ACM MM'18 Beste Studentenarbeit
Das Multi-Human-Parsing-Projekt der Learning and Vision (LV) Group der National University of Singapore (NUS) soll die Grenzen des feinkörnigen visuellen Verständnisses von Menschen in Menschenmengen erweitern.
Multi-Human-Parsing unterscheidet sich erheblich von herkömmlichen, wohldefinierten Objekterkennungsaufgaben, wie z. B. der Objekterkennung, die nur grobe Vorhersagen von Objektpositionen (Begrenzungsrahmen) liefert; Instanzsegmentierung, die nur die Maske auf Instanzebene vorhersagt, ohne detaillierte Informationen zu Körperteilen und Modekategorien; menschliches Parsing, das auf der pixelweisen Vorhersage auf Kategorieebene basiert, ohne unterschiedliche Identitäten zu unterscheiden.
In einem realen Szenario sind die Interaktionen mehrerer Personen realistischer und üblicher. Daher sind eine Aufgabe, entsprechende Datensätze und Basismethoden zur Berücksichtigung sowohl der feinkörnigen semantischen Informationen jeder einzelnen Person als auch der Beziehungen und Interaktionen der gesamten Personengruppe äußerst wünschenswert.
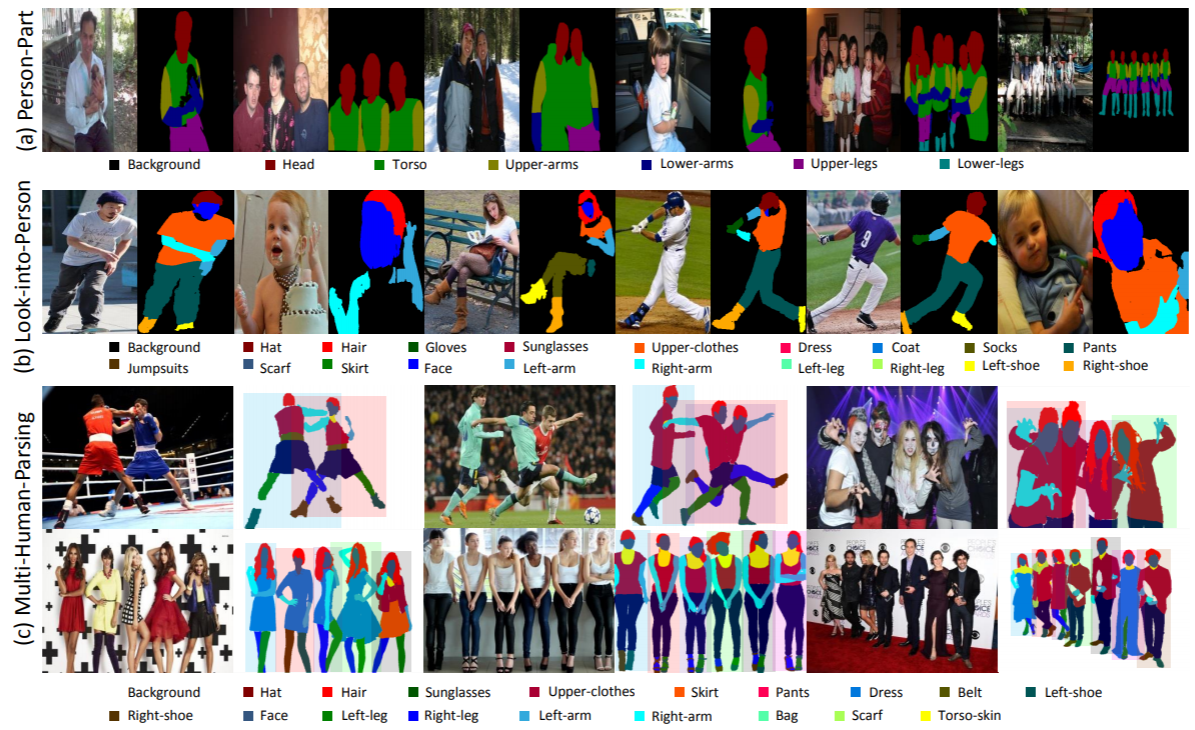
Statistik: Der MHP v1.0-Datensatz enthält 4.980 Bilder mit jeweils mindestens zwei Personen (Durchschnitt liegt bei 3). Wir wählen zufällig 980 Bilder und die entsprechenden Anmerkungen als Testsatz aus. Der Rest besteht aus einem Trainingssatz aus 3.000 Bildern und einem Validierungssatz aus 1.000 Bildern. Für jede Instanz werden 18 semantische Kategorien definiert und mit Anmerkungen versehen, mit Ausnahme der Kategorie „Hintergrund“, also „Hut“, „Haar“, „Sonnenbrille“, „Oberbekleidung“, „Rock“, „Hose“, „Kleid“, „ Gürtel“, „linker Schuh“, „rechter Schuh“, „Gesicht“, „linkes Bein“, „rechtes Bein“, „linker Arm“, „rechter Arm“, „Tasche“, „Schal“ und „Rumpfhaut“. Jede Instanz verfügt über einen vollständigen Satz von Anmerkungen, wann immer die entsprechende Kategorie im aktuellen Bild erscheint.
WeChat-Nachrichten.
Download: Der MHP v1.0-Datensatz ist auf Google Drive und Baidu Drive verfügbar (Passwort: cmtp).
Weitere Informationen finden Sie in unserem MHP v1.0-Papier (eingereicht beim IJCV).

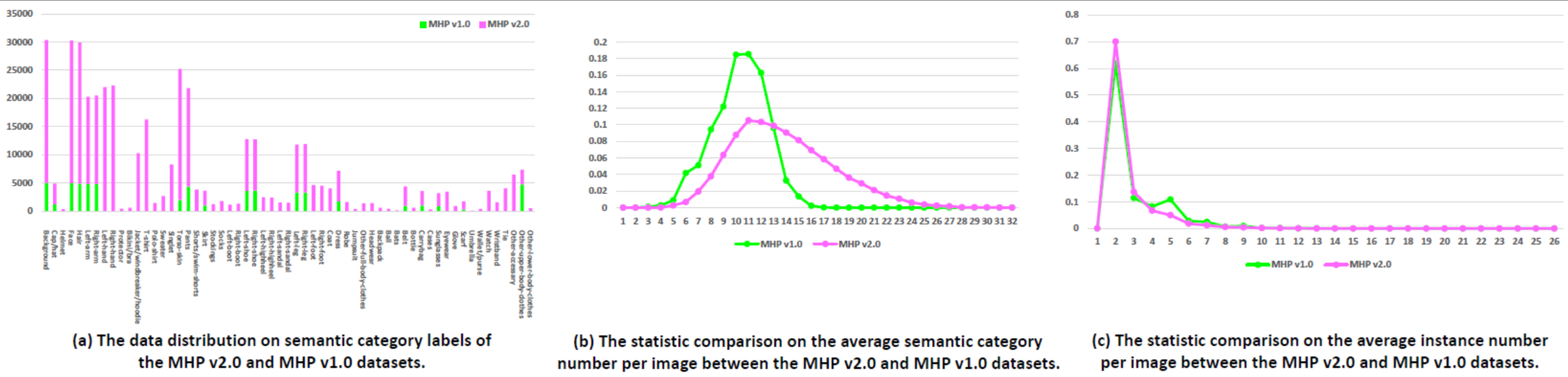

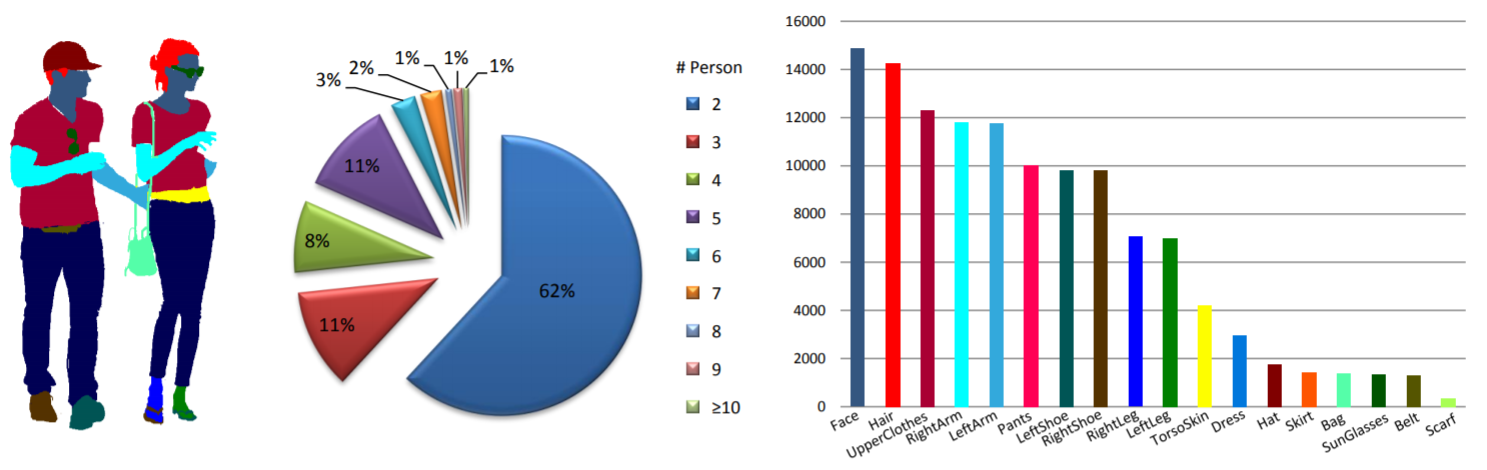
Statistik: Der MHP v2.0-Datensatz enthält 25.403 Bilder mit jeweils mindestens zwei Personen (der Durchschnitt liegt bei 3). Wir wählen zufällig 5.000 Bilder und die entsprechenden Anmerkungen als Testsatz aus. Der Rest besteht aus einem Trainingssatz aus 15.403 Bildern und einem Validierungssatz aus 5.000 Bildern. Für jede Instanz werden 58 semantische Kategorien definiert und mit Anmerkungen versehen, mit Ausnahme der Kategorie „Hintergrund“, also „Mütze/Hut“, „Helm“, „Gesicht“, „Haar“, „linker Arm“, „rechter Arm“. „Linkshänder“, „Rechtshänder“, „Protektor“, „Bikini/BH“, „Jacke/Windjacke/Hoodie“, „T-Shirt“, „Poloshirt“, „Pullover“, „Singlet“, „Rumpfhaut“, „Hose“, „Shorts/Badeshorts“, „Rock“, „Strümpfe“, „Socken“, „linker Stiefel“, „rechter Stiefel“, „linker Schuh“, „rechter Schuh“, „linker Highheel“, „rechter Highheel“, „linke Sandale“, „rechte Sandale“, „linkes Bein“, „rechtes Bein“, „linker Fuß“, „rechter Fuß“, „Mantel“, „Kleid“, „Robe“, „Overall“, „Andere Ganzkörperkleidung“, „Kopfbedeckung“, „Rucksack“, „Ball“, „Schläger“, „Gürtel“, „Flasche“, „Tragetasche“, „Etuis“, „Sonnenbrille“, „Brillen“, „Handschuh“, „Schal“, „Regenschirm“, „Brieftasche/Geldbörse“, „Uhr“, „Armband“, „Krawatte“, „anderes Accessoire“, „andere Kleidung für den Oberkörper“ und „andere Unterkörperkleidung“. -Körperkleidung". Jede Instanz verfügt über einen vollständigen Satz von Anmerkungen, wann immer die entsprechende Kategorie im aktuellen Bild erscheint. Darüber hinaus sind 2D-menschliche Posen mit 16 dichten Schlüsselpunkten („rechte Schulter“, „rechter Ellenbogen“, „rechtes Handgelenk“, „linke Schulter“, „linker Ellenbogen“, „linkes Handgelenk“, „rechts- Hüfte“, „rechtes Knie“, „rechter Knöchel“, „linke Hüfte“, „linkes Knie“, „linker Knöchel“, „Kopf“, „Hals“, „Wirbelsäule“ und „Becken“. Der Schlüsselpunkt verfügt über eine Markierung, die angibt, ob dies der Fall ist sichtbar-0/verdeckt-1/außerhalb des Bildes-2) und Kopf- und Instanz-Begrenzungsrahmen werden ebenfalls bereitgestellt, um die Forschung zur Multi-Human-Pose-Schätzung zu erleichtern.
Download: Der MHP v2.0-Datensatz ist auf Google Drive und Baidu Drive verfügbar (Passwort: uxrb).
Weitere Informationen finden Sie in unserem MHP v2.0-Papier (ACM MM'18 Best Student Paper).
Multi-Human-Parsing: Wir verwenden zwei menschenzentrierte Metriken für die Multi-Human-Parsing-Bewertung, die ursprünglich in unserem MHP v1.0-Artikel beschrieben werden. Die beiden Metriken sind die durchschnittliche Präzision basierend auf dem Teil (AP p ) (%) und der Prozentsatz der korrekt analysierten semantischen Teile (PCP) (%). Den Evaluierungscode finden Sie im Ordner „Evaluation“ in unserem Repository „Multi-Human-Parsing_MHP“.
Schätzung der Haltung mehrerer Menschen: In Anlehnung an MPII verwenden wir das Bewertungsmaß mAP (%).
Wir haben den CVPR 2018 Workshop zum visuellen Verständnis von Menschen in Menschenmengen (VUHCS 2018) organisiert. Dieser Workshop wird von NUS, CMU und SYSU gemeinsam durchgeführt. Basierend auf VUHCS 2017 haben wir diesen Workshop weiter gestärkt, indem wir ihn um fünf Wettbewerbsstrecken erweitert haben: die Einzelpersonen-Menschenanalyse, die Mehrpersonen-Menschenanalyse, die Einzelpersonen-Posenschätzung, die Mehrpersonen-Posenschätzung und die Feinanalyse. Körniges Multi-Mensch-Parsing.
Ergebnisübermittlung und Bestenliste.
WeChat-Nachrichten.
Bitte konsultieren Sie die folgenden Dokumente und ziehen Sie in Betracht, sie zu zitieren:
@article{zhao2018understanding,
title={Understanding Humans in Crowded Scenes: Deep Nested Adversarial Learning and A New Benchmark for Multi-Human Parsing},
author={Zhao, Jian and Li, Jianshu and Cheng, Yu and Zhou, Li and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1804.03287},
year={2018}
}
@article{li2017towards,
title={Multi-Human Parsing in the Wild},
author={Li, Jianshu and Zhao, Jian and Wei, Yunchao and Lang, Congyan and Li, Yidong and Sim, Terence and Yan, Shuicheng and Feng, Jiashi},
journal={arXiv preprint arXiv:1705.07206},
year={2017}
}


