sandbox toy semantic search
1.0.0
################################################################################
# ____ _ ____ _ _ #
# / ___|___ | |__ ___ _ __ ___ / ___| __ _ _ __ __| | |__ _____ __ #
# | | / _ | '_ / _ '__/ _ ___ / _` | '_ / _` | '_ / _ / / #
# | |__| (_) | | | | __/ | | __/ ___) | (_| | | | | (_| | |_) | (_) > < #
# _______/|_| |_|___|_| ___| |____/ __,_|_| |_|__,_|_.__/ ___/_/_ #
# #
# This project is part of Cohere Sandbox, Cohere's Experimental Open Source #
# offering. This project provides a library, tooling, or demo making use of #
# the Cohere Platform. You should expect (self-)documented, high quality code #
# but be warned that this is EXPERIMENTAL. Therefore, also expect rough edges, #
# non-backwards compatible changes, or potential changes in functionality as #
# the library, tool, or demo evolves. Please consider referencing a specific #
# git commit or version if depending upon the project in any mission-critical #
# code as part of your own projects. #
# #
# Please don't hesitate to raise issues or submit pull requests, and thanks #
# for checking out this project! #
# #
################################################################################
Betreuer: jcudit und lsgos
Projekt gepflegt bis mindestens (JJJJ-MM-TT): 14.03.2023
Dies ist ein Beispiel für die Verwendung der Cohere-API zum Aufbau einer einfachen semantischen Suchmaschine. Es soll nicht produktionsbereit sein oder effizient skaliert werden (obwohl es für diese Zwecke angepasst werden könnte), sondern dient vielmehr dazu, die einfache Erstellung einer Suchmaschine zu demonstrieren, die auf Darstellungen basiert, die von den Large Language Models (LLMs) von Cohere erstellt wurden.
Der hier verwendete Suchalgorithmus ist ziemlich einfach: Er findet mithilfe des co.embed Endpunkts einfach den Absatz, der der Darstellung der Frage am ehesten entspricht. Dies wird weiter unten ausführlicher erläutert, aber hier ist ein einfaches Diagramm, was vor sich geht. Zuerst zerlegen wir den Eingabetext in eine Reihe von Absätzen, speichern deren Adressen in der Eingabe in einer Liste und generieren mit co.embed eine Vektoreinbettung für jeden Absatz:
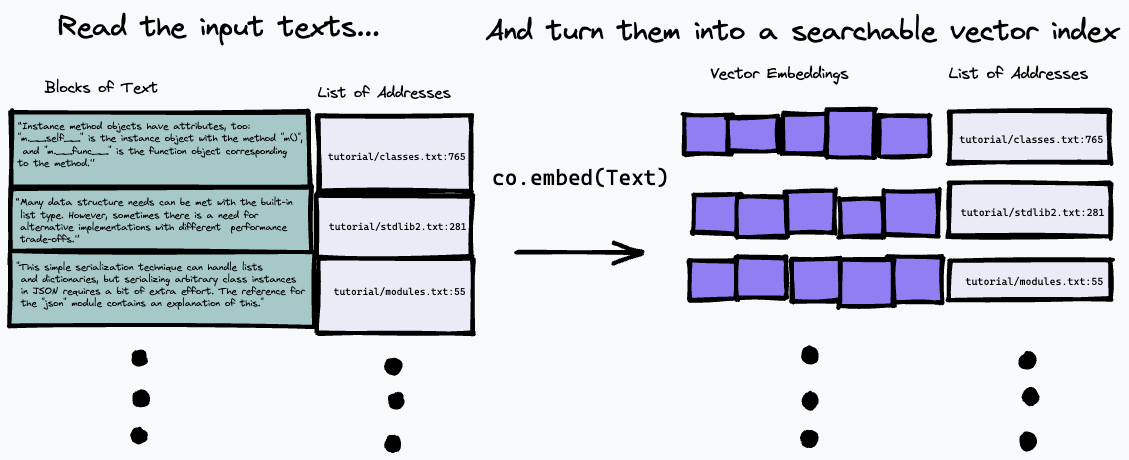
Dann können wir unseren Index abfragen, indem wir die Textabfrage einbetten und mithilfe eines Maßes der Vektorähnlichkeit (wir haben die Kosinusähnlichkeit verwendet) die Absätze im Quelltext finden, die am ehesten übereinstimmen: 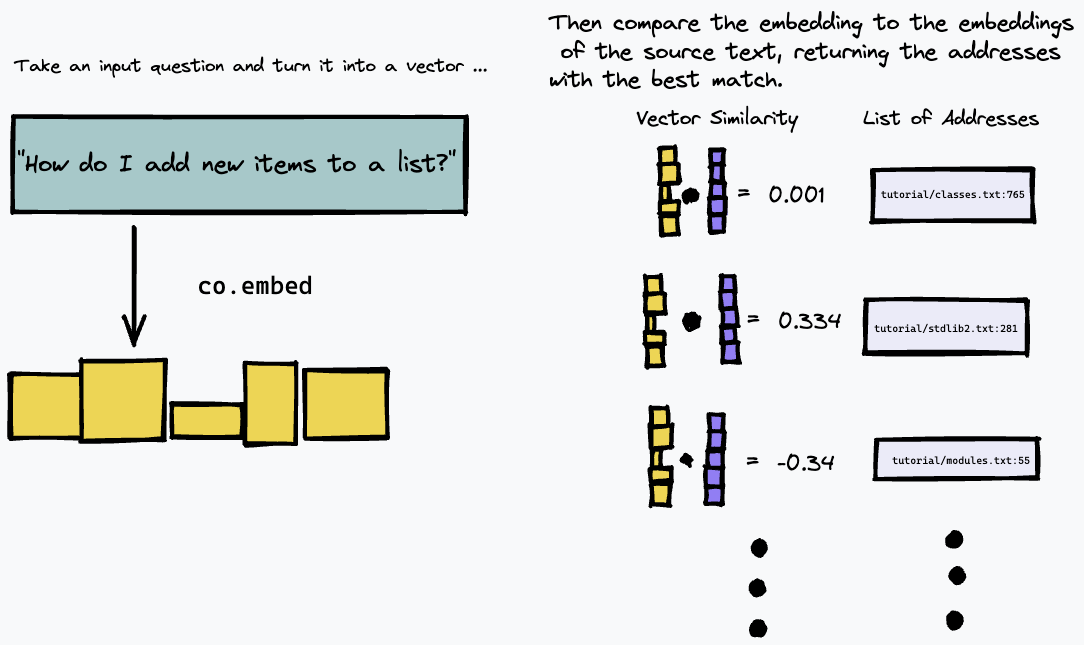
Daher funktioniert es am besten bei Textquellen, bei denen die Antwort auf eine bestimmte Frage wahrscheinlich durch einen konkreten Absatz im Text gegeben wird, wie z. B. technische Dokumentationen oder interne Wikis, die als Liste konkreter Anweisungen oder Fakten strukturiert sind. Es funktioniert beispielsweise nicht annähernd so gut bei der Beantwortung von Fragen zu Freiformtexten wie Romanen, bei denen die Informationen möglicherweise über mehrere Absätze verteilt sind. Sie müssten hierfür eine andere Methode zur Indexierung des Textes verwenden.
Dieses Repository baut beispielsweise eine einfache semantische Suchmaschine auf der Grundlage der Textversion der neuesten Python-Dokumentation auf.
Um die Python-Anforderungen zu installieren, stellen Sie sicher, dass Sie Poetry installiert haben und Folgendes ausführen:
# install python deps
poetry installSie sollten auch Docker installiert haben. Wenn Sie unter OS X Homebrew verwenden, empfehlen wir die Ausführung
brew install --cask dockerBevor Sie Docker zum ersten Mal unter OS
Sie benötigen außerdem einen Cohere-API-Schlüssel im COHERE_TOKEN . Holen Sie sich eines von der Cohere-Plattform (erstellen Sie bei Bedarf ein Konto) und schreiben Sie es in Ihre Umgebung
export COHERE_TOKEN= < MY_API_KEY > (wobei <MY_API_KEY> der Schlüssel ist, den Sie erhalten haben, ohne die Klammern <...> ).
Alternativ können Sie COHERE_TOKEN=<MY_API_KEY> als zusätzliches Argument an jeden unten aufgeführten make -Befehl übergeben.
Befolgen Sie diese Schritte, um zunächst einen semantischen Index Ihrer Dokumentensammlung zu erstellen. Diese Schritte erzeugen einen semantischen Index für die offiziellen Python-Dokumente, könnten aber für beliebige Datensammlungen angepasst werden.
Laden Sie zunächst die Python-Dokumentation herunter, indem Sie einen der folgenden Befehle ausführen.
Wenn Sie schnell loslegen möchten, laufen Sie
make download-python-docs-smallum den Dokumentensatz auf das Python-Tutorial zu beschränken. Wir empfehlen dies nur für einen Schnelltest, da die Ergebnisse sehr begrenzt sein werden .
Wenn Sie die Suchmaschine in der gesamten Python-Dokumentation testen möchten, führen Sie sie aus
make download-python-docsBeachten Sie jedoch, dass die Erstellung der Einbettungen Stunden dauern wird (obwohl dies nur einmal erfolgen muss).
Wenn Sie alternativ mit Ihrem eigenen Text experimentieren möchten, laden Sie ihn einfach als .txt Dateien in ein Verzeichnis namens txt/ in diesem Repository herunter.
Sobald Sie Text haben, müssen wir ihn in einen Suchindex mit Einbettungen und Adressen verarbeiten.
Dies kann mit dem Befehl erfolgen
make embeddings Vorausgesetzt, Ihr Zieltext befindet sich im Verzeichnis ./txt/ .
Der Befehl durchsucht das Verzeichnis ./txt/ rekursiv nach Dateien mit der Erweiterung .txt und erstellt eine einfache Datenbank mit den Einbettungen, dem Dateinamen und der Zeilennummer jedes Absatzes.
Warnung: Wenn Sie viel Text durchsuchen müssen, kann es eine Weile dauern, bis die Suche abgeschlossen ist!
Sobald Sie eine Datei embeddings.npz erstellt haben, können Sie mit dem folgenden Befehl ein Docker-Image erstellen, das einer einfachen REST-App dient, mit der Sie die von Ihnen erstellte Datenbank abfragen können:
make buildAnschließend können Sie den Server mit starten
make runDies ist für ein einfaches Beispiel etwas übertrieben, soll aber der Tatsache Rechnung tragen, dass die Erstellung eines Indexes für einen großen Textkörper relativ langsam ist, und stellt sicher, dass die Abfrage an die Engine schnell erfolgt.
Wenn Sie dieses Projekt als Baustein für eine echte Anwendung verwenden möchten, möchten Sie wahrscheinlich Ihre Datenbank mit Texteinbettungen in einer Serverarchitektur verwalten und sie mit einem schlanken Client abfragen. Das Packen des Servers als Docker-Anwendung bedeutet, dass es sehr einfach ist, ihn durch die Bereitstellung in einem Cloud-Dienst in eine „echte“ Anwendung umzuwandeln.
Wenn Sie für eine der folgenden Optionen ein neues Terminalfenster öffnen, denken Sie daran, sie auszuführen
export COHERE_TOKEN= < MY_API_KEY > Die bei weitem einfachste Möglichkeit besteht darin, unser Hilfsskript auszuführen:
scripts/ask.sh " My query here "um die Datenbank abzufragen. Das Skript benötigt ein optionales zweites Argument, das die Anzahl der gewünschten Ergebnisse angibt.
Das Skript öffnet eine modifizierte VIM-Schnittstelle mit den folgenden Befehlen:
q um den Vorgang zu beenden.Im oberen Bereich wird Ihnen die Position im Dokument angezeigt, an der sich das Ergebnis befindet.
Sobald der Server läuft, können Sie ihn mit einer einfachen REST-API abfragen. Sie können die API direkt erkunden, indem Sie hier zu /docs#/default/search_search_post gehen. Es handelt sich um eine einfache JSON-REST-API. So können Sie mit curl eine Abfrage stellen:
curl -X POST -H "Content-Type: application/json" -d '{"query": "How do I append to a list?", "num_results": 3}' http://localhost:8080/search
Dadurch wird eine JSON-Liste der Länge num_results zurückgegeben, jeweils mit dem Dateinamen und der Zeilennummer ( doc_url und block_url ) der Blöcke, die Ihrer Abfrage semantisch am nächsten kamen. Aber Sie möchten wahrscheinlich nur den Teil der Dateien lesen, der die beste Antwort ist.
Da wir lokale Textdateien durchsuchen, ist es tatsächlich etwas einfacher, die Ausgabe mit Befehlszeilentools zu analysieren. Verwenden Sie das bereitgestellte Python-Skript utils/query_server.py um es in der Befehlszeile abzufragen. query_server.py druckt die Ergebnisse im Standardformat file_name:line_number: aus, sodass wir die tatsächlichen Ergebnisse auf nette Weise durchblättern können, indem wir den Quickfix-Modus von vim nutzen.
Vorausgesetzt, Sie haben vim auf Ihrem Computer, können Sie das einfach tun
vim +cw -M -q <(python utils/query_server.py "my_query" --num_results 3)
um vim dazu zu bringen, die indizierten Textdateien an den vom Suchalgorithmus zurückgegebenen Speicherorten zu öffnen. (Verwenden Sie :qall um sowohl das Fenster als auch den Quickfix-Navigator zu schließen.) Sie können die zurückgegebenen Ergebnisse mit :cn und :cp durchgehen. Die Ergebnisse sind nicht perfekt; Da es sich um eine semantische Suche handelt, ist zu erwarten, dass die Übereinstimmung etwas unscharf ist. Trotzdem finde ich oft, dass Sie die Antwort auf Ihre Frage bereits in den ersten paar Ergebnissen erhalten. Mit der API von Cohere können Sie Ihre Frage in natürlicher Sprache ausdrücken und mit nur wenigen Codezeilen eine überraschend effektive Suchmaschine erstellen.
Einige gut auszuprobierende Abfragen im Fall von Python-Dokumenten, die zeigen, dass die Suche bei generischen Fragen in natürlicher Sprache gut funktioniert, sind:
How do I put new items in a list? (Beachten Sie, dass diese Frage die Verwendung des Schlüsselworts „append“ vermeidet und nicht genau mit der Erläuterung des Anhängens in den Dokumenten übereinstimmt (sie sagen, dass es zum Hinzufügen neuer Elemente am Ende einer Liste verwendet wird). Die semantische Suche stellt jedoch korrekt fest, dass das (Der relevante Absatz ist immer noch die beste Übereinstimmung.)How do I put things in a list?Are dictionary keys in insertion order?What is the difference between a tuple and a list? (Beachten Sie bei dieser Frage, dass das erste Ergebnis für mich eine FAQ zu genau diesem Thema ist, jedoch mit einer anders formulierten Frage. Da es sich jedoch um eine semantische Suche handelt, wählt unser Algorithmus korrekt ein Ergebnis aus, das der Bedeutung entspricht, nicht nur dem Wortlaut unserer Anfrage)How do I remove an item from a set?How do list comprehensions work? Dieses Repo verwendet eine sehr einfache Strategie, um ein Dokument zu indizieren und nach der besten Übereinstimmung zu suchen. Zunächst wird jedes Dokument in Absätze oder „Blöcke“ unterteilt. Anschließend wird für jeden Absatz co.embed aufgerufen, um mithilfe des Sprachmodells von Cohere eine Vektoreinbettung zu generieren. Anschließend speichert es jeden Einbettungsvektor zusammen mit dem entsprechenden Dokument und der Zeilennummer des Absatzes in einem einfachen Array als „Datenbank“.
Um die Suche tatsächlich durchzuführen, verwenden wir die FAISS-Ähnlichkeitssuchbibliothek. Wenn wir eine Abfrage erhalten, verwenden wir denselben Cohere-API-Aufruf, um die Abfrage einzubetten. Anschließend verwenden wir FAISS, um die Spitze zu finden
Wenn Sie Fragen oder Kommentare haben, melden Sie bitte ein Problem oder kontaktieren Sie uns auf Discord.
Wenn Sie zu diesem Projekt beitragen möchten, lesen Sie bitte CONTRIBUTORS.md in diesem Repository und unterzeichnen Sie die Lizenzvereinbarung für Mitwirkende, bevor Sie Pull-Anfragen einreichen. Ein Link zum Signieren der Cohere CLA wird generiert, wenn Sie zum ersten Mal eine Pull-Anfrage an ein Cohere-Repository stellen.
Toy Semantic Search verfügt über eine MIT-Lizenz, wie in der LICENSE-Datei zu finden.


