YAYI UIE
1.0.0

[README] [?HF Repo] [?Webversion]
Chinesisch |. Englisch
[28.03.2024] Alle Modelle und Daten werden in die Magic Community hochgeladen.
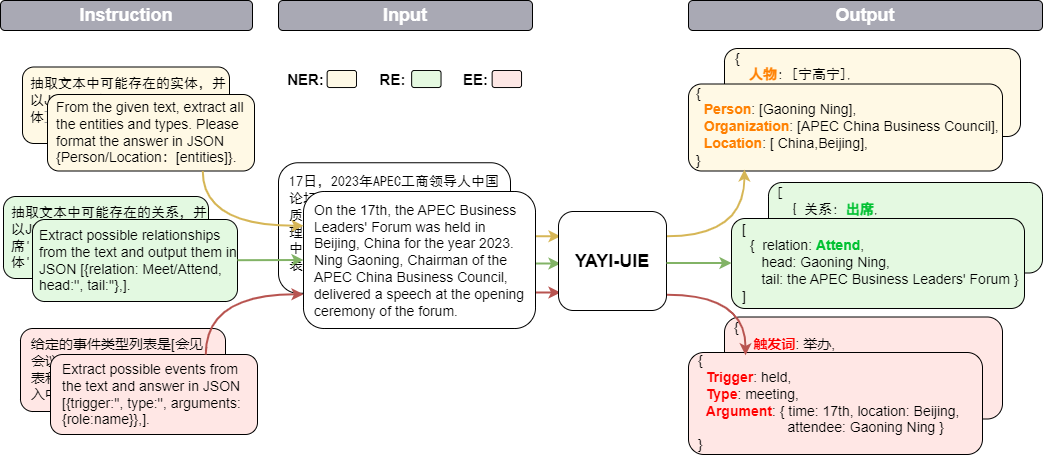
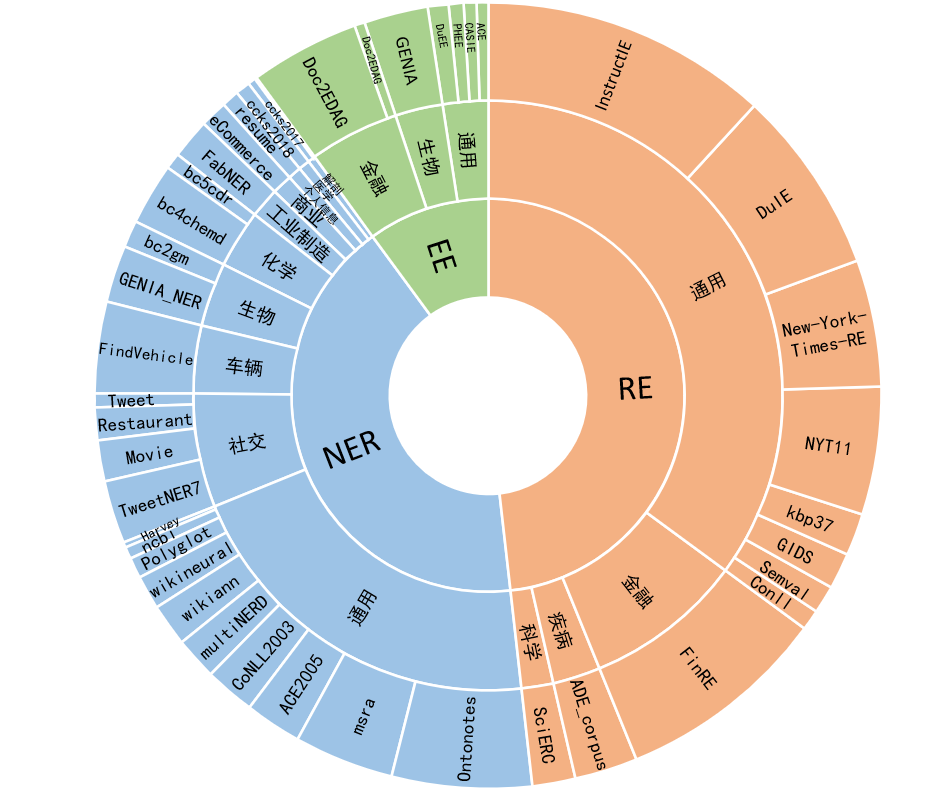
Das Yayi Information Extraction Unified Large Model (YAYI-UIE) optimiert Anweisungen für Millionen manuell erstellter, hochwertiger Informationsextraktionsdaten. Zu den einheitlichen Trainingsinformationsextraktionsaufgaben gehören benannte Entitätserkennung (NER), Beziehungsextraktion (RE) und Ereignisextraktion ( EE), um eine strukturierte Extraktion in allgemeinen, Sicherheits-, Finanz-, biologischen, medizinischen, kommerziellen, persönlichen, Fahrzeug-, Film-, Industrie-, Restaurant-, wissenschaftlichen und anderen Szenarien zu erreichen.
Durch die Open Source des Yayi UIE-Großmodells werden wir unsere eigenen Anstrengungen unternehmen, um die Entwicklung der vorab trainierten Großmodell-Open-Source-Community in China zu fördern. Durch Open Source werden wir mit jedem Partner das Yayi-Großmodell-Ökosystem aufbauen. Weitere technische Details finden Sie in unserem technischen Bericht YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction.
| Name | ? HF-Modellidentifikation | Adresse herunterladen | Magisches Modelllogo | Adresse herunterladen |
|---|---|---|---|---|
| YAYI-UIE | wenge-research/yayi-uie | Modell-Download | wenge-research/yayi-uie | Modell-Download |
| YAYI-UIE-Daten | wenge-research/yayi_uie_sft_data | Datensatz-Download | wenge-research/yayi_uie_sft_data | Datensatz-Download |
54 % des Millionenkorpus sind chinesisch und 46 % sind englisch; der Datensatz umfasst 12 Bereiche, darunter Finanzen, Gesellschaft, Biologie, Handel, industrielle Fertigung, Chemie, Fahrzeuge, Wissenschaft, Krankheit und medizinische Behandlung, Privatleben, Sicherheit und allgemein. Deckt Hunderte von Szenarien ab
git clone https://github.com/wenge-research/yayi-uie.git
cd yayi-uieconda create --name uie python=3.8
conda activate uiepip install -r requirements.txt Es wird nicht empfohlen, dass die Versionen torch und transformers niedriger sind als die empfohlenen Versionen.
Das Modell steht als Open Source in unserem Huggingface-Modell-Repository zur Verfügung und Sie können es gerne herunterladen und verwenden. Das Folgende ist ein Beispielcode, der einfach YAYI-UIE für die Downstream-Task-Inferenz aufruft. Er kann auf einer einzelnen GPU wie A100/A800 ausgeführt werden. Bei Verwendung der bf16-Präzisionsinferenz werden etwa 33 GB Videospeicher benötigt.
> >> import torch
> >> from transformers import AutoModelForCausalLM , AutoTokenizer
> >> from transformers . generation . utils import GenerationConfig
> >> tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi-uie" , use_fast = False , trust_remote_code = True )
> >> model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi-uie" , device_map = "auto" , torch_dtype = torch . bfloat16 , trust_remote_code = True )
> >> generation_config = GenerationConfig . from_pretrained ( "wenge-research/yayi-uie" )
> >> prompt = "文本:氧化锆陶瓷以其卓越的物理和化学特性在多个行业中发挥着关键作用。这种材料因其高强度、高硬度和优异的耐磨性,广泛应用于医疗器械、切削工具、磨具以及高端珠宝制品。在制造这种高性能陶瓷时,必须遵循严格的制造标准,以确保其最终性能。这些标准涵盖了从原材料选择到成品加工的全过程,保障产品的一致性和可靠性。氧化锆的制造过程通常包括粉末合成、成型、烧结和后处理等步骤。原材料通常是高纯度的氧化锆粉末,通过精确控制的烧结工艺,这些粉末被转化成具有特定微观结构的坚硬陶瓷。这种独特的微观结构赋予氧化锆陶瓷其显著的抗断裂韧性和耐腐蚀性。此外,氧化锆陶瓷的热膨胀系数与铁类似,使其在高温应用中展现出良好的热稳定性。因此,氧化锆陶瓷不仅在工业领域,也在日常生活中的应用日益增多,成为现代材料科学中的一个重要分支。 n抽取文本中可能存在的实体,并以json{制造品名称/制造过程/制造材料/工艺参数/应用/生物医学/工程特性:[实体]}格式输出。"
> >> # "<reserved_13>" is a reserved token for human, "<reserved_14>" is a reserved token for assistant
>> > prompt = "<reserved_13>" + prompt + "<reserved_14>"
> >> inputs = tokenizer ( prompt , return_tensors = "pt" ). to ( model . device )
> >> response = model . generate ( ** inputs , max_new_tokens = 512 , temperature = 0 )
> >> print ( tokenizer . decode ( response [ 0 ], skip_special_tokens = True ))Notiz:
文本:xx
【实体抽取】抽取文本中可能存在的实体,并以json{人物/机构/地点:[实体]}格式输出。
文本:xx
【关系抽取】已知关系列表是[注资,拥有,纠纷,自己,增持,重组,买资,签约,持股,交易]。根据关系列表抽取关系三元组,按照json[{'relation':'', 'head':'', 'tail':''}, ]的格式输出。
文本:xx
抽取文本中可能存在的关系,并以json[{'关系':'会见/出席', '头实体':'', '尾实体':''}, ]格式输出。
文本:xx
已知论元角色列表是[时间,地点,会见主体,会见对象],请根据论元角色列表从给定的输入中抽取可能的论元,以json{角色:论元}格式输出。
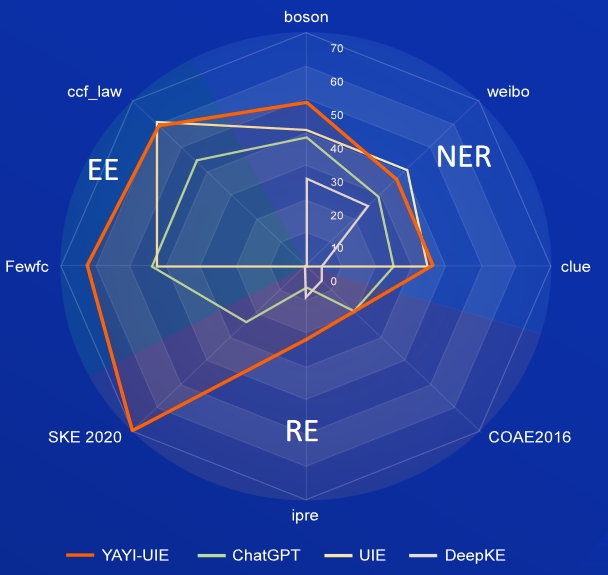
KI, Literatur, Musik, Politik und Wissenschaft sind englische Datensätze und Boson, Clue und Weibo sind chinesische Datensätze.
| Modell | KI | Literatur | Musik | Politik | Wissenschaft | Englischer Durchschnitt | Boson | Hinweis | Chinesischer Durchschnitt | |
|---|---|---|---|---|---|---|---|---|---|---|
| davinci | 2,97 | 9,87 | 13.83 | 18.42 | 10.04 | 11.03 | - | - | - | 31.09 |
| ChatGPT 3.5 | 54.4 | 54.07 | 61,24 | 59.12 | 63 | 58,37 | 38,53 | 25.44 | 29.3 | |
| UIE | 31.14 | 38,97 | 33,91 | 46,28 | 41,56 | 38,37 | 40,64 | 34,91 | 40,79 | 38,78 |
| USM | 28.18 | 56 | 44,93 | 36.1 | 44.09 | 41,86 | - | - | - | - |
| InstructUIE | 49 | 47.21 | 53.16 | 48.15 | 49.3 | 49,36 | - | - | - | - |
| KnowLM | 13.76 | 20.18 | 14.78 | 33,86 | 9.19 | 18.35 | 25.96 | 4.44 | 25.2 | 18.53 |
| YAYI-UIE | 52.4 | 45,99 | 51.2 | 51,82 | 50,53 | 50,39 | 49,25 | 36,46 | 36,78 | 40,83 |
FewRe, Wiki-ZSL sind englische Datensätze, SKE 2020, COAE2016, IPRE sind chinesische Datensätze
| Modell | WenigeRel | Wiki-ZSL | Englischer Durchschnitt | SKE 2020 | COAE2016 | IPRE | Chinesischer Durchschnitt |
|---|---|---|---|---|---|---|---|
| ChatGPT 3.5 | 9,96 | 13.14 | 11.55 24.47 | 19.31 | 6,73 | 16.84 | |
| ZETT(T5-klein) | 30.53 | 31.74 | 31.14 | - | - | - | - |
| ZETT (T5-Basis) | 33,71 | 31.17 | 32,44 | - | - | - | - |
| InstructUIE | 39,55 | 35.2 | 37,38 | - | - | - | - |
| KnowLM | 17.46 | 15.33 | 16.40 | 0,4 | 6.56 | 9,75 | 5.57 |
| YAYI-UIE | 36.09 | 41.07 | 38,58 | 70,8 | 19.97 | 22.97 | 37,91 |
Commodity News ist der englische Datensatz, FewFC, ccf_law ist der chinesische Datensatz
EET (Ereignistypidentifikation)
| Modell | Rohstoffnachrichten | WenigeFC | ccf_law | Chinesischer Durchschnitt |
|---|---|---|---|---|
| ChatGPT 3.5 | 1.41 | 16.15 | 0 | 8.08 |
| UIE | - | 50.23 | 2.16 | 26.20 |
| InstructUIE | 23.26 | - | - | - |
| YAYI-UIE | 12.45 | 81,28 | 12.87 | 47.08 |
EEA (Ereignisargumentextraktion)
| Modell | Rohstoffnachrichten | WenigeFC | ccf_law | Chinesischer Durchschnitt |
|---|---|---|---|---|
| ChatGPT 3.5 | 8.6 | 44.4 | 44,57 | 44,49 |
| UIE | - | 43.02 | 60,85 | 51,94 |
| InstructUIE | 21.78 | - | - | - |
| YAYI-UIE | 19.74 | 63.06 | 59,42 | 61,24 |
Das auf Basis aktueller Daten und Basismodelle trainierte SFT-Modell weist hinsichtlich der Wirksamkeit noch folgende Probleme auf:
Basierend auf den oben genannten Modellbeschränkungen verlangen wir von Entwicklern, dass sie unseren Open-Source-Code, unsere Daten, Modelle und Folgeableitungen, die von diesem Projekt generiert werden, nur für Forschungszwecke und nicht für kommerzielle Zwecke oder andere Zwecke verwenden, die der Gesellschaft Schaden zufügen. Bitte achten Sie darauf, die von Yayi Big Model generierten Inhalte zu identifizieren und zu verwenden und die generierten schädlichen Inhalte nicht im Internet zu verbreiten. Sollten nachteilige Folgen eintreten, trägt der Kommunikator die Verantwortung. Dieses Projekt darf nur zu Forschungszwecken verwendet werden und der Projektentwickler ist nicht verantwortlich für Schäden oder Verluste, die durch die Verwendung dieses Projekts entstehen (einschließlich, aber nicht beschränkt auf Daten, Modelle, Codes usw.). Einzelheiten entnehmen Sie bitte dem Haftungsausschluss.
Der Code und die Daten in diesem Projekt sind Open Source und entsprechen dem Apache-2.0-Protokoll. Wenn die Community das YAYI UIE Modell oder seine Derivate verwendet, befolgen Sie bitte die Community-Vereinbarung und die kommerzielle Vereinbarung von Baichuan2.
Wenn Sie unser Modell in Ihrer Arbeit verwenden, können Sie unseren Artikel zitieren:
@article{YAYI-UIE,
author = {Xinglin Xiao, Yijie Wang, Nan Xu, Yuqi Wang, Hanxuan Yang, Minzheng Wang, Yin Luo, Lei Wang, Wenji Mao, Dajun Zeng}},
title = {YAYI-UIE: A Chat-Enhanced Instruction Tuning Framework for Universal Information Extraction},
journal = {arXiv preprint arXiv:2312.15548},
url = {https://arxiv.org/abs/2312.15548},
year = {2023}
}


