cape webservices
1.0.0
Einstiegspunkt für alle Backend-Cape-Webservices.
Die Frontend-Demo finden Sie hier (funktioniert nur, wenn Sie bereits ein Backend gestartet haben).
Cape ist eine Suite von Open-Source-Bibliotheken zur Verwaltung eines Frage-Antwort-Modells, das Fragen durch automatisches „Lesen“ von Dokumenten beantwortet. Es basiert auf modernsten maschinellen Lesemodellen, die auf riesigen Datensätzen trainiert wurden, und umfasst mehrere Mechanismen, um die Verwendung zu vereinfachen und basierend auf Benutzerfeedback zu verbessern. Es ist portabel konzipiert, funktioniert also auf einem einzelnen Laptop oder auf einem Cluster paralleler Maschinen, um die Berechnung zu beschleunigen, und ist Open Source-freundlich, sodass es auf allen Erfahrungsstufen verwendet werden kann.
Es ermöglicht Benutzern dies
Es gibt mehrere Möglichkeiten, Cape zu verwenden:
from cape_responder.responder_core import Responder
Responder.get_answers_from_documents('my-token','How easy is Cape to use', text ="Cape is an open source large-scale question answering system and is super easy to use!")
python3 -m cape_webservices.rundocker run -p 5050:5050 bloomsburyai/capeWir empfehlen mindestens 3 GB RAM und mindestens 2 moderne CPU-Kerne (4, wenn virtuell). Wenn Sie Docker verwenden, stellen Sie sicher, dass Sie die Speicherressourcengrenzen in den Docker-Einstellungen erhöhen.
Sie können eine eigenständige Version der Webanwendung ausführen, die ein Verwaltungs-Dashboard enthält. Aktualisieren Sie nach der Installation von Docker das Cape-Image und führen Sie es aus:
docker pull bloomsburyai/cape && docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape
Dadurch werden sowohl die Backend- als auch die Frontend-Webdienste gestartet. Standardmäßig werden auch Tunnel für beide erstellt und die öffentlichen URLs ausgegeben:
RANDOM_STRING_HERE .ngrok.io?configuration={"api":{"backendURL":"https:// RANDOM_STRING_HERE .ngrok .io:5050","timeout":"15000"}} Rufen Sie die neueste Version des Docker-Images ab (das Herunterladen aller Abhängigkeiten und eines Maschinenlesemodells dauert einige Augenblicke): docker pull bloomsburyai/cape
Führen Sie den Docker-Container aus und starten Sie darin eine IPython-Konsole mit dem folgenden Befehl: docker run -ti -p 5050:5050 -p 5051:5051 bloomsburyai/cape ipython3
Responder importieren: from cape_responder.responder_core import Responder
Stellen Sie eine Frage, speichern Sie die Antwort (eine Liste von Antworten) und zeigen Sie die erste Antwort an mit: response = Responder.get_answers_from_documents('my-token','How easy is Cape to use?', text="Cape is an open source large-scale question answering system and is super easy to use!"); print(response[0]['answerText'])
Wenn Sie mehr darüber erfahren möchten, wie die Antwort aussieht, zeigen Sie die vollständige Antwort mit folgendem Befehl an: print(response)
Um Cape nativ auf einem Linux-System zu installieren, werfen Sie einen Blick auf „deployment/Dockerfile“.
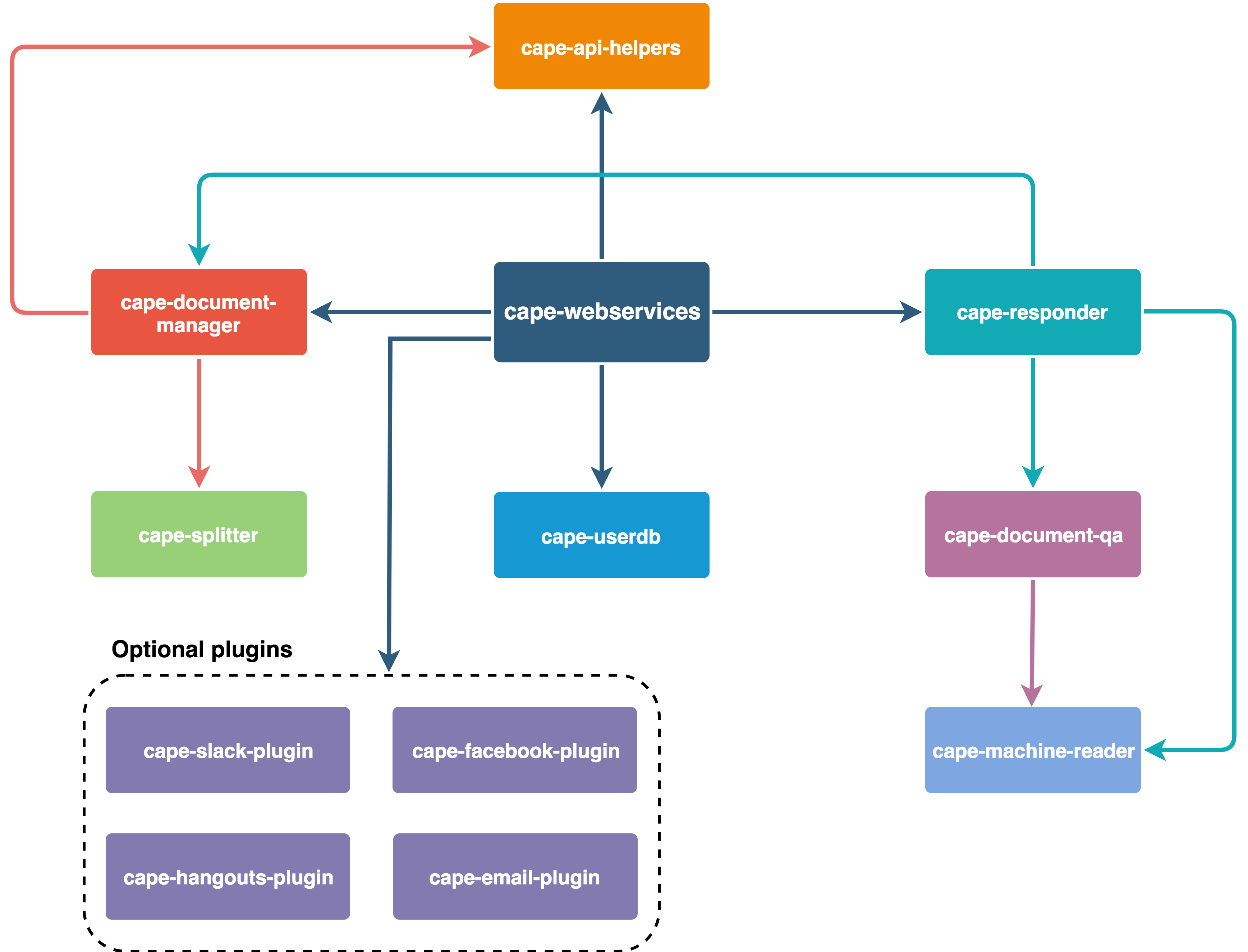
Zusammenfassend ist Cape wie folgt organisiert:


