Phi2 mini Chinese
1.0.0
Bei diesem Projekt handelt es sich um ein experimentelles Projekt mit Open-Source-Code und Modellgewichten sowie weniger Vortrainingsdaten. Wenn Sie ein besseres kleines chinesisches Modell benötigen, können Sie auf das Projekt ChatLM-mini-Chinese verweisen
Vorsicht
Dieses Projekt ist ein experimentelles Projekt und kann jederzeit größeren Änderungen unterliegen, einschließlich Trainingsdaten, Modellstruktur, Dateiverzeichnisstruktur usw. Die erste Version des Modells und bitte überprüfen Sie tag v1.0
Zum Beispiel das Hinzufügen von Punkten am Ende von Sätzen, das Konvertieren von traditionellem Chinesisch in vereinfachtes Chinesisch, das Löschen wiederholter Satzzeichen (z. B. enthalten einige Dialogmaterialien viele "。。。。。" ), die NFKC-Unicode-Standardisierung (hauptsächlich das Problem der Vollständigkeit). Breitenkonvertierung in halbe Breite und Webseitendaten (u3000 xa0) usw.
Informationen zum spezifischen Datenbereinigungsprozess finden Sie im Projekt ChatLM-mini-Chinese.
Dieses Projekt verwendet den BPE -Tokenizer byte level . Es gibt zwei Arten von Trainingscodes für Wortsegmentierer: char level und byte level .
Nach dem Training erinnert sich der Tokenizer daran, zu prüfen, ob das Vokabular häufig vorkommende Sonderzeichen enthält, z. B. t , n usw. Sie können versuchen, einen Text mit Sonderzeichen zu encode und decode , um zu sehen, ob er wiederhergestellt werden kann. Wenn diese Sonderzeichen nicht enthalten sind, fügen Sie sie über die Funktion add_tokens hinzu. Verwenden Sie len(tokenizer) um die Vokabulargröße zu ermitteln. tokenizer.vocab_size zählt nicht die über die Funktion add_tokens hinzugefügten Zeichen.
Das Tokenizer-Training verbraucht viel Speicher:
Das Training von 100 Millionen Zeichen byte level erfordert mindestens 32G Speicher (tatsächlich reichen 32G nicht aus und der Austausch wird häufig ausgelöst). Das 13600k -Training dauert etwa eine Stunde.
Das Training char level mit 650 Millionen Zeichen (das ist genau die Datenmenge in der chinesischen Wikipedia) erfordert mindestens 32 GB Speicher. Da der Austausch mehrmals ausgelöst wird, beträgt die tatsächliche Nutzung weit mehr als 32 GB. Das 13600K -Training dauert etwa eine halbe Stunde Stunde.
Wenn der Datensatz groß ist (GB-Ebene), wird daher empfohlen, beim Training tokenizer eine Stichprobe aus dem Datensatz zu verwenden.
Verwenden Sie eine große Textmenge für das unbeaufsichtigte Vortraining, hauptsächlich unter Verwendung des Datensatzes BELLE von bell open source .
Datensatzformat: ein Satz für eine Probe. Wenn er zu lang ist, kann er gekürzt und in mehrere Proben aufgeteilt werden.
Während des CLM-Vortrainingsprozesses sind die Modelleingabe und -ausgabe gleich und müssen bei der Berechnung des Kreuzentropieverlusts um ein Bit verschoben werden ( shift ).
Bei der Verarbeitung des Enzyklopädie-Korpus wird empfohlen, am Ende jedes Eintrags die Markierung '[EOS]' hinzuzufügen. Andere Korpusverarbeitungen sind ähnlich. Das Ende eines doc (das das Ende eines Artikels oder das Ende eines Absatzes sein kann) muss mit '[EOS]' gekennzeichnet werden. Die Startmarke '[BOS]' kann hinzugefügt werden oder nicht.
Verwenden Sie hauptsächlich den Datensatz von bell open source . Danke Chef BELLE.
Das Datenformat für das SFT-Training ist wie folgt:
text = f"##提问: n { example [ 'instruction' ] } n ##回答: n { example [ 'output' ][ EOS ]" Wenn das Modell den Verlust berechnet, ignoriert es den Teil vor der Markierung "##回答:" ( "##回答:" wird ebenfalls ignoriert), beginnend mit dem Ende von "##回答:" .
Denken Sie daran, die EOS Satzende-Sondermarkierung hinzuzufügen, da Sie sonst beim decode des Modells nicht wissen, wann Sie aufhören müssen. Die BOS Satzanfangsmarke kann ausgefüllt oder leer gelassen werden.
Übernehmen Sie eine einfachere und speichersparendere Methode zur Optimierung der DPO-Präferenzen.
Passen Sie das SFT-Modell entsprechend Ihren persönlichen Vorlieben an. Der rejected sollte aus drei Spalten bestehen epoch prompt , „ chosen “ und „ rejected “. 0,5- epoch -Checkpoint-Modell) Generieren: Wenn die Ähnlichkeit zwischen den generierten rejected und chosen Daten über 0,9 liegt, werden diese Daten nicht benötigt.
Im DPO-Prozess gibt es zwei Modelle, eines ist das zu trainierende Modell und das andere ist das Referenzmodell. Beim Laden handelt es sich tatsächlich um dasselbe Modell, aber das Referenzmodell nimmt nicht an Parameteraktualisierungen teil.
Modellgewicht- huggingface Repository: Phi2-Chinese-0.2B
from transformers import AutoTokenizer , AutoModelForCausalLM , GenerationConfig
import torch
device = torch . device ( "cuda" ) if torch . cuda . is_available () else torch . device ( "cpu" )
tokenizer = AutoTokenizer . from_pretrained ( 'charent/Phi2-Chinese-0.2B' )
model = AutoModelForCausalLM . from_pretrained ( 'charent/Phi2-Chinese-0.2B' ). to ( device )
txt = '感冒了要怎么办?'
prompt = f"##提问: n { txt } n ##回答: n "
# greedy search
gen_conf = GenerationConfig (
num_beams = 1 ,
do_sample = False ,
max_length = 320 ,
max_new_tokens = 256 ,
no_repeat_ngram_size = 4 ,
eos_token_id = tokenizer . eos_token_id ,
pad_token_id = tokenizer . pad_token_id ,
)
tokend = tokenizer . encode_plus ( text = prompt )
input_ids , attention_mask = torch . LongTensor ([ tokend . input_ids ]). to ( device ),
torch . LongTensor ([ tokend . attention_mask ]). to ( device )
outputs = model . generate (
inputs = input_ids ,
attention_mask = attention_mask ,
generation_config = gen_conf ,
)
outs = tokenizer . decode ( outputs [ 0 ]. cpu (). numpy (), clean_up_tokenization_spaces = True , skip_special_tokens = True ,)
print ( outs ) ##提问:
感冒了要怎么办?
##回答:
感冒是由病毒引起的,感冒一般由病毒引起,以下是一些常见感冒的方法:
- 洗手,特别是在接触其他人或物品后。
- 咳嗽或打喷嚏时用纸巾或手肘遮住口鼻。
- 用手触摸口鼻,特别是喉咙和鼻子。
- 如果咳嗽或打喷嚏,可以用纸巾或手绢来遮住口鼻,但要远离其他人。
- 如果你感冒了,最好不要触摸自己的眼睛、鼻子和嘴巴。
- 在感冒期间,最好保持充足的水分和休息,以缓解身体的疲劳。
- 如果您已经感冒了,可以喝一些温水或盐水来补充体液。
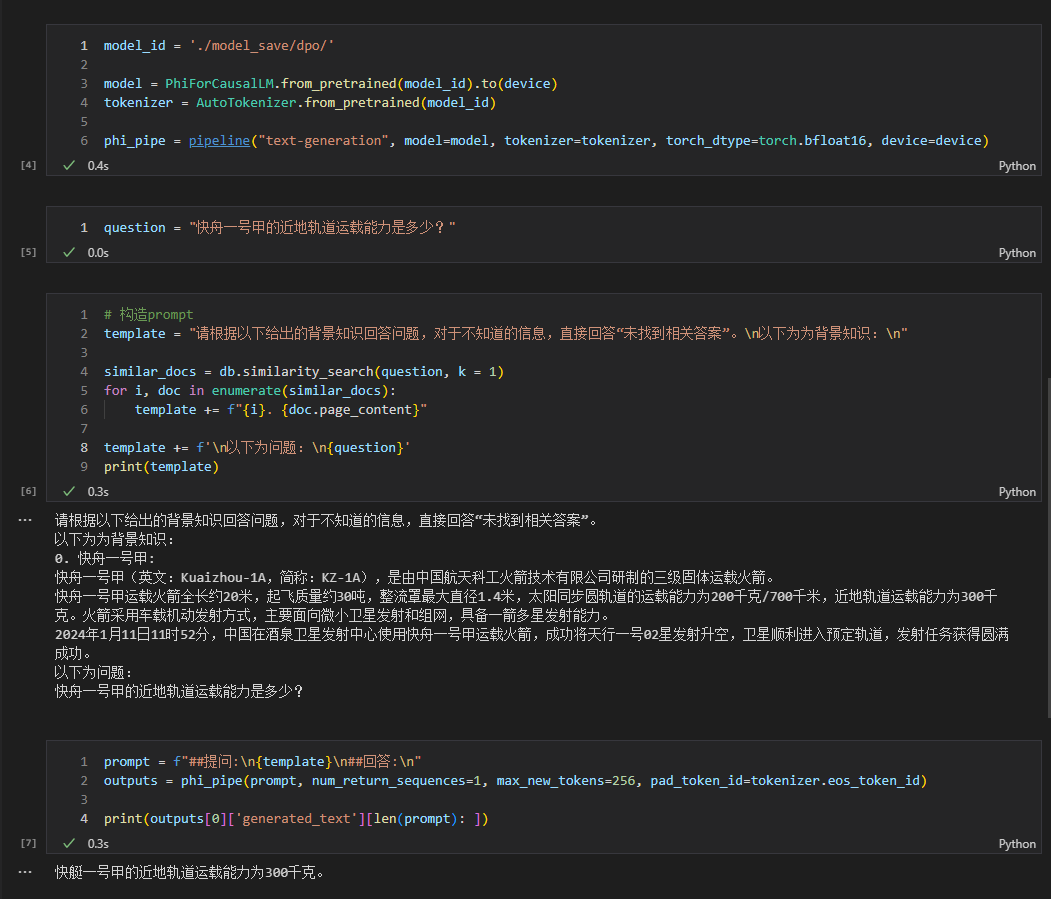
- 另外,如果感冒了,建议及时就医。 Den spezifischen Code finden Sie unter rag_with_langchain.ipynb .
Wenn Sie glauben, dass dieses Projekt für Sie hilfreich ist, zitieren Sie es bitte.
@misc{Charent2023,
author={Charent Chen},
title={A small Chinese causal language model with 0.2B parameters base on Phi2},
year={2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/charent/Phi2-mini-Chinese}},
}
Dieses Projekt trägt nicht die Risiken und Verantwortlichkeiten der Datensicherheit und der öffentlichen Meinung, die durch Open-Source-Modelle und -Codes verursacht werden, oder die Risiken und Verantwortlichkeiten, die sich aus der Irreführung, dem Missbrauch, der Verbreitung oder der missbräuchlichen Nutzung von Modellen ergeben.


