Grounding_LLMs_with_online_RL
1.0.0
Dieses Repository enthält den Code, der für unseren Artikel Grounding Large Language Models with Online Reinforcement Learning verwendet wird.
Weitere Informationen finden Sie auf unserer Website.
Wir führen eine funktionale Verankerung des LLM-Wissens in BabyAI-Text mithilfe der GLAM- Methode durch: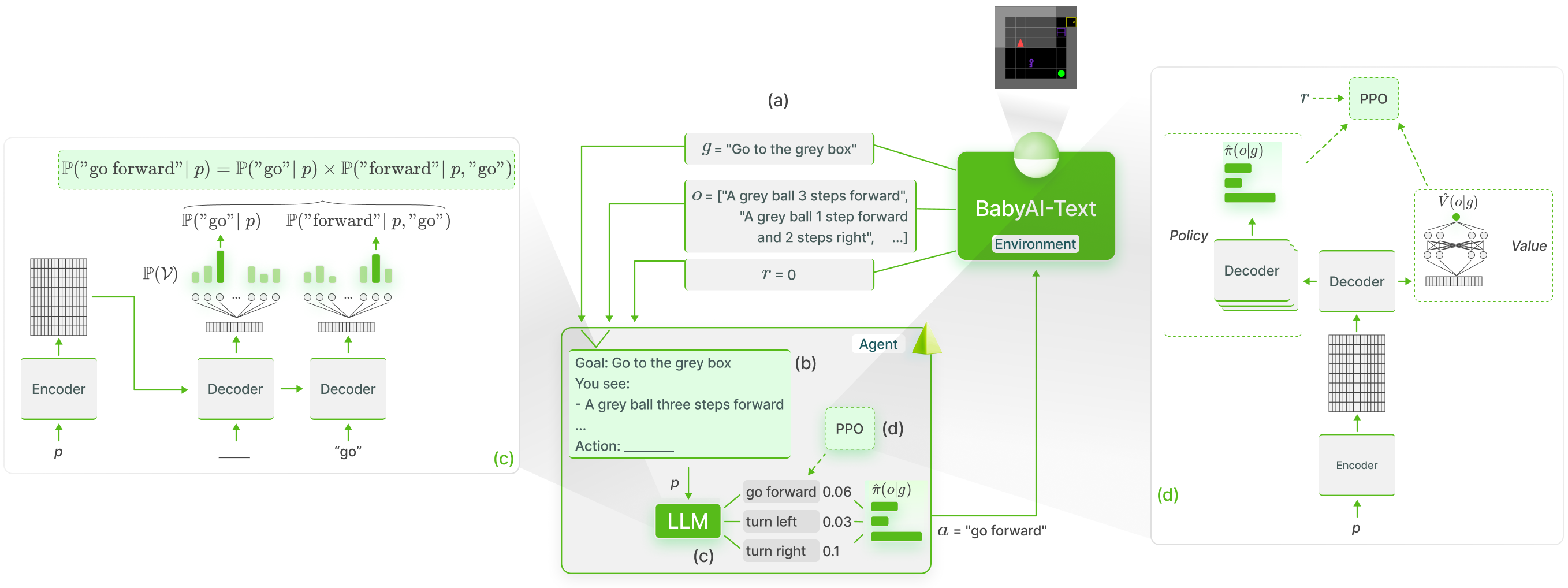
Wir veröffentlichen unsere BabyAI-Text-Umgebung zusammen mit dem Code, um unsere Experimente durchzuführen (sowohl das Training von Agenten als auch die Bewertung ihrer Leistung). Zur Verwendung von LLMs verlassen wir uns auf die Lamorel-Bibliothek.
Unser Repository ist wie folgt aufgebaut:
? Grounding_LLMs_with_online_RL
┣ babyai-text – unsere BabyAI-Text-Umgebung
┣ experiments – Code für unsere Experimente
┃ ┣ agents – Implementierung aller unserer Agenten
┃ ┃ ┣ bot – Bot-Agent, der den Bot von BabyAI nutzt
┃ ┃ ┣ random_agent – Agent, der gleichmäßig zufällig spielt
┃ ┃ ┣ drrn – DRRN-Agent von hier
┃ ┃ ┣ ppo – Agenten, die PPO verwenden
┃ ┃ ┃ ┣ symbolic_ppo_agent.py – SymbolicPPO angepasst an BabyAIs PPO
┃ ┃ ┃ ┗ llm_ppo_agent.py – unser LLM-Agent mit PPO am Boden
┃ ┣ configs – Lamorel-Konfigurationen für unsere Experimente
┃ ┣ slurm – Utils-Skripte zum Starten unserer Experimente auf einem SLURM-Cluster
┃ ┣ campaign – SLURM-Skripte, die zum Starten unserer Experimente verwendet werden
┃ ┣ train_language_agent.py – trainiert Agenten mit BabyAI-Text (LLMs und DRRN) -> enthält unsere Implementierung des PPO-Verlusts für LLMs sowie zusätzliche Köpfe zusätzlich zu LLMs
┃ ┣ train_symbolic_ppo.py – SymbolicPPO auf BabyAI trainieren (mit den Aufgaben von BabyAI-Text)
┃ ┣ post-training_tests.py – Generalisierungstests geschulter Agenten
┃ ┣ test_results.py – Dienstprogramme zum Formatieren von Ergebnissen
┃ ┗ clm_behavioral-cloning.py – Code zum Durchführen von Verhaltensklonen auf einem LLM mithilfe von Trajektorien
conda create -n dlp python=3.10.8; conda activate dlp
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
pip install -r requirements.txt
Installieren Sie BabyAI-Text : Siehe Installationsdetails im Paket babyai-text
Installieren Sie Lamorel
git clone https://github.com/flowersteam/lamorel.git; cd lamorel/lamorel; pip install -e .; cd ../..
Bitte verwenden Sie Lamorel zusammen mit unseren Konfigurationen. Beispiele unserer Trainingsskripte finden Sie in der Kampagne.
Um ein Sprachmodell in einer BabyAI-Text-Umgebung zu trainieren, muss die Datei train_language_agent.py verwendet werden. Dieses Skript (gestartet mit Lamorel) verwendet die folgenden Konfigurationseinträge:
rl_script_args :
seed : 1
number_envs : 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
num_steps : 1000 # Total number of training steps
max_episode_steps : 3 # Maximum number of steps in a single episode
frames_per_proc : 40 # The number of collected transitions to perform a PPO update will be frames_per_proc*number_envs
discount : 0.99 # Discount factor used in PPO
lr : 1e-6 # Learning rate used to finetune the LLM
beta1 : 0.9 # PPO's hyperparameter
beta2 : 0.999 # PPO's hyperparameter
gae_lambda : 0.99 # PPO's hyperparameter
entropy_coef : 0.01 # PPO's hyperparameter
value_loss_coef : 0.5 # PPO's hyperparameter
max_grad_norm : 0.5 # Maximum grad norm when updating the LLM's parameters
adam_eps : 1e-5 # Adam's hyperparameter
clip_eps : 0.2 # Epsilon used in PPO's losses clipping
epochs : 4 # Number of PPO epochs performed on each set of collected trajectories
batch_size : 16 # Minibatch size
action_space : ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs : ??? # Where to store logs
name_experiment : ' llm_mtrl ' # Useful for logging
name_model : ' T5small ' # Useful for logging
saving_path_model : ??? # Where to store the finetuned model
name_environment : ' BabyAI-MixedTestLocal-v0 ' # BabiAI-Text's environment
load_embedding : true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads : false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
template_test : 1 # Which prompt template to use to log evolution of action's probability (Section C of our paper). Choices or [1, 2].
nbr_obs : 3 # Number of past observation used in the promptDie Konfigurationseinträge, die sich auf das Sprachmodell selbst beziehen, finden Sie unter Lamorel.
Um die Leistung eines Agenten (z. B. eines trainierten LLM, BabyAIs Bot...) bei Testaufgaben zu bewerten, verwenden Sie post-training_tests.py und legen Sie die folgenden Konfigurationseinträge fest:
rl_script_args :
seed : 1
number_envs : 2 # Number of parallel envs to launch (steps will be synchronized, i.e. a step call will return number_envs observations)
max_episode_steps : 3 # Maximum number of steps in a single episode
action_space : ["turn_left","turn_right","go_forward","pick_up","drop","toggle"] # Possible actions for the agent
saving_path_logs : ??? # Where to store logs
name_experiment : ' llm_mtrl ' # Useful for logging
name_model : ' T5small ' # Useful for logging
saving_path_model : ??? # Where to store the finetuned model
name_environment : ' BabyAI-MixedTestLocal-v0 ' # BabiAI-Text's environment
load_embedding : true # Whether trained embedding layers should be loaded (useful when lm_args.pretrained=False). Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
use_action_heads : false # Whether action heads should be used instead of scoring. Setting both this and use_action_heads to True (lm_args.pretrained=False) creates our NPAE agent.
nbr_obs : 3 # Number of past observation used in the prompt
number_episodes : 10 # Number of test episodes
language : ' english ' # Useful to perform the French experiment (Section H4)
zero_shot : true # Whether the zero-shot LLM (i.e. without finetuning should be used)
modified_action_space : false # Whether a modified action space (e.g. different from the one seen during training) should be used
new_action_space : # ["rotate_left","rotate_right","move_ahead","take","release","switch"] # Modified action space
im_learning : false # Whether a LLM produced with Behavioral Cloning should be used
im_path : " " # Path to the LLM learned with Behavioral Cloning
bot : false # Whether the BabyAI's bot agent should be used

