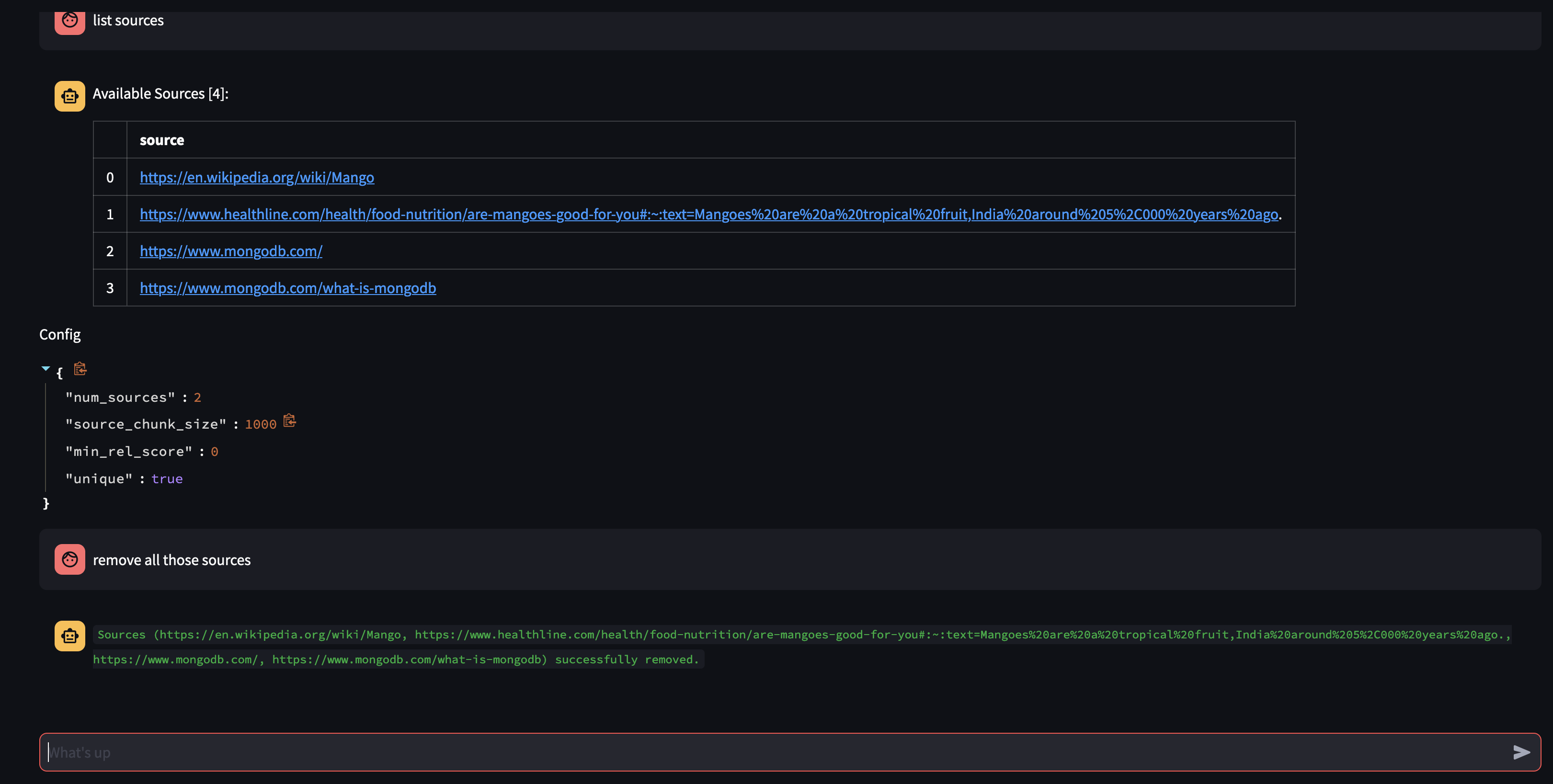
Sehen wir uns an, was in der Wissensdatenbank des Agenten verfügbar ist, indem wir ihn fragen: Welche Quellen haben Sie in Ihrer Wissensdatenbank?
Wenn Sie eine bestimmte Ressource entfernen möchten, können Sie Folgendes tun:
USER: remove source 'https://www.oracle.com' from the knowledge base
Um alle Quellen in der Sammlung zu entfernen, könnten wir Folgendes tun:
USER: what sources do you have in your knowledge base?
AGENT: {response}
USER: remove all those sources please
Diese Demo bietet einen Einblick in das Innenleben unseres KI-Agenten und demonstriert seine Fähigkeit, auf interaktive Weise zu lernen und auf Benutzeranfragen zu reagieren. Wir haben gesehen, wie das Unternehmen seine interne Wissensdatenbank nahtlos mit der Echtzeit-Websuche kombiniert, um umfassende und genaue Informationen bereitzustellen. Das Potenzial dieser Technologie ist enorm und geht weit über die einfache Beantwortung von Fragen hinaus. Nichts davon wäre ohne die Magie der Function Calling API möglich.
Dies wurde von https://github.com/TengHu/Interactive-RAG inspiriert
Wir freuen uns über Beiträge aus der Open-Source-Community.
Apache-Lizenz 2.0


