php rag
v1.1.0
Diese Anwendung verwendet LLM (Large Language Model) GPT-4o, auf das über die OpenAI-API zugegriffen wird, um Text basierend auf der Benutzereingabe zu generieren. Mithilfe der Benutzereingabe werden relevante Informationen aus der Datenbank abgerufen und anschließend werden die abgerufenen Informationen zum Generieren des Textes verwendet. Dieser Ansatz kombiniert die Leistungsfähigkeit von Transformatoren und den Zugriff auf Quelldokumente.
In dieser speziellen Anwendung wird die Datenbank von über 1000 Websites nach Informationen durchsucht, die sich auf eine bestimmte Person beziehen. Die eigentliche Herausforderung besteht darin, dass die gesuchte Person „Michał Żarnecki“ in zwei verschiedenen Kontexten als zwei verschiedene Personen mit demselben Namen erscheint. Ziel ist es, nicht nur spezifische Informationen zu finden, sondern auch den Kontext zu verstehen und Fehler wie das Vermischen von Informationen über zwei verschiedene Personen mit demselben Namen zu vermeiden.
Ich habe die in dieser Anwendung verwendeten Konzepte mit weiteren Einzelheiten im Artikel auf medium.com beschrieben: https://medium.com/@michalzarnecki88/a-guide-to-using-llm-retrieval-augmented-generation-with-php-3bff25ce6616
Für die Einrichtung müssen Sie zunächst Docker und Docker Compose https://docs.docker.com/compose/install/ installiert haben.
In der CLI ausführen: cd app/src && composer install
Sprachmodell einrichten – wählen Sie aus den folgenden Optionen: Option mit OpenAI-API
„A“ mit kostenlosem Modell über lokales Ollama API3
„B“ mit OpenAI-API
Option B ist einfacher und erfordert weniger CPU- und RAM-Ressourcen, Sie benötigen jedoch den OpenAI-API-Schlüssel https://platform.openai.com/settings/profile?tab=api-keys Option A erfordert mehr CPU- und RAM-Ressourcen, kann aber ausgeführt werden es lokal mit der Ollama-API. Für diese Option ist es gut, eine GPU zu haben.
Befolgen Sie die nachstehenden Anweisungen für die bevorzugte Option A oder B:
Wenn Sie Ollama lokal einrichten möchten, verwenden Sie bitte die Anweisungen am Ende dieser Datei. Bei Verwendung von Docker ist dies jedoch nicht erforderlich.
*Ollama bietet lokale API-Serving-LLMs: „Mit großen Sprachmodellen loslegen.“ https://ollama.com/
docker-compose up
*TIPP: Das Skript muss zuerst die Quelldokumente transformieren, was sogar 30 Minuten dauern kann. Wenn Sie etwas Zeit sparen möchten, entfernen Sie einfach einen Teil der Dokumente aus app/src/documents.
Warten Sie, bis die Einrichtung der Container abgeschlossen ist. In den Konsolenprotokollen sollte Folgendes angezeigt werden:
php-app | Loaded documents complete
php-app | Postgres is ready - executing command
php-app | [Sat Nov 02 11:32:28.365214 2024] [core:notice] [pid 1:tid 1] AH00094: Command line: 'apache2 -D FOREGROUND'
Sie können die Anwendung als API verwenden, indem Sie die folgenden Anforderungen verwenden:
Option A ollama:
curl -d '{"prompt":"what is result of 2+2?"}' -H "Content-Type: application/json" -X POST http://127.0.0.1:2037/processOllama.php?api
Option B OpenAI GPT:
curl -d '{"prompt":"what is result of 2+2?"}' -H "Content-Type: application/json" -X POST http://127.0.0.1:2037/processGpt.php?api
Führen Sie docker Interactive docker exec -it php-app sh aus
In der CLI ausführen: php minicli rag
Frage stellen
##### INPUT:
What is the result of 2 + 2?
##### RESPONSE:
The result of 2 + 2 is 4.
##### INPUT:
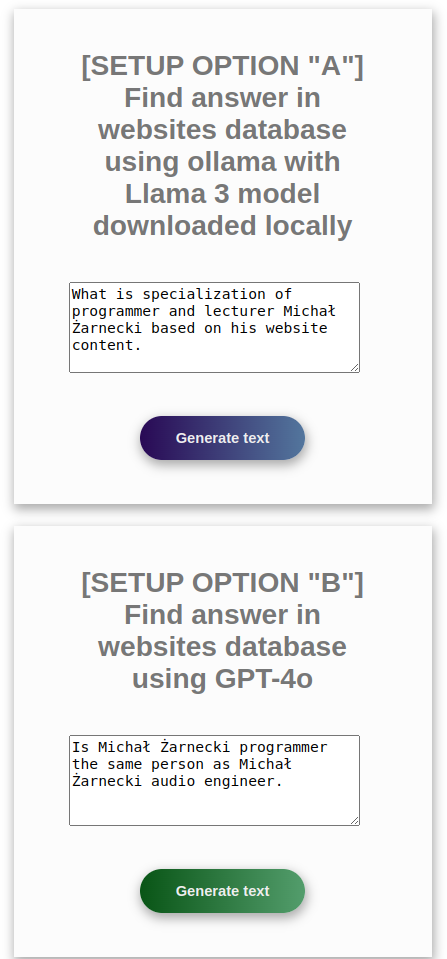
what is specialization of Michał Żarnecki based on his website content
##### RESPONSE:
Michał Żarnecki is a programmer and lecturer specializing in several key areas related to modern software development and data-driven technologies.
His expertise includes:
1. **Programming Languages**: Python, PHP, JavaScript.
2. **AI and Machine Learning**: Designing systems and solutions related to artificial intelligence and machine learning.
3. **Data Mining and Big Data**: Extracting valuable insights from large datasets.
4. **Natural Language Processing (NLP)**: Working on systems that understand and generate human language.
5. **Software Development Frameworks**: Utilizing various tools and frameworks such as Streamlit, TensorFlow, PyTorch, and langchain.
6. **Database Systems**: Implementing and working with databases like PostgreSQL, Elasticsearch, Neo4j, and others.
His portfolio highlights projects such as an AI chatbot for analyzing company documents and a self-driving vehicle based on TensorFlow and Raspberry Pi.
Additionally, he has contributed to conferences and created e-learning courses focused on machine learning, underscoring his dual role as a developer and educator.
##### INPUT:
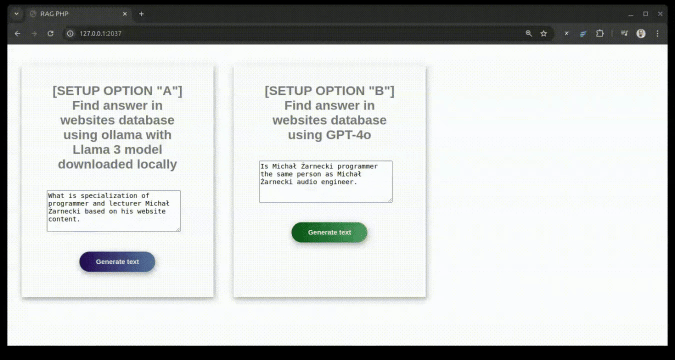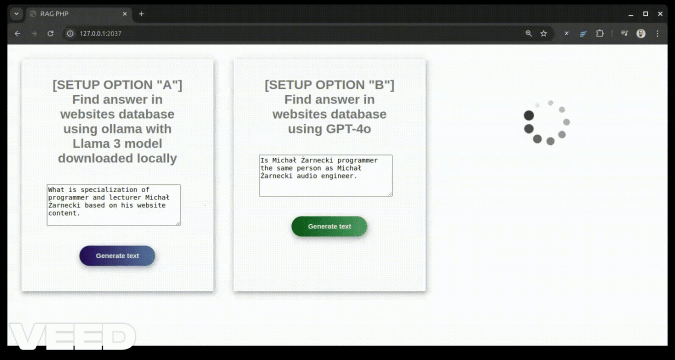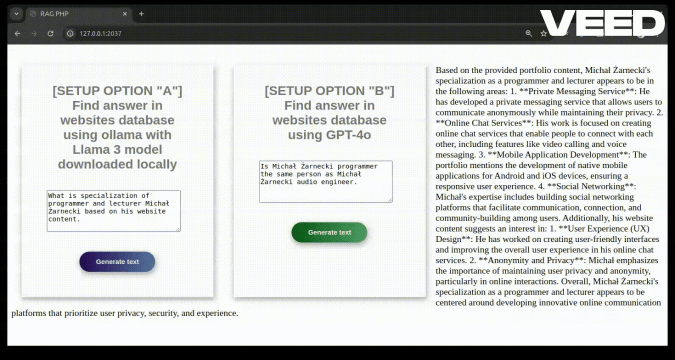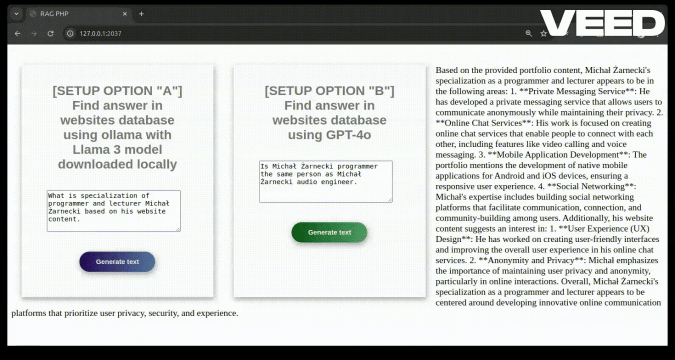
Is Michał Żarnecki programmer the same person as Michał Żarnecki audio engineer?
##### RESPONSE:
Based on the information provided, it appears that Michał Żarnecki the programmer and Michał Żarnecki the audio engineer are not the same person.
Here’s why:
1. **Fields of Expertise**:
- Michał Żarnecki, the audio engineer, was a well-known operator and reżyser dźwięku (sound director) in Poland, with notable contributions to the Polish film industry, as mentioned in the Wikipedia excerpt.
- Michal Żarnecki, the programmer, has a portfolio focused on programming in Python, PHP, and JavaScript, with projects related to AI, machine learning, data mining, and software development.
2. **Lifespan**:
- Michał Żarnecki the audio engineer was born on November 12, 1946, and passed away on November 21, 2016.
- The projects listed in Michał Żarnecki the programmer’s portfolio date from 2014 to 2016, which would be conflicting if he had passed away in 2016 and was actively working in those years.
3. **Occupational Focus**:
- The audio engineer has a career documented in film sound engineering and education.
- The programmer’s career is centered around software development, mobile applications, ERP systems, and consulting in technology.
Given the distinct differences in their professional domains, timelines, and expertise, it is highly unlikely that they are the same individual
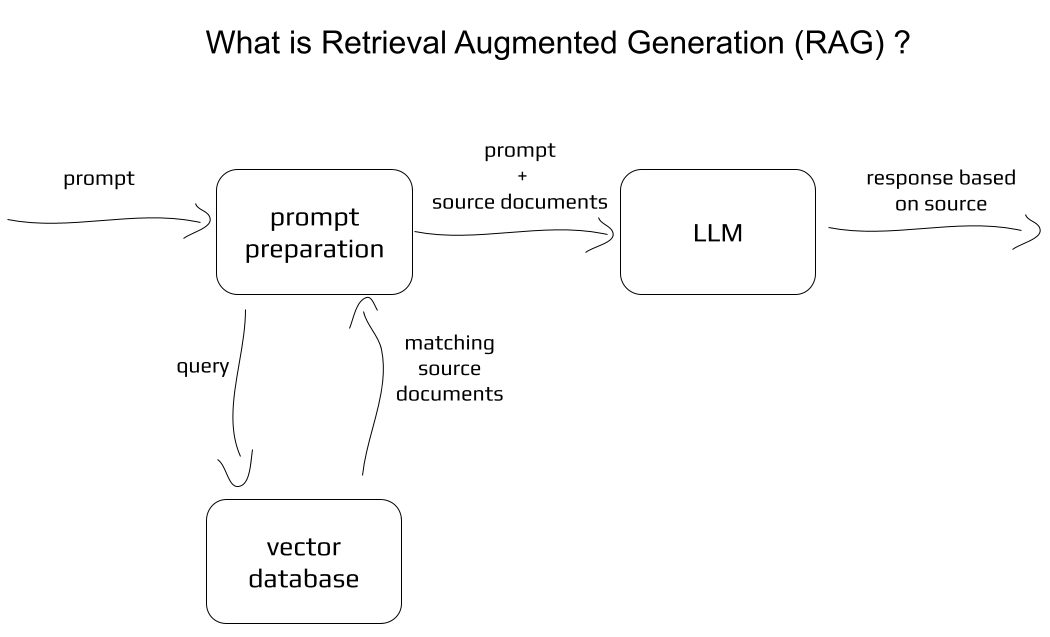
Grundkonzept:
Weitere Details für Nerds:
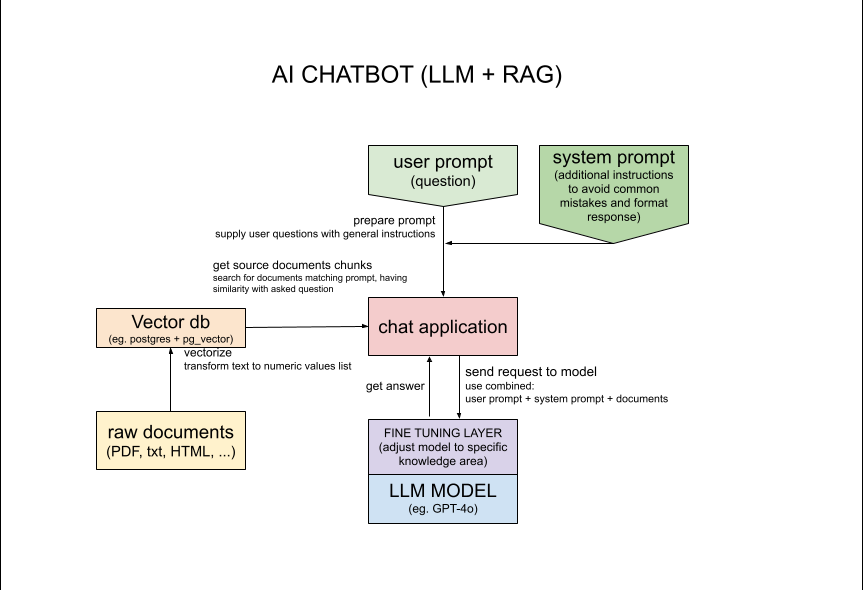
Um das Laden von Dokumenten zu beschleunigen oder mehr davon zum besseren Abrufen zu verwenden, manipulieren Sie den Wert $skipFirstN in app/src/service/DocumentLoader.php:20
Nach Änderungen an PHP-Skripten Docker mit folgenden Befehlen neu erstellen:
docker-compose rm
docker rmi -f php-rag
docker-compose up
Websites, die zum Füllen der Vektordatenbank verwendet werden, stammen aus dem Datensatz „Website Classification“ von Kaggle. Autor: Hetul Mehta, Link: https://www.kaggle.com/datasets/hetulmehta/website-classification?resource=download
Verwandte Artikel/Repositories:
https://medium.com/mlearning-ai/create-a-chatbot-in-python-with-langchain-and-rag-85bfba8c62d2
https://github.com/Krisseck/php-rag
https://ollama.com/download herunterollama pull llama3:latestollama pull mxbai-embed-large ollama list
NAME ID SIZE MODIFIED
mxbai-embed-large:latest 468836162de7 669 MB 7 seconds ago
llama3:latest 365c0bd3c000 4.7 GB 17 seconds ago
ollama serve startenapp/src/loadDocuments.php (Standard). Bitte teilen Sie mir mit, wenn Sie Probleme oder Verbesserungsbedarf haben. Sie können mich unter der E-Mail-Adresse [email protected] kontaktieren. Fühlen Sie sich frei, Fehler zu melden und Upgrades in Pull-Requests vorzuschlagen.


