icl selective annotation
1.0.0
Code für selektive Annotation auf Papier macht Sprachmodelle zu besseren Few-Shot-Lernenden
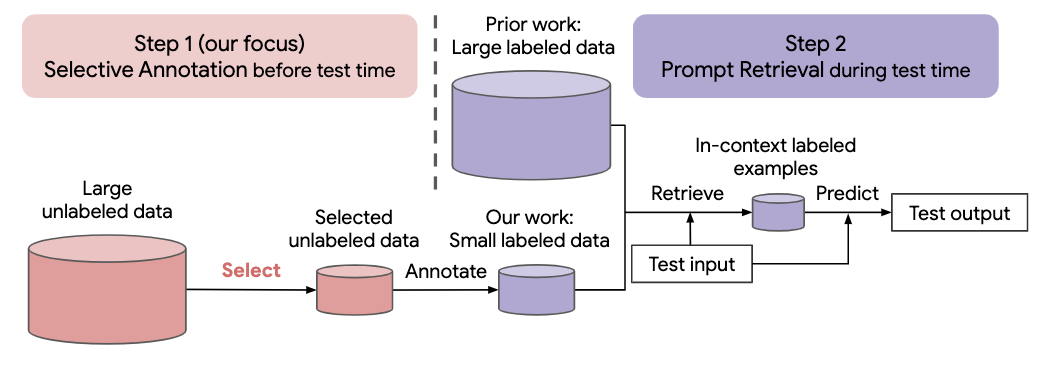
Viele neuere Ansätze für Aufgaben in natürlicher Sprache basieren auf den bemerkenswerten Fähigkeiten großer Sprachmodelle. Große Sprachmodelle können In-Context-Lernen durchführen, bei dem sie eine neue Aufgabe anhand einiger Aufgabendemonstrationen lernen, ohne dass Parameter aktualisiert werden müssen. Diese Arbeit untersucht die Auswirkungen des kontextbezogenen Lernens auf die Erstellung von Datensätzen für neue Aufgaben in natürlicher Sprache. Ausgehend von neueren Methoden des kontextbezogenen Lernens formulieren wir ein annotationseffizientes, zweistufiges Framework: selektive Annotation , die im Voraus einen Pool von Beispielen zum Annotieren aus unbeschrifteten Daten auswählt, gefolgt von einem sofortigen Abruf, der Aufgabenbeispiele aus dem annotierten Pool abruft Testzeit. Basierend auf diesem Framework schlagen wir eine unbeaufsichtigte, graphbasierte selektive Annotationsmethode, vote-k , vor, um verschiedene, repräsentative Beispiele für die Annotation auszuwählen. Umfangreiche Experimente mit 10 Datensätzen (die Klassifizierung, vernünftiges Denken, Dialog und Text-/Codegenerierung abdecken) zeigen, dass unsere selektive Annotationsmethode die Aufgabenleistung deutlich verbessert. Im Durchschnitt erreicht vote-k bei einem Anmerkungsbudget von 18/100 einen relativen Gewinn von 12,9 % bzw. 11,4 % im Vergleich zur zufälligen Auswahl von Beispielen zur Kommentierung. Im Vergleich zu modernsten überwachten Feinabstimmungsansätzen bietet es eine ähnliche Leistung mit 10–100-mal weniger Annotationskosten über 10 Aufgaben hinweg. Wir analysieren außerdem die Wirksamkeit unseres Frameworks in verschiedenen Szenarien: Sprachmodelle mit unterschiedlichen Größen, alternative selektive Annotationsmethoden und Fälle, in denen es zu einer Verschiebung der Testdatendomäne kommt. Wir hoffen, dass unsere Studien als Grundlage für Datenannotationen dienen werden, da große Sprachmodelle zunehmend auf neue Aufgaben angewendet werden
Führen Sie den folgenden Befehl aus, um dieses Repo zu klonen
git clone https://github.com/HKUNLP/icl-selective-annotation
Um die Umgebung einzurichten, führen Sie diesen Code in der Shell aus:
conda env create -f selective_annotation.yml
conda activate selective_annotation
cd transformers
pip install -e .
Dadurch wird die von uns verwendete Umgebung „selective_annotation“ erstellt.
Aktivieren Sie die Umgebung durch Ausführen
conda activate selective_annotation
GPT-J als kontextbezogenes Lernmodell, DBpedia als Aufgabe und vote-k als selektive Annotationsmethode (1 GPU, 40 GB Speicher)
python main.py --task_name dbpedia_14 --selective_annotation_method votek --model_cache_dir models --data_cache_dir datasets --output_dir outputs
Wenn Sie unsere Arbeit hilfreich finden, zitieren Sie uns bitte
@article{Selective_Annotation,
title={Selective Annotation Makes Language Models Better Few-Shot Learners},
author={Hongjin Su and Jungo Kasai and Chen Henry Wu and Weijia Shi and Tianlu Wang and Jiayi Xin and Rui Zhang and Mari Ostendorf and Luke Zettlemoyer and Noah A. Smith and Tao Yu},
journal={ArXiv},
year={2022},
}


