Image to text chrome extension
1.0.0
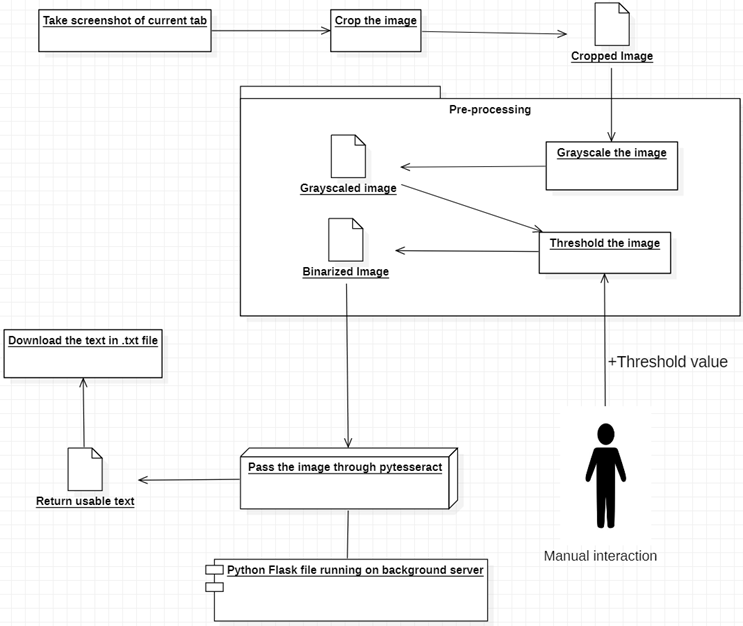
Eine Chrome-Erweiterung, die mithilfe des OCR-Konzepts jede Art von Text in Ihrem Browser aus jedem Video oder Bild erkennen kann. OCR ist die Kurzform von Optical Character Recognition oder anders ausgedrückt: Texterkennung in Bildern. Google hatte zuvor eine Engine namens Tesseract OCR veröffentlicht. Das bedeutet, dass Google Ihnen ein Programm zur Verfügung stellt, in das die Texterkennung bereits eingearbeitet ist, sodass ich komplizierte Dinge wie das Einlernen der Daten in OCR nicht selbst durchführen muss. Um jedoch genauer zu sein, müssen wir das Bild vorverarbeiten, bevor wir es durch Tesseract weiterleiten, da Tesseract einige vordefinierte Umstände hat, die befolgt werden müssen, um ein genaues Ergebnis zu erhalten. Um die Funktionalität unserer Erweiterung zu gewährleisten, erstellt sie zunächst einen Screenshot des aktuell geöffneten Tabs, schneidet dann den gewünschten Teil mithilfe von Canvas zu und passt ihn mithilfe der Schwellenwertbinarisierung an, sodass die OCR-Anforderungen erfüllt werden können, um genauere Ergebnisse zu liefern. Senden Sie es dann an pytesseract (Python-Version von Tesseract), damit es es konvertieren kann. Holen Sie sich am Ende den Text und laden Sie ihn im TXT-Dateiformat herunter. Der Benutzer kann es also im Editor oder einem anderen Texteditor öffnen und den Text bei Bedarf vergleichen und ändern.
Auf YouTube oder anderen Websites stoße ich sehr häufig auf Codeschnipsel. Mittlerweile schätze ich den Aufwand, den die Tutorial-Ersteller in ihre Videos stecken, jedes Mal sehr, wenn ich auf einen Code stoße, der keinen Link zum Herunterladen oder Kopieren bereitstellt. Um Codes aus diesen Videos zu erhalten, habe ich dieses Projekt mit Hilfe des Tesseract-Plugins erstellt, damit ich Text aus diesen Videos oder Bildern extrahieren kann.
Die Modulimplementierung und Demo finden Sie im ppt.
pip install pytesseract
npm i flask
Die jQuery-Min-Datei ist den Dateien beigefügt, falls Sie sie ändern oder den CDN-Ansatz verwenden möchten, können Sie sie ändern.


