korpatbert
1.0.0
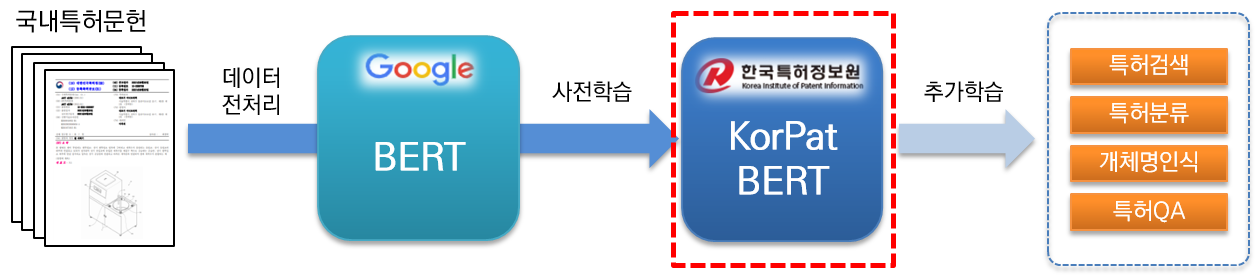
KorPatBERT (Korean Patent BERT) ist ein KI-Sprachmodell, das vom Korea Patent Information Service erforscht und entwickelt wurde.
Um koreanische Probleme bei der Verarbeitung natürlicher Sprache im Patentbereich zu lösen und eine intelligente Informationsinfrastruktur in der Patentbranche vorzubereiten, ist eine Vorschulung an einer großen Menge inländischer Patentdokumente (Basis: etwa 4,06 Millionen Dokumente, groß: etwa 5,06 Millionen Dokumente) erforderlich basiert auf der Architektur des bestehenden Google BERT-Basismodells (Vorschulung) und wird kostenlos zur Verfügung gestellt.
Es handelt sich um ein leistungsstarkes vorab trainiertes Sprachmodell, das auf den Patentbereich spezialisiert ist und für verschiedene Aufgaben der Verarbeitung natürlicher Sprache verwendet werden kann.
[KorPatBERT-Basis]
[KorPatBERT-groß]
[KorPatBERT-Basis]
[KorPatBERT-groß]
Ungefähr 10 Millionen Hauptnomen und zusammengesetzte Substantive wurden aus den Patentdokumenten extrahiert, die beim Lernen von Sprachmodellen verwendet wurden, und diese wurden dem Benutzerwörterbuch des koreanischen Morphemanalysators Mecab-ko hinzugefügt und dann über Google SentencePiece in Unterwörter unterteilt Tokenizer (Mecab-ko Sentencepiece Patent Tokenizer).
| Modell | Top@1(ACC) |
|---|---|
| Google BERT | 72,33 |
| KorBERT | 73,29 |
| KOBERT | 33,75 |
| KrBERT | 72,39 |
| KorPatBERT-Basis | 76,32 |
| KorPatBERT-groß | 77.06 |
| Modell | Top@1(ACC) | Top@3(ACC) | Top@5(ACC) |
|---|---|---|---|
| KorPatBERT-Basis | 61,91 | 82,18 | 86,97 |
| KorPatBERT-groß | 62,89 | 82,18 | 87,26 |
| Programmname | Version | Pfad zur Installationsanleitung | Erforderlich? |
|---|---|---|---|
| Python | 3,6 und höher | https://www.python.org/ | Y |
| Anakonda | 4.6.8 und höher | https://www.anaconda.com/ | N |
| Tensorfluss | 2.2.0 und höher | https://www.tensorflow.org/install/pip?hl=ko | Y |
| Satzstück | 0,1,96 oder höher | https://github.com/google/sentencepiece | N |
| mecab-ko | 0.996-en-0.0.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| mecab-ko-dic | 2.1.1 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| mecab-python | 0.996-en-0.9.2 | https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/ | Y |
| python-mecab-ko | 1.0.11 oder höher | https://pypi.org/project/python-mecab-ko/ | Y |
| Keras | 2.4.3 und höher | https://github.com/keras-team/keras | N |
| bert_for_tf2 | 0,14,4 und höher | https://github.com/kpe/bert-for-tf2 | N |
| tqdm | 4.59.0 und höher | https://github.com/tqdm/tqdm | N |
| soynlp | 0,0,493 oder höher | https://github.com/lovit/soynlp | N |
Installation URL: https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/
mecab-ko > 0.996-ko-0.9.2
mecab-ko-dic > 2.1.1
mecab-python > 0.996-ko-0.9.2
from korpat_tokenizer import Tokenizer
# (vocab_path=Vocabulary 파일 경로, cased=한글->True, 영문-> False)
tokenizer = Tokenizer(vocab_path="./korpat_vocab.txt", cased=True)
# 테스트 샘플 문장
example = "본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다."
# 샘플 토크나이즈
tokens = tokenizer.tokenize(example)
# 샘플 인코딩 (max_len=토큰 최대 길이)
ids, _ = tokenizer.encode(example, max_len=256)
# 샘플 디코딩
decoded_tokens = tokenizer.decode(ids)
# 결과 출력
print("Length of Token dictionary ===>", len(tokenizer._token_dict.keys()))
print("Input example ===>", example)
print("Tokenized example ===>", tokens)
print("Converted example to IDs ===>", ids)
print("Converted IDs to example ===>", decoded_tokens)
Length of Token dictionary ===> 21400
Input example ===> 본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다.
Tokenized example ===> ['[CLS]', '본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.', '[SEP]']
Converted example to IDs ===> [5, 58, 554, 32, 2716, 6554, 817, 20418, 20308, 20514, 15, 732, 15572, 39, 1634, 12, 11, 5934, 20514, 20367, 9, 315, 16, 5922, 17, 33, 279, 20399, 16971, 26, 5934, 20514, 13, 674, 26, 11, 10132, 1686, 33, 3781, 15, 11950, 12, 64, 87, 12, 3958, 315, 10, 51, 39, 25, 11, 5934, 20514, 15, 1803, 12889, 399, 24, 25, 118, 12, 11, 817, 20418, 20308, 299, 20367, 10, 439, 56, 13, 18, 14, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Converted IDs to example ===> ['본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.']
※ Es handelt sich um dasselbe wie die Google BERT-Basislernmethode. Anwendungsbeispiele finden Sie in Abschnitt 2.3 특허분야 사전학습 언어모델(KorPatBERT) 사용자 매뉴얼 .
Wir verbreiten das Sprachmodell des Korea Patent Information Institute durch bestimmte Verfahren an daran interessierte Organisationen, Unternehmen und Forscher. Bitte füllen Sie das Bewerbungsformular und die Vereinbarung gemäß dem unten stehenden Bewerbungsverfahren aus und senden Sie die Bewerbung per E-Mail an die zuständige Person.
| Dateiname | Erläuterung |
|---|---|
| pat_all_mecab_dic.csv | Mecab Patent-Benutzerwörterbuch |
| lm_test_data.tsv | Klassifizierungsbeispieldatensatz |
| korpat_tokenizer.py | KorPat Tokenizer-Programm |
| test_tokenize.py | Beispiel für die Verwendung des Tokenizers |
| test_tokenize.ipynb | Beispiel für die Nutzung des Tokenizers (Jupiter) |
| test_lm.py | Beispiel für die Verwendung eines Sprachmodells |
| test_lm.ipynb | Beispiel für die Verwendung eines Sprachmodells (Jupyter) |
| korpat_bert_config.json | KorPatBERT-Konfigurationsdatei |
| korpat_vocab.txt | KorPatBERT-Vokabulardateien |
| model.ckpt-381250.meta | KorPatBERT-Modelldatei |
| model.ckpt-381250.index | KorPatBERT-Modelldatei |
| model.ckpt-381250.data-00000-of-00001 | KorPatBERT-Modelldatei |


