Stable Diffusion wurde durch eine Zusammenarbeit mit Stability AI und Runway ermöglicht und baut auf unserer früheren Arbeit auf:
Hochauflösende Bildsynthese mit latenten Diffusionsmodellen
Robin Rombach*, Andreas Blattmann*, Dominik Lorenz, Patrick Esser, Björn Ommer
CVPR '22 Mündlich | GitHub | arXiv | Projektseite
 Stable Diffusion ist ein latentes Text-zu-Bild-Diffusionsmodell. Dank einer großzügigen Rechenspende von Stability AI und der Unterstützung von LAION konnten wir ein Latent Diffusion Model auf 512x512-Bildern aus einer Teilmenge der LAION-5B-Datenbank trainieren. Ähnlich wie Googles Imagen verwendet dieses Modell einen eingefrorenen CLIP ViT-L/14-Textencoder, um das Modell auf Textaufforderungen vorzubereiten. Mit seinem 860M-UNet- und 123M-Text-Encoder ist das Modell relativ leichtgewichtig und läuft auf einer GPU mit mindestens 10GB VRAM. Siehe diesen Abschnitt unten und die Modellkarte.
Stable Diffusion ist ein latentes Text-zu-Bild-Diffusionsmodell. Dank einer großzügigen Rechenspende von Stability AI und der Unterstützung von LAION konnten wir ein Latent Diffusion Model auf 512x512-Bildern aus einer Teilmenge der LAION-5B-Datenbank trainieren. Ähnlich wie Googles Imagen verwendet dieses Modell einen eingefrorenen CLIP ViT-L/14-Textencoder, um das Modell auf Textaufforderungen vorzubereiten. Mit seinem 860M-UNet- und 123M-Text-Encoder ist das Modell relativ leichtgewichtig und läuft auf einer GPU mit mindestens 10GB VRAM. Siehe diesen Abschnitt unten und die Modellkarte.
Eine geeignete Conda-Umgebung namens ldm kann erstellt und aktiviert werden mit:
conda env create -f environment.yaml
conda activate ldm
Sie können eine vorhandene latente Diffusionsumgebung auch durch Ausführen aktualisieren
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2 diffusers invisible-watermark
pip install -e .
Stable Diffusion v1 bezieht sich auf eine spezifische Konfiguration der Modellarchitektur, die einen Downsampling-Faktor 8-Autoencoder mit einem 860M UNet und CLIP ViT-L/14-Textencoder für das Diffusionsmodell verwendet. Das Modell wurde auf 256x256-Bildern vorab trainiert und dann auf 512x512-Bildern verfeinert.
Hinweis: Stable Diffusion v1 ist ein allgemeines Text-zu-Bild-Diffusionsmodell und spiegelt daher Vorurteile und (Fehl-)Vorstellungen wider, die in seinen Trainingsdaten vorhanden sind. Einzelheiten zum Trainingsablauf und den Trainingsdaten sowie zum Verwendungszweck des Modells finden Sie in der entsprechenden Modellkarte.
Die Gewichte sind über die CompVis-Organisation bei Hugging Face im Rahmen einer Lizenz erhältlich, die spezifische nutzungsbasierte Einschränkungen enthält, um Missbrauch und Schäden gemäß den Angaben in der Modellkarte zu verhindern, ansonsten aber freizügig bleibt. Während die kommerzielle Nutzung gemäß den Lizenzbedingungen zulässig ist, empfehlen wir nicht, die bereitgestellten Gewichte für Dienstleistungen oder Produkte ohne zusätzliche Sicherheitsmechanismen und Überlegungen zu verwenden , da es bekannte Einschränkungen und Vorurteile der Gewichte gibt und Untersuchungen zum sicheren und ethischen Einsatz von Gewichten vorliegen Die Entwicklung allgemeiner Text-zu-Bild-Modelle ist eine fortlaufende Anstrengung. Die Gewichte sind Forschungsartefakte und sollten als solche behandelt werden.
Die CreativeML OpenRAIL M-Lizenz ist eine Open RAIL M-Lizenz, die auf der Arbeit basiert, die BigScience und die RAIL Initiative gemeinsam im Bereich der verantwortungsvollen KI-Lizenzierung durchführen. Siehe auch den Artikel über die BLOOM Open RAIL-Lizenz, auf der unsere Lizenz basiert.
Derzeit bieten wir folgende Kontrollpunkte an:
sd-v1-1.ckpt : 237.000 Schritte bei einer Auflösung 256x256 auf laion2B-en. 194.000 Schritte bei einer Auflösung von 512x512 auf Laion-High-Resolution (170 Millionen Beispiele von LAION-5B mit einer Auflösung >= 1024x1024 ).sd-v1-2.ckpt : Fortgesetzt von sd-v1-1.ckpt . 515.000 Schritte bei einer Auflösung von 512x512 auf laion-aesthetics v2 5+ (eine Teilmenge von laion2B-en mit einem geschätzten Ästhetikwert > 5.0 und zusätzlich gefiltert nach Bildern mit einer Originalgröße >= 512x512 und einer geschätzten Wasserzeichenwahrscheinlichkeit < 0.5 . Die Wasserzeichenschätzung stammt aus den LAION-5B-Metadaten, der Ästhetik-Score wird mithilfe von LAION-Aesthetics geschätzt Prädiktor V2).sd-v1-3.ckpt : Fortgesetzt von sd-v1-2.ckpt . 195.000 Schritte bei einer Auflösung von 512x512 auf „laion-aesthetics v2 5+“ und 10 % Reduzierung der Textkonditionierung zur Verbesserung der klassifikatorfreien Führungsstichprobe.sd-v1-4.ckpt : Fortgesetzt von sd-v1-2.ckpt . 225.000 Schritte bei einer Auflösung von 512x512 auf „laion-aesthetics v2 5+“ und 10 % Reduzierung der Textkonditionierung zur Verbesserung der klassifikatorfreien Führungsstichprobe. Auswertungen mit unterschiedlichen klassifikatorfreien Leitskalen (1,5, 2,0, 3,0, 4,0, 5,0, 6,0, 7,0, 8,0) und 50 PLMS-Stichprobenschritten zeigen die relativen Verbesserungen der Kontrollpunkte: 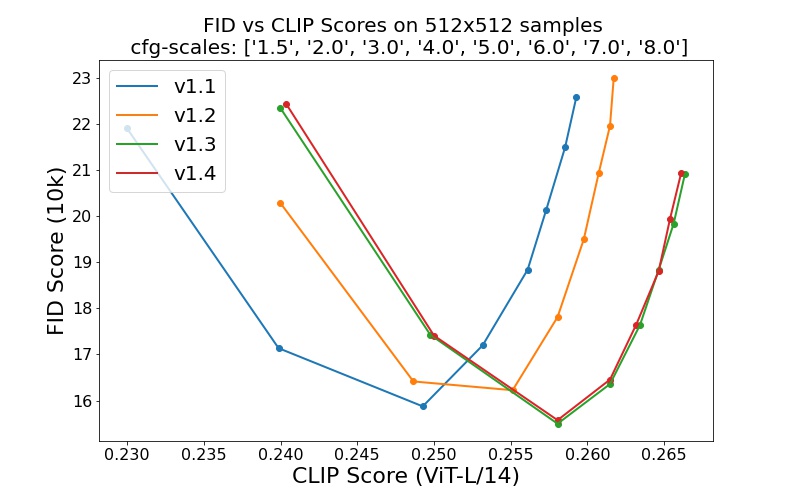


Stable Diffusion ist ein latentes Diffusionsmodell, das auf den (nicht gepoolten) Texteinbettungen eines CLIP ViT-L/14-Textencoders basiert. Wir stellen ein Referenzskript zum Sampling zur Verfügung, es gibt aber auch eine Diffusor-Integration, von der wir eine aktivere Community-Entwicklung erwarten.
Wir stellen ein Referenz-Sampling-Skript zur Verfügung, das Folgendes beinhaltet
Nachdem Sie die stable-diffusion-v1-*-original erhalten haben, verknüpfen Sie sie
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
und Probe mit
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
Standardmäßig verwendet dies eine Orientierungsskala von --scale 7.5 , Katherine Crowsons Implementierung des PLMS-Samplers, und rendert Bilder der Größe 512 x 512 (auf der trainiert wurde) in 50 Schritten. Alle unterstützten Argumente sind unten aufgeführt (geben Sie python scripts/txt2img.py --help ein).
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
Hinweis: Die Inferenzkonfiguration für alle v1-Versionen ist für die Verwendung mit reinen EMA-Prüfpunkten konzipiert. Aus diesem Grund ist in der Konfiguration use_ema=False gesetzt, andernfalls versucht der Code, von Nicht-EMA-Gewichten auf EMA-Gewichte umzustellen. Wenn Sie die Wirkung von EMA im Vergleich zu keinem EMA untersuchen möchten, stellen wir „vollständige“ Prüfpunkte bereit, die beide Arten von Gewichtungen enthalten. Für diese werden use_ema=False die Nicht-EMA-Gewichte geladen und verwendet.
Eine einfache Möglichkeit, Stable Diffusion herunterzuladen und auszuprobieren, ist die Verwendung der Diffusoren-Bibliothek:
# make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline . from_pretrained (
"CompVis/stable-diffusion-v1-4" ,
use_auth_token = True
). to ( "cuda" )
prompt = "a photo of an astronaut riding a horse on mars"
with autocast ( "cuda" ):
image = pipe ( prompt )[ "sample" ][ 0 ]
image . save ( "astronaut_rides_horse.png" )Durch die Verwendung eines Diffusions-Entrauschungsmechanismus, wie er erstmals von SDEdit vorgeschlagen wurde, kann das Modell für verschiedene Aufgaben wie textgesteuerte Bild-zu-Bild-Übersetzung und Hochskalierung verwendet werden. Ähnlich wie das txt2img-Sampling-Skript stellen wir ein Skript zur Verfügung, um Bildmodifikationen mit Stable Diffusion durchzuführen.
Im Folgenden wird ein Beispiel beschrieben, bei dem eine in Pinta erstellte grobe Skizze in ein detailliertes Kunstwerk umgewandelt wird.
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
Hier ist die Stärke ein Wert zwischen 0,0 und 1,0, der die Menge an Rauschen steuert, die dem Eingabebild hinzugefügt wird. Werte, die sich 1,0 nähern, ermöglichen viele Variationen, erzeugen aber auch Bilder, die semantisch nicht mit der Eingabe übereinstimmen. Siehe das folgende Beispiel.
Eingang

Ausgänge


Mit diesem Verfahren können beispielsweise auch Stichproben aus dem Basismodell hochskaliert werden.
Unsere Codebasis für die Diffusionsmodelle basiert stark auf der ADM-Codebasis von OpenAI und https://github.com/lucidrains/denoising-diffusion-pytorch. Vielen Dank für Open-Sourcing!
Die Implementierung des Transformer-Encoders stammt von x-transformers von lucidrains.
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


