Dropout NeuralNetworks
1.0.0
In diesem Forschungsprojekt werde ich mich auf die Auswirkungen sich ändernder Abbrecherquoten auf den MNIST-Datensatz konzentrieren. Mein Ziel ist es, die folgende Abbildung mit den in der Forschungsarbeit verwendeten Daten zu reproduzieren. Der Zweck dieses Projekts besteht darin, zu erfahren, wie die Figur des maschinellen Lernens hergestellt wurde. Insbesondere geht es um das Erlernen der Auswirkungen auf Klassifizierungsfehler, wenn die Abbruchwahrscheinlichkeit geändert/nicht geändert wird.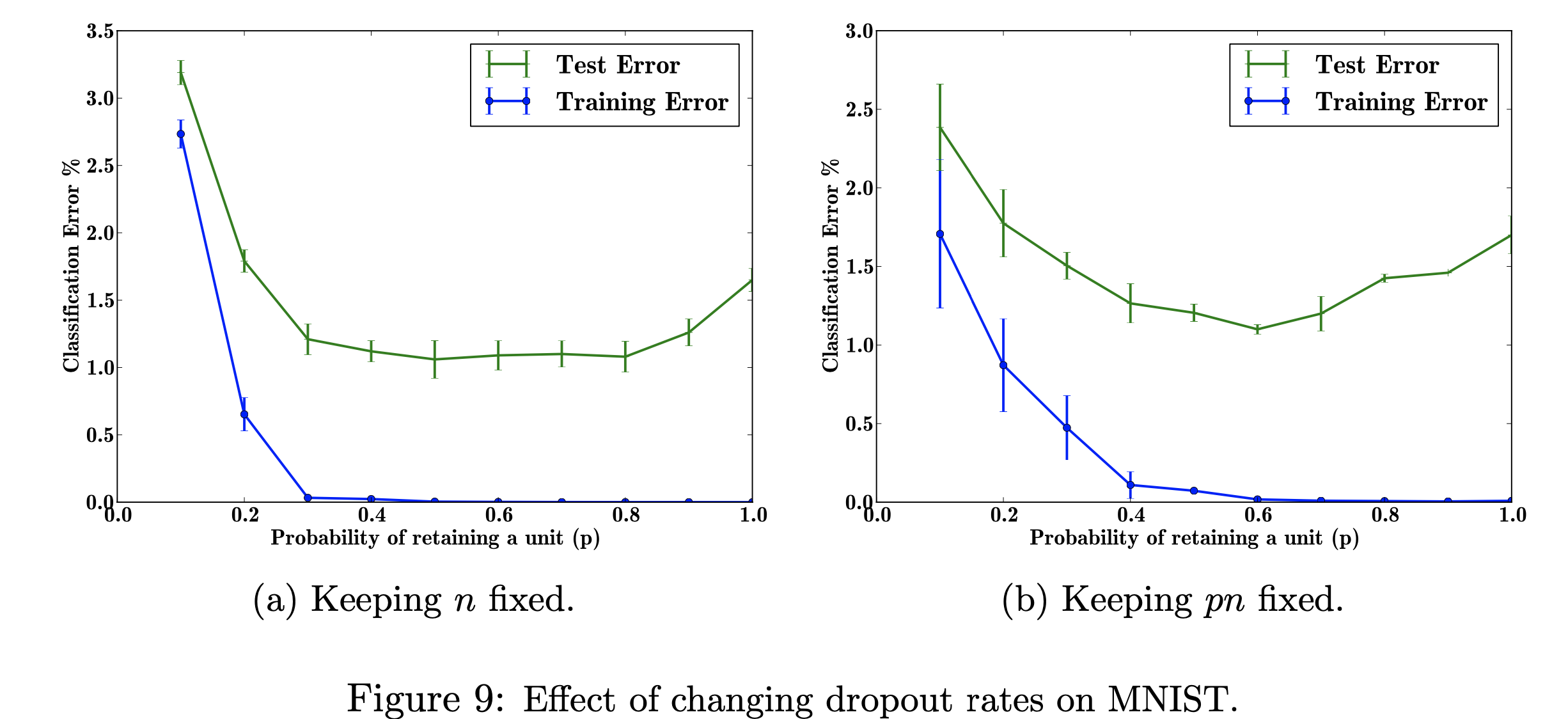 Abbildung zitiert aus: Srivastava, N., Hinton, G., Krizhevsky, A., Krizhevsky, I., Salakhutdinov, R., Dropout: A Simple Way to Prevent Neural Networks from Overfitting, Abbildung 9
Abbildung zitiert aus: Srivastava, N., Hinton, G., Krizhevsky, A., Krizhevsky, I., Salakhutdinov, R., Dropout: A Simple Way to Prevent Neural Networks from Overfitting, Abbildung 9
Ich habe TensorFlow verwendet, um Dropout für den MNIST-Datensatz auszuführen, und Matplotlib, um die Abbildung in der Arbeit neu zu erstellen. Ich habe auch eine integrierte Dezimalbibliothek verwendet, um die verschiedenen Werte von p von 0,0 bis 1,0 zu berechnen. Die Bibliothek „csv“ wurde importiert, um zuvor ausgeführte Daten in eine CSV-Datei hinzuzufügen, um Zeit bei der Berechnung bereits berechneter Werte von p zu sparen. Numpy wurde importiert, damit die Darstellung auf der x- und y-Achse die gleiche Schrittweite hat. Zuletzt habe ich „os“ importiert, damit ich einen Fehler beseitigen konnte, der durch die Verwendung einer CPU statt einer GPU verursacht wurde.
Untersuchung der Auswirkungen variierender Werte des einstellbaren Hyperparameters „p“ (die Wahrscheinlichkeit, eine Einheit im Netzwerk zu behalten) und der Anzahl verborgener Schichten „n“, die sich auf die Fehlerraten auswirken. Wenn das Produkt von p und n festgelegt ist, können wir sehen, dass sich die Fehlergröße für kleine Werte von p verringert hat (Abb. 9a), verglichen mit einer konstanten Anzahl verborgener Schichten (Abb. 9b).
Bei begrenzten Trainingsdaten sind viele komplizierte Beziehungen zwischen Ein- und Ausgängen auf das Abtastrauschen zurückzuführen. Sie sind im Trainingssatz vorhanden, jedoch nicht in echten Testdaten, selbst wenn diese aus derselben Verteilung stammen. Diese Komplikation führt zu einer Überanpassung. Dies ist einer der Algorithmen, die dazu beitragen, dies zu verhindern. Die Eingabe für diese Abbildung ist ein Datensatz handgeschriebener Ziffern, und die Ausgabe nach dem Hinzufügen von Dropout sind verschiedene Werte, die das Ergebnis der Anwendung der Dropout-Methode beschreiben. Alles in allem führt das Hinzufügen von Dropout zu weniger Fehlern.
Ein reales Problem, auf das dies zutreffen kann, ist die Google-Suche. Jemand sucht möglicherweise nach einem Filmtitel, sucht aber möglicherweise nur nach Bildern, weil er eher visuell lernt. Wenn Sie also Textteile weglassen oder kurze Erläuterungen geben, können Sie sich auf die Bildmerkmale konzentrieren. Der Artikel gibt an, woher sie die Daten abrufen (http://yann.lecun.com/exdb/mnist/). Jedes Bild ist eine 28x28-stellige Darstellung. Die Y-Beschriftungen scheinen die Bilddatenspalten zu sein.
Mein Ziel bei der Reproduktion dieser Zahl besteht darin, die Daten zu testen/zu trainieren und den Klassifizierungsfehler für jede Wahrscheinlichkeit von p (Wahrscheinlichkeit, eine Einheit im Netzwerk zu behalten) zu berechnen. Mein Ziel ist es, p mit abnehmendem Fehler zu erhöhen, um zu zeigen, dass meine Implementierung gültig ist, und ich werde diesen Hyperparameter optimieren, um das gleiche Ergebnis zu erzielen. Ich werde dies tun, indem ich alle Trainings- und Testdaten mithilfe einer 784-2048-2048-2048-10-Architektur durchlaufe und n fest lasse und dann pn so ändere, dass es behoben wird. Ich werde die Daten dann in eine CSV-Datei sammeln/schreiben. Diese csv-Datei enthält dann alle notwendigen Daten zur Ausgabe der Zahlen. In diesem Projekt werde ich lernen, wie sich die Abbrecherquote auf den Gesamtfehler in einem neuronalen Netzwerk auswirken kann.
Klicken Sie zum Anzeigen


