eye in the sky
1.0.0
Satellitenbildklassifizierung, InterIIT Techmeet 2018, IIT Bombay.
Team: Manideep Kolla, Aniket Mandle, Apoorva Kumar
Dieses Repository enthält die Implementierung von zwei Algorithmen, nämlich U-Net: Convolutional Networks for Biomedical Image Segmentation und Pyramid Scene Parsing Network, modifiziert für das Problem der Satellitenbildklassifizierung.
main_unet.py : Python-Code zum Trainieren des Algorithmus mit der U-Net-Architektur einschließlich der Kodierung der Grundwahrheiten.unet.py : Enthält unsere Implementierung von U-Net-Layern.test_unet.py : Code zum Testen, Berechnen von Genauigkeiten, Berechnen von Verwirrungsmatrizen für Training und Validierung und Speichern von Vorhersagen des U-Net-Modells zum Training, zur Validierung und zum Testen von Bildern.Inter-IIT-CSRE : Enthält alle Schulungs- und Validierungs- und Testdaten.Comparison_Test.pdf : Direkter Vergleich der Testdaten mit den U-Net-Modellvorhersagen für die Daten.train_predictions : U-Net-Modellvorhersagen für Trainings- und Validierungsbilder.plots : Genauigkeits- und Verlustdiagramme für Training und Validierung für die U-Net-Architektur.Test_images , Test_outputs : Enthält Testbilder und ihre Vorhersagen für das U-Net-Modell.class_masks , compare_pred_to_gt , images_for_doc : Enthält mehrere Bilder zur Dokumentation.PSPNet : Enthält Trainingsdateien für die Implementierung des PSPNet-Algorithmus zur Klassifizierung von Satellitenbildern. Klonen Sie das Repository und ändern Sie Ihr aktuelles Arbeitsverzeichnis in das geklonte Verzeichnis. Erstellen Sie Ordner mit den Namen train_predictions und test_outputs um vom Modell vorhergesagte Ausgaben für Trainings- und Testbilder zu speichern (jetzt nicht erforderlich, da das Repo diese Ordner bereits enthält).
$ git clone https://github.com/manideep2510/eye-in-the-sky.git
$ cd eye-in-the-sky
$ mkdir train_predictions
$ mkdir test_outputs
Führen Sie den folgenden Befehl aus, um das U-Net-Modell zu trainieren und Gewichte zu sparen
$ python3 main_unet.py
Zum Testen des U-Net-Modells, zum Berechnen von Genauigkeiten, zum Berechnen von Verwirrungsmatrizen für Training und Validierung und zum Speichern von Vorhersagen des Modells zu Trainings-, Validierungs- und Testbildern.
$ python3 test_unet.py
Beim Ausführen unseres Codes erhalten Sie möglicherweise die Fehlermeldung xrange is not defined . Dieser Fehler ist nicht auf Fehler in unserem Code zurückzuführen, sondern auf ein nicht aktuelles Python-Paket namens libtiff (einige Teile des Quellcodes des Pakets befinden sich in Python2 und andere in Python3), das wir zum Lesen des Datensatzes verwendet haben, in dem sich dieser befindet Die Bilder liegen im .tif-Format vor. Wir konnten keine anderen Bibliotheken wie openCV oder PIL zum Lesen der Bilder verwenden, da diese das Lesen der 4-Kanal-.tif-Bilder nicht ordnungsgemäß unterstützen.
Dieser Fehler kann durch Bearbeiten des Quellcodes der libtiff -Bibliothek behoben werden.
Gehen Sie zu der Datei im Quellcode der Bibliothek, aus der der Fehler stammt (der Dateiname wird im Terminal angezeigt, wenn der Fehler angezeigt wird) und ersetzen Sie alle xrange() (python2)-Funktionen in der Datei durch range() (python3).
Wir stellen hier einige einigermaßen gute vortrainierte Gewichte zur Verfügung, damit die Benutzer nicht von Grund auf trainieren müssen.
| Beschreibung | Aufgabe | Datensatz | Modell |
|---|---|---|---|
| UNet-Architektur | Klassifizierung von Satellitenbildern | IITB-Datensatz (siehe Inter-IIT-CSRE Ordner) | herunterladen (.h5) |
Um die vorab trainierten Gewichtungen zu verwenden, ändern Sie den Namen der in test_unet.py erwähnten .h5-Datei (Gewichtungsdatei) so, dass er bei Bedarf mit dem Namen der Gewichtungsdatei übereinstimmt, die Sie heruntergeladen haben.
Lassen Sie uns jetzt diskutieren
1. Worum es in diesem Projekt geht,
2. Architekturen, die wir verwendet und mit denen wir experimentiert haben
3. Einige neuartige Trainingsstrategien, die wir im Projekt verwendet haben
Bei der Fernerkundung handelt es sich um die Wissenschaft, Informationen über Objekte oder Gebiete aus der Ferne zu erhalten, typischerweise von Flugzeugen oder Satelliten.
Wir haben das Problem der Klassifizierung von Satellitenbildern als semantisches Segmentierungsproblem erkannt und semantische Segmentierungsalgorithmen im Deep Learning entwickelt, um dieses Problem anzugehen.
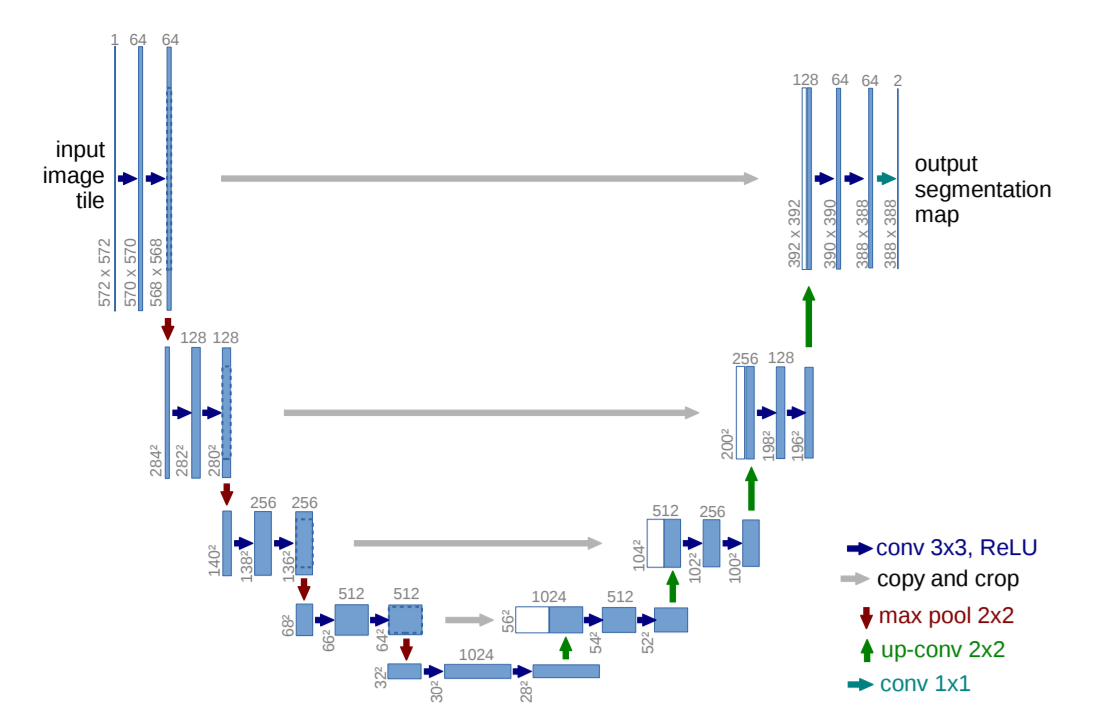
U-Net: Faltungsnetzwerke für die biomedizinische Bildsegmentierung
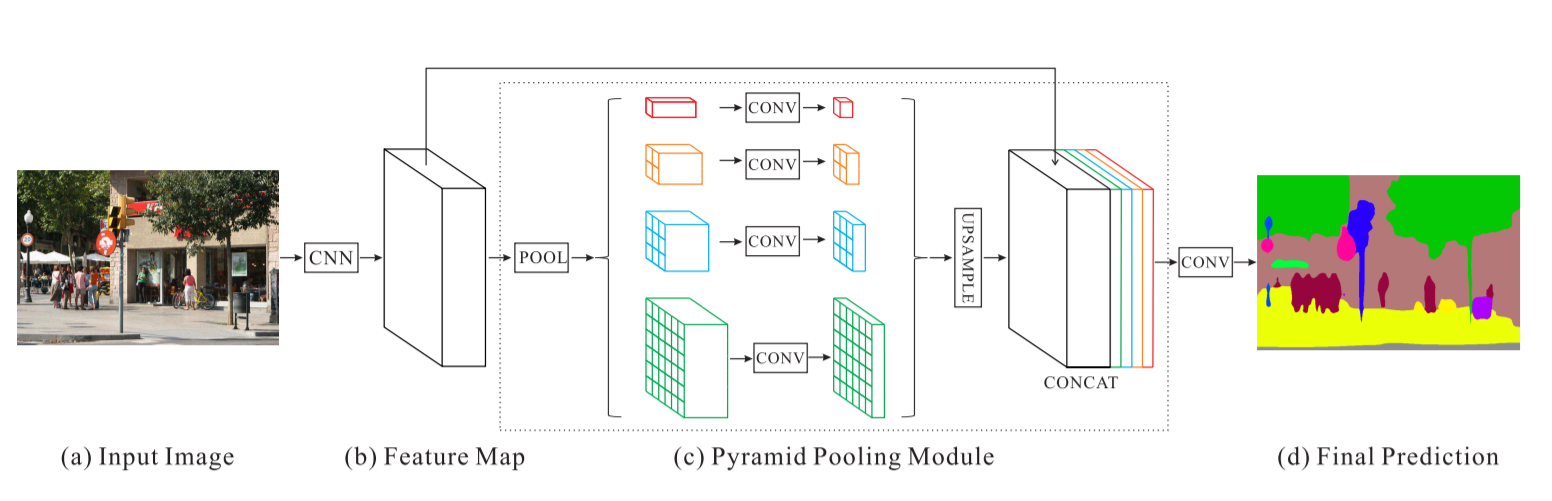
Pyramid Scene Parsing Network – PSPNet
Die bereitgestellten Grundwahrheiten sind 3-Kanal-RGB-Bilder. Im aktuellen Datensatz gibt es nur 9 eindeutige RGB-Werte in den Grundwahrheiten, da 9 Klassen klassifiziert werden müssen. Diese 9 verschiedenen RGB-Werte werden One-Hot-codiert, um eine 9-Kanal-codierte Ground Truth zu erzeugen, wobei jeder Kanal eine bestimmte Klasse darstellt.
Nachfolgend finden Sie das Codierungsschema
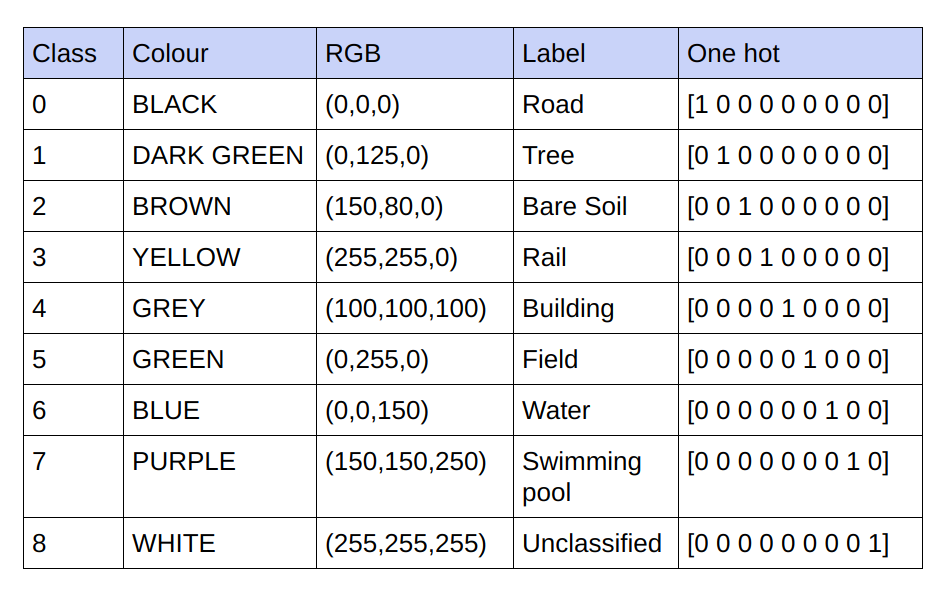
Realisierung jedes Kanals in der kodierten Grundwahrheit als Klasse

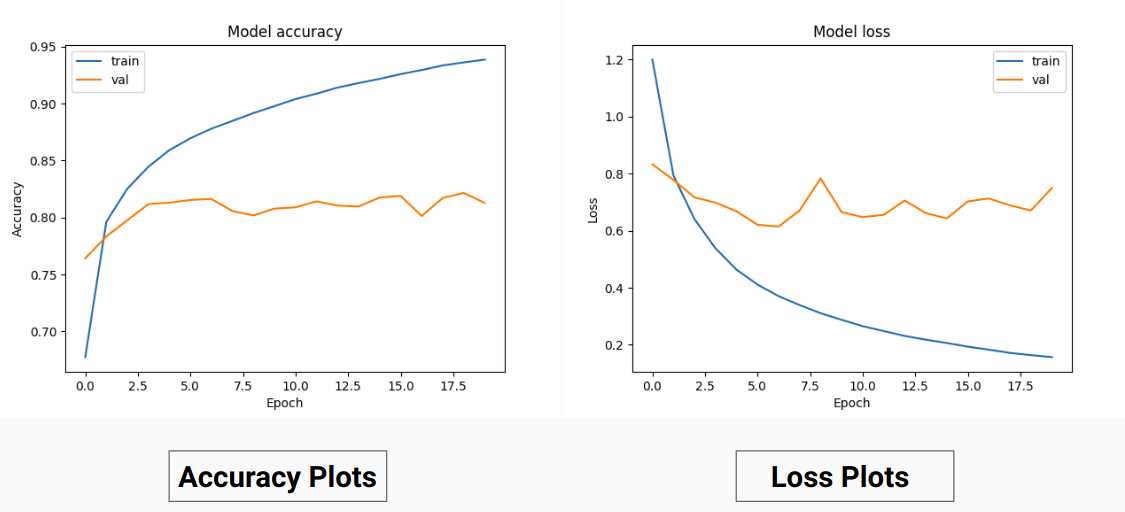
Anstatt also auf den RGB-Werten der Grundwahrheit zu trainieren, haben wir sie in One-Hot-Werte verschiedener Klassen umgewandelt. Dieser Ansatz ergab eine Validierungsgenauigkeit von 85 % und eine Trainingsgenauigkeit von 92 %, verglichen mit einer Validierungsgenauigkeit von 71 % und einer Trainingsgenauigkeit von 65 %, als wir die RGB-Grundwahrheitswerte für das Training verwendeten.
Dies könnte auf eine Verringerung der Varianz und des Mittelwerts der Grundwahrheit der Trainingsdaten zurückzuführen sein, da diese als wirksame Normalisierungstechnik fungieren. Die bessere Leistung dieser Trainingstechnik liegt auch daran, dass das Modell eine Ausgabe mit 9 Feature-Maps liefert, wobei jede Karte eine Klasse angibt, d. aber hier hängt definitiv die Vorhersage auf einem Kanal, der einer bestimmten Klasse entspricht, von anderen ab) .
Unsere Ergebnisse auf PSPNet für die Klassifizierung von Satellitenbildern:
Trainingsgenauigkeit – 49 % Validierungsgenauigkeit – 60 %
Gründe:
U-Net:
Modifiziertes U-Net:
Für Training und Validierung haben wir die 14 „.tif“-Bilder im Ordner Inter-IIT-CSRE/The-Eye-in-the-Sky-dataset verwendet.
Für das Training haben wir die ersten 13 Bilder im Datensatz verwendet und zur Validierung wird das 14. Bild verwendet .
Jedes Satellitenbild im Ordner sat enthält 4 Kanäle, nämlich R (Band 1), G (Band 2), B (Band 3) und NIR (Band 4).
Die Ground-Truth-Bilder im gt Verzeichnis sind RGB-Bilder und zeigen 8 Klassen: Straßen, Gebäude, Bäume, Gras, nackter Boden, Wasser, Eisenbahnen und Schwimmbäder
Der Grund, warum wir nur ein Bild (14. Bild) als Validierungssatz berücksichtigt haben, liegt darin, dass es eines der kleinsten Bilder im Datensatz ist und wir nicht weniger Daten für das Training übrig lassen wollen, da der Datensatz ziemlich klein ist. Der von uns betrachtete Validierungssatz (14. Bild) enthält keine drei Klassen (Bare-Soil, Rail, Swimmimg-Umfrage), die eine ziemlich hohe Trainingsgenauigkeit aufweisen. Die Validierungsgenauigkeit wäre besser gewesen, wenn wir ein Bild mit allen darin enthaltenen Klassen berücksichtigt hätten (kein Bild im Datensatz enthält alle Klassen, es fehlt mindestens eine Klasse in allen Bildern).
Das geschrittenen Zuschneiden:
Um ausreichend Trainingsdaten aus den gegebenen hochauflösenden Bildern zu erhalten, ist ein Zuschneiden erforderlich, um den Klassifikator zu trainieren, der über etwa 31 Millionen Parameter unserer U-Net-Implementierung verfügt. Bei der Ausschnittgröße von 64 x 64 stellen wir fest, dass die einzelnen Klassen unterrepräsentiert sind und die Geometrie und Kontinuität der Objekte verloren geht, wodurch das Sichtfeld der Windungen verringert wird.
Unter Verwendung eines Zuschneidefensters von 128 x 128 Pixeln mit einem Schritt von 32, was aus 15887 Trainings-414 Validierungsbildern resultiert.
Bildabmessungen:
Vor dem Zuschneiden werden die Abmessungen der Trainingsbilder zur Vereinfachung des schrittweisen Zuschneidens in Vielfache der Schrittlänge umgewandelt.
Für die Fälle, in denen die Nr. Da die Anzahl der Ausschnitte nicht das Vielfache der Bilddimensionen ist, die wir ursprünglich mit Zero Padding versucht haben, haben wir festgestellt, dass das Hinzufügen von Padding unerwünschte Artefakte in Form von schwarzen Pixeln in Trainings- und Testbildern hinzufügt, was zu einem Training mit falschen Daten und Bildgrenzen führt.
Alternativ haben wir die Bildabmessungen korrekt geändert, indem wir ganz rechts und unten im Bild zusätzliche Pixel hinzugefügt haben. Deshalb haben wir den Unterschied vom äußersten linken Teil des Bildes zum rechten Defizitende aufgefüllt und das Gleiche gilt für den oberen und unteren Teil des Bildes.
Trainingsbeispiel 1: Bild „2.tif“ aus Trainingsdaten
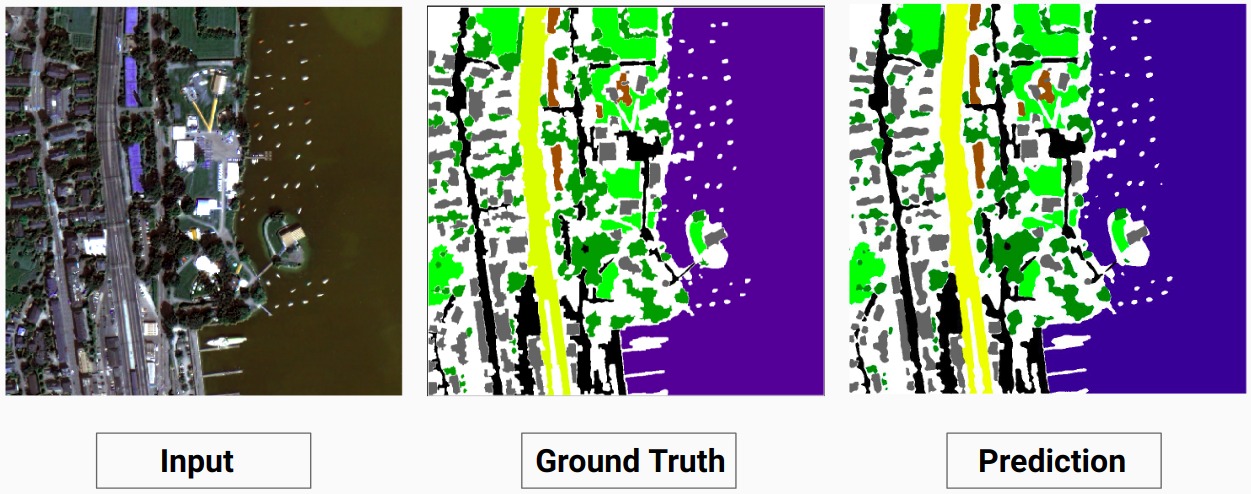
Trainingsbeispiel 2: Bild „4.tif“ aus Trainingsdaten
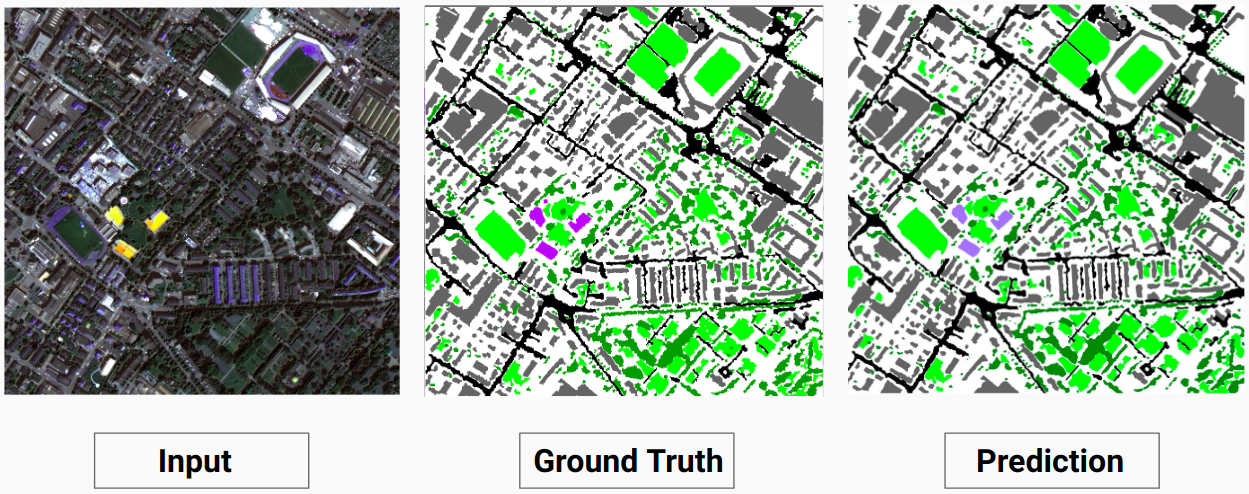
Validierungsbeispiel: Bild „14.tif“ aus dem Datensatz

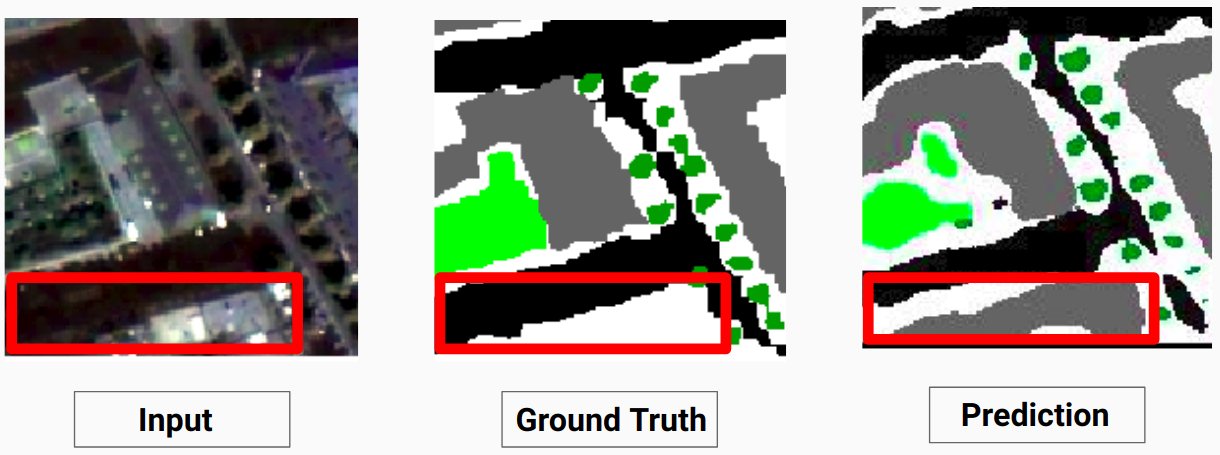
Unser Modell ist in der Lage, einige Klassen vorherzusagen, zu denen ein menschlicher Annotator nicht in der Lage war. Die nicht identifizierbaren Klassen in den Bildern werden vom menschlichen Annotator als weiße Pixel gekennzeichnet. Unser Modell ist in der Lage, einige dieser weißen Pixel als eine bestimmte Klasse korrekt vorherzusagen. Dies führte jedoch zu einer Verringerung der Gesamtgenauigkeit, da die weißen Pixel vom Modell als separate Klasse betrachtet werden.
Hier ist das Modell in der Lage, die weißen Pixel als korrektes Gebäude vorherzusagen, das im Eingabebild deutlich zu erkennen ist
Schauen Sie sich Comparison_Test.pdf an, um einen Vergleich zwischen Testbildern und ihren vom Modell vorhergesagten Ausgaben zu erhalten
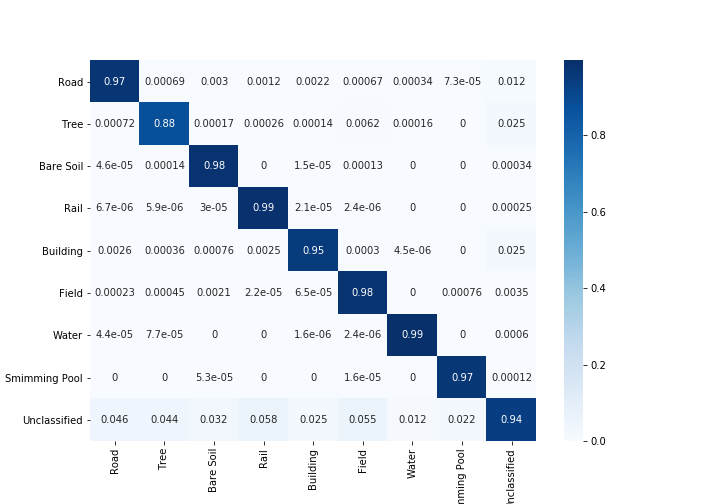
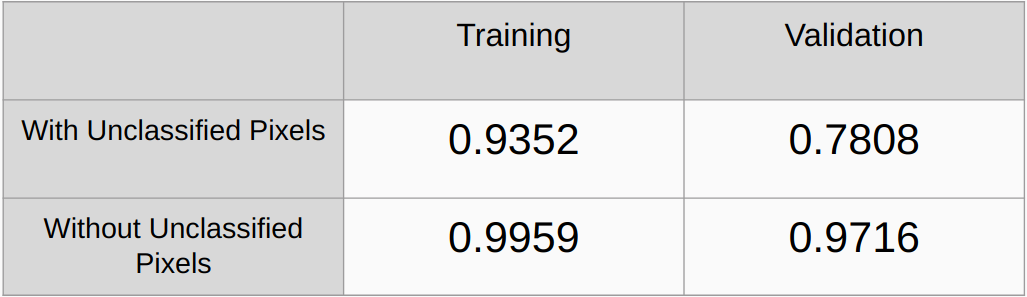
Kappa-Koeffizienten mit und ohne Berücksichtigung der nicht klassifizierten Pixel
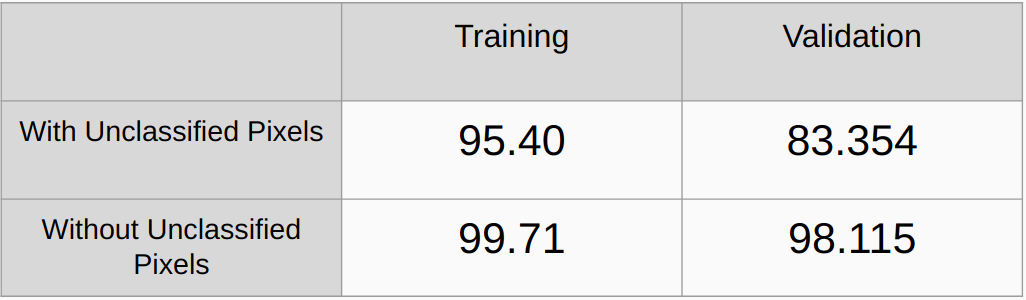
Gesamtgenauigkeit mit und ohne Berücksichtigung der nicht klassifizierten Pixel
Es müssen Regularisierungsmethoden wie L2-Regularisierung und Droupout hinzugefügt und die Leistung überprüft werden
Implementieren Sie einen Algorithmus, um automatisch alle eindeutigen RGB-Werte in den Grundwahrheiten zu erkennen und sie One-Hot-kodiert, anstatt die RGB-Werte manuell zu finden.
[1] U-Net: Convolutional Networks for Biomedical Image Segmentation, Olaf Ronneberger, Philipp Fischer und Thomas Brox
[2] Pyramid Scene Parsing Network, Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, Jiaya Jia
[3] Ein Leitfaden zur semantischen Segmentierung mit Deep Learning aus dem Jahr 2017, Sasank Chilamkurthy


