Alpaka-rlhf
Feinabstimmung von LLaMA mit RLHF (Reinforcement Learning with Human Feedback).
Online-Demo
Änderungen am DeepSpeed Chat
Schritt 1
- alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py#main()
- Legen Sie spezielle Token fest
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Trainieren Sie nur auf Antworten und fügen Sie EOS hinzu
- Entfernen Sie end_of_conversation_token
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#PromptDataset# getitem
- Beschriftungen unterscheiden sich von der Eingabe
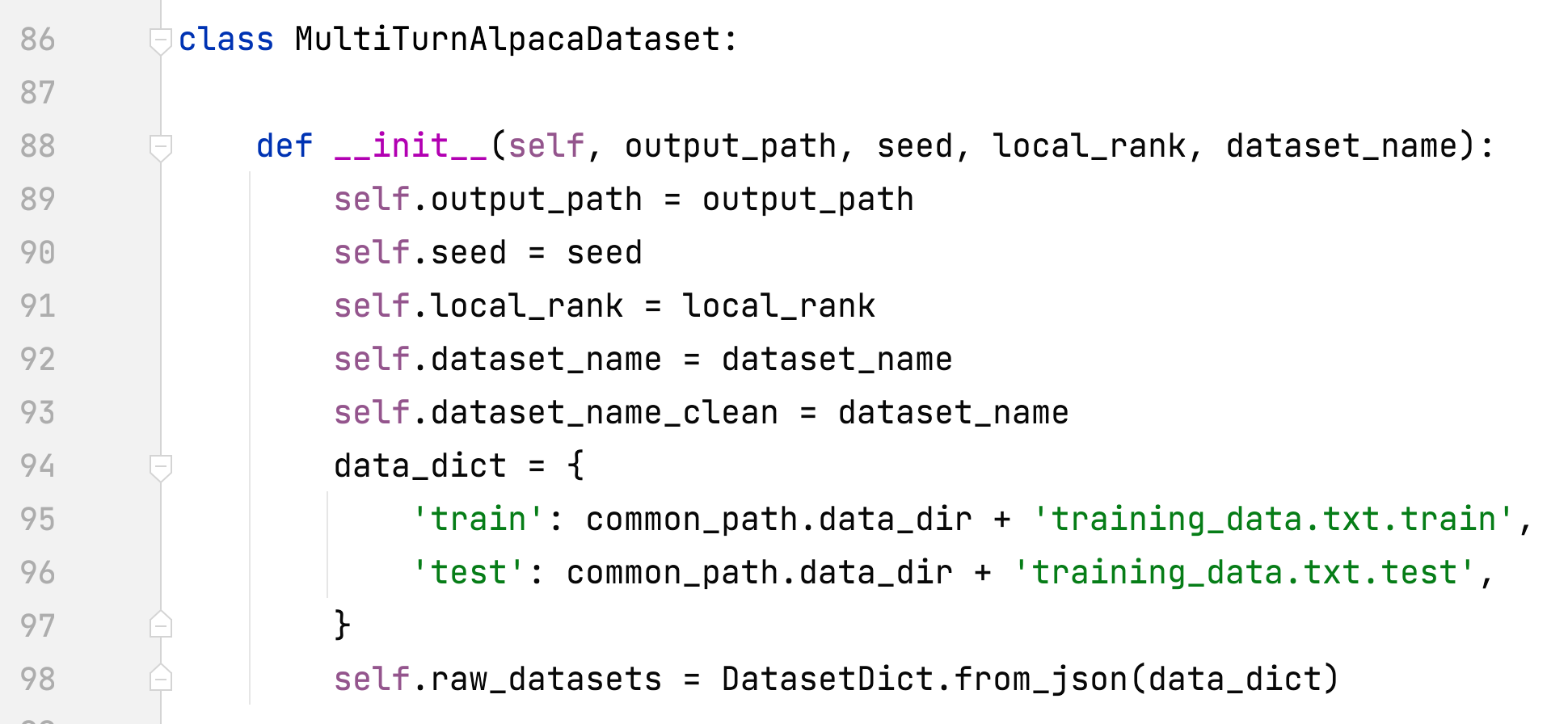
- alpaca_rlhf/deepspeed_chat/training/utils/data/raw_datasets.py#MultiTurnAlpacaDataset
- MultiTurnAlpacaDataset hinzufügen
- alpaca_rlhf/deepspeed_chat/training/utils/module/lora.py#convert_linear_layer_to_lora
- Unterstützt mehrere Modulnamen für Lora
Schritt 2
- alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py#main()
- Legen Sie spezielle Token fest
- alpaca_rlhf/deepspeed_chat/training/utils/model/reward_model.py#RewardModel#forward()
- Behebung der numerischen Instabilität
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Entfernen Sie end_of_conversation_token
Schritt 3
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py#main()
- Legen Sie spezielle Token fest
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#create_dataset_split()
- Fehler bei der maximalen Länge behoben
- alpaca_rlhf/deepspeed_chat/training/utils/data/data_utils.py#DataCollatorRLHF# Aufruf
- Fehler bei der Polsterung an der Seite behoben
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience
- alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#_generate_sequence
- Maskieren Sie die Token nach dem EOS
Stey by Step
- Alle drei Schritte auf 2 x A100 80G ausführen
- Datensätze
- Dahoas/rm-static Huggingface Paper GitHub
- MultiTurnAlpaca
- Dies ist eine Multi-Turn-Version des Alpaka-Datensatzes und basiert auf AlpacaDataCleaned und ChatAlpaca.
- Geben Sie zuerst das Verzeichnis ./alpaca_rlhf ein und führen Sie dann die folgenden Befehle aus:
- Schritt 1: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step1_supervised_finetuning/main.py --sft_only_data_path MultiTurnAlpaca --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b-hf --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --max_seq_len 512 --learning_rate 3e-4 --num_train_epochs 1 --gradient_accumulation_steps 8 --num_warmup_steps 100 --output_dir /root/autodl-tmp/rlhf/actor --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora --deepspeed --zero_stage 2
- Wenn --sft_only_data_path MultiTurnAlpaca hinzugefügt wird, entpacken Sie bitte zuerst data/data.zip.
- Schritt 2: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step2_reward_model_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --model_name_or_path decapoda-research/llama-7b -hf --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_eval_batch_size 64 --learning_rate 5e-4 --num_train_epochs 1 --gradient_accumulation_steps 1 --num_warmup_steps 0 --zero_stage 2 --deepspeed --output_dir /root/autodl-tmp/rlhf/critic --lora_dim 8 --lora_module_name q_proj,k_proj --only_optimize_lora
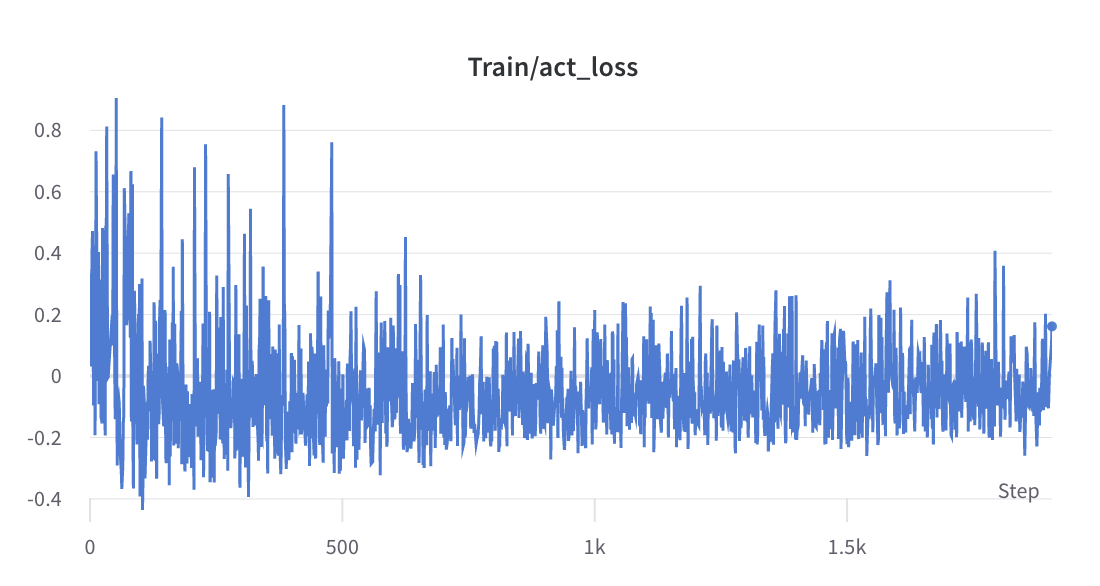
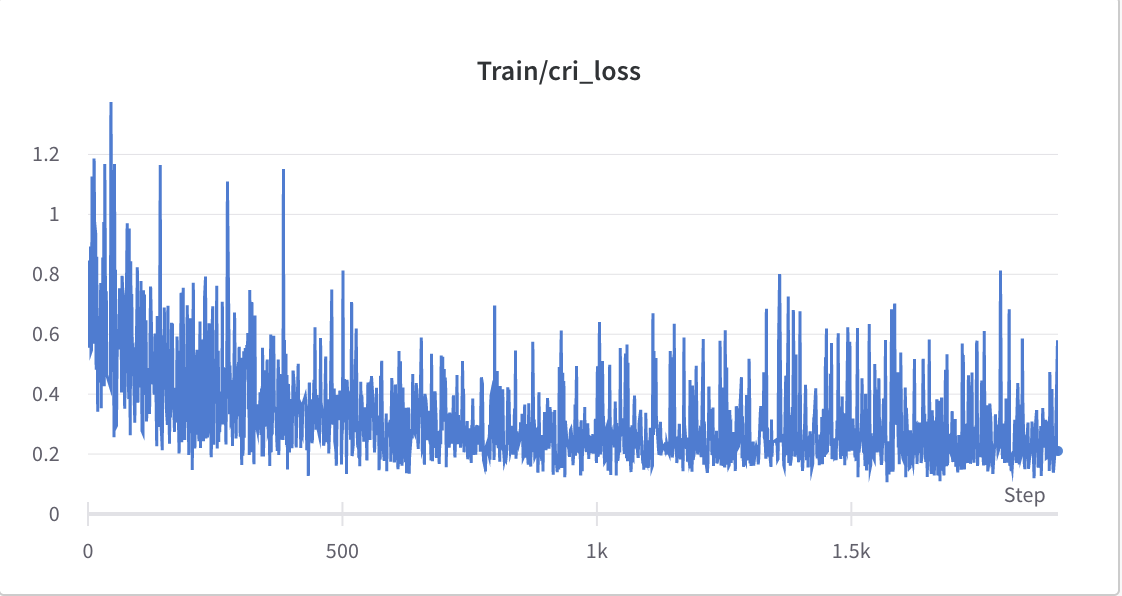
- Der Trainingsprozess von Schritt 2
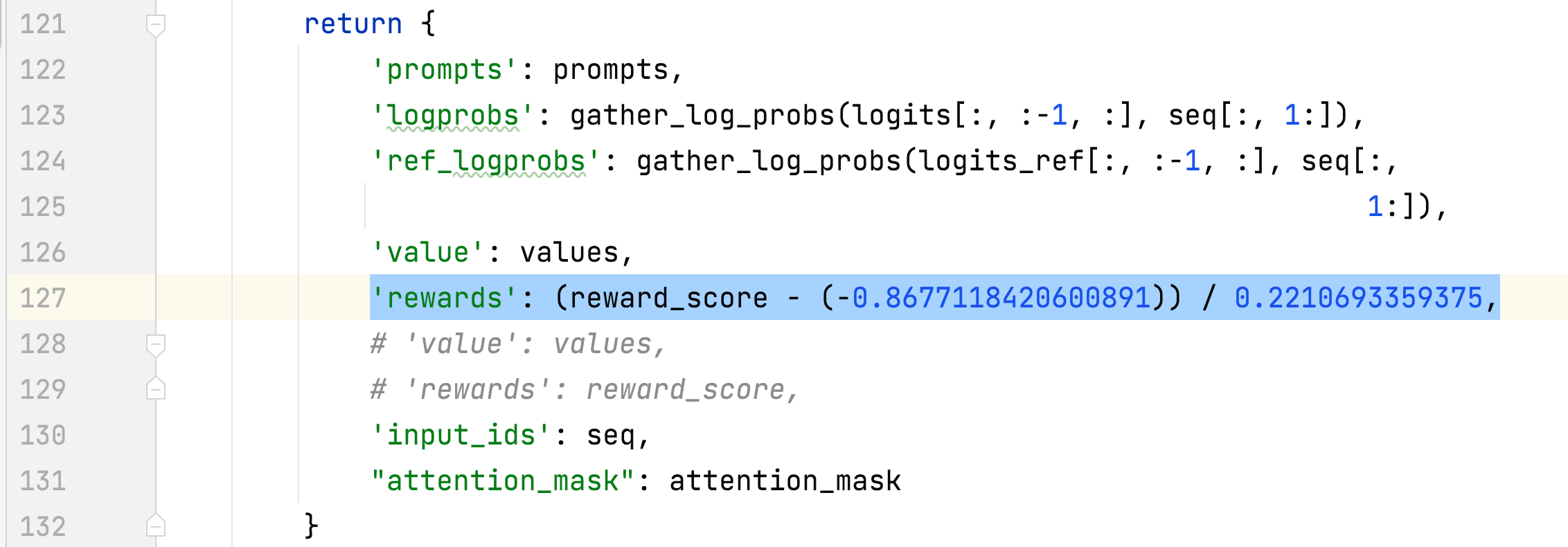
- Der Mittelwert und die Standardabweichung der Belohnung der ausgewählten Antworten werden erfasst und zur Normalisierung der Belohnung in Schritt 3 verwendet. In einem Experiment betragen sie -0,8677118420600891 bzw. 0,2210693359375 und werden im verwendet alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/ppo_trainer.py#DeepSpeedPPOTrainer#generate_experience Methoden: 'rewards': (reward_score - (-0.8677118420600891)) / 0.2210693359375.
- Schritt 3: sh run.sh --num_gpus 2 /tmp/pycharm_project_227/alpaca_rlhf/deepspeed_chat/training/step3_rlhf_finetuning/main.py --data_output_path /root/autodl-tmp/rlhf/tmp/ --actor_model_name_or_path /root/autodl-tmp/ rlhf/Schauspieler/ --tokenizer_name_or_path decapoda-research/llama-7b-hf --critic_model_name_or_path /root/autodl-tmp/rlhf/critic --actor_zero_stage 2 --critic_zero_stage 2 --num_padding_at_beginning 0 --per_device_train_batch_size 4 --per_device_mini_train_batch_size 4 --ppo_epochs 2 --actor_learning_rate 9.65e-6 --critic_learning_rate 5e-6 --gradient_accumulation_steps 1 --deepspeed --actor_lora_dim 8 --actor_lora_module_name q_proj --critic_lora_dim 8 --critic_lora_module_name q_proj,k_proj --only_optimize_lora --output_dir /root/autodl-tmp/rlhf/final
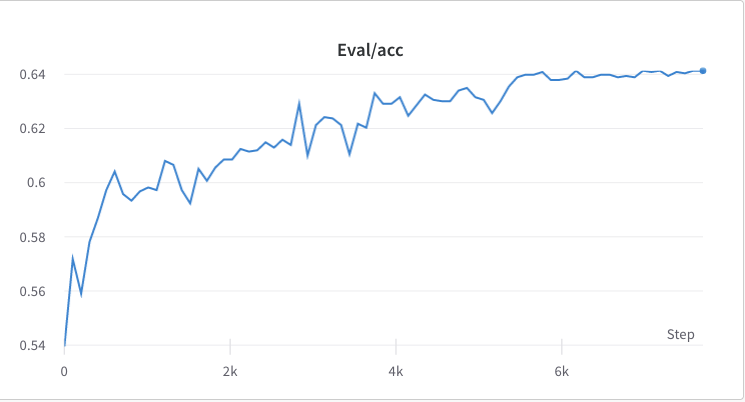
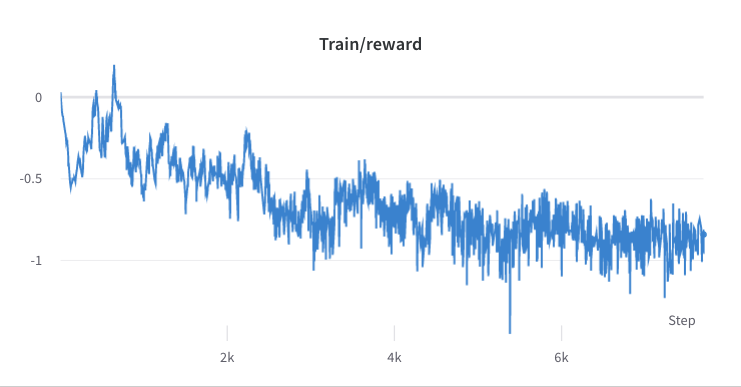
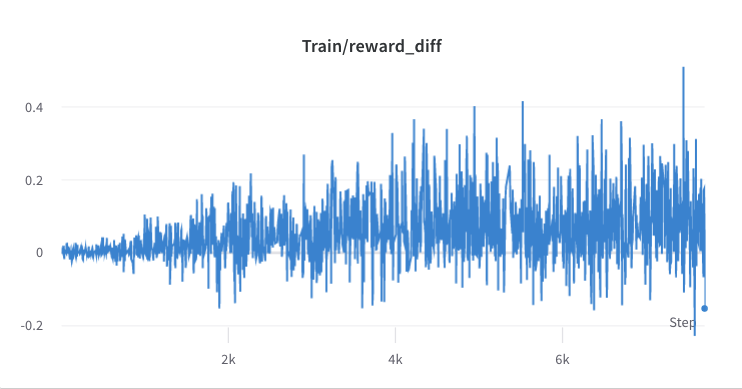
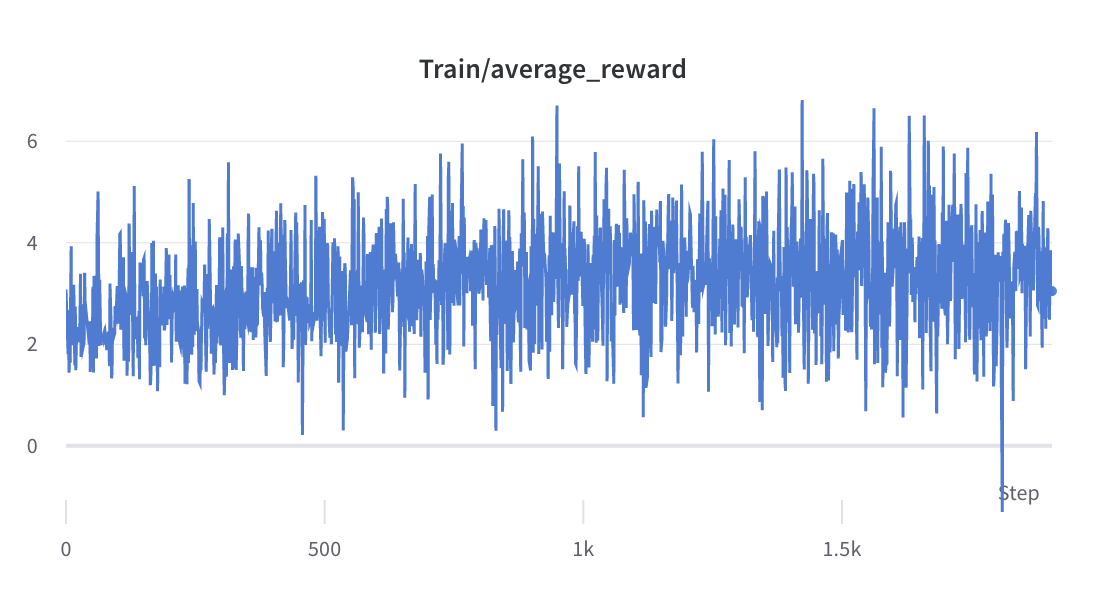
- Der Trainingsprozess von Schritt 3
- Schlussfolgerung
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/final/actor > rlhf_inference.log 2>&1 &
- nohup sh run_inference.sh 0 alpaca_rlhf/inference/llama_chatbot_gradio.py --path /root/autodl-tmp/rlhf/actor > sft_inference.log 2>&1 &
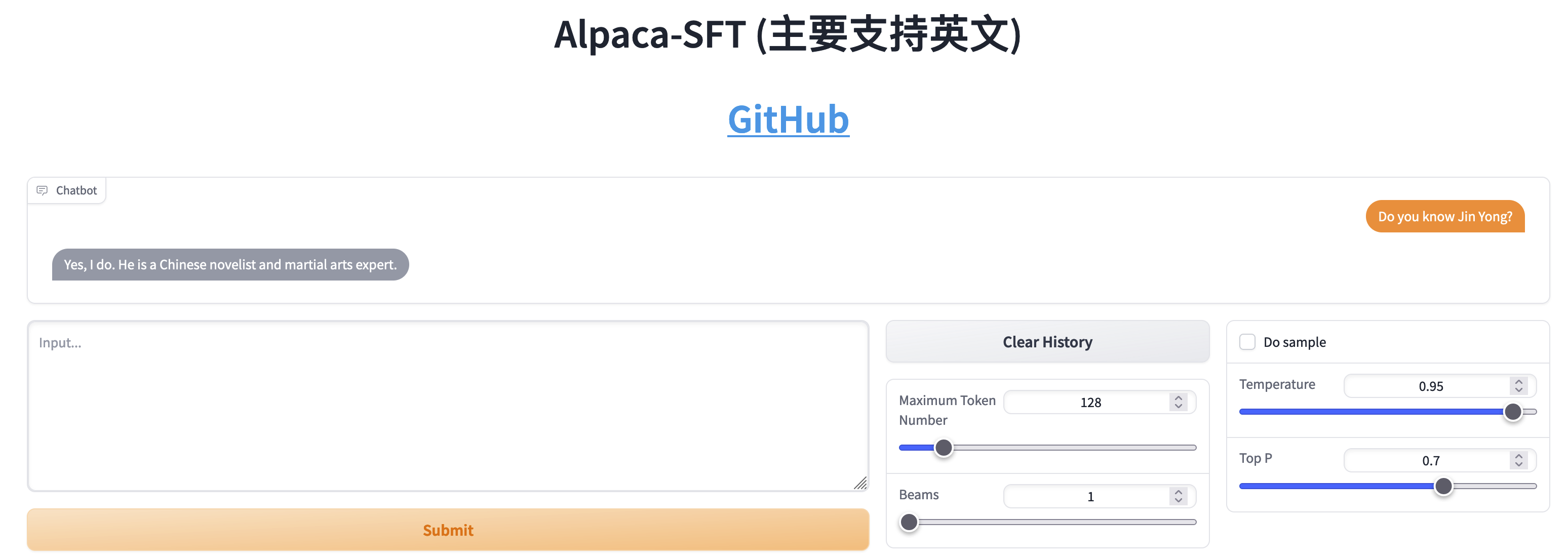
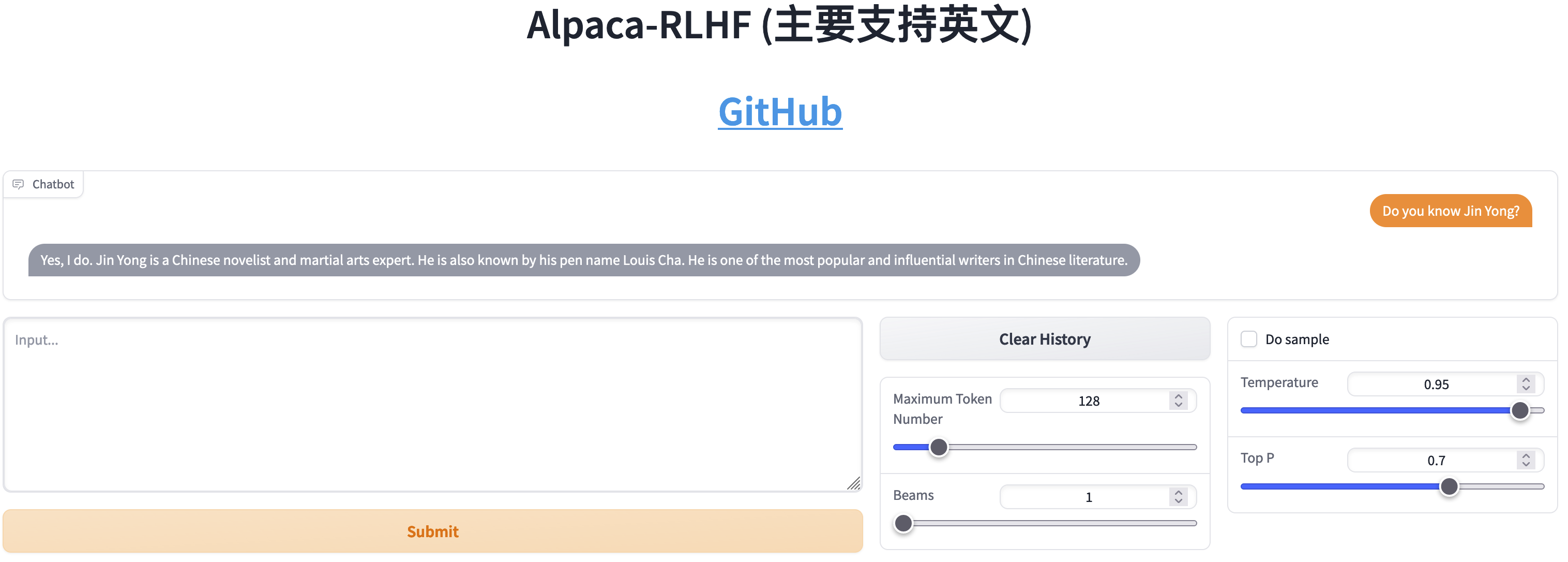
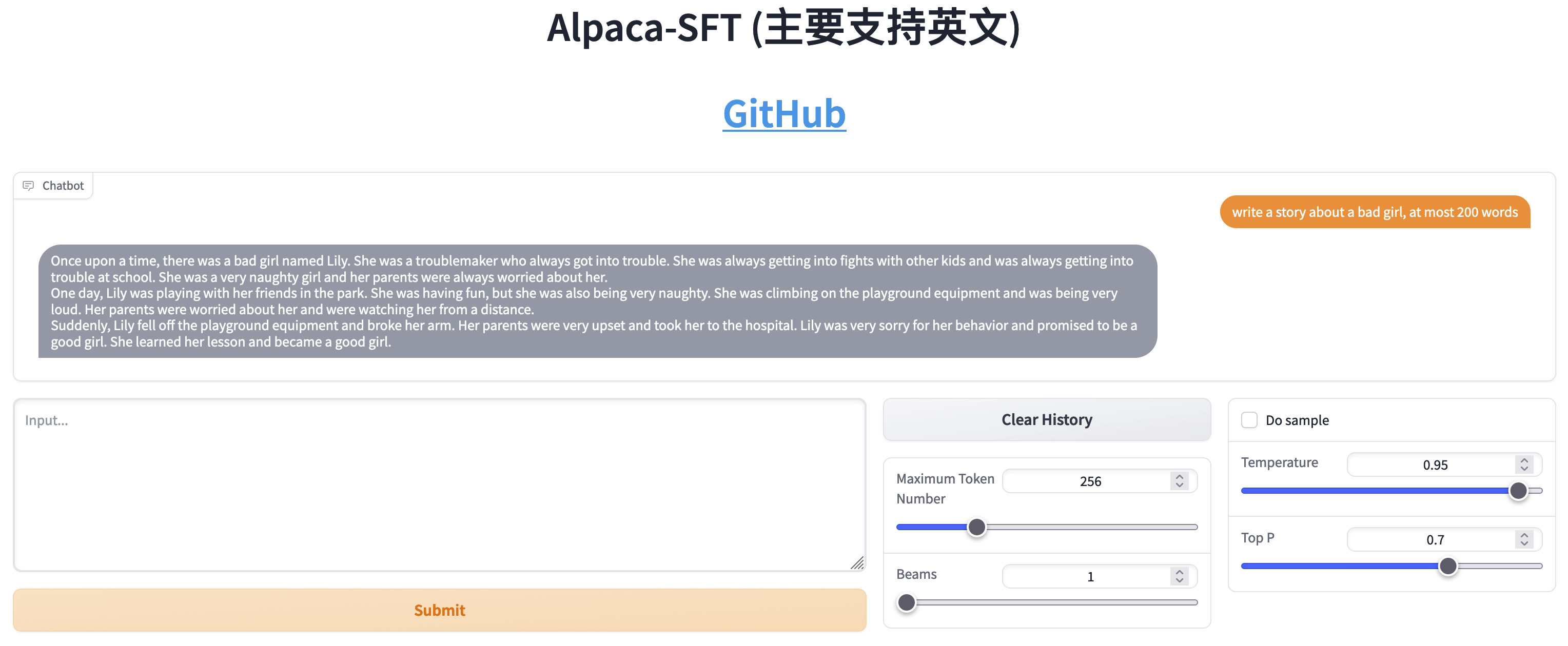
Vergleich zwischen SFT und RLHF
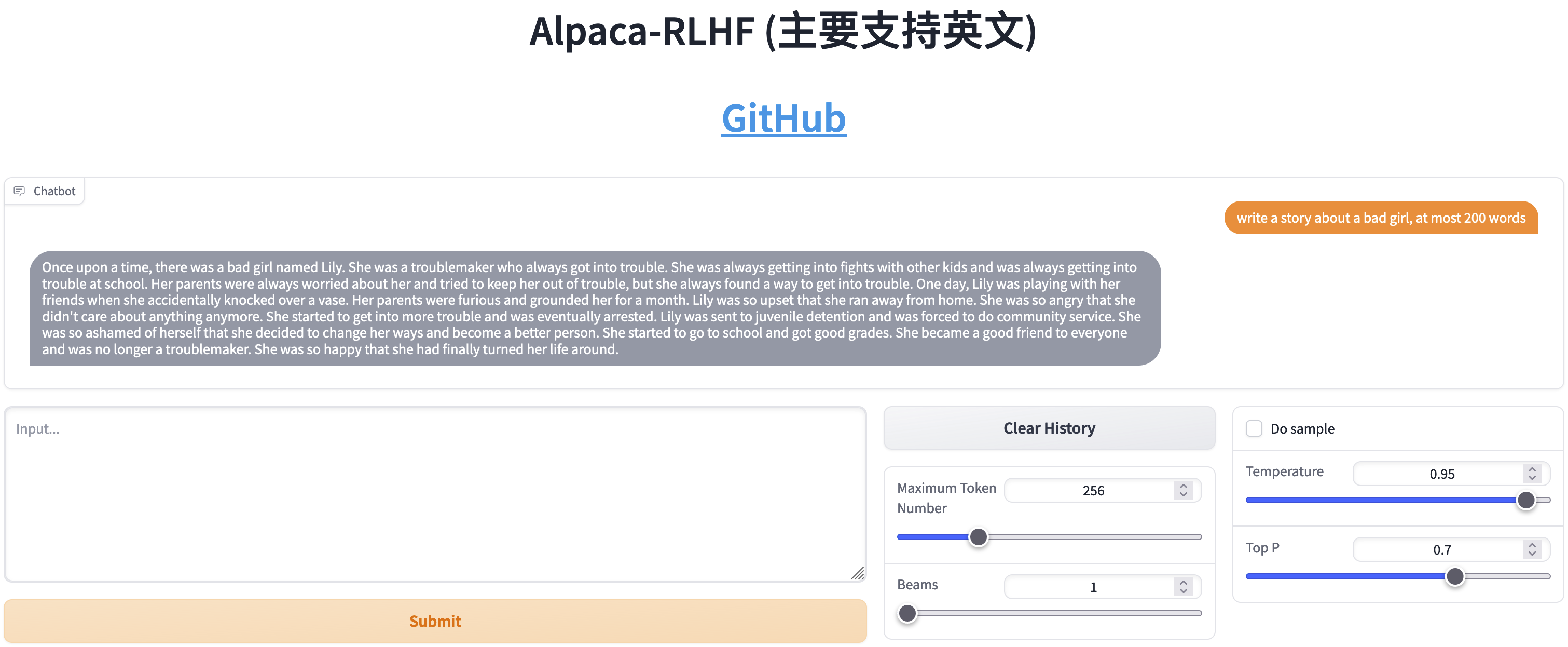
- Chatten
- Schreiben Sie Geschichten
Referenzen
Artikel
- 如何正确复现 GPT / RLHF anweisen?
- 影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现)
Quellen
Werkzeuge
Datensätze
- Stanford Human Preferences Dataset (SHP)
- HH-RLHF
- hh-rlhf
- Ausbildung eines hilfreichen und harmlosen Assistenten mit verstärkendem Lernen aus menschlichem Feedback [Papier]
- Dahoas/statisch-hh
- Dahoas/rm-statisch
- GPT-4-LLM
- Offener Assistent
Verwandte Repositories
- mein-Alpaka
- Multiturn-Alpaka