Scraping Dynamic JavaScript Ajax Websites With BeautifulSoup
1.0.0

JavaScript rendern?BrowserDas Web Scraping der meisten Websites kann vergleichsweise einfach sein. Dieses Thema wird in diesem Tutorial bereits ausführlich behandelt. Es gibt jedoch viele Websites, die nicht mit der gleichen Methode gescrapt werden können. Der Grund dafür ist, dass diese Websites den Inhalt dynamisch mithilfe von JavaScript laden.
Diese Technik ist auch als AJAX (Asynchronous JavaScript and XML) bekannt. In der Vergangenheit war dieser Standard darin enthalten, ein XMLHttpRequest Objekt zu erstellen, um XML von einem Webserver abzurufen, ohne die gesamte Seite neu zu laden. Heutzutage wird dieses Objekt nur noch selten direkt verwendet. Normalerweise wird ein Wrapper wie jQuery verwendet, um Inhalte wie JSON, teilweises HTML oder sogar Bilder abzurufen.
Zum Scrapen einer regulären Webseite sind mindestens zwei Bibliotheken erforderlich. Die requests lädt die Seite herunter. Sobald diese Seite als HTML-String verfügbar ist, besteht der nächste Schritt darin, sie als BeautifulSoup-Objekt zu analysieren. Dieses BeautifulSoup-Objekt kann dann verwendet werden, um bestimmte Daten zu finden.
Hier ist ein einfaches Beispielskript, das den Text innerhalb des h1 Elements druckt, wobei id auf firstHeading gesetzt ist.
import requests
from bs4 import BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## OUTPUT
# Albert EinsteinBeachten Sie, dass wir mit Version 4 der Beautiful Soup-Bibliothek arbeiten. Frühere Versionen werden nicht mehr unterstützt. Möglicherweise sehen Sie, dass „Beautiful Soup 4“ einfach als „Beautiful Soup“, „BeautifulSoup“ oder sogar „BS4“ geschrieben wird. Sie beziehen sich alle auf dieselbe schöne Suppen-4-Bibliothek.
Derselbe Code funktioniert nicht, wenn die Site dynamisch ist. Beispielsweise gibt es für dieselbe Website eine dynamische Version unter https://quotes.toscrape.com/js/ (beachten Sie js am Ende dieser URL).
response = requests . get ( "https://quotes.toscrape.com/js" ) # dynamic web page
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## No output Der Grund dafür ist, dass die zweite Site dynamisch ist und die Daten mithilfe von JavaScript generiert werden.
Es gibt zwei Möglichkeiten, mit solchen Websites umzugehen.
Diese beiden Ansätze werden in diesem Tutorial ausführlich behandelt.
Zunächst müssen wir jedoch verstehen, wie wir feststellen können, ob eine Site dynamisch ist.
Hier ist der einfachste Weg, mit Chrome oder Edge festzustellen, ob eine Website dynamisch ist. (Beide Browser nutzen unter der Haube Chromium).
Öffnen Sie die Entwicklertools, indem Sie die Taste F12 drücken. Stellen Sie sicher, dass der Fokus auf den Entwicklertools liegt, und drücken Sie die Tastenkombination CTRL+SHIFT+P um das Befehlsmenü zu öffnen.
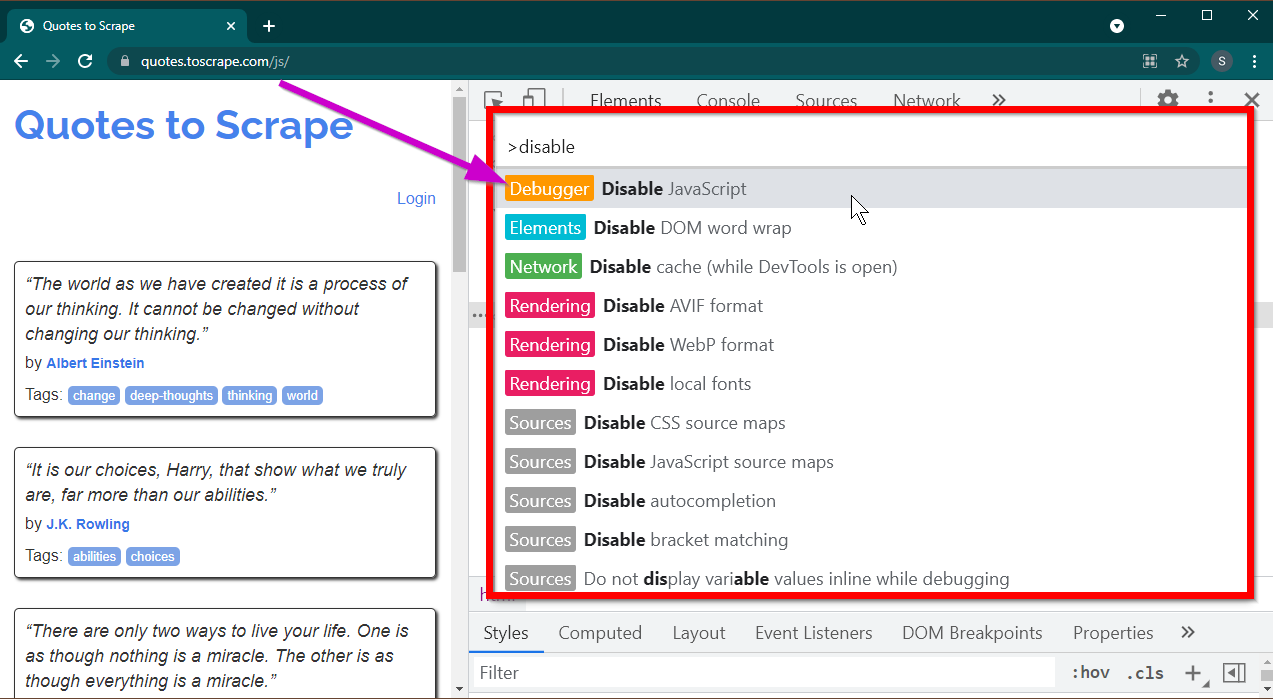
Es werden viele Befehle angezeigt. Beginnen Sie mit der Eingabe von disable und die Befehle werden gefiltert, um Disable JavaScript anzuzeigen. Wählen Sie diese Option, um JavaScript zu deaktivieren.
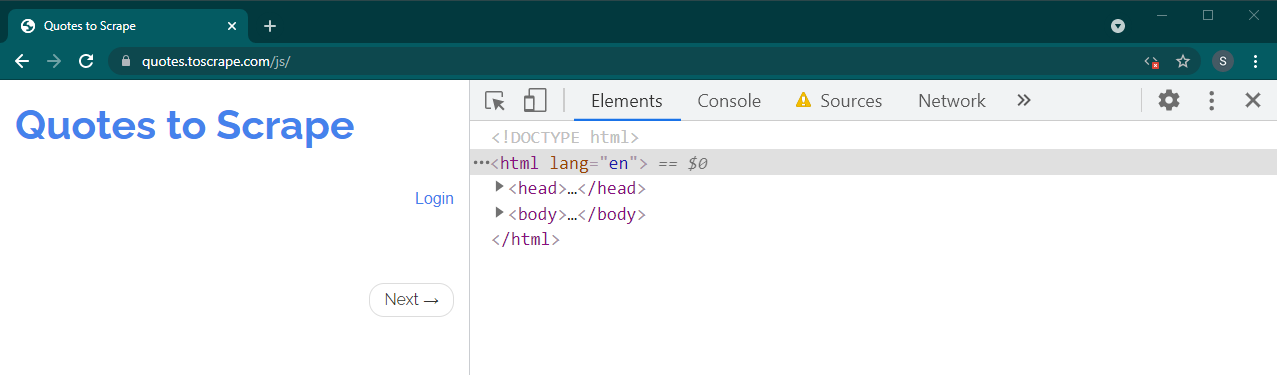
Laden Sie nun diese Seite neu, indem Sie Ctrl+R oder F5 drücken. Die Seite wird neu geladen.
Wenn es sich um eine dynamische Website handelt, verschwinden viele Inhalte:
In einigen Fällen werden die Daten auf den Websites weiterhin angezeigt, es wird jedoch auf die Grundfunktionalität zurückgegriffen. Diese Site verfügt beispielsweise über eine unendliche Schriftrolle. Wenn JavaScript deaktiviert ist, wird eine normale Paginierung angezeigt.
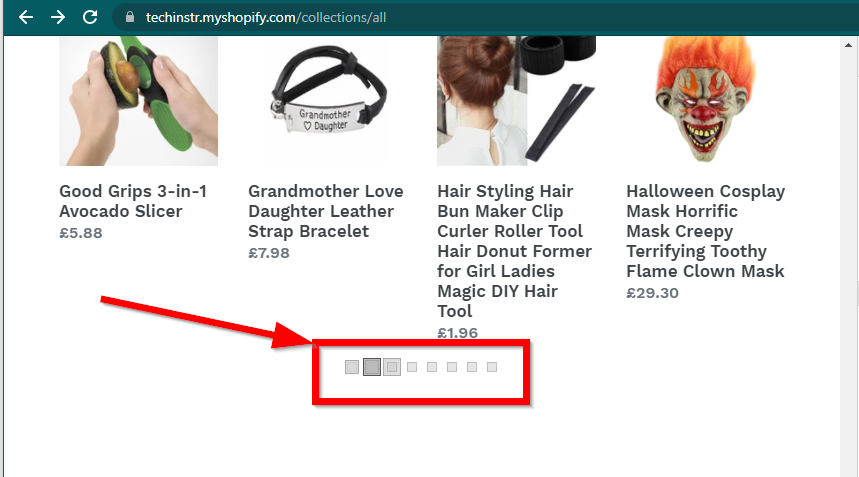 | 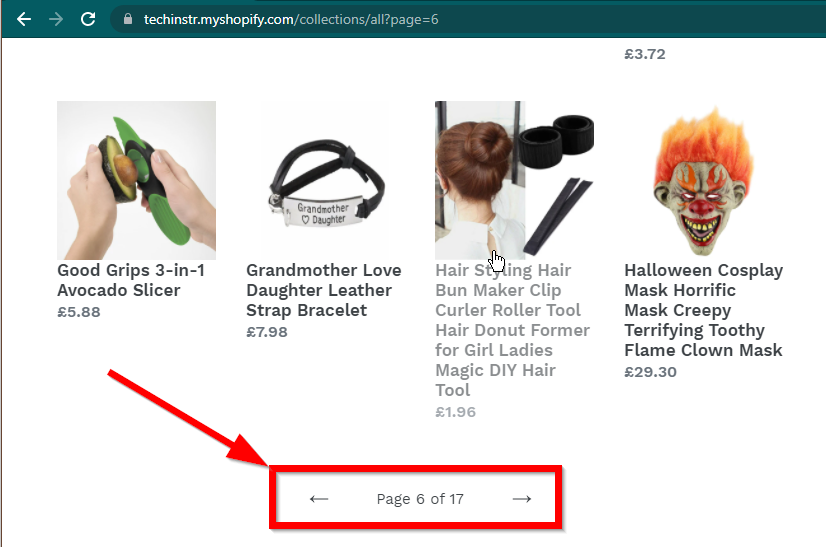 |
|---|---|
| JavaScript aktiviert | JavaScript deaktiviert |
Die nächste Frage, die beantwortet werden muss, betrifft die Fähigkeiten von BeautifulSoup.
JavaScript rendern?Die kurze Antwort ist nein.
Es ist wichtig, die Wörter wie Parsen und Rendern zu verstehen. Beim Parsen wird einfach eine String-Darstellung eines Python-Objekts in ein tatsächliches Objekt konvertiert.
Was ist also Rendering? Beim Rendern werden im Wesentlichen HTML, JavaScript, CSS und Bilder in etwas interpretiert, das wir im Browser sehen.
Beautiful Soup ist eine Python-Bibliothek zum Extrahieren von Daten aus HTML-Dateien. Dazu gehört das Parsen einer HTML-Zeichenfolge in das BeautifulSoup-Objekt. Zum Parsen benötigen wir zunächst den HTML-Code als String. Dynamische Websites verfügen nicht direkt über die Daten im HTML. Das bedeutet, dass BeautifulSoup nicht mit dynamischen Websites arbeiten kann.
Die Selenium-Bibliothek kann das Laden und Rendern von Websites in einem Browser wie Chrome oder Firefox automatisieren. Obwohl Selenium das Extrahieren von Daten aus HTML unterstützt, ist es möglich, vollständigen HTML-Code zu extrahieren und stattdessen Beautiful Soup zum Extrahieren der Daten zu verwenden.
Beginnen wir zunächst mit dem dynamischen Web-Scraping mit Python und Selenium.
Die Installation von Selenium umfasst die Installation von drei Dingen:
Der Browser Ihrer Wahl (den Sie bereits haben):
Der Treiber für Ihren Browser:
Python-Selenium-Paket:
pip install seleniumconda-forge -Kanal installiert werden. conda install -c conda-forge selenium Das Grundgerüst des Python-Skripts zum Starten eines Browsers, zum Laden der Seite und zum anschließenden Schließen des Browsers ist einfach:
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
#
# Code to read data from HTML here
#
driver . quit ()Nachdem wir die Seite nun in den Browser laden können, schauen wir uns das Extrahieren bestimmter Elemente an. Es gibt zwei Möglichkeiten, Elemente zu extrahieren: Selen und Beautiful Soup.
Unser Ziel in diesem Beispiel ist es, das Autorelement zu finden.
Laden Sie die Website https://quotes.toscrape.com/js/ in Chrome, klicken Sie mit der rechten Maustaste auf den Namen des Autors und klicken Sie auf „Inspizieren“. Dadurch sollten die Entwicklertools geladen werden, wobei das Autorenelement wie folgt hervorgehoben ist:
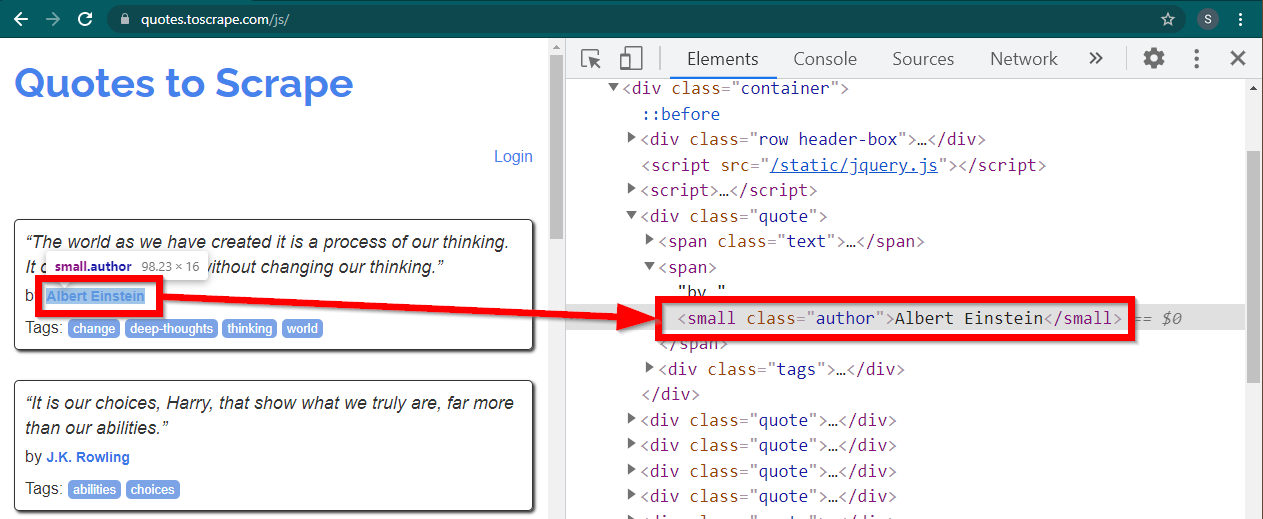
Dies ist ein small Element, dessen class auf author gesetzt ist.
< small class =" author " > Albert Einstein </ small >Selenium ermöglicht verschiedene Methoden zum Auffinden der HTML-Elemente. Diese Methoden sind Teil des Treiberobjekts. Einige der Methoden, die hier nützlich sein können, sind wie folgt:
element = driver . find_element ( By . CLASS_NAME , "author" )
element = driver . find_element ( By . TAG_NAME , "small" )Es gibt nur wenige andere Methoden, die für andere Szenarios nützlich sein können. Diese Methoden sind wie folgt:
element = driver . find_element ( By . ID , "abc" )
element = driver . find_element ( By . LINK_TEXT , "abc" )
element = driver . find_element ( By . XPATH , "//abc" )
element = driver . find_element ( By . CSS_SELECTOR , ".abc" ) Die vielleicht nützlichsten Methoden sind find_element(By.CSS_SELECTOR) und find_element(By.XPATH) . Mit jeder dieser beiden Methoden sollten die meisten Szenarien ausgewählt werden können.
Ändern wir den Code so, dass der Erstautor gedruckt werden kann.
from selenium . webdriver import Chrome
from selenium . webdriver . common . by import By
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
element = driver . find_element ( By . CLASS_NAME , "author" )
print ( element . text )
driver . quit ()Was ist, wenn Sie alle Autoren drucken möchten?
Alle find_element -Methoden haben ein Gegenstück – find_elements . Beachten Sie die Pluralisierung. Um alle Autoren zu finden, ändern Sie einfach eine Zeile:
elements = driver . find_elements ( By . CLASS_NAME , "author" )Dies gibt eine Liste von Elementen zurück. Wir können einfach eine Schleife ausführen, um alle Autoren auszugeben:
for element in elements :
print ( element . text )Hinweis: Der vollständige Code befindet sich in der Codedatei selenium_example.py.
Wenn Sie jedoch bereits mit BeautifulSoup vertraut sind, können Sie das Beautiful Soup-Objekt erstellen.
Wie wir im ersten Beispiel gesehen haben, benötigt das Beautiful Soup-Objekt HTML. Für statische Web-Scraping-Sites kann der HTML-Code mithilfe der requests abgerufen werden. Der nächste Schritt besteht darin, diesen HTML-String in das BeautifulSoup-Objekt zu analysieren.
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )Lassen Sie uns herausfinden, wie Sie mit BeautifulSoup eine dynamische Website erstellen.
Der folgende Teil bleibt gegenüber dem vorherigen Beispiel unverändert.
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
from bs4 import BeautifulSoup
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' ) Der gerenderte HTML-Code der Seite ist im Attribut page_source verfügbar.
soup = BeautifulSoup ( driver . page_source , "lxml" )Sobald das Suppenobjekt verfügbar ist, können alle Beautiful Soup-Methoden wie gewohnt verwendet werden.
author_element = soup . find ( "small" , class_ = "author" )
print ( author_element . text )Hinweis: Der vollständige Quellcode befindet sich in selenium_bs4.py
BrowserSobald das Skript fertig ist, muss der Browser nicht mehr sichtbar sein, wenn das Skript ausgeführt wird. Der Browser kann ausgeblendet werden und das Skript läuft weiterhin einwandfrei. Dieses Verhalten eines Browsers wird auch als Headless Browser bezeichnet.
Um den Browser kopflos zu machen, importieren Sie ChromeOptions . Für andere Browser stehen eigene Optionsklassen zur Verfügung.
from selenium . webdriver import ChromeOptions Erstellen Sie nun ein Objekt dieser Klasse und setzen Sie das headless -Attribut auf True.
options = ChromeOptions ()
options . headless = TrueSenden Sie dieses Objekt abschließend beim Erstellen der Chrome-Instanz.
driver = Chrome ( ChromeDriverManager (). install (), options = options )Wenn Sie nun das Skript ausführen, ist der Browser nicht sichtbar. Die vollständige Implementierung finden Sie in der Datei selenium_bs4_headless.py.
Das Laden des Browsers ist teuer – es beansprucht CPU, RAM und Bandbreite, die nicht wirklich benötigt werden. Beim Scraping einer Website sind die Daten wichtig. All diese CSS, Bilder und Renderings werden nicht wirklich benötigt.
Der schnellste und effizienteste Weg, dynamische Webseiten mit Python zu crawlen, besteht darin, den tatsächlichen Ort zu lokalisieren, an dem sich die Daten befinden.
Es gibt zwei Orte, an denen sich diese Daten befinden können:
<script> -TagSchauen wir uns einige Beispiele an.
Öffnen Sie https://quotes.toscrape.com/js in Chrome. Sobald die Seite geladen ist, drücken Sie Strg+U, um die Quelle anzuzeigen. Drücken Sie Strg+F, um das Suchfeld aufzurufen und nach Albert zu suchen.
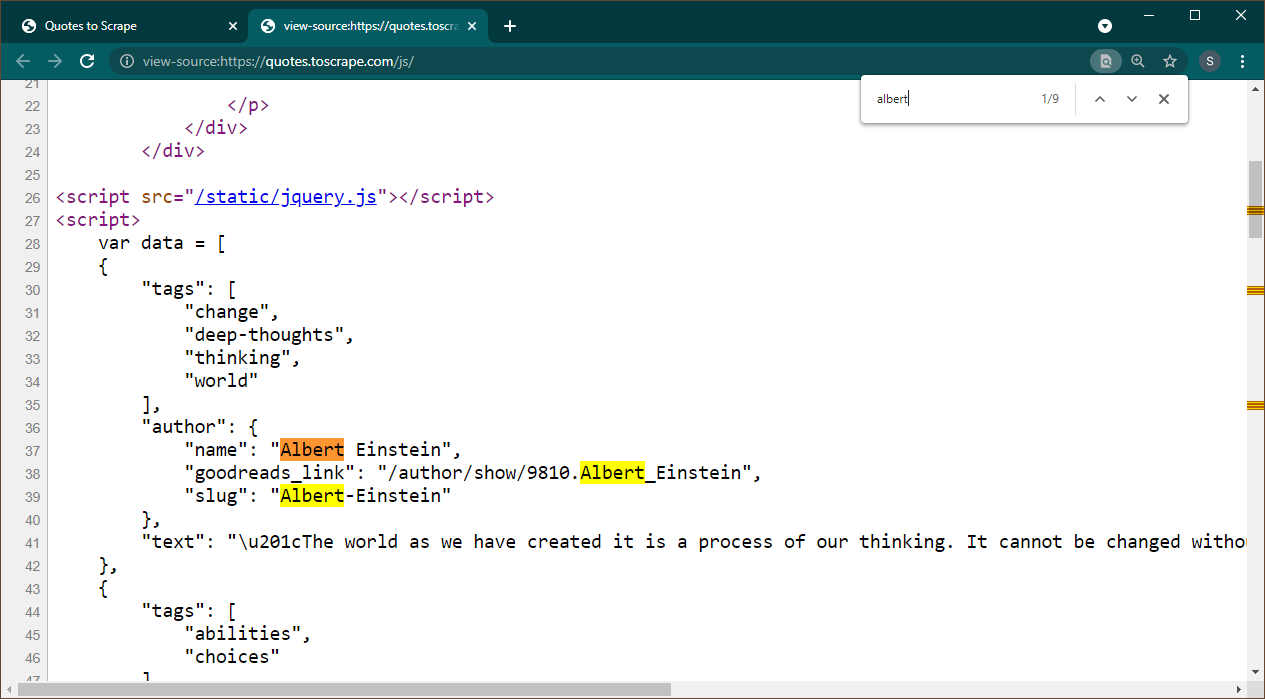
Wir können sofort erkennen, dass Daten als JSON-Objekt auf der Seite eingebettet sind. Beachten Sie außerdem, dass dies Teil eines Skripts ist, in dem diese Daten einer Variablen data zugewiesen werden.
In diesem Fall können wir die Requests-Bibliothek verwenden, um die Seite abzurufen, und Beautiful Soup verwenden, um die Seite zu analysieren und das Skriptelement abzurufen.
response = requests . get ( 'https://quotes.toscrape.com/js/' )
soup = BeautifulSoup ( response . text , "lxml" ) Beachten Sie, dass es mehrere <script> -Elemente gibt. Derjenige, der die von uns benötigten Daten enthält, hat kein src Attribut. Verwenden wir dies, um das Skriptelement zu extrahieren.
script_tag = soup . find ( "script" , src = None )Denken Sie daran, dass dieses Skript neben den Daten, die uns interessieren, weiteren JavaScript-Code enthält. Aus diesem Grund verwenden wir einen regulären Ausdruck, um diese Daten zu extrahieren.
import re
pattern = "var data =(.+?); n "
raw_data = re . findall ( pattern , script_tag . string , re . S )Die Datenvariable ist eine Liste mit einem Element. Jetzt können wir die JSON-Bibliothek verwenden, um diese String-Daten in ein Python-Objekt zu konvertieren.
if raw_data :
data = json . loads ( raw_data [ 0 ])
print ( data )Die Ausgabe wird das Python-Objekt sein:
[{ 'tags' : [ 'change' , 'deep-thoughts' , 'thinking' , 'world' ], 'author' : { 'name' : 'Albert Einstein' , 'goodreads_link' : '/author/show/9810.Albert_Einstein' , 'slug' : 'Albert-Einstein' }, 'text' : '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' }, { 'tags' : [ 'abilities' , 'choices' ], 'author' : { 'name' : 'J.K. Rowling' , .....................Diese Liste kann nicht beliebig in ein beliebiges Format konvertiert werden. Beachten Sie außerdem, dass jedes Element einen Link zur Autorenseite enthält. Das bedeutet, dass Sie diese Links lesen und einen Spider erstellen können, um Daten von all diesen Seiten abzurufen.
Dieser vollständige Code ist in data_in_same_page.py enthalten.
Dynamische Web-Scraping-Sites können einen völlig anderen Weg einschlagen. Manchmal werden die Daten insgesamt auf einer separaten Seite geladen. Ein solches Beispiel ist Librivox.
Öffnen Sie die Entwicklertools, gehen Sie zur Registerkarte „Netzwerk“ und filtern Sie nach XHR. Öffnen Sie nun diesen Link oder suchen Sie nach einem beliebigen Buch. Sie werden sehen, dass es sich bei den Daten um in JSON eingebettetes HTML handelt.
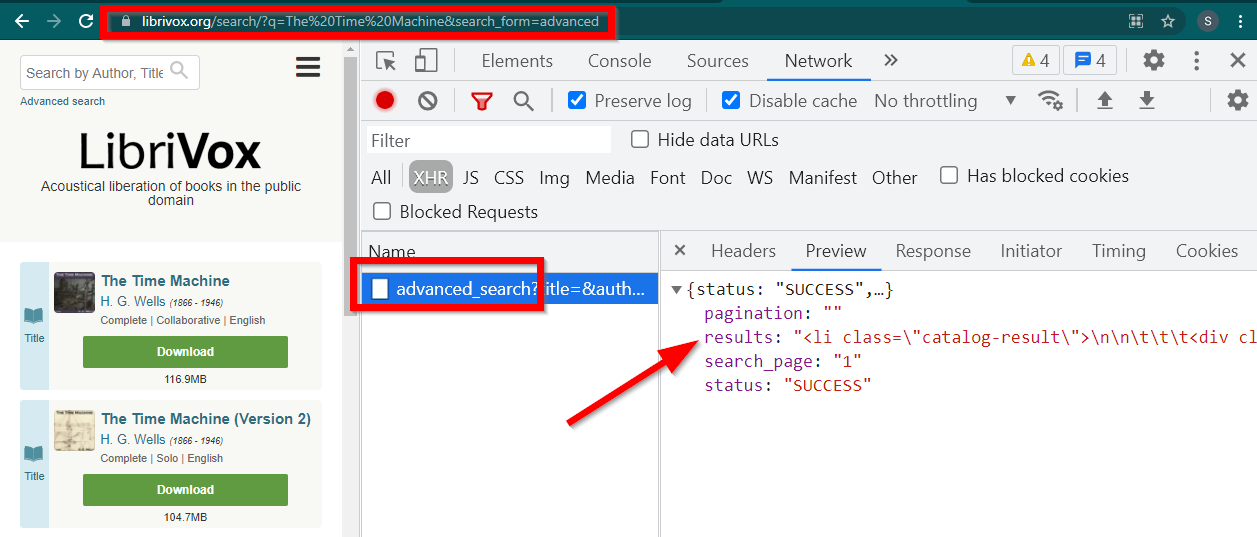
Beachten Sie einige Dinge:
Die vom Browser angezeigte URL lautet https://librivox.org/search/?q=...
Die Daten finden Sie unter https://librivox.org/advanced_search?....
Wenn Sie sich die Header ansehen, werden Sie feststellen, dass der Seite „advanced_search“ ein spezieller Header X-Requested-With: XMLHttpRequest gesendet wird
Hier ist ein Ausschnitt zum Extrahieren dieser Daten:
headers = {
'X-Requested-With' : 'XMLHttpRequest'
}
url = 'https://librivox.org/advanced_search?title=&author=&reader=&keywords=&genre_id=0&status=all&project_type=either&recorded_language=&sort_order=alpha&search_page=1&search_form=advanced&q=The%20Time%20Machine'
response = requests . get ( url , headers = headers )
data = response . json ()
soup = BeautifulSoup ( data [ 'results' ], 'lxml' )
book_titles = soup . select ( 'h3 > a' )
for item in book_titles :
print ( item . text )Der vollständige Code ist in der Datei librivox.py enthalten.


