metal flash attention
v1.0.1
Dieses Repository portiert die offizielle Implementierung von FlashAttention auf Apple-Silizium. Es handelt sich um einen minimalen, wartbaren Satz von Quelldateien, der den FlashAttention-Algorithmus reproduziert.
Nur einköpfige Aufmerksamkeit, um sich auf die Kernengpässe verschiedener Aufmerksamkeitsalgorithmen (Registerdruck, Parallelität) zu konzentrieren. Wenn der Grundalgorithmus korrekt ausgeführt wird, sollte es vergleichsweise einfach sein, Anpassungen wie Blocksparsity hinzuzufügen.
Alles wird zur Laufzeit JIT-kompiliert. Dies steht im Gegensatz zur vorherigen Implementierung, die auf einer in Xcode 14.2 eingebetteten ausführbaren Datei basierte.
Der Rückwärtsdurchlauf verbraucht weniger Speicher als Dao-AILab/flash-attention. Die offizielle Implementierung weist Arbeitsraum für Atome und Teilsummen zu. Auf Apple-Hardware fehlen native FP32-Atomics ( metal::atomic<float> wird emuliert). Bei dem Versuch, die fehlende Hardwareunterstützung zu umgehen, wurden Bandbreiten- und Parallelisierungsengpässe im FlashAttention-2-Backward-Kernel aufgedeckt. Ein alternativer Rückwärtsdurchlauf wurde mit höheren Rechenkosten entwickelt (7 GEMMs statt 5 GEMMs). Es erreicht eine Parallelisierungseffizienz von 100 % sowohl in der Zeilen- als auch in der Spaltendimension der Aufmerksamkeitsmatrix. Am wichtigsten ist, dass es einfacher zu programmieren und zu warten ist.
Es wurden viele verrückte Dinge getan, um Engpässe beim Registerdruck zu überwinden. Bei großen Kopfabmessungen (z. B. 256) passt keiner der Matrixblöcke in Register. Das kann nicht einmal der Akku. Daher wird absichtlich ein Register-Spilling durchgeführt, allerdings auf eine optimiertere Art und Weise. Dem Aufmerksamkeitsalgorithmus wurde eine dritte Blockdimension hinzugefügt, die entlang D blockt. Das Seitenverhältnis der Aufmerksamkeitsmatrixblöcke wurde stark verzerrt, um die Bandbreitenkosten durch Register-Spilling zu minimieren. Zum Beispiel 16-32 entlang der Parallelisierungsdimension und 80-128 entlang der Traversaldimension. Es gibt eine große Parameterdatei, die die D -Dimension annimmt und bestimmt, welche Operanden in Register passen. Anschließend wird eine Blockgröße zugewiesen, die viele konkurrierende Engpässe ausgleicht.
Das Endergebnis sind konsistente 4400 Gigaanweisungen pro Sekunde auf M1 Max (83 % ALU-Auslastung), bei unendlicher Sequenzlänge und unendlicher Kopfdimension. Vorausgesetzt, die BF16-Emulation wird für gemischte Präzision verwendet (Metals bfloat verfügt über IEEE-konforme Rundung, ein großer Overhead bei älteren Chips ohne Hardware-BF16).
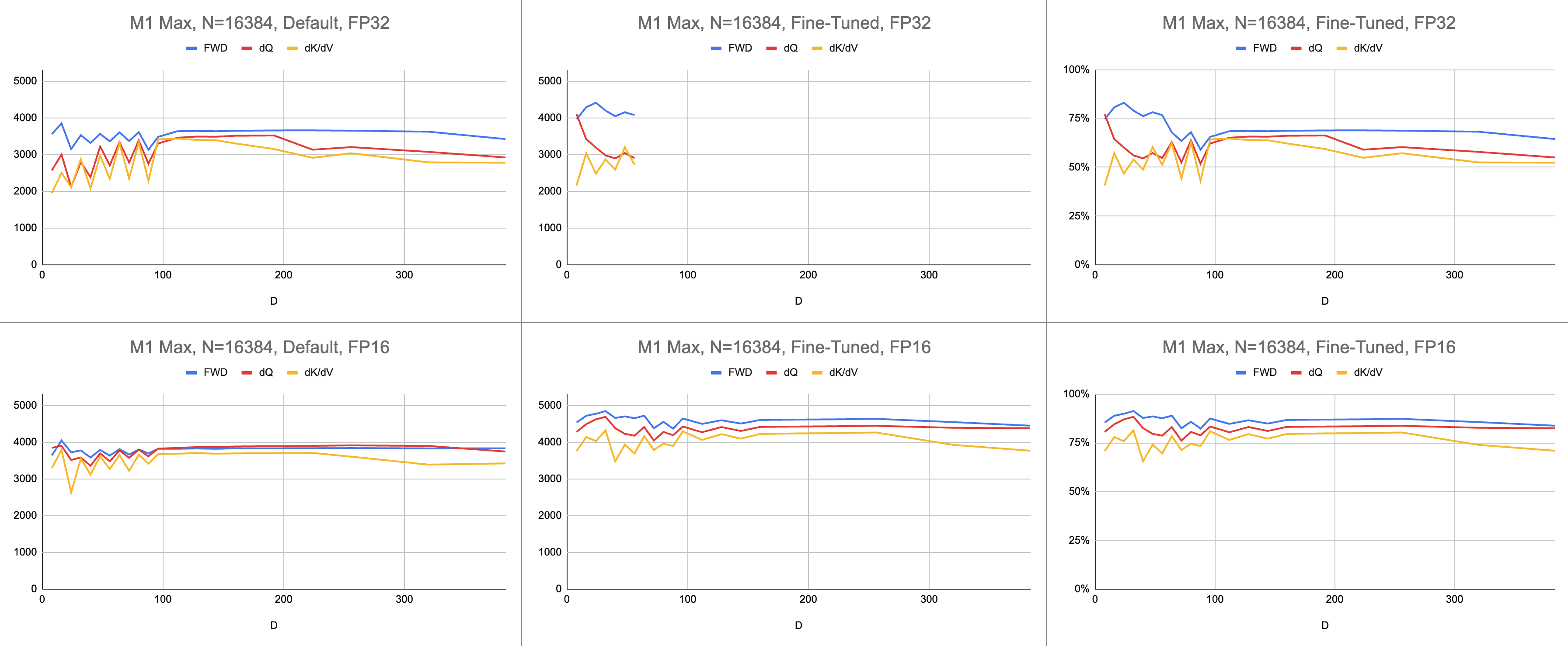
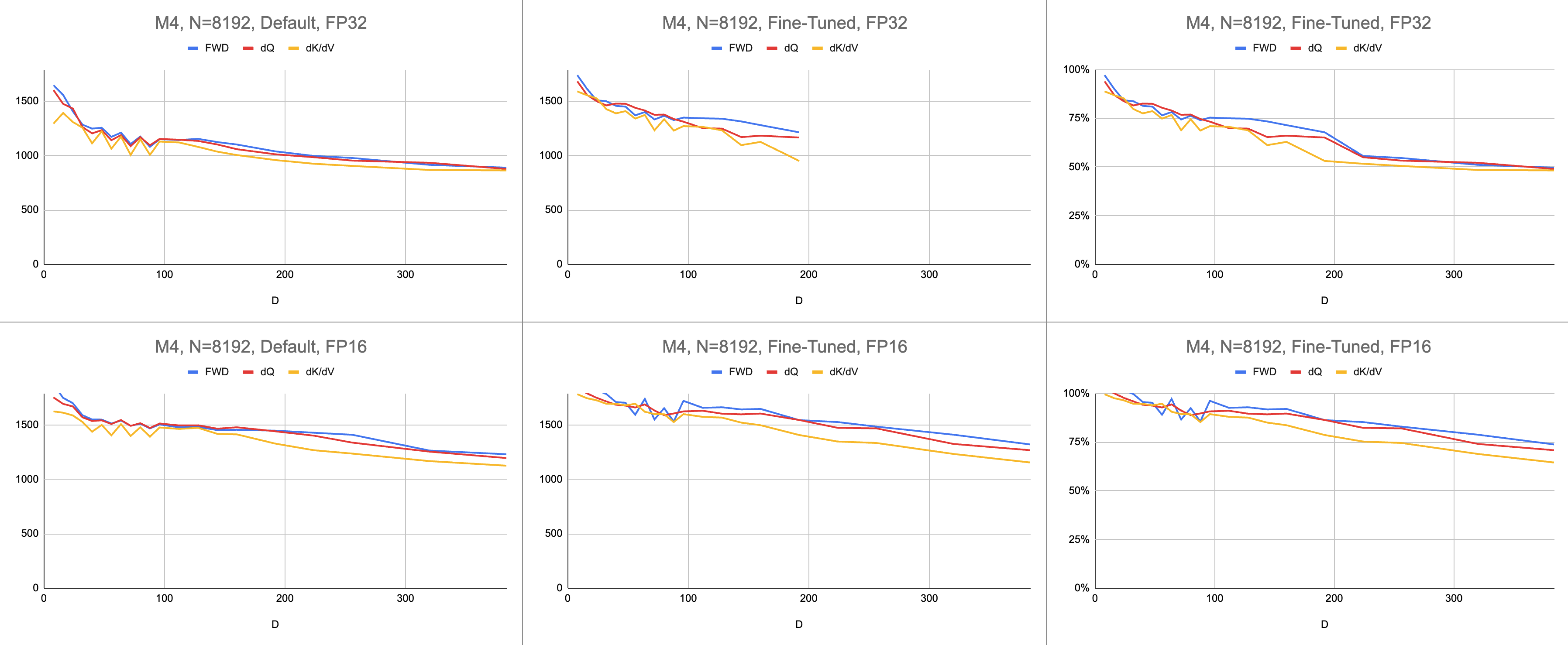
Rohdaten: https://docs.google.com/spreadsheets/d/1Xf4jrJ7e19I32J1IWIekGE9uMFTeZKoOpQ6hlUoh-xY/edit?usp=sharing
Im KI-Bereich wird die Leistung am häufigsten in Giga-Gleitkommaoperationen pro Sekunde (GFLOPS) angegeben. Diese Metrik spiegelt ein vereinfachtes Leistungsmodell wider, bei dem jede Anweisung in GEMM auftritt. Mit der Weiterentwicklung der Hardware von frühen FPUs zu modernen Vektorprozessoren wurden die gängigsten Gleitkommaoperationen in einem einzigen Befehl zusammengefasst. Fused Multiply-Add (FMA). Wenn man zwei 100x100-Matrizen multipliziert, werden 1 Million FMA-Anweisungen ausgegeben. Warum müssen wir diese FMA als zwei separate Anweisungen behandeln?
Diese Frage ist relevant, da nicht alle Gleitkommaoperationen gleich sind. Die Potenzierung während Softmax erfolgt in einem einzigen Taktzyklus, vorausgesetzt, dass die meisten anderen Befehle an die FMA-Einheit gehen. Einige der Multiplikationen und Additionen während Softmax können nicht mit einer nahegelegenen Addition oder Multiplikation fusioniert werden. Sollten wir diese wie FMA behandeln und so tun, als würde die Hardware die FMA nur doppelt so langsam ausführen? Es ist unklar, wie das GEMM-Leistungsmodell erklären kann, ob mein Shader die ALU-Hardware effektiv nutzt.
Anstelle von Gigaflops verwende ich Gigaanweisungen, um zu verstehen, wie gut der Shader funktioniert. Es lässt sich direkter auf den Algorithmus abbilden. Ein GEMM besteht beispielsweise aus N^3 FMA-Anweisungen. Die Vorwärtsaufmerksamkeit führt zwei Matrixmultiplikationen oder 2 * D * N^2 FMA-Anweisungen durch. Die Rückwärtsaufmerksamkeit (durch die Dao-AILab/Flash-Attention-Implementierung) beträgt 5 * D * N^2 FMA-Anweisungen. Versuchen Sie, diese Tabelle mit Dachlinienmodellen in den Flash1-, Flash2- oder Flash3-Papieren zu vergleichen.
| Betrieb | Arbeiten |
|---|---|
| Quadratisches GEMM | N^3 |
| Aufmerksamkeit weiterleiten | (2D + 5) * N^2 |
| Rückständige naive Aufmerksamkeit | 4D * N^2 |
| RückwärtsblitzAchtung | (5D + 5) * N^2 |
| FWD + BWD kombiniert | (7D + 10) * N^2 |
Aufgrund der Komplexität der FP32-Atomik verwendete MFA einen anderen Ansatz für den Rückwärtsdurchlauf. Dieser hat höhere Rechenkosten. Es teilt den Rückwärtsdurchlauf in zwei separate Kernel auf: dQ und dK/dV . Ein Dropdown-Menü zeigt den Pseudocode. Vergleichen Sie dies mit einem der Algorithmen in den Flash1-, Flash2- oder Flash3-Artikeln.
| Betrieb | Arbeiten |
|---|---|
| Nach vorne | (2D + 5) * N^2 |
| Rückwärts dQ | (3D + 5) * N^2 |
| Rückwärts dK/dV | (4D + 5) * N^2 |
| FWD + BWD kombiniert | (9D + 15) * N^2 |
// Forward
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// (m, l, P) = softmax(m, l, S * scaleFactor)
//
// O *= correction
// load V[c]
// O += P * V
// }
// O /= l
//
// L = m + logBaseE(l)
//
// Backward Query
// D = dO * O
//
// for c in 0..<C {
// load K[c]
// S = Q * K^T
// P = exp(S - L)
//
// load V[c]
// dP = dO * V^T
// dS = P * (dP - D) * scaleFactor
//
// load K[c]
// dQ += dS * K
// }
//
// Backward Key-Value
// for r in 0..<R {
// load Q[r]
// load L[r]
// S^T = K * Q^T
// P^T = exp(S^T - L)
//
// load dO[r]
// dV += P^T * dO
//
// load dO[r]
// load D[r]
// dP^T = V * dO^T
// dS^T = P^T * (dP^T - D) * scaleFactor
//
// load Q[r]
// dK += dS^T * Q
// }Die Leistung wird gemessen, indem der Umfang der Rechenarbeit berechnet und dann durch Sekunden dividiert wird. Das Endergebnis sind „Gigaanweisungen pro Sekunde“. Als nächstes benötigen wir ein Dachlinienmodell. Die folgende Tabelle zeigt Dachlinien für GINSTRS, berechnet als die Hälfte von GFLOPS. Die ALU-Nutzung beträgt (tatsächliche Gigaanweisungen pro Sekunde) / (erwartete Gigaanweisungen pro Sekunde). Beispielsweise erreicht M1 Max typischerweise eine ALU-Auslastung von 80 % mit gemischter Präzision.
Diesem Modell sind Grenzen gesetzt. Bei kleinen Kopfabmessungen bricht es mit der M3-Generation zusammen. Es können verschiedene Recheneinheiten gleichzeitig genutzt werden, sodass die scheinbare Auslastung über 100 % liegt. Der Benchmark liefert größtenteils ein genaues Modell dafür, wie viel Leistung noch übrig ist.
var operations : Int
switch benchmarkedKernel {
case . forward :
operations = 2 * headDimension + 5
case . backwardQuery :
operations = 3 * headDimension + 5
case . backwardKeyValue :
operations = 4 * headDimension + 5
}
operations *= ( sequenceDimension * sequenceDimension )
operations *= dispatchCount
// Divide the work by the latency, resulting in throughput.
let instrs = Double ( operations ) / Double ( latencySeconds )
let ginstrs = Int ( instrs / 1e9 )| Hardware | GFLOPS | GINSTRS |
|---|---|---|
| M1 max | 10616 | 5308 |
| M4 | 3580 | 1790 |
Wie gut schneidet die Metal-Portierung im Vergleich zum offiziellen FlashAttention-Repository ab? Stellen Sie sich vor, ich hätte den „Atomic dQ“-Algorithmus verwendet und eine Leistung von 100 % erreicht. Dann wechselte ich zum eigentlichen MFA-Repo und stellte fest, dass das Modelltraining viermal langsamer war. Das wären 25 % der Dachlinie des offiziellen Endlagers. Um diesen Prozentsatz zu erhalten, multiplizieren Sie die durchschnittliche ALU-Auslastung aller drei Kernel mit 7 / 9 . Für die Statistiken zur Apple-Hardware wurde ein differenzierteres Modell verwendet, aber das ist das Wesentliche.
Um die Auslastung der Nvidia-Hardware zu berechnen, habe ich GFLOPS für FP16/BF16-ALUs verwendet. Ich habe die höchsten GFLOPS aus jedem Diagramm in der Arbeit durch 312.000 (A100 SXM), 989.000 (H100 SXM) dividiert. Beachten Sie, dass für größere Kopfabmessungen und registerintensive Kernel (Rückwärtsdurchlauf) keine Benchmarks gemeldet wurden. Ich habe bestätigt, dass sie das Registerdruckproblem bei unendlichen Kopfabmessungen nicht gelöst haben. Beispielsweise wird der Akkumulator immer in Registern gehalten. Zum Zeitpunkt des Schreibens hatte ich keine konkreten Beweise dafür gesehen, dass der Rückwärtsgradient D=256 mit korrekten Ergebnissen ausgeführt wurde.
| A100, Flash2, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Nach vorne | 192000 | 223000 | 0 |
| Rückwärts | 170000 | 196000 | 0 |
| Vorwärts + Rückwärts | 176000 | 203000 | 0 |
| H100, Flash3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Nach vorne | 497000 | 648000 | 756000 |
| Rückwärts | 474000 | 561000 | 0 |
| Vorwärts + Rückwärts | 480000 | 585000 | 0 |
| H100, Flash3, FP8 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Nach vorne | 613000 | 1008000 | 1171000 |
| Rückwärts | 0 | 0 | 0 |
| Vorwärts + Rückwärts | 0 | 0 | 0 |
| A100, Flash2, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Nach vorne | 62 % | 71 % | 0% |
| Vorwärts + Rückwärts | 56 % | 65 % | 0% |
| H100, Flash3, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Nach vorne | 50 % | 66 % | 76 % |
| Vorwärts + Rückwärts | 48 % | 59 % | 0% |
| M1-Architektur, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Nach vorne | 86 % | 85 % | 86 % |
| Vorwärts + Rückwärts | 62 % | 63 % | 64 % |
| M3-Architektur, FP16 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| Nach vorne | 94 % | 91 % | 82 % |
| Vorwärts + Rückwärts | 71 % | 69 % | 61 % |
| Hardware hergestellt im Jahr 2020 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| A100 | 56 % | 65 % | 0% |
| M1-M2-Architektur | 62 % | 63 % | 64 % |
| Hardware hergestellt im Jahr 2023 | D = 64 | D = 128 | D = 256 |
|---|---|---|---|
| H100 (mit FP8 GFLOPS) | 24 % | 30 % | 0% |
| H100 (mit FP16 GFLOPS) | 48 % | 59 % | 0% |
| M3-M4-Architektur | 71 % | 69 % | 61 % |
Obwohl mehr Berechnungen durchgeführt werden, trainiert Apple-Hardware Transformatoren schneller als Nvidia-Hardware, die die gleiche Arbeit erledigt . Normalisierung für den Größenunterschied zwischen verschiedenen GPUs. Konzentrieren Sie sich nur darauf, wie effizient die GPU genutzt wird.
Vielleicht sollte das Haupt-Repository den Algorithmus ausprobieren, der FP32-Atomics vermeidet und absichtlich Register verschüttet, wenn sie nicht in den GPU-Kern passen. Dies scheint unwahrscheinlich, da sie eine fest codierte Unterstützung für eine kleine Teilmenge der möglichen Problemgrößen bieten. Die Motivation scheint darin zu liegen, die gängigsten Modelle zu unterstützen, bei denen D eine Potenz von 2 und kleiner als 128 ist. Für alles andere müssen sich Benutzer auf alternative Fallback-Implementierungen (z. B. das MFA-Repository) verlassen, die möglicherweise ein völlig anderes zugrunde liegendes Modell verwenden Algorithmus.
Laden Sie unter macOS das Swift-Paket herunter und kompilieren Sie es mit -Xswiftc -Ounchecked . Diese Compileroption wird für leistungsempfindlichen CPU-Code benötigt. Der Release-Modus kann nicht verwendet werden, da er erzwingt, dass die gesamte Codebasis bei jeder einzelnen Änderung von Grund auf neu kompiliert wird. Navigieren Sie im Finder zum Git-Repository und doppelklicken Sie auf Package.swift . Es sollte ein Xcode-Fenster erscheinen. Auf der linken Seite sollte eine Dateihierarchie angezeigt werden. Wenn Sie die Hierarchie nicht entschlüsseln können, ist etwas schief gelaufen.
git clone https://github.com/philipturner/metal-flash-attention
swift build -Xswiftc -Ounchecked # Does it even compile?
swift test -Xswiftc -Ounchecked # Does the test suite finish in ~10 seconds?
Alternativ können Sie ein neues Xcode-Projekt mit der SwiftUI-Vorlage erstellen. Überschreiben Sie das "Hello, world!" string mit einem Aufruf einer Funktion, die einen String zurückgibt. Diese Funktion führt das Skript Ihrer Wahl aus und ruft dann exit(0) auf, sodass die App abstürzt, bevor etwas auf dem Bildschirm angezeigt wird. Sie verwenden die Ausgabe in der Xcode-Konsole als Feedback zu Ihrem Code. Dieser Workflow ist sowohl mit macOS als auch mit iOS kompatibel.
Fügen Sie die Option -Xswiftc -Ounchecked über Project > Name Ihres Projekts > Build Settings > Swift Compiler – Code Generation > Optimization Level hinzu. In der zweiten Spalte der Tabelle wird der Name Ihres Projekts aufgeführt. Klicken Sie im Dropdown-Menü auf „Andere“ und geben Sie im angezeigten Fenster -Ounchecked ein. Als nächstes fügen Sie dieses Repository als Swift-Paketabhängigkeit hinzu. Schauen Sie sich einige der Tests unter Tests/FlashAttention an. Kopieren Sie den Rohquellcode für einen dieser Tests in Ihr Projekt. Rufen Sie den Test über die Funktion im vorherigen Absatz auf. Untersuchen Sie, was auf der Konsole angezeigt wird.
Um die Metal-Codegenerierung zu ändern (z. B. Unterstützung für mehrere Köpfe oder Masken hinzuzufügen), kopieren Sie den rohen Swift-Code in Ihr Xcode-Projekt. Verwenden Sie entweder git clone in einem separaten Ordner oder laden Sie die Rohdateien auf GitHub als ZIP herunter. Es gibt auch eine Möglichkeit, eine Verbindung zu Ihrem Fork von metal-flash-attention herzustellen und Ihre Änderungen automatisch in der Cloud zu speichern, diese ist jedoch schwieriger einzurichten. Entfernen Sie die Swift-Paketabhängigkeit aus dem vorherigen Absatz. Führen Sie den Test Ihrer Wahl erneut durch. Kompiliert es etwas und zeigt es etwas in der Konsole an?
Suchen Sie eines der mehrzeiligen Zeichenfolgenliterale in einem dieser Ordner:
Sources/FlashAttention/Attention/AttentionKernel
Sources/FlashAttention/GEMM/GEMMKernel
Fügen Sie einem davon zufälligen Text hinzu. Kompilieren Sie das Projekt und führen Sie es erneut aus. Etwas sollte furchtbar schief gehen. Beispielsweise kann der Metal-Compiler einen Fehler auslösen. Wenn dies nicht der Fall ist, versuchen Sie, an einer anderen Stelle eine andere Codezeile durcheinander zu bringen. Wenn der Test weiterhin besteht, registriert Xcode Ihre Änderungen nicht.
Fahren Sie mit der Codierung der Blocksparsity oder so fort. Erhalten Sie Feedback darüber, ob der Code überhaupt funktioniert, ob er schnell funktioniert und ob er bei jeder Problemgröße schnell funktioniert. Integrieren Sie den Rohquellcode in Ihre App oder übersetzen Sie ihn in eine andere Programmiersprache.


