genai knowledge capture
1.0.0
Diese Proof-of-Concept-Lösung erläutert eine mögliche Lösung, mit der Stammeswissen durch Sprachaufzeichnungen von leitenden Mitarbeitern eines Unternehmens erfasst werden kann. Es beschreibt Methoden zur Nutzung von Amazon Transcribe und Amazon Bedrock Service für die systematische Dokumentation und Verifizierung der Eingabedaten. Durch die Bereitstellung einer Struktur für die Formalisierung dieses informellen Wissens garantiert die Lösung dessen Langlebigkeit und Anwendbarkeit auf nachfolgende Kohorten von Mitarbeitern in einer Organisation. Dieses Bestreben stellt nicht nur die nachhaltige Aufrechterhaltung der operativen Exzellenz sicher, sondern verbessert auch die Wirksamkeit von Schulungsprogrammen durch die Einbeziehung praktischer Kenntnisse, die durch direkte Erfahrung erworben wurden.
Diese Demoanwendung ist ein Proof-of-Concept für eine Anwendung zur Dokumentenerstellung mit Amazon Transcribe und Amazon Bedrock.
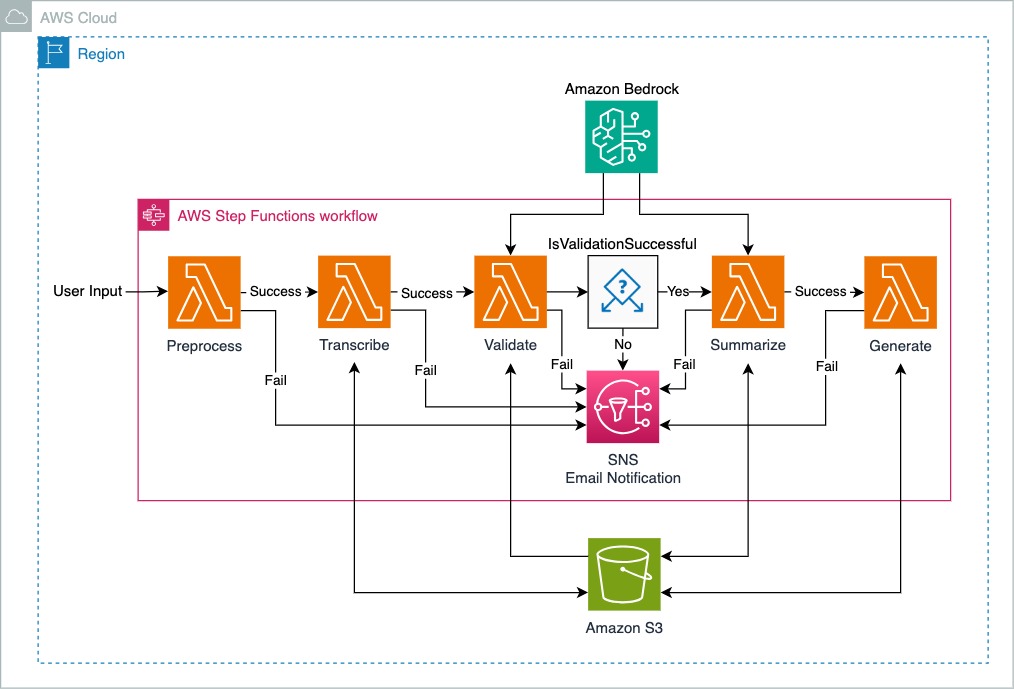
Das Diagramm zeigt eine Lösungsarchitektur für einen von AWS Step Functions orchestrierten Workflow innerhalb einer AWS Cloud-Region. Der Workflow besteht aus mehreren Schritten zur Verarbeitung von Benutzereingaben, mit Mechanismen für die Erfolgs- und Fehlerbehandlung bei jedem Schritt. Nachfolgend finden Sie eine Beschreibung des Prozessablaufs:
Benutzereingabe : Der Workflow wird mit Benutzereingaben initiiert, um die preprocess Lambda-Funktion auszulösen.
Vorverarbeitung : Die Eingabe wird zunächst vorverarbeitet. Bei Erfolg geht es zum transcribe über; Wenn dies fehlschlägt, veranlasst es Amazon SNS, Benachrichtigungen zu versenden.
Transkribieren : Dieser Schritt übernimmt die Ausgabe des vorherigen Schritts. Eine erfolgreiche Transkription geht zum Schritt „Validieren“ über und die Transkriptionsausgaben werden im Amazon S3-Bucket gespeichert.
Validieren : Die transkribierten Daten werden validiert. Basierend auf dem Validierungsergebnis weicht der Workflow ab:
Zusammenfassen : Wenn die Daten nach der Validierung erfolgreich zusammengefasst wurden, wird der zusammengefasste Text im Amazon S3-Bucket gespeichert. Wenn dies fehlschlägt, veranlasst es Amazon SNS, Benachrichtigungen zu versenden.
Amazon Bedrock ist der Kerndienst, der die Lambda-Funktionen Validate und Summarize unterstützt.
Generieren : Dieser letzte Schritt generiert das endgültige Dokument aus dem zusammengefassten Text. Sollte dies fehlschlagen, veranlasst es Amazon SNS, Benachrichtigungen zu versenden.
Jeder Schritt im Prozess ist mit „Erfolgreich“- oder „Fehlgeschlagen“-Pfaden gekennzeichnet, was die Fähigkeit des Workflows anzeigt, Fehler in verschiedenen Phasen zu behandeln. Bei einem Fehler wird Amazon SNS verwendet, um Benachrichtigungen an den Benutzer zu senden.
Der AWS Step Functions-Workflow fungiert als zentraler Orchestrator, der sicherstellt, dass jede Aufgabe in der richtigen Reihenfolge ausgeführt wird und den Erfolg oder Misserfolg jedes Schritts angemessen behandelt.
Die Datei cdk.json teilt dem CDK Toolkit mit, wie Ihre App ausgeführt werden soll.
Dieses Projekt ist wie ein Standard-Python-Projekt eingerichtet. Der Initialisierungsprozess erstellt auch eine virtuelle Umgebung innerhalb dieses Projekts, die im Verzeichnis .venv gespeichert ist. Um die virtuelle Umgebung zu erstellen, wird davon ausgegangen, dass sich in Ihrem Pfad eine ausführbare python3 (oder python für Windows) mit Zugriff auf das venv -Paket befindet. Wenn die automatische Erstellung der virtuellen Umgebung aus irgendeinem Grund fehlschlägt, können Sie die virtuelle Umgebung manuell erstellen.
So erstellen Sie manuell eine virtuelle Umgebung unter MacOS und Linux:
$ python3 -m venv .venvNachdem der Init-Prozess abgeschlossen und die virtuelle Umgebung erstellt wurde, können Sie Ihre virtuelle Umgebung mit dem folgenden Schritt aktivieren.
$ source .venv/bin/activateWenn Sie eine Windows-Plattform verwenden, würden Sie die virtuelle Umgebung wie folgt aktivieren:
% .venvScripts activate.batSobald die virtuelle Umgebung aktiviert ist, können Sie die erforderlichen Abhängigkeiten installieren.
$ pip install -r requirements.txt Um zusätzliche Abhängigkeiten hinzuzufügen, beispielsweise andere CDK-Bibliotheken, fügen Sie diese einfach zu Ihrer setup.py Datei hinzu und führen Sie den Befehl pip install -r requirements.txt erneut aus.
An diesem Punkt können Sie nun die CloudFormation-Vorlage für diesen Code synthetisieren.
$ cdk synth Um zusätzliche Abhängigkeiten hinzuzufügen, beispielsweise andere CDK-Bibliotheken, fügen Sie diese einfach zu Ihrer setup.py Datei hinzu und führen Sie den Befehl pip install -r requirements.txt erneut aus.
Sie müssen einen Bootstrap durchführen, wenn Sie cdk zum ersten Mal unter einem bestimmten Konto und in einer bestimmten Region ausführen.
$ cdk bootstrap
Sobald das Bootstrapping abgeschlossen ist, können Sie mit der Bereitstellung von cdk fortfahren.
$ cdk deploy
Wenn Sie es zum ersten Mal bereitstellen, kann der Vorgang zum Erstellen mehrerer Docker-Images in ECS (Amazon Elastic Container Service) etwa 30 bis 45 Minuten dauern. Bitte haben Sie etwas Geduld, bis es fertig ist. Anschließend wird mit der Bereitstellung des Docgen-Stacks begonnen, was normalerweise etwa 5–8 Minuten dauert.
Sobald der Bereitstellungsprozess abgeschlossen ist, sehen Sie die Ausgabe des CDK im Terminal und können den Status auch in Ihrer CloudFormation-Konsole überprüfen.
Um das CDK zu löschen, sobald Sie es nicht mehr verwenden, um zukünftige Kosten zu vermeiden, können Sie es entweder über die Konsole löschen oder den folgenden Befehl im Terminal ausführen.
$ cdk destroyMöglicherweise müssen Sie auch den vom CDK generierten S3-Bucket manuell löschen. Bitte stellen Sie sicher, dass Sie alle generierten Ressourcen löschen, um Kosten zu vermeiden.
cdk ls listet alle Stacks in der App aufcdk synth gibt die synthetisierte CloudFormation-Vorlage auscdk deploy stellt diesen Stack in Ihrem Standard-AWS-Konto/Ihrer Standard-AWS-Region bereitcdk diff vergleicht den bereitgestellten Stack mit dem aktuellen Statuscdk docscdk destroy zerstört einen oder mehrere angegebene Stacks code # Root folder for code for this solution
├── lambdas # Root folder for all lambda functions
│ ├── preprocess # Lambda function that processes user input, and outputs audio files uris for Amazon Transcribe
│ ├── transcribe # Lambda function that triggers Amazon Transcribe batch transcription
│ ├── validate # Lambda function that analyzes answers from Amazon Transcribe using LLMs from Amazon Bedrock
│ ├── summarize # Lambda function that summarizes on-topic texts from Amazon Transcribe using LLMs from Amazon Bedrock
│ └── generate # Lambda function that generates documents from the summary.
└── code_stack.py # Amazon CDK stack that deploys all AWS resources
Um die DocGen-Anwendung an die Integration Ihrer eigenen Daten anzupassen, sollten die folgenden Schritte befolgt werden:
Nach der Bereitstellung erleichtert die AWS CDK-Infrastruktur die automatische Übertragung von Audiodateien in den angegebenen Amazon S3-Bucket. Anschließend kann die Ausführung der AWS Step Function initiiert werden, um die Verarbeitungsphase zu starten.
Sobald die Lösung bereitgestellt ist, können Sie Ihre E-Mail zum SNS-Thema abonnieren, um Benachrichtigungen zu erhalten.
Bitte folgen Sie den SNS-E-Mail-Benachrichtigungen.
Wenn ein Schritt im StepFunction-Workflow fehlschlägt, erhalten Sie eine E-Mail-Benachrichtigung.
Nach der Bereitstellung können Sie die bereitgestellte AWS State Machine mit dem folgenden Befehl auslösen:
aws stepfunctions start-execution
--state-machine-arn "arn:aws:states:<your aws region>:<your account id>:stateMachine:genai-knowledge-capture-stack-state-machine"
--input "{"documentName": "<your document name>", "audioFileFolderUri": "s3://<your s3 bucket>/assets/audio_samples/what is amazon bedrock/"}"
Weitere Informationen finden Sie unter BEITRAGEN.
Diese Bibliothek ist unter der MIT-0-Lizenz lizenziert. Siehe die LICENSE-Datei.


