mlmm evaluation
1.0.0
Bewertungsrahmen für mehrsprachige große Sprachmodelle
Dieses Repo enthält Benchmark-Datensätze und Bewertungsskripte für mehrsprachige große Sprachmodelle (LLMs). Diese Datensätze können zur Auswertung der Modelle in 26 verschiedenen Sprachen verwendet werden und umfassen drei verschiedene Aufgaben: ARC, HellaSwag und MMLU. Dies wird als Teil unseres Okapi-Frameworks für mehrsprachige, auf Anweisungen abgestimmte LLMs mit verstärkendem Lernen aus menschlichem Feedback veröffentlicht.
Derzeit unterstützen unsere Datensätze 26 Sprachen: Russisch, Deutsch, Chinesisch, Französisch, Spanisch, Italienisch, Niederländisch, Vietnamesisch, Indonesisch, Arabisch, Ungarisch, Rumänisch, Dänisch, Slowakisch, Ukrainisch, Katalanisch, Serbisch, Kroatisch, Hindi, Bengali, Tamil, Nepali, Malayalam, Marathi, Telugu und Kannada.
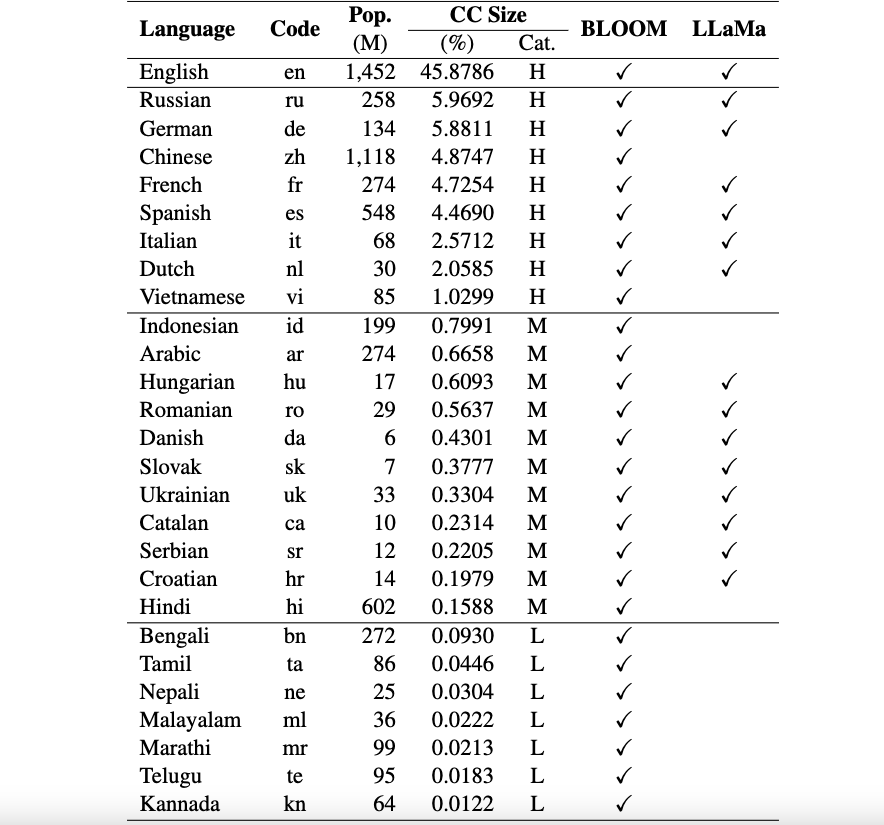
Diese Datensätze werden mithilfe von ChatGPT aus den ursprünglichen ARC-, HellaSwag- und MMLU-Datensätzen ins Englische übersetzt. Unser technisches Dokument für Okapi zur Beschreibung der Datensätze sowie der Bewertungsergebnisse für mehrere mehrsprachige LLMs (z. B. BLOOM, LLaMa und unsere Okapi-Modelle) finden Sie hier.
Nutzungs- und Lizenzhinweise : Unser Evaluierungsframework ist nur für Forschungszwecke bestimmt und lizenziert. Die Datensätze sind CC BY NC 4.0 (nur nichtkommerzielle Nutzung erlaubt) und sollten nicht außerhalb von Forschungszwecken verwendet werden.
Um lm-eval aus unserem Repository-Hauptzweig zu installieren, führen Sie Folgendes aus:
git clone https://github.com/nlp-uoregon/mlmm-evaluation.git
cd mlmm-evaluation
pip install -e " .[multilingual] " Zunächst müssen Sie die mehrsprachigen Bewertungsdatensätze mithilfe des folgenden Skripts herunterladen:
bash scripts/download.shUm Ihr Modell anhand von drei Aufgaben zu bewerten, können Sie das folgende Skript verwenden:
bash scripts/run.sh [LANG] [YOUR-MODEL-PATH]Wenn Sie beispielsweise unser vietnamesisches Okapi-Modell evaluieren möchten, können Sie Folgendes ausführen:
bash scripts/run.sh vi uonlp/okapi-vi-bloomWir führen eine Bestenliste, um den Fortschritt des mehrsprachigen LLM zu verfolgen.
Unser Framework wurde größtenteils vom lm-evaluation-harness-Repo von EleutherAI übernommen. Bitte geben Sie auch deren Repo an, wenn Sie den Code verwenden.
Wenn Sie die Daten, das Modell oder den Code in diesem Repository verwenden, geben Sie bitte Folgendes an:
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

