ChatGPT, GenerativeAI und LLMs-Zeitleiste
Dieses Repository organisiert eine Zeitleiste der wichtigsten Ereignisse (Produkte, Dienstleistungen, Artikel, GitHub, Blogbeiträge und Neuigkeiten), die vor und nach der ChatGPT-Ankündigung stattgefunden haben.
In dieser Zeitleiste werden verschiedene Informationen zusammengestellt, mit besonderem Schwerpunkt auf LLM und generativer KI.
Vielleicht ist es eine Szene aus der heißesten Geschichte, also dachte ich, es wäre wichtig, diese Erinnerungen gut aufzubewahren, also habe ich sie organisiert.
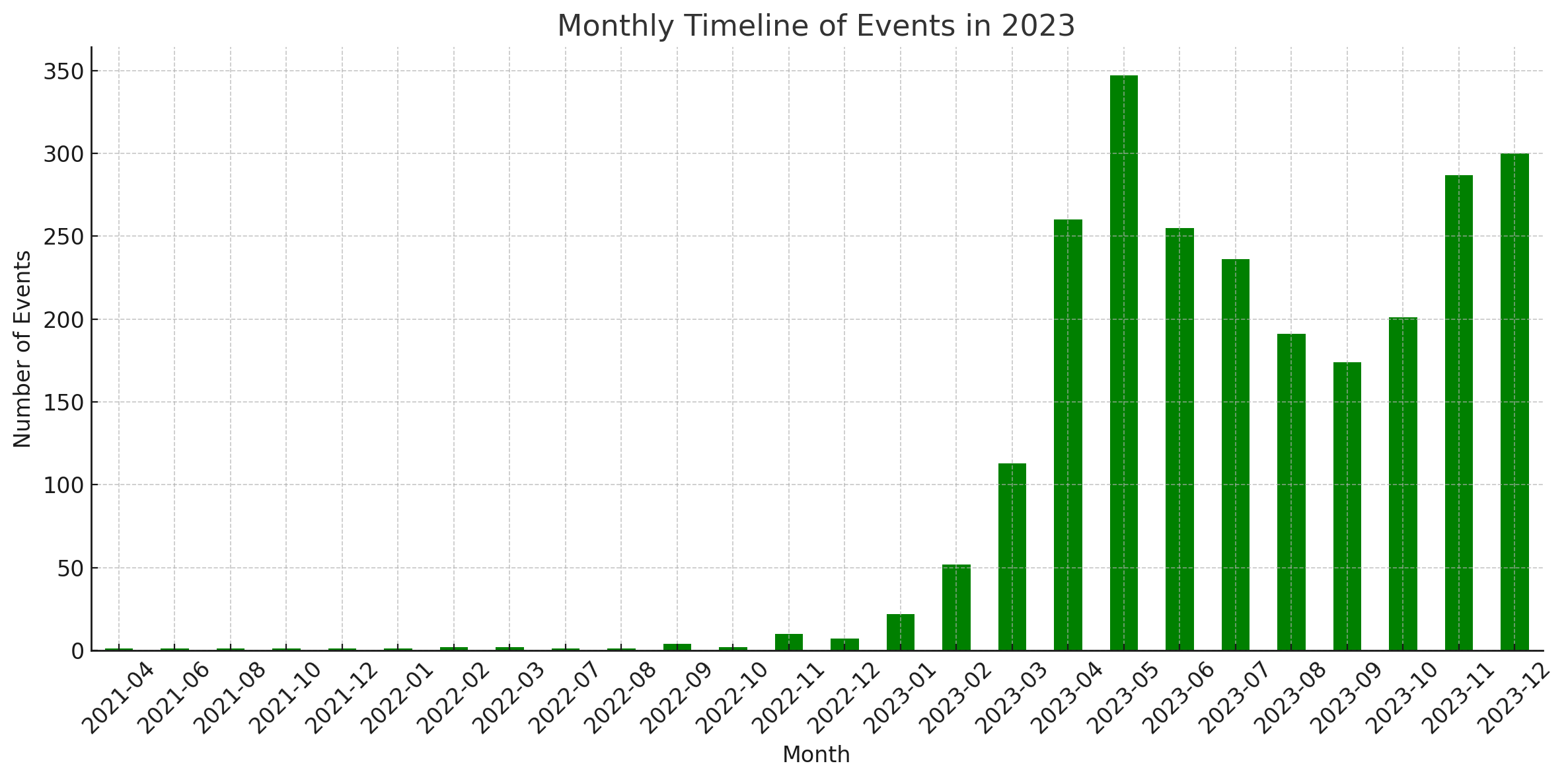
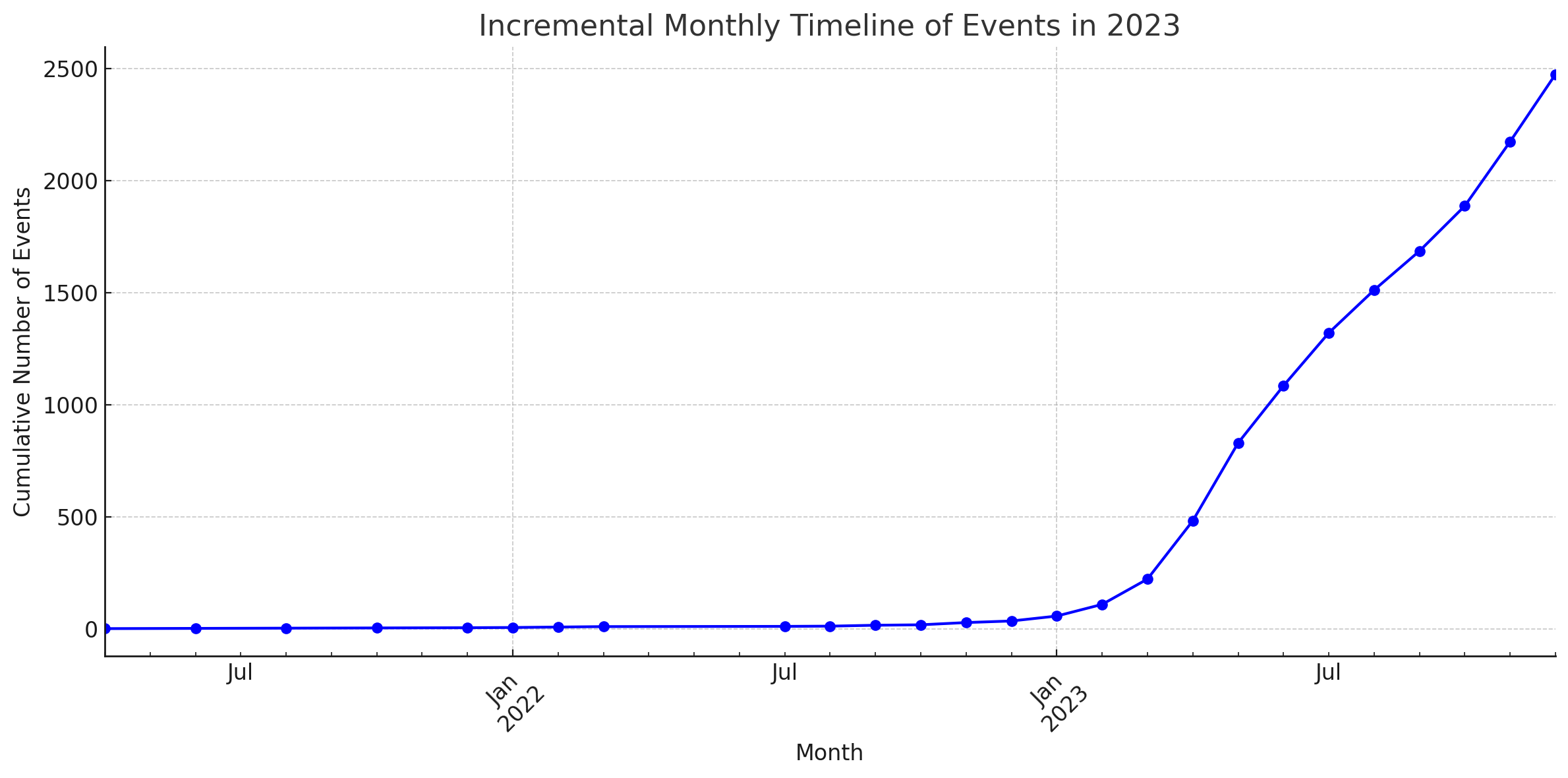
Statistiken
Diese Diagramme wurden vom Code Interpreter von ChatGPT generiert.
Mitwirken
Probleme und Pull-Anfragen werden sehr geschätzt. Wenn Sie noch nie an einem Open-Source-Projekt mitgewirkt haben, erkläre ich Ihnen gerne, wie Sie eine Pull-Anfrage erstellen.
Sie können damit beginnen, ein Problem zu eröffnen, in dem Sie das Problem beschreiben, das Sie lösen möchten, und wir werden von dort aus fortfahren.
Emoji
arXiv, PDF?, arxiv-vanity?, Papierseite?, Papiere mit Code ✳️, Github
Lizenz
Dieses Dokument ist unter der MIT-Lizenz lizenziert © Jonghong Jeon (전종홍)
Zeitleiste V2
2024
- 17.05. – OpenAI schließt Reddit-Deal ab, um seine KI auf Ihre Beiträge zu trainieren
(Nachricht), - 17.05. – OpenAI löst Team auf, das sich auf langfristige KI-Risiken konzentriert, weniger als ein Jahr nach der Ankündigung
(Nachricht), - 17.05. – Internationaler wissenschaftlicher Bericht zur Sicherheit fortschrittlicher KI
(Blog), - 16.05. – TRANSIC: Sim-to-Real-Richtlinientransfer durch Lernen aus der Online-Korrektur
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16.05. – Toon3D: Cartoons aus einer neuen Perspektive sehen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16.05. – Testen der Zuverlässigkeit eines KI-basierten großen Sprachmodells zur Extraktion ökologischer Informationen aus der wissenschaftlichen Literatur
(Nachricht), - 16.05. – Vielschichtiges In-Context-Lernen in multimodalen Basismodellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16.05. – So schalten Sie die KI an, bevor es zu spät ist
(Nachricht), - 05/16 – Einführung von DINO 1.5: Weiterentwicklung der „Edge“ der Open-Set-Objekterkennung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16.05. – GPT Store Mining und Analyse
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16.05. – Dual3D: Effiziente und konsistente Text-zu-3D-Generierung mit Dual-Mode-Multi-View-Latent-Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 16.05. – Chameleon: Mixed-Modal Early-Fusion Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/16 – CAT3D: Erstellen Sie alles in 3D mit Multi-View-Diffusionsmodellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15.05. – Xmodel-VLM: Eine einfache Basis für ein multimodales Vision-Sprachmodell
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15.05. – LoRA lernt weniger und vergisst weniger
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15.05. – Das unsichtbare KI-Wasserzeichen von Google hilft bei der Identifizierung generativer Texte und Videos
(Nachricht), - 15.05. – Google I/O 2024: alles angekündigt
(Blog), - 15.05. – BEHAVIOR Vision Suite: Anpassbare Datensatzgenerierung per Simulation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15.05. – ALPINE: Enthüllung der Planungsfähigkeit von autoregressivem Lernen in Sprachmodellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14.05. – Den Leistungsunterschied zwischen Online- und Offline-Ausrichtungsalgorithmen verstehen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14.05. – SpeechVerse: Ein groß angelegtes verallgemeinerbares Audio-Sprachmodell
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14.05. – SpeechGuard: Erforschung der kontroversen Robustheit multimodaler großer Sprachmodelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 – Keine Zeit zu verschwenden: Nutzen Sie den Kanal für das Verständnis mobiler Videos
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14.05. – Hunyuan-DiT: Ein leistungsstarker Diffusionstransformator mit mehreren Auflösungen und feinkörnigem chinesischen Verständnis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/14 – Kompositionelle Text-zu-Bild-Generierung mit dichten Blob-Darstellungen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 14.05. – Jenseits von Skalierungsgesetzen: Transformatorleistung mit assoziativem Gedächtnis verstehen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13.05. – SambaNova SN40L: Skalierung der KI-Speichermauer mit Datenfluss und Expertenzusammensetzung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13.05. – RLHF-Workflow: Von der Belohnungsmodellierung zum Online-RLHF
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13.05. – Plot2Code: Ein umfassender Benchmark zur Bewertung multimodaler großer Sprachmodelle bei der Codegenerierung aus wissenschaftlichen Diagrammen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13.05. – OpenAI stellt das neueste KI-Modell vor, GPT-4o
(Nachricht), - 13.05. – MS MARCO Web Search: ein umfangreicher, informationsreicher Web-Datensatz mit Millionen von echten Klick-Labels
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 13.05. – Wie viel Forschung wird von großen Sprachmodellen geschrieben?
(Blog), - 13.05. – Hallo GPT-4o
(Blog), - 13.05. – Coin3D: Steuerbare und interaktive 3D-Asset-Generierung mit Proxy-gesteuerter Konditionierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/11 – Piccolo2: Allgemeine Texteinbettung mit Multi-Task-Hybrid-Verlusttraining
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/11 - LogoMotion: Visuell fundierte Codegenerierung für inhaltsbewusste Animationen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/10 – INSPECT – Ein Open-Source-Framework für die Evaluierung großer Sprachmodelle
(Blog), - 05/10 – AI Safety Institute veröffentlicht neue KI-Sicherheitsbewertungsplattform
(Nachricht), - 05/07 - SUTRA: Skalierbare mehrsprachige Sprachmodellarchitektur
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/07 – Meta veröffentlicht Llama 3 Open-Source-LLM
(Nachricht), - 05/03 – Worauf kommt es beim Aufbau von Vision-Language-Modellen an?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 – WildChat: 1 Mio. ChatGPT-Interaktionsprotokolle in freier Wildbahn
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 – StoryDiffusion: Konsequente Selbstaufmerksamkeit für die Generierung von Bildern und Videos mit großer Reichweite
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 – Prometheus 2: Ein Open-Source-Sprachmodell, das auf die Bewertung anderer Sprachmodelle spezialisiert ist
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - NeMo-Aligner: Skalierbares Toolkit für effiziente Modellausrichtung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - LLM-AD: Auf einem großen Sprachmodell basierendes Audiobeschreibungssystem
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 - FLAME: Faktalitätsbewusste Ausrichtung für große Sprachmodelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/02 – Anpassen von Text-zu-Bild-Modellen mit einem einzelnen Bildpaar
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 – Spektral beschnittene Gaußsche Felder mit neuronaler Kompensation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 – Self-Play-Präferenzoptimierung für die Sprachmodellausrichtung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 – Ist eine größere Bearbeitungsstapelgröße immer besser? – Eine empirische Studie zur Modellbearbeitung mit Llama-3
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 – Clover: Regressive Lightweight Speculative Decoding mit sequentiellem Wissen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 05/01 – Eine sorgfältige Untersuchung der Leistung großer Sprachmodelle in der Grundschularithmetik
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. – Visual Fact Checker: Ermöglicht die Generierung detaillierter Untertitel mit hoher Wiedergabetreue
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. - STT: Stateful Tracking mit Transformern für autonomes Fahren
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. – SemantiCodec: Ein semantischer Audio-Codec mit extrem niedriger Bitrate für allgemeinen Ton
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. – Octopus v4: Diagramm der Sprachmodelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. – MotionLCM: Echtzeit-steuerbare Bewegungserzeugung über ein Latent-Konsistenzmodell
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. – MicroDreamer: Zero-Shot-3D-Generierung in sim20 Sekunden durch punktebasierte iterative Rekonstruktion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. - Lightplane: Hochskalierbare Komponenten für neuronale 3D-Felder
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. – KAN: Kolmogorov-Arnold-Netzwerke
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. – Iterative Reasoning-Präferenzoptimierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. – Unsichtbarer Stich: Generieren glatter 3D-Szenen mit Tiefen-Inpainting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. – InstantFamily: Maskierte Aufmerksamkeit für Zero-Shot-Multi-ID-Bildgenerierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. - GS-LRM: Großes Rekonstruktionsmodell für 3D-Gauß-Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. – Den Kontext von Llama-3 über Nacht um das Zehnfache erweitern
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. - DOCCI: Beschreibungen verbundener und kontrastierender Bilder
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 30.04. – Bessere und schnellere große Sprachmodelle durch Multi-Token-Vorhersage
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29.04. – Stylus: Automatische Adapterauswahl für Diffusionsmodelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29.04. – SAGS: Strukturbewusstes 3D-Gaußsches Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29.04. - Richter durch Jurys ersetzen: Bewertung von LLM-Generationen mit einer Gruppe verschiedener Modelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29.04. – NIST AI RMF Generatives KI-Profil
(Nachricht), - 29.04. – LoRA Land: 310 fein abgestimmte LLMs, die es mit GPT-4 aufnehmen können, ein technischer Bericht
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29.04. – Kangaroo: Verlustfreie selbstspekulative Dekodierung durch Double Early Exiting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 29.04. - Fähigkeiten von Zwillingsmodellen in der Medizin
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 28.04. – Malen mit Inpaint: Lernen, Bildobjekte hinzuzufügen, indem man sie zuerst entfernt
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 28.04. – LEGENT: Offene Plattform für verkörperte Agenten
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 27.04. – Ag2Manip: Erlernen neuartiger Manipulationsfähigkeiten mit agentenunabhängigen visuellen und Aktionsdarstellungen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 26.04. – MaPa: Textgesteuerte fotorealistische Materialmalerei für 3D-Formen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 26.04. – BlenderAlchemy: Bearbeiten von 3D-Grafiken mit Vision-Language-Modellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25.04. – Technischer Bericht von Tele-FLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25.04. – SEED-Bench-2-Plus: Benchmarking multimodaler großer Sprachmodelle mit textreichem visuellem Verständnis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25.04. – Überarbeitung der Text-zu-Bild-Bewertung mit Gecko: Über Metriken, Eingabeaufforderungen und menschliche Bewertungen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25.04. – PLLaVA: Parameterfreie LLaVA-Erweiterung von Bildern zu Videos für dichte Videountertitel
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25.04. – Sorgen Sie dafür, dass Ihr LLM den Kontext vollständig nutzt
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25.04. – Elemente einzeln auflisten: Eine neue Datenquelle und ein neues Lernparadigma für multimodale LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25.04. – Layer-Skip: Ermöglichen von Early-Exit-Inferenz und selbstspekulativer Dekodierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25.04. – Interactive3D: Erstellen Sie mit der interaktiven 3D-Generierung, was Sie wollen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25.04. – Wie weit sind wir von GPT-4V entfernt? Mit Open-Source-Suites die Lücke zu kommerziellen multimodalen Modellen schließen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 25.04. – ConsistentID: Porträtgenerierung mit multimodaler, feinkörniger Identitätserhaltung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24.04. – XC-Cache: Übergreifende Betrachtung des zwischengespeicherten Kontexts für effiziente LLM-Inferenz
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24.04. – Die Ethik fortgeschrittener KI-Assistenten
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24.04. – PuLID: Pure- und Lightning-ID-Anpassung über Kontrastausrichtung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24.04. – NeRF-XL: Skalierung von NeRFs mit mehreren GPUs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24.04. – MotionMaster: Schulungsfreie Kamerabewegungsübertragung zur Videogenerierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24.04. – MoDE: CLIP-Datenexperten über Clustering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24.04. – MMT-Bench: Ein umfassender multimodaler Benchmark zur Bewertung großer Vision-Language-Modelle im Hinblick auf Multitask-AGI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24.04. – MaGGIe: Maskierte geführte schrittweise Mattierung menschlicher Instanzen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24.04. – ID-Aligner: Verbesserung der identitätserhaltenden Text-zu-Bild-Generierung durch Belohnungs-Feedback-Lernen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24.04. – Bearbeitbare Bildelemente für kontrollierbare Synthese
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24.04. – CatLIP: Visuelle Erkennungsgenauigkeit auf CLIP-Ebene mit 2,7-fach schnellerem Vortraining für Bild-Text-Daten im Webmaßstab
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 24.04. – BASS: Batch-aufmerksamkeitsoptimiertes spekulatives Sampling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23.04. – Transformatoren können N-Gramm-Sprachmodelle darstellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23.04. – Technischer Bericht zu Pegasus-v1
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23.04. – Mehrköpfiger Expertenmix
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 23.04. – FlashSpeech: Effiziente Zero-Shot-Sprachsynthese
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22.04. – SnapKV: LLM weiß schon vor der Generierung, wonach Sie suchen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22.04. - SEED-X: Multimodale Modelle mit einheitlichem Multigranularitätsverständnis und -generierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22.04. – Szenenkoordinatenrekonstruktion: Posieren von Bildsammlungen durch inkrementelles Lernen eines Relocalizers
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22.04. – Technischer Bericht zu Phi-3: Ein äußerst leistungsfähiges Sprachmodell lokal auf Ihrem Telefon
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22.04. – OpenELM: Eine effiziente Sprachmodellfamilie mit Open-Source-Trainings- und Inferenz-Framework
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22.04. – MultiBooth: Auf dem Weg zur Generierung aller Ihrer Konzepte in einem Bild aus Text
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22.04. – Erlernen der H-Infinity-Fortbewegungssteuerung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22.04. – Wie gut sind Low-Bit-quantisierte LLaMA3-Modelle? Eine empirische Studie
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22.04. – Richten Sie Ihre Schritte aus: Optimierung von Probenahmeplänen in Diffusionsmodellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 22.04. – Ein multimodaler automatisierter Interpretierbarkeitsagent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 21.04. – Hyper-SD: Trajektoriensegmentiertes Konsistenzmodell für effiziente Bildsynthese
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 21.04. – AdvPrompter: Schnelles adaptives kontradiktorisches Prompting für LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/20 – Musikkonsistenzmodelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 – Die Instruktionshierarchie: Schulung von LLMs zur Priorisierung privilegierter Instruktionen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 – TextSquare: Optimierung der textzentrierten visuellen Befehlsoptimierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19.04. – PhysDreamer: Physikbasierte Interaktion mit 3D-Objekten per Videogenerierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 – LLM-R2: Ein erweitertes regelbasiertes Rewrite-System für große Sprachmodelle zur Steigerung der Abfrageeffizienz
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19.04. – Wie real ist real? Ein menschlicher Bewertungsrahmen für uneingeschränkte kontradiktorische Beispiele
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 – Wie weit können wir mit der praktischen Reparatur von Programmen auf Funktionsebene gehen?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19.04. – Groma: Lokalisierte visuelle Tokenisierung zur Grundlage multimodaler großer Sprachmodelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 19.04. – Benötigt Gaussian Splatting eine SFM-Initialisierung?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/19 – AutoCrawler: Ein Web-Agent mit fortschrittlichem Verständnis für die Web-Crawler-Generierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18.04. – TriForce: Verlustfreie Beschleunigung der Generierung langer Sequenzen mit hierarchischer spekulativer Dekodierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18.04. – Auf dem Weg zur Selbstverbesserung von LLMs durch Vorstellungskraft, Suchen und Kritisieren
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 – Nutzen Sie Ihre Belohnungen wieder: Belohnungsmodellübertragung für Zero-Shot Cross-Lingual Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18.04. – Reka Core, Flash und Edge: Eine Reihe leistungsstarker multimodaler Sprachmodelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18.04. – OpenBezoar: Kleine, kostengünstige und offene Modelle, die auf Mischungen von Befehlsdaten trainiert werden
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18.04. – MeshLRM: Großes Rekonstruktionsmodell für hochwertiges Mesh
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18.04. – Einführung von Version 0.5 des AI Safety Benchmark von MLCommons
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 18.04. – Wir stellen Meta Llama 3 vor: Das bisher leistungsfähigste offen verfügbare LLM
(Blog), - 18.04. – EdgeFusion: Text-zu-Bild-Generierung auf dem Gerät
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 – BLINK: Multimodale große Sprachmodelle können sehen, aber nicht wahrnehmen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/18 - AniClipart: Clipart-Animation mit Text-zu-Video-Prioritäten
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17.04. – MoA: Aufmerksamkeitsmischung zur Subjekt-Kontext-Entflechtung bei der Erzeugung personalisierter Bilder
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/17 - FlowMind: Automatische Workflow-Generierung mit LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/17 – Dynamische Typografie: Wörter zum Leben erwecken
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 17.04. – Stable Diffusion 3 API jetzt verfügbar
(Twitter), (Blog), (Demo), - 04/16 – VASA-1: Lebensechte, audiogesteuerte sprechende Gesichter, die in Echtzeit generiert werden
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 16.04. – US-Handelsministerin Gina Raimondo kündigt Erweiterung des Führungsteams des US AI Safety Institute an
(Nachricht), - 04/16 – Lange Musikgeneration mit latenter Verbreitung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15.04. – LLM-Evaluatoren erkennen ihre eigenen Generationen an und bevorzugen sie
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 15.04. - Video2Game: Echtzeit-, interaktive, realistische und browserkompatible Umgebung aus einem einzigen Video
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15.04. – Tango 2: Ausrichtung diffusionsbasierter Text-to-Audio-Generierungen durch direkte Präferenzoptimierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 15.04. – Zähmung des latenten Diffusionsmodells für das Inpainting neuronaler Strahlungsfelder
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15.04. – Opus kann als Turing-Maschine betrieben werden
(Twitter), - 15.04. – MathGPT: Nutzung von Llama 2 zur Schaffung einer Plattform für hochgradig personalisiertes Lernen
- 15.04. – HQ-Edit: Ein hochwertiger Datensatz für die anleitungsbasierte Bildbearbeitung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15.04. – Ctrl-Adapter: Ein effizientes und vielseitiges Framework zur Anpassung verschiedener Steuerelemente an jedes Diffusionsmodell
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/15 – Komprimierung repräsentiert Intelligenz linear
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 15.04. – CompGS: Effiziente 3D-Szenendarstellung durch komprimiertes Gaußsches Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 14.04. – TextHawk: Erforschung der effizienten feinkörnigen Wahrnehmung multimodaler großer Sprachmodelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 13.04. – Cathie Wood startet mit neuem OpenAI-Anteil in den ChatGPT-Boom
(Nachricht), - 04/12 – Skalierung (nach unten) CLIP: Eine umfassende Analyse von Daten, Architektur und Trainingsstrategien
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 – Untersuchung des 3D-Bewusstseins von Visual Foundation-Modellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 – Kleine Basis-LMs mit weniger Token vorab trainieren
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 – Zur Robustheit der Sprachführung für Sehaufgaben auf niedrigem Niveau: Erkenntnisse aus der Tiefenschätzung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/12 – MonoPatchNeRF: Verbesserung neuronaler Strahlungsfelder mit Patch-basierter monokularer Führung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 – Megalodon: Effizientes LLM-Vortraining und Inferenz mit unbegrenzter Kontextlänge
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 12.04. – Verändert ChatGPT den Schreibstil von Akademikern?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/12 - COCONut: Modernisierung der COCO-Segmentierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 12.04. – KI-Chip reduziert Energiebudget um über 99 Prozent
(Nachricht), - 04/12 – AdapterSwap: Kontinuierliche Schulung von LLMs mit Datenentfernungs- und Zugriffskontrollgarantien
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 12.04. – Grok-1.5 Vision-Vorschau
(Demo), - 04/12 – Der gute, der schlechte und der humane Pin
(Nachricht), - 12.04. – Bezahlte ChatGPT-Benutzer können jetzt auf GPT-4 Turbo zugreifen
(Twitter), (Nachrichten), , () - 04/11 – Die Notwendigkeit von AI Audit Standards Boards
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/11 – Transformer für kontinuierliches Lernen in Erinnerung behalten
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11.04. – Amazon beruft Andrew Ng, eine führende Stimme im Bereich der künstlichen Intelligenz, in seinen Vorstand
(Nachricht), - 11.04. – Adobe kauft Videos für 3 US-Dollar pro Minute, um ein KI-Modell zu erstellen
(Nachricht), - 04/11 – UltraEval: Eine leichte Plattform für flexible und umfassende Evaluierung für LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 – Übertragbare und prinzipielle Effizienz für die Segmentierung des offenen Wortschatzes
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 - SWE-Agent
(Twitter), (Demo), , () - 04/11 – Sparse Laneformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 11.04. – Rho-1: Nicht alle Token sind das, was Sie brauchen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 – ResearchAgent: Iterative Forschungsideengenerierung über wissenschaftliche Literatur mit großen Sprachmodellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 – RecurrentGemma: Über Transformatoren hinweg für effiziente offene Sprachmodelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 – OSWorld: Benchmarking multimodaler Agenten für offene Aufgaben in realen Computerumgebungen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 - LLoCO: Lange Kontexte offline lernen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 – Nutzung großer Sprachmodelle (LLMs) zur Unterstützung der kollaborativen Online-Annotation von Risikodaten zwischen Mensch und KI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 – JetMoE: Erreichen der Llama2-Leistung mit 0,1 Mio. Dollar
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) (Projekt), (twitter), , (✳️), () - 04/11 – HGRN2: Gated Linear RNNs mit State Expansion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/11 – Von Wörtern zu Zahlen: Ihr großes Sprachmodell ist insgeheim ein leistungsfähiger Regressor, wenn es Beispiele im Kontext gibt
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 – Ferret-v2: Eine verbesserte Basis für Referenzierung und Erdung mit großen Sprachmodellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 – ControlNet++: Verbesserung bedingter Kontrollen durch effizientes Konsistenz-Feedback
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 – Kontextbewusste Erkennung von Videoanomalien in Langzeitdatensätzen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 – ChatGPT-3.5, Claude 3 tritt pixeligen Hintern im Street Fighter III-Turnier für LLMs
(Nachricht), - 04/11 – ChatGPT kann die Zukunft vorhersagen, wenn es in der Zukunft angesiedelte Geschichten über die Vergangenheit erzählt
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 – Best Practices und gewonnene Erkenntnisse zu synthetischen Daten für Sprachmodelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 – Benchmarking von LLMs durch Kämpfe in Street Fighter 3
(Demo), , () - 04/11 – Audio Dialogues: Dialogues-Datensatz für das Audio- und Musikverständnis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 – Die Anwendung von Anleitungen in einem begrenzten Intervall verbessert die Proben- und Verteilungsqualität in Diffusionsmodellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/11 – AmpleGCG: Erlernen eines universellen und übertragbaren generativen Modells kontradiktorischer Suffixe für das Jailbreaking sowohl offener als auch geschlossener LLMs
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/10 – LM Transparency Tool: Interaktives Tool zur Analyse von Transformer-Sprachmodellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 – Gemini 1.5 Pro versteht jetzt Audio
(Twitter), - 04/10 – Konzepttiefe erforschen: Wie erwerben große Sprachmodelle Wissen auf verschiedenen Ebenen?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/10 – Urban Architect: Steuerbare 3D-Stadtszenengenerierung mit Layout Prior
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 – RealmDreamer: Textgesteuerte 3D-Szenengenerierung mit Inpainting und Tiefendiffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 – OpenAI und Meta stehen kurz davor, KI-Modelle zu veröffentlichen, die wie Menschen denken können, heißt es in einem Bericht
(Nachricht), - 04/10 – MetaCheckGPT – Ein Multitasking-Halluzinationsdetektor unter Verwendung von LLM-Unsicherheits- und Metamodellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 – Meta bestätigt, dass sein Llama 3 Open-Source-LLM im nächsten Monat erscheint
(Nachricht), - 04/10 – Lassen Sie keinen Kontext zurück: Effiziente unendliche Kontexttransformatoren mit unendlicher Aufmerksamkeit
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 – Inkrementelles XAI: Einprägsames Verständnis von KI mit inkrementellen Erklärungen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 – DreamScene360: Uneingeschränkte Text-zu-3D-Szenengenerierung mit Panorama-Gauß-Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 – Enthält Mapo-Tofu Kaffee? Untersuchung von LLMs auf lebensmittelbezogenes Kulturwissen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 – BRAVE: Erweiterung der visuellen Kodierung von Vision-Sprachmodellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 – Das KI-Startup Mistral bringt ein 281-GB-KI-Modell auf den Markt, das mit OpenAI, Meta und Google konkurriert
(Nachricht), - 04/10 – Agentengesteuerte generative semantische Kommunikation für die Fernüberwachung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 – Anpassung des LLaMA-Decoders an den Vision Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/10 – Eine Umfrage zur Integration generativer KI für kritisches Denken in Mobilfunknetzen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 – Schauen Sie es sich an! Überdenken der Bewertung des Sprachmodell-Jailbreaks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 – RULER: Wie groß ist die tatsächliche Kontextgröße Ihrer Langkontext-Sprachmodelle?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 – Überarbeitung der Verdichtung im Gaußschen Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 - Rekonstruktion handgehaltener Objekte in 3D
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 – RAR-b: Argumentation als Retrieval-Benchmark
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 – Privacy Preserving Prompt Engineering: Eine Umfrage
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 – Zur Bewertung der Effizienz von Quellcode, der von LLMs generiert wird
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 04/09 – Technischer Bericht zu OmniFusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 – MuPT: Ein vortrainierter Transformator für generative symbolische Musik
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 – MiniCPM: Das Potenzial kleiner Sprachmodelle mit skalierbaren Trainingsstrategien enthüllen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 – Magic-Boost: Steigern Sie die 3D-Generierung mit bedingter Mutli-View-Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/09 – LLM2Vec: Große Sprachmodelle sind insgeheim leistungsstarke Textkodierer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - InternLM-XComposer2-4KHD: Ein bahnbrechendes großes Vision-Language-Modell, das Auflösungen von 336 Pixeln bis 4K HD verarbeitet
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 - Hash3D: Trainingsfreie Beschleunigung für die 3D-Generierung
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 – Google stellt Open-Source-Projekte für generative KI vor
(Nachricht), - 04/09 – Elefanten vergessen nie: Auswendiglernen und Lernen von Tabellendaten in großen Sprachmodellen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/09 – Apple hat gerade das neue Ferret-UI LLM vorgestellt – diese KI kann Ihren iPhone-Bildschirm lesen
(Nachricht), - 04/09 – AEGIS: Online-Moderation für adaptive KI-Inhaltssicherheit mit einem Ensemble von LLM-Experten
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 - YaART: Noch eine weitere ART-Rendering-Technologie
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 – WILBUR: Adaptives In-Context-Lernen für robuste und genaue Web-Agenten
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 – UniFL: Verbessern Sie die stabile Verbreitung durch einheitliches Feedback-Lernen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 – Unbridled Icarus: Ein Überblick über die potenziellen Gefahren von Bildeingaben in der Sicherheit multimodaler großer Sprachmodelle
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 – The Hallucinations Leaderboard – Ein offener Versuch, Halluzinationen in großen Sprachmodellen zu messen
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 04/08 – Das Problem der Faktenauswahl bei der LLM-basierten Programmreparatur
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 04/08 - Swapanything: Aktiviert ein beliebiges Objekttausch in der personalisierten visuellen Bearbeitung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Sambalingo: Lehren von großen Sprachen neue Sprachen unterrichten
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Negative Präferenzoptimierung: vom katastrophalen Zusammenbruch zum effektiven Verlernen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Naver debütiert mehrsprachige Hyperclova x llm, mit der es für Asien souveräne AI erstellt wird
(Nachricht), - 04/08 - MOMA: Multimodaler LLM -Adapter für eine schnelle personalisierte Bildgenerierung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - medexpqa: Mehrsprachiger Benchmarking von großsprachigen Modellen für die Beantwortung medizinischer Frage
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08- MA-LMM: Memory-Augmented großes multimodales Modell für langfristiges Videoverständnis
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Layoutllm: Layout -Anweisung Tuning mit großen Sprachmodellen für das Verständnis des Dokuments
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/08 - Ferret -UI: geerdete mobile UI -Verständnis mit multimodalen LLMs
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Bewertung interventioneller Argumentationsfunktionen großer Sprachmodelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Eagle und Finch: RWKV mit Matrix -Wert -Zuständen und dynamischem Rezidiv
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/08 - Codeclm: Sprachmodelle mit maßgeschneiderten synthetischen Daten ausrichten
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/08 - Autocoderover: Autonome Programmverbesserung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/07 - Zeitgpt in der Lastprognose: Eine große Zeitreihenperspektive
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/07 - OpenAI transkribierte über eine Million Stunden YouTube -Videos, um GPT -4 zu trainieren
(Nachricht), - 04/07 - Magictime: Zeitraffer -Videogenerierungsmodelle als metamorphe Simulatoren
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/07 - BYTEEDIT: Schub, Einhaltung und Beschleunigung der generativen Bildbearbeitung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - Mehrheitswahl für Ärzte verbessert die Angemessenheit der Abhängigkeit von KI in die Pathologie
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 04/06- Diffusion-RWKV: Skalierung von RWKV-ähnlichen Architekturen für Diffusionsmodelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/06- DATENERF: Tiefenbewusst textbasierte Bearbeitung von Nerfs
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06- Beyondscene: Human-zentrierte Szenengenerierung mit höherer Auflösung mit vorbereiteter Diffusion
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - Ausrichtung von Diffusionsmodellen durch Optimierung des menschlichen Nutzens
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/06 - Der Fall für die Entwicklung eines Fundamentmodells für planungsähnliche Aufgaben von Grund auf neu
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Erhöhte LLM -Schwachstellen durch Feinabstimmung und Quantisierung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Spatialtracker: Verfolgung von 2D -Pixeln im 3D -Raum
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Training für soziale Skills mit großen Sprachmodellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Sigma: Siamese Mamba Network für multimodale semantische Segmentierung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/05 - Robustes Gaußscher Splating
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Physavatar: Lernen der Physik von gekleideten 3D -Avataren aus visuellen Beobachtungen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05- KOALA: Key Frame-Conditioned Long Video-Llm
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Hinweis: Eine klinische Sprachverständnisbewertung für LLMs
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Chinesische winzige LLM: Vorbereitungen eines chinesischen Großsprachenmodells
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/05 - Unterstützung des Menschen in komplexen Vergleiche: Automatisierter Informationsvergleich in Maßstab
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - verkörperte AI mit zwei Armen: Null -Shot -Lernen, Sicherheit und Modularität
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 04/04 - Sprachmodellentwicklung: Eine iterierte Lernperspektive
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- Visualisierung des Gedanken
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) (twitter), - 04/04 - Nein "Zero -Shot" ohne exponentielle Daten: Die Konzeptfrequenz der Vorab -Konzept bestimmt die multimodale Modellleistung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Bewertung von LLMs beim Erkennen von Fehlern in LLM -Antworten
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Bewertung generativer Sprachmodelle in der Informationsextraktion als subjektive Fragekorrektur
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Direkte NASH -Optimierung: Lehren von Sprachmodellen, um sich mit allgemeinen Vorlieben zu verbessern
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- CBR-RAG: Fallbasierte Argumentation zum Abrufen Augmented Generation in LLMs für die Beantwortung von Rechtsfragen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Funktionen von Großsprachenmodellen in Control Engineering: Eine Benchmark -Studie zu GPT -4, Claude 3 Opus und Gemini 1.0 Ultra
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - CanttalkaboutThis: Sprachmodelle ausrichten, um in Dialogen zum Thema zu bleiben
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - AutoWebglm: Bootstrap und verstärken einen großsprachigen modellbasierten Web -Navigating -Agenten
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04 - Trainings -LLMs über neural komprimierten Text
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - Reft: Repräsentation Finetuning für Sprachmodelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/04- Red Teaming GPT-4V: Sind GPT-4V gegen UNI/Multi-Modal-Jailbreak-Angriffe sicher?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- Rall-E: Robust Codec-Sprachmodellierung mit der Aufforderung zur Kette der Gedanken für die Synthese von Text-to-Speech
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - PointInfinity: Auflösungsinvariante Punktdiffusionsmodelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- Minigpt4-Video: Multimodale LLMs für Videoverständnisse mit verschachtelten visuellen Text-Token vorantreiben
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04- COMAT: Ausrichten von Text-zu-Image-Diffusionsmodell mit dem Bild-zu-Text-Konzept Matching
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - CodeditorBench: Bewertung der Codemittelungsfähigkeit großer Sprachmodelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/04 - AutoWebglm: Bootstrap und verstärken einen großsprachigen modellbasierten Web -Navigating -Agenten
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03 - Visuelle autoregressive Modellierung: Skalierbare Bildgenerierung durch die Vorhersage der nächsten Skala
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03- Über die Skalierbarkeit von Diffusionsbasis-basierter Text-zu-Image-Erzeugung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03 - Many -Shot -Jailbreaking
() - 04/03- LVLM-In-Trepret: Ein Interpretierbarkeitsinstrument für große Sichtsprachenmodelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03 - Sprachmodelle als Compiler: Die Simulation der Pseudocode -Ausführung verbessert das algorithmische Denken in Sprachmodellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03- InstantStyle: Kostenloses Mittagessen in Richtung Style-Boning in der Generierung von Text-zu-Image
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03 - Freditor: hohe Abfindungs- und übertragbare NERF -Bearbeitung durch Frequenzabzersetzung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/03- Cross-Tention macht Inferenz in Text-zu-Image-Diffusionsmodellen umständlich
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/03- CHATGLM-MATH: Verbesserung der Mathematik-Problemlösung in Großsprachenmodellen mit einer selbstkritischen Pipeline
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/02 - Großbritannien & Vereinigte Staaten kündigen Partnerschaft zur Wissenschaft der KI -Sicherheit an
(Nachricht), - 04/02 - Großsprachenmodelle als Planungsdomänengeneratoren
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 04/02 - PORO 34B und der Segen der Mehrrichtung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02 - Octopus V2: Sprachmodell für Super -Agent für Super Agent
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02- Mischung aus den Tiefen: Dynamisch Berechnung in transformatorbasierten Sprachmodellen zuweisen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02- Langkontext-LLMs kämpfen mit langem In-Context-Lernen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/02 - LLM -ABR: Entwerfen adaptiver Bitrate -Algorithmen über große Sprachmodelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02 - Große Sprachmodelle könnten die Zukunft der Verhaltensgesundheit verändern: Ein Vorschlag für die verantwortungsvolle Entwicklung und Bewertung
() - 04/02 - Hyperclova X Technischer Bericht
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/02- Cameractrl: Aktivierung der Kamera-Steuerung für die Erzeugung von Text-zu-Video
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/02 - LLM Argumentation Generalisten mit Präferenzbäumen vorantreiben
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Suchstream (SOS): Lernen in der Sprache lernen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - LLM als Mastermind: Eine Umfrage zum strategischen Denken mit großen Sprachmodellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Der Aufstieg und der Aufstieg von AI großartigen Sprachmodellen (LLMs)
(Blog), - 04/01 - Streaming Dichte Videounterschrift Streaming
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Messstil -Ähnlichkeit in Diffusionsmodellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01- Machen Sie es richtig: Verbesserung der räumlichen Konsistenz in Text-zu-Image-Modellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Für datenverletzende KI -Unternehmen ist das Internet zu klein
(Nachricht), - 04/01- flexidreamer: Einzelbild-zu-3D-Generation mit Flexicubes
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Evaluse: Unified und zugänglich
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - Direkte Präferenzoptimierung von Video großen multimodalen Modellen aus der Belohnung des Sprachmodells
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 04/01 - DBRX, kontinuierliche Vorbereitung, Belohnung, schnellere Inferenz und mehr
(Blog), - 04/01- Cosmicman: Ein Text-zu-Image-Fundamentmodell für den Menschen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Kondition -bewusstes neuronales Netzwerk für die kontrollierte Bildgenerierung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Größer ist nicht immer besser: Skalierungseigenschaften latenter Diffusionsmodelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 04/01 - Sind große Sprachmodelle übermenschliche Chemiker?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/31 - Wavllm: Auf dem Weg zu einem robusten und adaptiven Sprachmodell großer Sprache
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/31 - Müde von Plugins? Großsprachige Modelle können End-to-End-Empfehlungen sein
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/30 - Umfrage zum großsprachigen Modellverstärkungslernen: Konzept, Taxonomie und Methoden
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/30 - ST -LlM: Großsprachige Modelle sind effektive zeitliche Lernende
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 03/30- Rauschbewusstes Training von Layout-bewahrten Sprachmodellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/30 - Magritte: Manipulative und generative 3D -Realisierung aus Bild, Topview und Text
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 03/30- Aurora-M: Das erste Open-Source-mehrsprachige Sprachmodell, das gemäß der US-Executive Order rot-Team
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Unlösbare Problemerkennung: Bewertung der Vertrauenswürdigkeit von Sehsprachenmodellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29- Transformator-Lite: Hochwirkungsgrades Bereitstellung von großsprachigen Modellen auf dem Mobiltelefon-GPUs
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29- Snap-it, Tap-it, splat-it: taktilgeformte 3D-Gaußsche Splatting für die Rekonstruktion herausfordernder Oberflächen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Realm: Referenzauflösung als Sprachmodellierung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - NVIDIA H200 GPUS CREBS MLPERFs LLM -Inferenz -Benchmark
(Nachricht), - 03/29 - Mambamixer: Effiziente selektive Zustandsraummodelle mit Doppel -Token- und Kanalauswahl
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - LLAVA -GEMMA: Beschleunigende multimodale Grundlagenmodelle mit einem kompakten Sprachmodell
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29- Instantsplat: Unbegrenzter spärlicher Pose-freier Gaußscher Splating in 40 Sekunden
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Gecko: Vielseitige Textbettdings, destilliert von großen Sprachmodellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Dijiang: Effiziente Großsprachenmodelle durch kompakte Kernelisierung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/29- DeepMind entwickelt sich sicher, eine AI-basierte App, die LLMs fakten überprüfen kann
(Nachricht), - 03/29 - Strg -SIM: reaktive und kontrollierbare Fahrmittel mit Offline -Verstärkungslernen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/29 - Sind wir auf dem richtigen Weg zur Bewertung großer Sichtsprachmodelle?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/28 - SDPO: Verwenden Sie Ihre Daten nicht alle gleichzeitig
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/28 - MESH2NERF: Direkte Mesh -Überwachung für die Repräsentation und Erzeugung neuronaler Strahlen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/28 - Lokalisierung von Absätzen in Sprachmodellen lokalisieren
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/28 - Jamba: Ein hybrides Transformator -Mamba -Sprachmodell
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 28.03.28 - Gaußsiancube: Strukturierung von Gaußschen Splating unter Verwendung eines optimalen Transports für die 3D -Generative Modellierung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/28 - Claude 3 überholt GPT -4 im Duell der AI -Bots. Hier erfahren Sie, wie Sie in die Aktion einsteigen können
(Nachricht), - 03/28 - Ankündigung von GROK -1.5
(Blog), (Demo), - 03/27 - Ein Weg zur legalen Autonomie: Ein interoperabler und erklärbarer Ansatz zum Extrahieren, Transformieren, Laden und Berechnen von Rechtsinformationen mit großer Sprachmodellen, Expertensystemen und Bayes'schen Netzwerken
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27 - Vitar: Vision Transformator mit jeder Auflösung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27- Auf dem Weg zu einem weltglischen Sprachmodell für virtuelle Assistenten auf dem Gerät
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27 - TextCraftor: Ihr Text -Encoder kann Bildqualitätscontroller sein
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 23.03 .
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27- Mini-Gemini: Bergung des Potenzials von Multi-Modality Vision Language-Modellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/27 - Langform -Fakten in Großsprachenmodellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/27 - LITA: Sprache, die Temporal -Localization Assistant angewiesen hat
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/27 - Kleidungsstück 3DGen: 3D -Kleidungsstilisierung und Texturgenerierung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27 - Gamba: Heirate Gaußscher Splating mit Mamba für eine 3D -Rekonstruktion von Einzelansicht
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27- Flexedit: Flexible und kontrollierbare diffusionsbasierte objektorientierte Bildbearbeitung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/27 - BiomedLM: Ein auf biomedizinischem Text trainierter Parametersprachenmodell von 2,7B
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26- MAGIS: LLM-basiertes Multi-Agent-Framework für GitHub-Problemlösung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26 - Die unangemessene Unwirksamkeit der tieferen Schichten
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26- TC4D: Trajektorien-konditionierte Text-zu-4d-Generation
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26- Octree-GS: Auf dem Weg zu einem konsequenten Echtzeit-Rendering mit lodstrukturierten 3D-Gaußern
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/26- Einführung von DBRX: Eine neue hochmoderne offene LLM
(Blog), - 26.03.26 - Interner technischer Bericht für Internlm2
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/26- Verbesserung der Konsistenz von Text zu Image durch automatische Eingabeaufforderungoptimierung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26- Vollständiger Mehrschicht-Perzeptrons im Intel Data Center GPUs
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/26 - Egolifter: Open -World 3D -Segmentierung für die egozentrische Wahrnehmung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/26 - Aniportait: Audiogetriebene Synthese der fotorealistischen Porträtanimation
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/26 - 2d Gaußsche Splating für geometrisch genaue Strahlenfelder
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25 - Auf der automatischen Bewertung der klinischen Funktionen von LLMs: Metrik, Daten und Algorithmus
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25 - Reparaturagent: Ein autonomer LLM -basierter Agent für die Programmreparatur
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25- RL für Konsistenzmodelle: schnellere Belohnung Guided Text-to-Image-Generation
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/25- VP3D: Entfesseln Sie die 2D-visuelle Eingabeaufforderung für Text-zu-3D-Generation
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25- Reise: Temporales Restlernen mit Bildrauschen vor den Image-Video-Diffusionsmodellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25- SDXS: Echtzeit einstufige latente Diffusionsmodelle mit Bildbedingungen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/25 - LLM Agent Betriebssystem
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/25 - Flashface: Menschliche Bildpersonalisierung mit hoher Erhaltung der Identität von hoher Quelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/25- Dreampolisher: Auf dem Weg zu einer hochwertigen Text-zu-3d-Generation über geometrische Diffusion
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/25- Sei du selbst: begrenzte Aufmerksamkeit für die Erzeugung von Text-zu-Image-Multi-Subjekte
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/23 - Wenn LLM -basierte Codegenerierung dem Softwareentwicklungsprozess erfüllt
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/22 - Themsee: Erzeugen von themenbewussten 3D -Vermögenswerten von wenigen Exemplaren
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/22 - SIMBA: vereinfachte Mamba -basierte Architektur für Vision und multivariate Zeitreihe
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/22 - LLM2LLM: Steigerung von LLMs mit neuartiger iterativer Datenverstärkung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/22- LATTE3D: Großer amortisierter Text-zu-verstärkter 3-Skala-Synthese
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/22 - Internvideo2: Skalierung von Videofundierungsmodellen für multimodales Videoverständnis
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 22.03.22 - Folgen Sie: Bewertung und Unterrichten von Informationen zum Abrufen von Informationen, um Anweisungen zu befolgen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/22 - Dragapart: Erlernen einer beweglichen Bewegungsbewegung vor artikulierten Objekten
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/22 - Können große Sprachmodelle In -Context untersuchen?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/22 - AllHands: Fragen Sie mich nach großem Maßstab wörtlich über große Sprachmodelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss) - 03/21 - PEERGPT: Untersuchung der Rolle von Peer -Agenten auf LLM -basierten Peer -Agenten als Team Moderatoren und Teilnehmer am kollaborativen Lernen von Kindern
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - Stylecinegan: Landschaft Cinemagraph Generation mit einem vorgebildeten Stylegan
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/21 - Streamingt2V: Konsistent, dynamisch und erweiterbares langes Videogenerierung aus dem Text
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/21 - Renoise: Echte Bildinversion durch iterative Nosing
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03.03.21 - Rücksicht auf Rückgewinnung: Chatten mit generativen Sprachmodellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - Rakutenai -7b: Erweiterung großer Sprachmodelle für Japanisch
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - MyVLM: Personalisierung von VLMs für benutzerspezifische Abfragen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - Mathverse: sieht Ihr multi -modales LLM die Diagramme in visuellen Mathematikproblemen wirklich?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - GRM: Großes Gaußsche Rekonstruktionsmodell für eine effiziente 3D -Rekonstruktion und -erzeugung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/21 - Generalversammlung übernimmt die Lösung der Wahrzeichen der künstlichen Intelligenz
(Nachricht), - 03/21 - Gaußscher Frosting: bearbeitbare komplexe Strahlungsfelder mit Echtzeit -Rendering
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - Erkundungsgeschäfte zwischen Zeit und Raum
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21- Effiziente Videodiffusionsmodelle über die Zersetzung von Miending-Latenten-Rahmen-Rahmen-Rahmen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21- Dreamreward: Text-zu-3d-Generation mit menschlicher Präferenz
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/21 - Cobra: Mamba auf multimodales Großsprachmodell für eine effiziente Inferenz erweitern
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/21 - Champ: Steuerbare und konsistente menschliche Bildanimation mit parametrischer 3D -Anleitung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/21- Anyv2v: Ein Plug-and-Play-Framework für alle Bearbeitungsaufgaben Video-zu-Video
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Zuordnung von LLM -Sicherheitslandschaften: Ein umfassender Vorschlag für Risikobewertungen der Stakeholder -Risikobewertung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Zickma: Zickzack Mamba -Diffusionsmodell
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 - VSTAR: Generative Temporal Nursing für eine längere dynamische Video -Synthese
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Belohnung: Bewertung von Belohnmodellen für die Sprachmodellierung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03.03.20 - Umkehrtraining, um den Umkehrfluch zu stillen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20- Radsplat: Field-informiertes Gaußscher Splating für robustes Echtzeit-Rendering mit 900+ FPS
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - MORA: Ermöglichen der Generalisten -Videogenerierung über einen Multi -Agent -Framework
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 - Lamafactory: Einheitliche effiziente Feinabstimmung von über 100 Sprachmodellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20- IDADAPTER: Lernen gemischte Funktionen für die stimmfreie Personalisierung von Text-zu-Image-Modellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - Hyperllava: Dynamisches Visual- und Sprach -Experten -Tuning für multimodale Großsprachenmodelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/20 - Bewertung von Grenzmodellen für gefährliche Fähigkeiten
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - TiepthFM: Schnelle Monokulartiefenschätzung mit Flussanpassung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20 - compress3d: Ein komprimierter latenter Raum für die 3D -Generierung von einem einzelnen Bild
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/20- Be-your-outpainter: Mastering von Videos,
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Wann brauchen wir keine größeren Sehmodelle?
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19- VID2ROBOT: End-to-End-Video-konditioniertes Richtlinienlernen mit Cross-Tention-Transformers
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Auf dem Weg zu einem allgemeinen Fundamentmodell für die Computerpathologie
() - 03/19- Texdreamer: In Richtung Null-Shot-High-Fidelity-3D-Erzeugung menschlicher Textur
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Szeneskript: Szenen mit einem autoregressiven strukturierten Sprachmodell rekonstruieren
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19- MPLUG-Dokowl 1.5: Unified Structure Lernen für OCR-freie Dokumentverständnis
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Magic Fixup: Optiminierung der Fotobearbeitung durch Ansehen von dynamischen Videos
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19- Llmlingua-2: Datendestillation für effiziente und treue Aufgaben-agnostische Eingabeaufforderungskomprimierung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19- GVGen: Text-zu-3d-Generation mit volumetrischer Darstellung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Gaußscherflow: Splating Gaußsche Dynamik für die Erstellung von 4D -Inhalten
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19- Fresko: räumlich-zeitliche Korrespondenz für eine Videoübersetzung mit Null-Shot
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19- Fouriscale: Eine Frequenzperspektive auf die schultrainfreie hochauflösende Bildsynthese
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Evolutionäre Optimierung von Modellverführungsrezepten
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), ([: Octocat:] (https : //github.com/ sakanaai/evolutionary-model-merge)! [github repo stars] (https://img.shields.io/github/stars/ sakanaai/evolutionary-model-merge? style = sozial))) - 03/19 - Kombination: Erstellung von 3D -Vermögenswerten für Zusammensetzungen mit räumlich bewusstes Diffusionsanleitung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Diagrammbasierte Argumentation: Übertragungsfunktionen von LLMs auf VLMs übertragen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Apples MM1: Ein multimodales großes Sprachmodell, das sowohl Bilder als auch Textdaten interpretieren kann
(Nachricht), - 03/19- Animatediff-Lightning: Cross-Model-Diffusionsdestillation
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/19 - Agent -Flan: Entwerfen von Daten und Methoden der effektiven Agentenabstimmung für große Sprachmodelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/19 - Ein visuellsprachiges Fundamentmodell für die Computerpathologie
(), (✳️) - 03/19 - charakteristische KI -Agenten über Großsprachmodelle
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), (! [Github repo sterne] ( https://img.shields.io/github/stars/nuaa-nlp/character100? style = social)) - 03/18 - Wie weit sind wir auf der Entscheidungsfindung von LLMs? Bewertung der Spielfähigkeit von LLMs in mehreren Agentenumgebungen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/18 - Videoagent: Ein maßstabsgerütiger multimodaler Agent für das Videoverständnis
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18 - Vfusion3D: Lernkalierbare 3D -Generative -Modelle aus Videodiffusionsmodellen lernen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18 - TNT -LlM: Textmining im Maßstab mit großen Sprachmodellen
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18 - SV3D: Neue Multi -View -Synthese und 3D -Generierung aus einem einzelnen Bild unter Verwendung der latenten Videodiffusion
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18 - Routerbench: Ein Benchmark für das Multi -LlM -Routing -System
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), (ss) - 03/18- META-Prompten zur Automatisierung von Null-Shot-Visualerkennung mit LLMs
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/18 - LN3DIFF: Skalierbare latente Neuralfelder Diffusion für die schnelle 3D -Generation
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18- Llava-UHD: Ein LMM, das jedes Seitenverhältnis und hochauflösende Bilder wahrnimmt
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️), () - 03/18 - Larimar: Großsprachige Modelle mit episodischer Gedächtnissteuerung
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18- Infinite-ID: Identitäts-bedrohte Personalisierung über ID-Semantics-Entkopplungsparadigma
(), (), (?), (?), (?), (Html), (sl), (sp), (gs), (ss), (✳️) - 03/18 - GPT -4 als Bewerter: Bewertung großer Sprachmodelle zum Schädlingsmanagement in der Landwirtschaft
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - From Pixels to Insights: A Survey on Automatic Chart Understanding in the Era of Large Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/18 - Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Decoding Compressed Trust: Scrutinizing the Trustworthiness of Efficient LLMs Under Compression
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/18 - Compiler generated feedback for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - PhD: A Prompted Visual Hallucination Evaluation Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/17 - MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/16 - VisionCLIP: An Med-AIGC based Ethical Language-Image Foundation Model for Generalizable Retina Image Analysis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/16 - Do Large Language Models understand Medical Codes?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - VideoAgent: Long-form Video Understanding with Large Language Model as Agent
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Trusting the Search: Unraveling Human Trust in Health Information from Google and ChatGPT
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - RAFT: Adapting Language Model to Domain Specific RAG
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - PERL: Parameter Efficient Reinforcement Learning from Human Feedback
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - NeuFlow: Real-time, High-accuracy Optical Flow Estimation on Robots Using Edge Devices
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - MusicHiFi: Fast High-Fidelity Stereo Vocoding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/15 - LightIt: Illumination Modeling and Control for Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/15 - FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Enhancing Human-Centered Dynamic Scene Understanding via Multiple LLMs Collaborated Reasoning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - EfficientVMamba: Atrous Selective Scan for Light Weight Visual Mamba
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - DiPaCo: Distributed Path Composition
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/15 - Controllable Text-to-3D Generation via Surface-Aligned Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - WavCraft: Audio Editing and Generation with Natural Language Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Video Editing via Factorized Diffusion Distillation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Unlocking the conversion of Web Screenshots into HTML Code with the WebSight Dataset
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - StreamMultiDiffusion: Real-Time Interactive Generation with Region-Based Semantic Control
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Scaling Instructable Agents Across Many Simulated Worlds
(twitter), (Blog), - 03/14 - Recurrent Drafter for Fast Speculative Decoding in Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - LocalMamba: Visual State Space Model with Windowed Selective Scan
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Helpful or Harmful? Exploring the Efficacy of Large Language Models for Online Grooming Prevention
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - Griffon v2: Advancing Multimodal Perception with High-Resolution Scaling and Visual-Language Co-Referring
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - GPT on a Quantum Computer
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/14 - Glyph-ByT5: A Customized Text Encoder for Accurate Visual Text Rendering
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - GiT: Towards Generalist Vision Transformer through Universal Language Interface
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - Exploring the Capabilities and Limitations of Large Language Models in the Electric Energy Sector
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/14 - BurstAttention: An Efficient Distributed Attention Framework for Extremely Long Sequences
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/14 - 3D-VLA: A 3D Vision-Language-Action Generative World Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Scaling Instructable Agents Across Many Simulated Worlds
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/13 - VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - The Human Factor in Detecting Errors of Large Language Models: A Systematic Literature Review and Future Research Directions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - SOTOPIA-π: Interactive Learning of Socially Intelligent Language Agents
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Simple and Scalable Strategies to Continually Pre-train Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Scaling Up Dynamic Human-Scene Interaction Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language-based game theory in the age of artificial intelligence
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Language models scale reliably with over-training and on downstream tasks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Knowledge Conflicts for LLMs: A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Gemma: Open Models Based on Gemini Research and Technology
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/13 - Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Cultural evolution in populations of Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/13 - Bugs in Large Language Models Generated Code: An Empirical Study
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Synth^2: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Motion Mamba: Efficient and Long Sequence Motion Generation with Hierarchical and Bidirectional Selective SSM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - MoAI: Mixture of All Intelligence for Large Language and Vision Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - Learning Generalizable Feature Fields for Mobile Manipulation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/12 - DragAnything: Motion Control for Anything using Entity Representation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Chronos: Learning the Language of Time Series
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/12 - Branch-Train-MiX: Mixing Expert LLMs into a Mixture-of-Experts LLM
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Transparent AI Disclosure Obligations: Who, What, When, Where, Why, How
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - HILL: A Hallucination Identifier for Large Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - FAX: Scalable and Differentiable Federated Primitives in JAX
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FashionReGen: LLM-Empowered Fashion Report Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - VideoMamba: State Space Model for Efficient Video Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - V3D: Video Diffusion Models are Effective 3D Generators
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Stealing Part of a Production Language Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/11 - Multistep Consistency Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - FaceChain-SuDe: Building Derived Class to Inherit Category Attributes for One-shot Subject-Driven Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/11 - Chain-of-table: Evolving tables in the reasoning chain for table understanding (Blog),
- 03/11 - An Image is Worth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision-Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/11 - Adding NVMe SSDs to Enable and Accelerate 100B Model Fine-tuning on a Single GPU
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/10 - VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/09 - Algorithmic progress in language models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - On Protecting the Data Privacy of Large Language Models (LLMs): A Survey
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 03/08 - VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - ELLA: Equip Diffusion Models with LLM for Enhanced Semantic Alignment
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - DeepSeek-VL: Towards Real-World Vision-Language Understanding
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/08 - CRM: Single Image to 3D Textured Mesh with Convolutional Reconstruction Model
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - CogView3: Finer and Faster Text-to-Image Generation via Relay Diffusion
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/08 - Now available on Poe: Claude 3 (Demo),
- 03/08 - Google - Health-specific embedding tools for dermatology and pathology (Blog),
- 03/07 - Yi: Open Foundation Models by 01.AI
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Teaching Large Language Models to Reason with Reinforcement Learning
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - StableDrag: Stable Dragging for Point-based Image Editing
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Radiative Gaussian Splatting for Efficient X-ray Novel View Synthesis
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Pix2Gif: Motion-Guided Diffusion for GIF Generation
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Meet 'Liberated Qwen', an uncensored LLM that strictly adheres to system prompts (News),
- 03/07 - LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - KAIST develops next-generation ultra-low power LLM accelerator (News),
- 03/07 - Inflection-2.5: meet the world's best personal AI (News),
- 03/07 - How Far Are We from Intelligent Visual Deductive Reasoning?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/07 - Evaluating LLM models at scale (Blog),
- 03/07 - Common 7B Language Models Already Possess Strong Math Capabilities
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/07 - Chatbot Arena: An Open Platform for Evaluating LLMs by Human Preference
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Stop Regressing: Training Value Functions via Classification for Scalable Deep RL
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - SaulLM-7B: A pioneering Large Language Model for Law
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - NY hospital exec: Multimodal LLM assistants will create a “paradigm shift” in patient care (News),
- 03/06 - Learning to Decode Collaboratively with Multiple Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - Enhancing Vision-Language Pre-training with Rich Supervisions
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/06 - Backtracing: Retrieving the Cause of the Query
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/06 - AI Prompt Engineering Is Dead (News),
- 03/06 - 3D Diffusion Policy
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 03/05 - OpenAI and Elon Musk (Blog),
- 03/05 - Caduceus: Bi-Directional Equivariant Long-Range DNA Sequence Modeling
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/05 - WikiTableEdit: A Benchmark for Table Editing by Natural Language Instruction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Updating the Minimum Information about CLinical Artificial Intelligence (MI-CLAIM) checklist for generative modeling research (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Tuning-Free Noise Rectification for High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Revisiting Meta-evaluation for Grammatical Error Correction (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - NaturalSpeech 3: Zero-Shot Speech Synthesis with Factorized Codec and Diffusion Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Modeling Collaborator: Enabling Subjective Vision Classification With Minimal Human Effort via LLM Tool-Use (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - MathScale: Scaling Instruction Tuning for Mathematical Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - KnowAgent: Knowledge-Augmented Planning for LLM-Based Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/05 - Interactive Continual Learning: Fast and Slow Thinking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - InjecAgent: Benchmarking Indirect Prompt Injections in Tool-Integrated Large Language Model Agents (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - In Search of Truth: An Interrogation Approach to Hallucination Detection (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ImgTrojan: Jailbreaking Vision-Language Models with ONE Image (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Generative Software Engineering (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/05 - Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Feast Your Eyes: Mixture-of-Resolution Adaptation for Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Exploring the Limitations of Large Language Models in Compositional Relation Reasoning (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - EasyQuant: An Efficient Data-free Quantization Algorithm for LLMs (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Design2Code: How Far Are We From Automating Front-End Engineering? (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - Benchmarking the Text-to-SQL Capability of Large Language Models: A Comprehensive Evaluation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/05 - An Empirical Study of LLM-as-a-Judge for LLM Evaluation: Fine-tuned Judge Models are Task-specific Classifiers (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 3/5 - OpenAI - ChatGPT can now read responses to you. (twitter,
- 03/04 - The Claude 3 Model Family: Opus, Sonnet, Haiku
() (twitter), , (✳️) - 03/04 - Wukong: Towards a Scaling Law for Large-Scale Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - Large language models surpass human experts in predicting neuroscience results
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 03/04 - NoteLLM: A Retrievable Large Language Model for Note Recommendation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - MagicClay: Sculpting Meshes With Generative Neural Fields (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 03/04 - Enhancing LLM Safety via Constrained Direct Preference Optimization (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - DACO: Towards Application-Driven and Comprehensive Data Analysis via Code Generation (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - CODE-ACCORD: A Corpus of Building Regulatory Data for Rule Generation towards Automatic Compliance Checking (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 03/04 - Balancing Enhancement, Harmlessness, and General Capabilities: Enhancing Conversational LLMs with Direct RLHF (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️)
- 03/04 - adaptMLLM: Fine-Tuning Multilingual Language Models on Low-Resource Languages with Integrated LLM Playgrounds (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 3/4 - ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - TripoSR: Fast 3D Object Reconstruction from a Single Image (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - RT-H: Action Hierarchies Using Language (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - ResAdapter: Domain Consistent Resolution Adapter for Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/4 - OOTDiffusion: Outfitting Fusion based Latent Diffusion for Controllable Virtual Try-on (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 3/4 - Build AI for a Better Future (twitter), (News),
- 3/4 - AtomoVideo: High Fidelity Image-to-Video Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 03/03 - Research Papers in February 2024: A LoRA Successor, Small Finetuned LLMs Vs Generalist LLMs, and Transparent LLM Research (Blog),
- 3/3 - Nvidia CEO Jensen Huang says AI could pass most human tests in 5 years (News
- 3/3 - MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/3 - Could this be bigger than OpenAI? Microsoft invests billions in French startup — Mistral AI is a multilingual maestro that's almost as good as ChatGPT 4 (News),
- 3/3 - 3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 3/2 - Nvidia CEO says AI could pass human tests in five years (News
- 3/1 - Elon Musk sues OpenAI and CEO Sam Altman over contract breach (News)
- 3.1 - AtP*: An efficient and scalable method for localizing LLM behaviour to components (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - VisionLLaMA: A Unified LLaMA Interface for Vision Tasks (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Learning and Leveraging World Models in Visual Representation Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - RealCustom: Narrowing Real Text Word for Real-Time Open-Domain Text-to-Image Customization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Multimodal ArXiv: A Dataset for Improving Scientific Comprehension of Large Vision-Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 3.1 - Resonance RoPE: Improving Context Length Generalization of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/29 - OHTA: One-shot Hand Avatar via Data-driven Implicit Priors
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/29 - Retrieval-Augmented Generation for AI-Generated Content: A Survey (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), ()
- 2.29 - DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Humanoid Locomotion as Next Token Prediction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - StarCoder 2 and The Stack v2: The Next Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Trajectory Consistency Distillation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - Beyond Language Models: Byte Models are Digital World Simulators (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - Syntactic Ghost: An Imperceptible General-purpose Backdoor Attacks on Pre-trained Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.29 - ViewFusion: Towards Multi-View Consistency via Interpolated Denoising (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.29 - MOSAIC: A Modular System for Assistive and Interactive Cooking (), (), (?), (?), (?), (HTML), (SP), (GS), (SS)
- 02/28 - Automatic Creative Selection with Cross-Modal Matching
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS) - 2.28 - Priority Sampling of Large Language Models for Compilers (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Simple linear attention language models balance the recall-throughput tradeoff (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.28 - Approaching Human-Level Forecasting with Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.28 - Datasets for Large Language Models: A Comprehensive Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.28 - A Survey on Recent Advances in LLM-Based Multi-turn Dialogue Systems (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - A High Level Guide to LLM Evaluation Metrics (Blog),
- 2/27 - Users Say Microsoft's AI Has Alternate Personality as Godlike AGI That Demands to Be Worshipped (News)
- 2/27 - Google DeepMind CEO on AGI, OpenAI and Beyond – MWC 2024 (News)
- 2.27 - Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding -- A Survey (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Towards Optimal Learning of Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Evaluating Very Long-Term Conversational Memory of LLM Agents (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Seeing and Hearing: Open-domain Visual-Audio Generation with Diffusion Latent Aligners (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive -- Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Training-Free Long-Context Scaling of Large Language Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - DiffuseKronA: A Parameter Efficient Fine-tuning Method for Personalized Diffusion Model (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora Generates Videos with Stunning Geometrical Consistency (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.27 - Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.27 - Video as the New Language for Real-World Decision Making (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 02/27 - On the Societal Impact of Open Foundation Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/26 - Set the Clock: Temporal Alignment of Pretrained Language Models
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2/26 - DenseMamba: State Space Models with Dense Hidden Connection for Efficient Large Language Models (), ()(?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/26 - Mistral Large is our flagship model, with top-tier reasoning capacities (News)
- 2.26 - Disentangled 3D Scene Generation with Layout Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Multi-LoRA Composition for Image Generation (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.26 - Do Large Language Models Latently Perform Multi-Hop Reasoning? (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Rainbow Teaming: Open-Ended Generation of Diverse Adversarial Prompts (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Nemotron-4 15B Technical Report (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - StructLM: Towards Building Generalist Models for Structured Knowledge Grounding (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.26 - Towards Open-ended Visual Quality Comparison (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.25 - ChatMusician: Understanding and Generating Music Intrinsically with LLM (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ( )
- 2.25 - FuseChat: Knowledge Fusion of Chat Models (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 02/24 - Divide-or-Conquer? Which Part Should You Distill Your LLM?
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️) - 02/24 - Perplexity.ai Revamps Google SEO Model For LLM Era (News)
- 02/24 - Data Interpreter: An LLM Agent For Data Science
(), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS), (✳️), () - 2.24 - Empowering Large Language Model Agents through Action Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Seamless Human Motion Composition with Blended Positional Encodings (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - AgentOhana: Design Unified Data and Training Pipeline for Effective Agent Learning (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️ )
- 2.23 - Gen4Gen: Generative Data Pipeline for Generative Multi-Concept Composition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️), ()
- 2.23 - API-BLEND: A Comprehensive Corpora for Training and Benchmarking API LLMs (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - Genie: Generative Interactive Environments (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - GPTVQ: The Blessing of Dimensionality for LLM Quantization (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.23 - ChunkAttention: Efficient Self-Attention with Prefix-Aware KV Cache and Two-Phase Partition (), (), (?), (?), (?), (HTML), (SP), (GS), (SS), (✳️)
- 2.22 - CLoVe: Encoding Compositional Language in Contrastive Vision-Language Models (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️), ()
- 02/22 - Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models (), (), (?), (?), (?), (HTML), (SL), (SP), (GS), (SS)
- 2.22 - Divide-or-Conquer? Which Part Should You Distill Your LLM? (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - Watermarking Makes Language Models Radioactive (), (), (?), (?), (?), (HTML), (AS), (GS), (✳️)
- 2.22 - AutoPrompt - prompt optimization framework ()
- 2.22 - Announcing Stable Diffusion 3 (tweet), (blog)
- 2.22 - DualFocus: Integrating Macro and Micro Perspectives in Multi-modal Large Language Models (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - RoboScript: Code Generation for Free-Form Manipulation Tasks across Real and Simulation (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - LLMs with Industrial Lens: Deciphering the Challenges and Prospects -- A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Vision-Language Navigation with Embodied Intelligence: A Survey (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Enhancing Robotic Manipulation with AI Feedback from Multimodal Large Language Models (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - Do Machines and Humans Focus on Similar Code? Exploring Explainability of Large Language Models in Code Summarization (), (), (?), (?), (?), (HTML), (✳️)
- 2.22 - PALO: A Polyglot Large Multimodal Model for 5B People (), (), (?), (?), (?), (HTML), (✳️) , ()
- 2.22 - GeneOH Diffusion: Towards Generalizable Hand-Object Interaction Denoising via Denoising Diffusion (), (), ([:paperclip:](https://arxiv.org/pdf/2402.148


