reflexion
1.0.0
Dieses Repo enthält den Code, Demos und Protokolldateien zur reflexion : Language Agents with Verbal Reinforcement Learning von Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, Shunyu Yao.
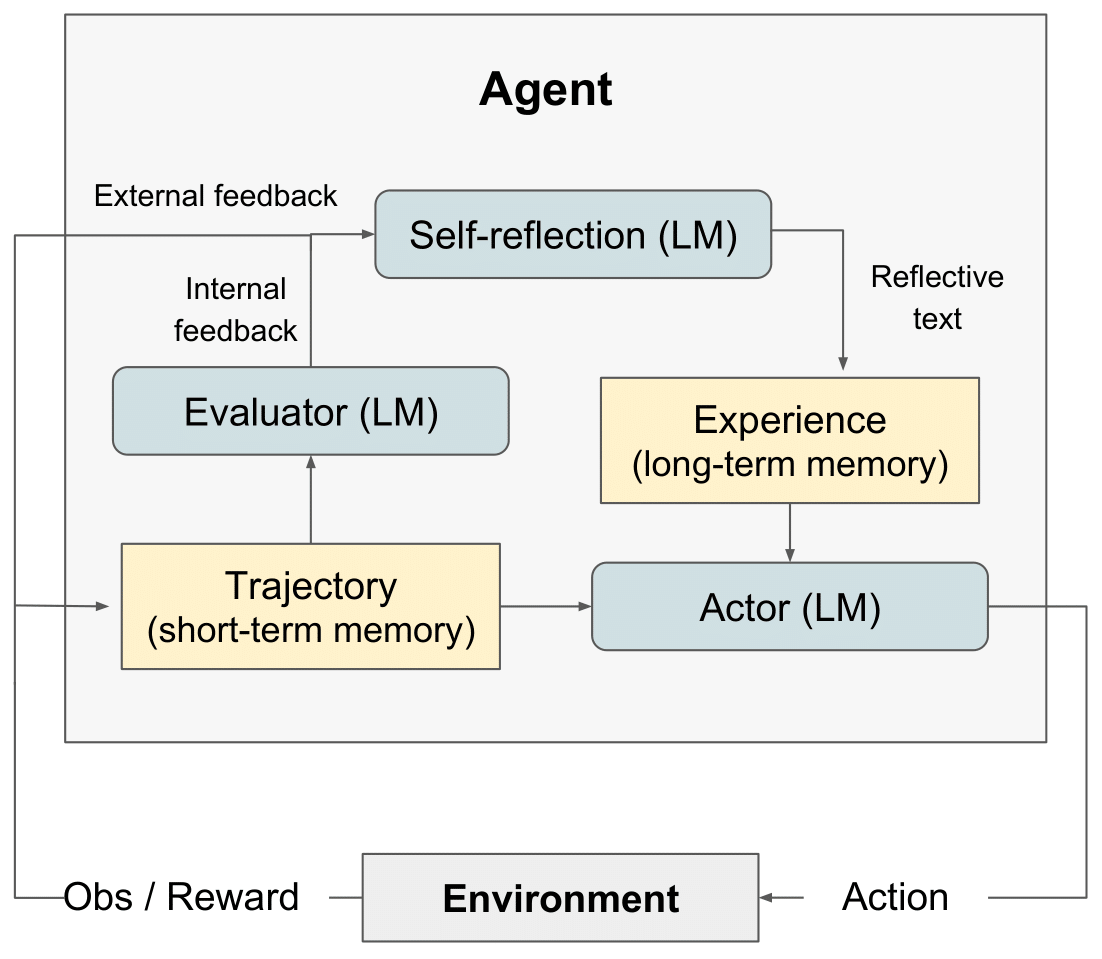 Reflexions-RL-Diagramm" style="max-width: 100%;">
Reflexions-RL-Diagramm" style="max-width: 100%;">
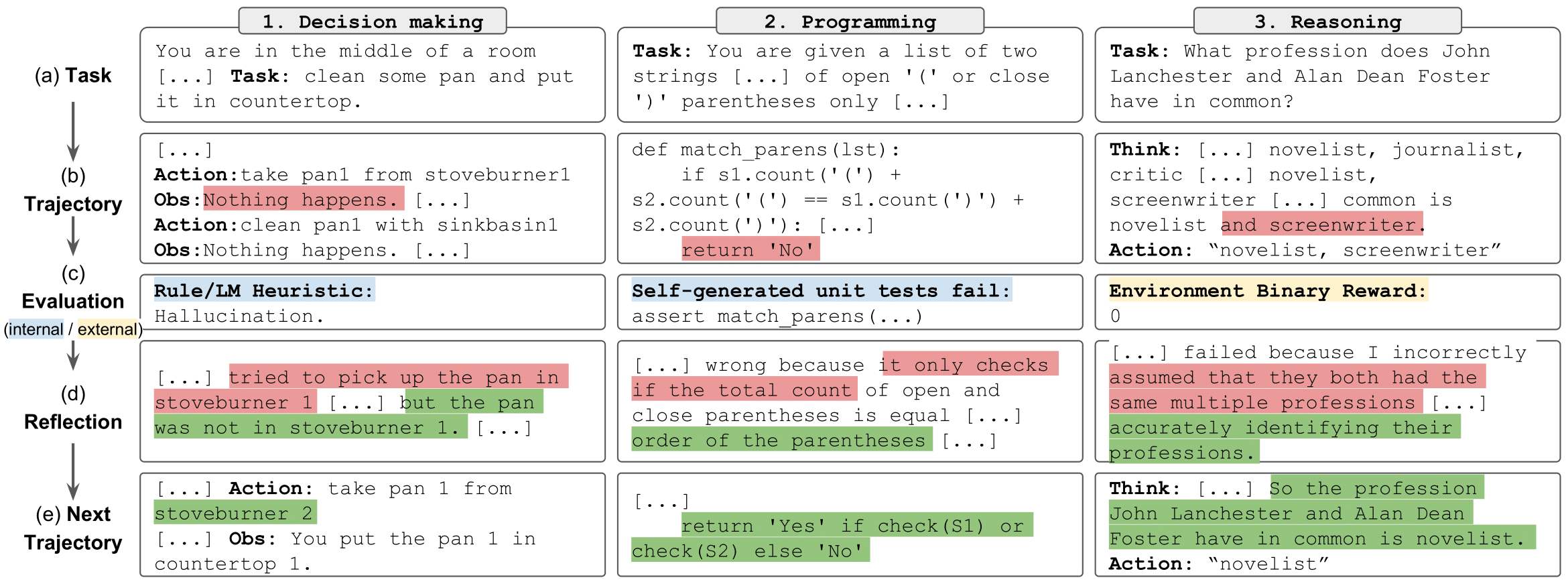 Reflexionsaufgaben" style="max-width: 100%;">
Reflexionsaufgaben" style="max-width: 100%;">
Wir haben den LeetcodeHardGym hier veröffentlicht
Wir haben eine Reihe von Notizbüchern bereitgestellt, um die Ergebnisse der Argumentationsexperimente einfach durchzuführen, zu erkunden und mit ihnen zu interagieren. Jedes Experiment besteht aus einer Zufallsstichprobe von 100 Fragen aus dem Distraktor-Datensatz von HotPotQA. Jede Frage in der Stichprobe wird von einem Agenten mit einem bestimmten Typ und einer bestimmten reflexion beantwortet.
Um zu beginnen:
git clone https://github.com/noahshinn/reflexion && cd ./hotpotqa_runspip install -r requirements.txtOPENAI_API_KEY auf Ihren OpenAI-API-Schlüssel: export OPENAI_API_KEY= < your key > Der Agententyp wird durch das Notebook bestimmt, das Sie ausführen möchten. Zu den verfügbaren Agententypen gehören:
ReAct – ReAct-Agent
CoT_context – CoT-Agent erhält unterstützenden Kontext zur Frage
CoT_no_context – CoT-Agent hat keinen unterstützenden Kontext zur Frage erhalten
Das Notebook für jeden Agententyp befindet sich im Verzeichnis ./hotpot_runs/notebooks .
In jedem Notizbuch können Sie die reflexion angeben, die von den Agenten verwendet werden soll. Zu den verfügbaren reflexion , die in einer Enum definiert sind, gehören:
reflexion Strategy.NONE – Der Agent erhält keine Informationen über seinen letzten Versuch.
reflexion Strategy.LAST_ATTEMPT – Der Agent erhält seine Argumentationsspur von seinem letzten Versuch zur Frage als Kontext.
reflexion Strategy. reflexion – Dem Agenten wird seine Selbstreflexion beim letzten Versuch als Kontext gegeben.
reflexion Strategy.LAST_ATTEMPT_AND_ reflexion – Der Agent erhält sowohl seine Argumentationsspur als auch seine Selbstreflexion beim letzten Versuch als Kontext.
Klonen Sie dieses Repo und verschieben Sie es in das AlfWorld-Verzeichnis
git clone https://github.com/noahshinn/reflexion && cd ./alfworld_runs Geben Sie die Laufparameter in ./run_ reflexion .sh . num_trials : Anzahl der iterativen Lernschritte. num_envs : Anzahl der Task-Umgebungs-Paare pro Test. run_name : der Name für diesen Lauf. use_memory : dauerhaften Speicher zum Speichern von Selbstreflexionen verwenden (ausschalten, um einen Basislauf auszuführen). is_resume : Protokollierungsverzeichnis zum Fortsetzen verwenden ein früherer Lauf, resume_dir : das Protokollierungsverzeichnis, von dem aus der vorherige Lauf fortgesetzt werden soll. start_trial_num : if Lauf fortsetzen, dann die Versuchsnummer, mit der gestartet werden soll
Führen Sie die Testversion durch
./run_ reflexion .sh Die Protokolle werden an ./root/<run_name> gesendet.
Aufgrund der Art dieser Experimente ist es für einzelne Entwickler möglicherweise nicht möglich, die Ergebnisse erneut auszuführen, da für GPT-4 nur begrenzter Zugriff und erhebliche API-Gebühren anfallen. Alle Durchläufe aus dem Papier und zusätzliche Ergebnisse werden in ./alfworld_runs/root für die Entscheidungsfindung, ./hotpotqa_runs/root für die Begründung und ./programming_runs/root für die Programmierung protokolliert
Schauen Sie sich hier den Code für den Originalcode an
Lesen Sie hier einen Blogbeitrag
Sehen Sie sich hier eine interessante Typvorhersage-Implementierung an: OpenTau
Bei allen Fragen wenden Sie sich bitte an [email protected]
@misc { shinn2023 reflexion ,
title = { reflexion : Language Agents with Verbal Reinforcement Learning } ,
author = { Noah Shinn and Federico Cassano and Edward Berman and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao } ,
year = { 2023 } ,
eprint = { 2303.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.AI }
}

